450% More Traffic, Why Agents Are Rewriting the WAN
Cisco’s WAN report argues that AI agents turn inference calls into a network bottleneck across capacity, security, observability, and reliability.

- What happened: Cisco’s
AI Impact on Wide Area Networksreport measures how AI inference and agentic AI change WAN traffic.- The report says an agent task can create 450% more traffic than the same manual workflow, with roughly 70% of the increase coming from AI inference.
- Why it matters: The bottleneck for agent products is expanding beyond GPUs and token prices into upstream capacity, flow state, QoS, and path security.
- Watch: Cisco’s 2035 forecasts, including 25% AI inference traffic and 9x enterprise traffic growth, are model outputs. The traffic shape matters more than the exact number.
Cisco published a blog post on May 21, 2026 about how AI is changing WAN traffic, alongside its AI Impact on Wide Area Networks: Cisco Report 2026. At first glance, this looks like the kind of infrastructure report a networking company would naturally publish. For developers and AI product teams, the sharper message is elsewhere. As agents spread, AI cost does not stop at a model pricing page. It starts pulling in network flows, upload symmetry, firewall state, observability, and the reliability of the path between an agent and its model.
The most visible number in the report is 450%. Cisco says an Open Deep Research-style agent experiment produced roughly 450% more network traffic than the same task performed manually by a human. About 70% of the increase was AI inference traffic. A user may only ask, "Research this for me," once. Underneath that request, the agent creates a longer execution graph across the agent runtime, web proxy, data sources, model provider, and tools.
That number is not interesting merely because it implies more bandwidth. Cisco describes the AI inference path as the agent's spinal cord. If the model is the brain, the link between the agent logic and the model is closer to the nervous system. When that path slows down or fails, the result is not just a slightly worse page load. The agent itself can fail. As long-running agents, background workflows, multi-tool tasks, and MCP-style connectors become more common, that path becomes part of production reliability.
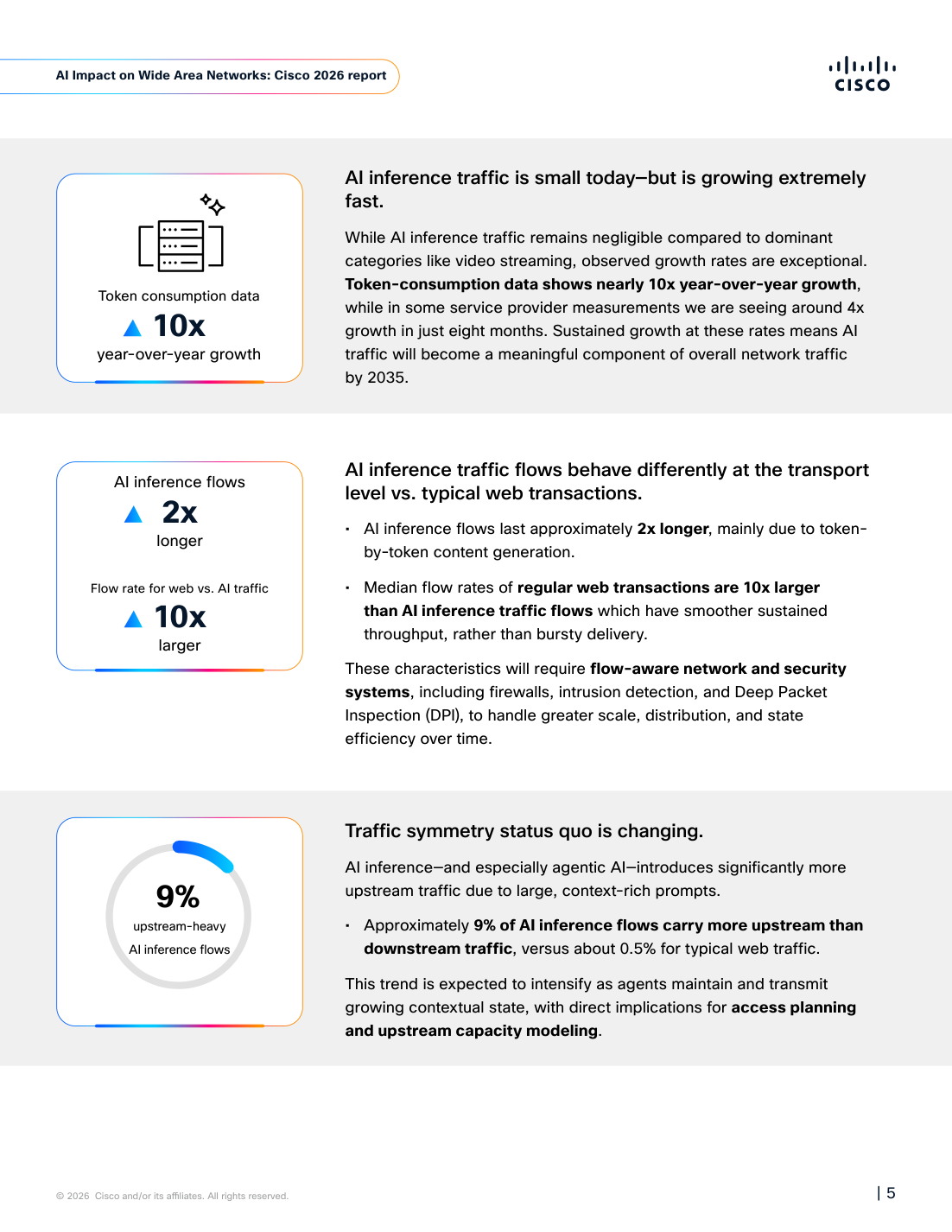
AI traffic does not move like web traffic
The old mental model for web traffic is mostly downstream-heavy. A user requests a page or a video, and a server or CDN sends down the larger payload. Uploads, real-time collaboration, and video calls complicate that picture, but consumer internet planning and a large share of enterprise network planning have long been optimized around bursty downstream demand. Cisco argues that AI inference and agentic AI weaken that assumption.
First, AI inference flows live longer. The report says AI inference flows last about twice as long as ordinary web transactions. The reason is familiar to anyone who has built an LLM feature. The model often streams output token by token instead of returning the full answer at once. That streaming experience feels natural to the user, but to a network device or firewall it is a longer-lived flow. In one request, the difference may be small. Across an agent that calls a model and tools dozens or hundreds of times, the accumulated pressure lands on flow-aware systems: state tables, intrusion detection, deep packet inspection, and telemetry pipelines.
Second, the throughput shape is different. Cisco says the median flow rate for ordinary web transactions is 10 times higher than for AI inference traffic. Web traffic often spikes harder and finishes faster. AI inference traffic is lower but steadier. If a network team looks only at peak bandwidth, it can underestimate this traffic. Long flows and many concurrent sessions create a different kind of capacity problem.
Third, upstream traffic becomes more important. Cisco says about 9% of AI inference flows carry more upstream than downstream traffic. In general HTTP web flows, the comparable share is about 0.5%. Agentic AI can amplify that difference. Agents do not only send a user's short prompt. They keep sending long context, retrieved chunks, conversation state, tool output, file diffs, logs, schemas, and policy text back toward the model. For AI builders, this is a direct architecture warning: larger context windows, richer tool traces, and broader retrieval sets increase not only model cost but also upstream path and observability cost.
The 450% jump is the price tag of the agent loop
Cisco's agent experiment uses an Open Deep Research-style workflow. The report figure shows an agent exploring 44 sources and creating 26.8 MB of agent-triggered traffic across a web proxy, data sources, OpenAI, and the agent. The point is not the absolute number of bytes. The point is that an agent can issue many more requests at software speed than a person performing the same task manually.

A human opens browser tabs, reads search results, clicks a few links, and copies some text. An agent performs the same pattern as a machine workflow. It searches, fetches pages, summarizes them, creates the next query, searches again, asks the model to judge the results, and sends tool output back into the model. Each step may be small. The task graph is not.
This connects directly to AI app unit economics. Many teams still calculate cost as input tokens * price + output tokens * price. That is a useful starting point, but it is incomplete for agent products. When an agent repeatedly calls the web, databases, vector stores, object storage, sandboxes, browsers, code runners, and notification APIs, network and surrounding infrastructure costs move with it. In enterprise deployments, egress, private connectivity, region choice, firewall inspection, log retention, and trace sampling all affect cost and latency.
So the 450% figure is more useful than "Cisco wants to sell more networking equipment." The practical reading is that agentic AI decomposes one user's intent into many machine-to-machine transactions. A large share of those transactions depends on the inference path. Designing agent reliability therefore means looking not only at model retries, tool retries, queues, and caches, but also at path resilience and path visibility.
After the GPU bottleneck comes the WAN question
For the past two years, AI infrastructure conversations have centered on GPUs. H100, H200, B200, TPU, MI300X, inference chips, data center power, and liquid cooling have owned the headlines. That focus is still valid. Training and serving models quickly requires compute. Cisco's report asks the next question: what happens after compute, when the agent has to reach the model, send context, receive tool results, and keep a workflow moving across providers and regions?
The report forecasts that AI inference could account for about 25% of total network traffic by 2035. It also models enterprise traffic growing about 2.5 times from 2026 to 2035 without agentic AI, but about 9 times with agentic AI adoption. For consumer networks, Cisco estimates that AI and agentic AI could create about 63% additional growth compared with a non-AI scenario.
Those long-range forecasts should not be treated as fixed outcomes. They are Cisco model outputs. Agent adoption, product design, on-device inference, caching, compression, model efficiency, regulation, and pricing could all change the shape of the result. If more inference moves to edge or on-device systems, WAN impact may fall. If agents connect to more tools and real-time data sources, traffic may grow. The more important point is directional: Cisco is not merely saying AI traffic gets bigger. It is saying AI traffic looks different.
That difference changes capacity planning. The old question was often, "How much bandwidth do we need?" For agentic AI, the better questions are: which paths are mission-critical, which flows stay open longer, where does upstream become the bottleneck, which inference provider and region define the failure domain, and where should QoS or path security be applied?
Security devices and observability inherit the pressure
When AI inference traffic becomes longer-lived and steadier, firewalls, intrusion detection systems, proxies, DPI layers, and SASE stacks feel it too. Cisco says flow-aware network and security systems need to handle larger scale, wider distribution, and more efficient state management. Longer inference flows increase the state burden, and wider use of encrypted transport and QUIC can make visibility harder.
Converge Digest, reporting on Cisco's study, said QUIC accounted for 57% of measured AI inference traffic volume in Cisco's data set. That number depends on the sample and methodology, so it should not be generalized to every environment. Still, the direction is clear. AI traffic is encrypted, spread across multiple providers and endpoints, and routed through agent runtimes and tools. A security team that relies only on allowing or blocking destination domains may not have enough control.
This matters for developers too. Once an agent product enters production, the security team will ask: where does this agent communicate, which model provider receives which data, is tool output included in prompts, do sensitive files enter retrieval context, and how far can retries spread when something fails? Answering those questions requires application traces and network traces to meet. Model-call logs without network path data leave incident analysis incomplete. Network telemetry without agent step traces cannot tell which task created a traffic spike.
Latency is not everything yet, but it is not optional
One of the report's more useful caveats is that network latency is not yet the dominant AI inference bottleneck. Current end-to-end inference latency is often governed by model processing. Even a short prompt can take hundreds of milliseconds to first token and several seconds to complete. From that angle, a blanket claim that all inference must move to the edge is premature.
But that does not mean the network can be ignored. In an agent loop, small delays compound. A model call, retrieval query, tool call, browser action, validation pass, second model review, and human approval step can stack into a slow workflow. For interactive coding agents or customer support agents, the user waits, so p95 and p99 latency matter. For background agents, reliability and cost may be more important than raw latency. Network design has to follow workload type.
The role of edge inference is therefore more nuanced than "move closer for speed." If the only goal is faster chatbot output, model processing may still dominate. But inference location can matter for data sovereignty, private data locality, tool proximity, offline tolerance, regulatory boundaries, and cost control. Cisco's argument is closer to: latency alone does not justify every edge inference move, but scale, sovereignty, and security may.
The metrics AI teams should start measuring
The practical value of Cisco's report is less in the 2035 forecast and more in the measurement checklist it implies. Teams operating AI apps should stop treating an agent run as a single API call. It is a distributed workflow. First, measure how many model calls one task creates, how many input and output tokens each call uses, and which steps expand the context. Then measure tool calls and data access alongside the model calls. Web fetches, database queries, vector searches, file uploads, sandbox executions, browser sessions, and MCP tool invocations all move through regions and providers.
From a network perspective, it helps to separate at least four paths. The first is the model inference path: the route from agent logic to the model provider or private inference cluster. The second is the retrieval and data path: vector stores, databases, object storage, and document sources. The third is the tool execution path: third-party APIs, internal services, browsers, and code runners. The fourth is the telemetry path: logs, traces, evaluation results, and audit records.
Those paths need to be visible separately. When a user says an agent is slow, the team has to distinguish a slow model from slow retrieval, a tool provider rate limit, packet loss on a network path, or a trace exporter becoming the bottleneck. Cost analysis follows the same pattern. If a cheaper model does not reduce total cost, surrounding traffic, egress, storage, log retention, and retry storms may be the reason.
As agents multiply, upstream becomes a product problem
Upstream traffic is easy for AI product teams to miss. Coding agents that analyze whole repositories, CRM agents that summarize customer records, finance agents that review accounting documents, and web research agents all send large context payloads toward the model. The output may be short while the input is large. If prompt caching, delta encoding, retrieval chunk selection, and context compaction are weak, upstream payloads can grow quickly.
This is not only a network engineering problem. Application architecture shapes it. Sending the entire conversation and all retrieved documents on every agent step is simple, but expensive. Structuring tool output, removing irrelevant chunks, summarizing state, and improving provider-level cache hits can reduce model cost and network load at the same time. As agents get more capable, context hygiene becomes infrastructure optimization.
The MCP and agent connector ecosystem makes the question more urgent. MCP servers can connect agents to SaaS tools and internal systems with a better developer experience. But if a team cannot trace which data went to which model, which tool result was reused at which step, or whether sensitive fields entered a prompt, both security and cost become opaque. Cisco's WAN traffic argument ultimately points back to application-layer habits.
How to read Cisco's report
Cisco sells networking, security, and observability products. It is natural for the report to lead toward the conclusion that AI-ready networks are necessary. Readers should keep that vendor context in mind. Numbers such as 25% inference traffic in 2035, 9x enterprise traffic growth, and 63% additional consumer traffic growth come from a forecast model. Different adoption curves, on-device models, compression, regulation, pricing, or product design could change the result.
That does not make the report disposable marketing. Its stronger contribution is a framework for distinguishing AI traffic from ordinary web traffic. Token-by-token streaming, longer-lived flows, upstream-heavy prompts, agent-driven tool traversal, and inference-path criticality are already visible in production AI systems. Teams that connect their agent traces to network traces may find similar patterns now.
Network World and Converge Digest emphasized the same point in their coverage. This story matters not because the internet is guaranteed to become mostly AI traffic overnight, but because agentic AI weakens old network planning assumptions one by one. As AI agents enter enterprise workflows, traffic is no longer bounded by the speed of human clicks. A software-speed agent that calls multiple providers and tools can turn one small user-facing feature into movement across a much larger infrastructure graph.
The conclusion is that agent reliability now has a wider boundary
Running AI agents reliably is no longer only about writing better prompts or choosing a stronger model. Model selection, prompt caching, RAG quality, tool permissions, sandbox isolation, evaluations, and human approvals still matter. Cisco's report adds network path and traffic shape to that list. If the path between agent logic and the model is the agent's spinal cord, then latency, packet loss, congestion, security inspection, and observability on that path are part of product reliability.
This does not mean every team should accept Cisco's long-range forecast and buy new network infrastructure immediately. A more practical first step is to connect agent run traces with traffic traces. Which tasks create how many inference calls? Which providers and regions do they cross? Why is upstream payload growing? How much do retries amplify traffic? Do long-running flows pressure the security stack's state management?
Once those answers exist, the team has options. It can shrink context, narrow retrieval, add caching, move a model closer to users or tools, run private inference, apply QoS, or monitor a specific agent path more closely. The next AI infrastructure bottleneck may appear outside the GPU. Cisco's most useful message is that agents are not merely applications that use models. They are software workers that continuously move the network.