SkillOpt Turns Agent Skills Into Trainable Deployment Artifacts
Microsoft SkillOpt treats SKILL.md-style agent instructions as trainable artifacts updated through rollouts, validation scores, and bounded edits.
- What happened: Microsoft published the
SkillOptpaper, project page, and GitHub code.- arXiv v2 landed on May 25, 2026, and proposes training skill documents into deployable
best_skill.mdartifacts.
- arXiv v2 landed on May 25, 2026, and proposes training skill documents into deployable
- The claim: The paper reports best or tied-best results across 52 evaluation cells covering 6 benchmarks, 7 target models, and 3 harnesses.
- Why builders should care: A
SKILL.mdfile becomes more than a prompt. It can carry rollout evidence, validation history, transfer tests, and deployment control. - Watch the limits: The results are benchmark-centered. Real repositories still need data splits, validation gates, policy review, and permission boundaries.
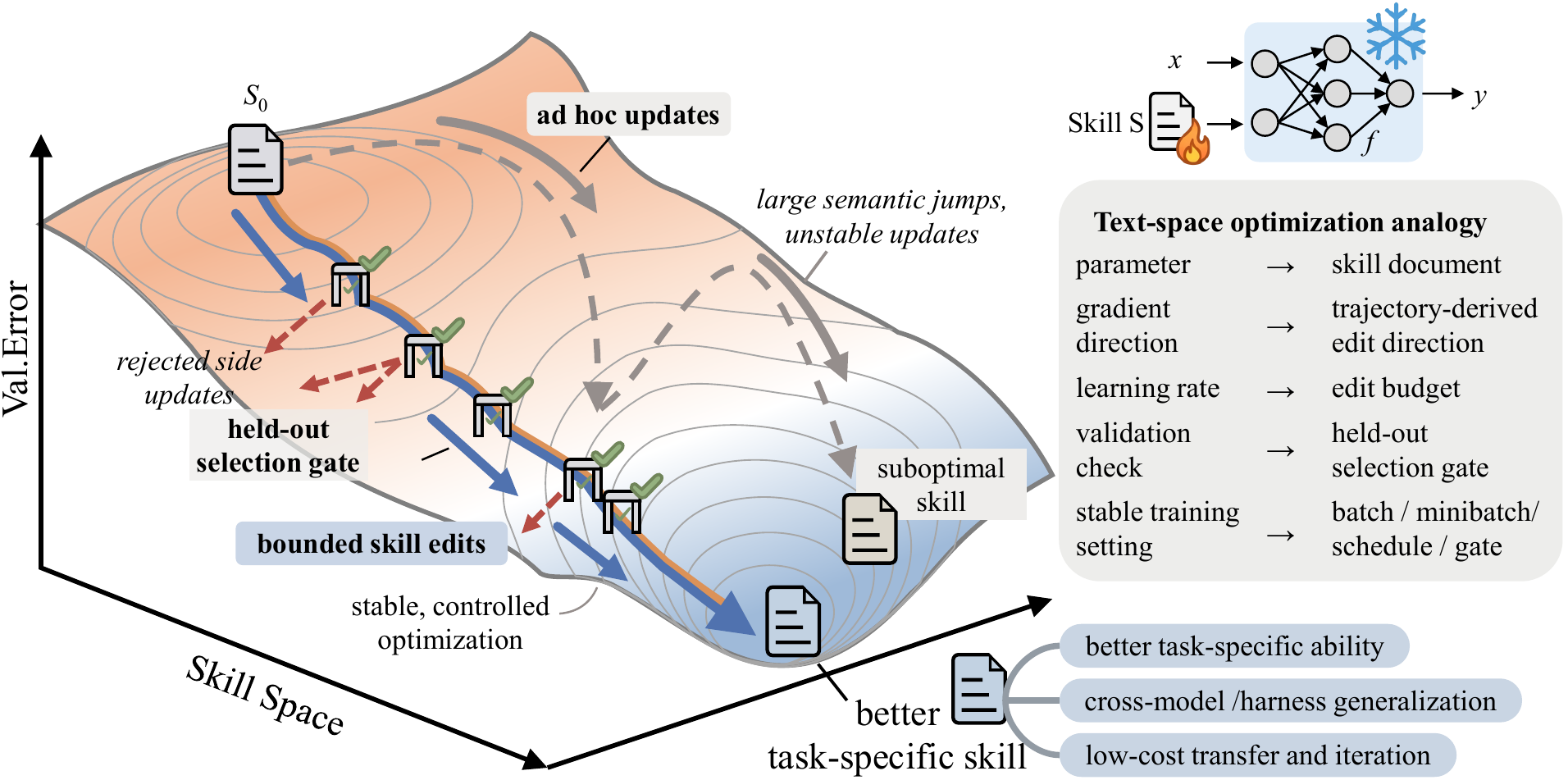
Microsoft's SkillOpt paper, posted to arXiv in v2 form on May 25, 2026, changes the way agent teams should read skill files. The full title is SkillOpt: Executive Strategy for Self-Evolving Agent Skills. The paper and project page make a direct claim: natural-language procedure files such as SKILL.md should not be treated as static instructions that a human writes once. They can be trained as external state, using model rollouts and validation scores.
That distinction matters for coding-agent users because SkillOpt does not train a new target model. The target model stays frozen. A separate optimizer model studies successful and failed trajectories, then proposes add, delete, or replace edits to the skill document. A candidate skill is adopted only when it improves held-out validation performance. At deployment time, the agent does not carry the optimizer's memory or a long reflection transcript. It reads a compact best_skill.md file.
Skill files become external state, not just prompts
Coding-agent products have been absorbing repository-level instruction files at high speed. Claude Code, Codex, GitHub Copilot app customization, Google Managed Agents, Android agent skills, and NVIDIA Verified Skills all point in the same direction. AGENTS.md, SKILL.md, MCP configuration, hooks, plugins, and connectors are moving from informal docs into the operational surface of development tools. At first these files looked like a way to tell an agent about team norms. Once an agent edits files, runs tests, and calls external tools, the same files start to behave more like execution preconditions.
SkillOpt focuses on the quality-control problem behind those files. A human-written skill may be useful on day one, then decay as failure patterns accumulate. A one-shot LLM-generated skill can encode a reasonable procedure, but it does not automatically absorb repeated failures from benchmark runs or real work. The SkillOpt paper frames earlier approaches as hand-crafted skills, one-shot generated skills, or loosely controlled self-revision. Its contribution is not gradient-based optimization of text, but a disciplined learning loop around document edits.
The project README describes the skill document as trainable state for a frozen agent. That phrase is doing real work. SkillOpt does not require model weight access, fine-tuning rights, or a custom inference stack. It can sit on top of provider APIs, Codex-style agent loops, or Claude Code-style CLI environments and modify only the external skill artifact. For enterprises, that opens a route to improve repeated task performance without changing the model provider contract.
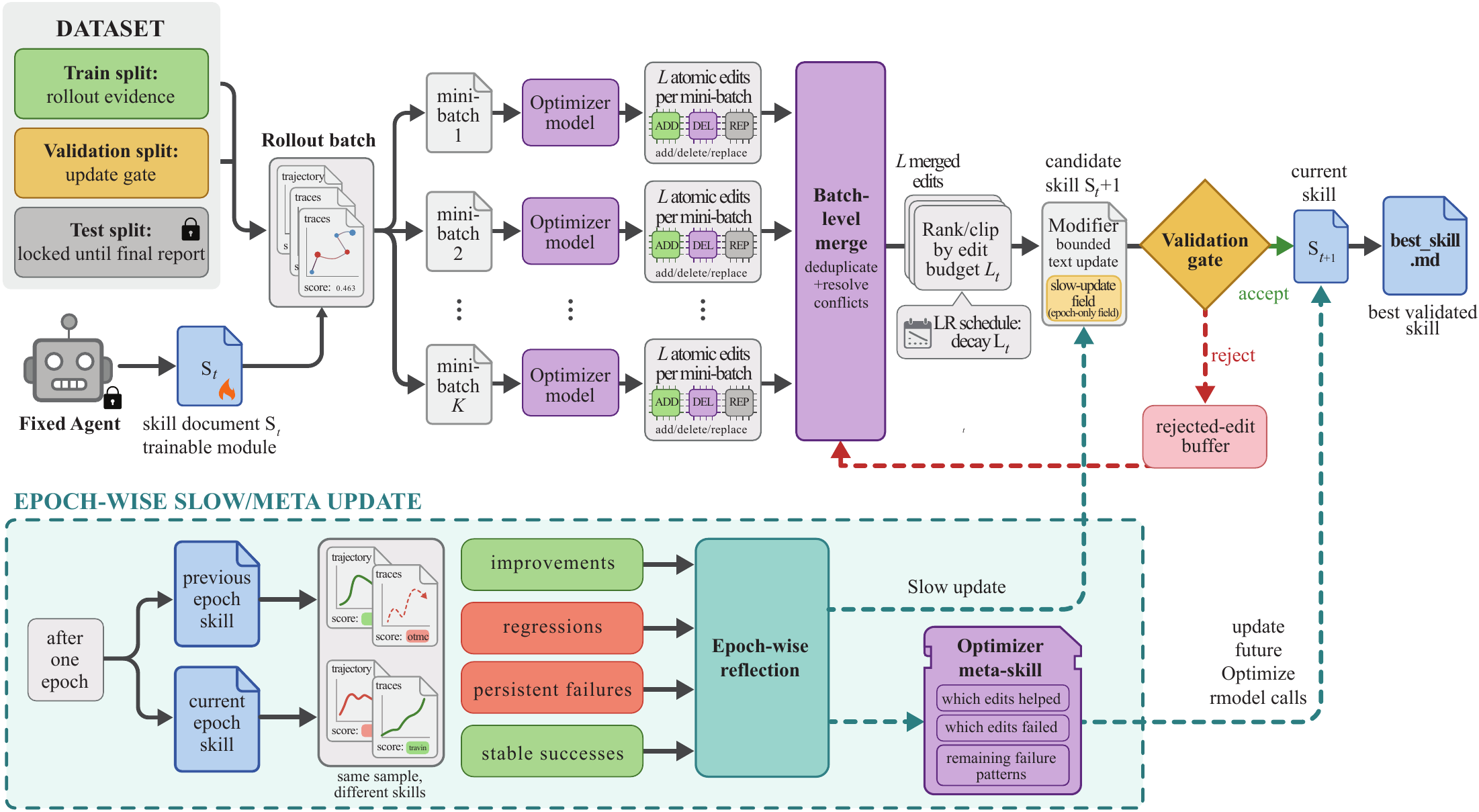
The loop is rollout, reflection, bounded edit, validation gate
SkillOpt's learning loop can be summarized in four steps. First, the target model reads the current skill and executes a batch of tasks. Messages, tool calls, verifier feedback, task metadata, and final scores become rollout evidence. Second, the optimizer model inspects successful and failed minibatches separately and reflects on which procedures should be kept and which errors are recurring. Third, the optimizer proposes bounded add, delete, or replace edits to the skill document. Fourth, a candidate skill is accepted only if it beats the current best skill on a held-out selection set.
The bounded edit constraint is not an implementation detail. The project page uses the phrase textual learning rate. Rewriting the entire skill can erase rules that were already working. Allowing only tiny changes can fail to capture a new failure mode. SkillOpt uses an edit budget to constrain each update and a rejected-edit buffer to reduce repeated attempts in directions that already failed.
The paper also describes slow or meta updates as a stabilizing element. Longer-horizon feedback can be incorporated across epochs, while the deployment artifact remains small. The deployed output is best_skill.md, not the optimizer's entire reasoning history. The README describes these compact skills as usually 300 to 2,000 tokens. That separation is important in production: adding an optimizer call at inference time would increase latency, cost, and security review scope. SkillOpt keeps training-time optimization separate from deployment-time use.
| Stage | SkillOpt role | Operational reading |
|---|---|---|
| Rollout | Run a task batch with the current skill | Record success and failure as traces, not anecdotes |
| Reflection | Analyze success and failure minibatches separately | Separate rules to preserve from rules to repair |
| Bounded edit | Generate add, delete, or replace candidates | Reduce regressions from whole-document rewrites |
| Gate | Accept only candidates that improve held-out score | Turn plausible self-edits into validated artifacts |
The headline result spans 52 evaluation cells
The largest number in SkillOpt's public claim is 52. The arXiv abstract says SkillOpt is best or tied-best in all 52 (model, benchmark, harness) evaluation cells across 6 benchmarks, 7 target models, and 3 execution harnesses. The baselines include human skills, one-shot LLM skills, Trace2Skill, TextGrad, GEPA, and EvoSkill-style methods.
The harness choice is as notable as the score table. SkillOpt does not evaluate only direct chat. It also includes a Codex agentic loop and a Claude Code execution environment. In current agent products, performance is not determined by the model name alone. The same model can behave differently depending on how the harness wraps tool calls, exposes the filesystem and shell, summarizes failures, or manages intermediate state. By treating Codex and Claude Code as separate harnesses, the study puts that product-layer variance into the experimental design.
The reported gains are large. In the abstract, GPT-5.5 average accuracy improvements over no-skill baselines are +23.5 points for direct chat, +24.8 for the Codex agentic loop, and +19.1 for Claude Code. The project page's main-results table lists GPT-5.5 average gains of +21.8 for Codex and +18.6 for Claude Code. Because the abstract and table may use different aggregation contexts, they should not be collapsed into a single number. The stable reading is that SkillOpt claims gains not only in direct chat but also in agent harnesses.
The benchmark set includes SearchQA, Sheet or Spreadsheet tasks, Office, DocVQA, LiveMath, and ALFWorld. That makes the paper different from coding-only SWE-Bench reporting. SkillOpt is asking a broader question: can a natural-language skill be reused across search, spreadsheet work, office automation, visual document question answering, math, and embodied tasks?
Transfer is the most practical part of the paper
For development teams, the transfer experiments may matter more than the leaderboard claim. The project page highlights three transfer numbers: a GPT-5.4 LiveMath skill moved to GPT-5.4-nano with a +15.2 improvement, a Codex-trained SpreadsheetBench skill moved to Claude Code with a +31.8 improvement, and a self-optimizer setting with a +10.4 improvement. The operational question is whether a natural-language procedure learned under one harness can survive in another.
Teams already face this issue without calling it transfer learning. One group may maintain SKILL.md files for Claude Code, while another uses Codex or GitHub Copilot app instructions. When an organization changes model providers or agent CLIs, it is hard to know how much of the existing instruction layer will still work. SkillOpt's transfer results suggest that, in a research setting, an optimized skill artifact can retain value outside the session or harness that created it.
That does not make transfer a production guarantee. Real repository skills include internal package names, release procedures, security policies, approval rules, and customer-data handling constraints. A command that is safe in one harness may be risky in another if permissions, sandboxing, or shell behavior differ. The lesson is not "copy the skill." It is that skills need portable validation procedures.
This is validated editing, not unrestricted self-modification
The phrase self-evolving agent skills can sound risky. In a real product, letting an agent freely rewrite its own instructions could produce prompt-injection exposure, privilege escalation, test avoidance, or deletion of organizational guardrails. SkillOpt is more interesting because it does not propose unrestricted self-modification. The optimizer can produce candidate edits, but a held-out validation gate decides adoption.
The ALFWorld example on the project page shows the structure. One run increased the selection score from 68.6% to 81.4% and the final ALFWorld test-hard score from 70.9% to 85.8%. The same walkthrough also shows a candidate at step 4 that improved train score but failed the selection gate. If the reported behavior holds, SkillOpt is stricter than adding more self-reflection text. A candidate has to beat the current best skill on unseen selection tasks.
That difference maps directly to AI engineering operations. Any automated skill-improvement workflow needs at least three controls. The first is a task split: if training rollouts and validation gates use the same data, a skill can overfit benchmark wording. The second is a rollbackable artifact trail: best_skill.md, rejected edits, score history, prompt versions, and harness versions need to be available for regression investigation. The third is a permission boundary: a skill optimizer should not be able to delete security policy, bypass approval rules, or relax secret-handling instructions without policy linting and human review.
The public repository makes the claim inspectable
Microsoft's SkillOpt GitHub repository was created on May 8, 2026. At the Korean article's reporting time, June 1, 2026 at 04:04 UTC, the GitHub API showed 3,767 stars. The repository is a Python project under an MIT license. The README lists Python 3.10 or newer, pip install -e ., and configuration paths for Azure OpenAI, OpenAI-compatible endpoints, Anthropic, Qwen local vLLM, and MiniMax.
The code release matters because many agent papers publish result tables but leave the harness hard to inspect. SkillOpt documents scripts/train.py, scripts/eval_only.py, benchmark configs, the outputs/<run_name>/best_skill.md pattern, and some pretrained skill artifacts. That still does not automatically verify every paper number. Anyone reproducing the results needs to inspect data splits, model versions, provider endpoints, benchmark licenses, and API cost.
The project page also includes a YouTube overview, a teaser figure, and a pipeline figure. This article uses the official pipeline figure as the body image. The thumbnail uses the separate official teaser figure, keeping the card image and the article image distinct.
Skill operations need code-review discipline
SkillOpt is not a tool that every team should deploy immediately. The paper is a 27-page research preprint, and the results come from defined benchmarks under specific model and harness combinations. Production costs and security concerns are substantial. Running optimizer rollouts and repeated validation can increase API spend, and failure trajectories may contain sensitive source code, logs, customer data, or secrets. Internal adoption would require anonymization, secret redaction, sandboxing, and audit logs before score chasing.
The release still changes the standard for agent skills. Many teams currently treat AGENTS.md or SKILL.md as documentation management: who writes the file, where it lives, and which agent reads it. A SkillOpt-style workflow asks sharper questions. What rollout evidence produced this skill? Which validation set did it pass? Which harness measured it? Does the score survive when moved to another model? Which edits failed, and why were they rejected?
Those questions resemble code review. A sentence that looks reasonable to a human is not enough. It should pass tests, avoid regressions, and leave a deployment history. As agents take on more work, skill files start to look less like README notes and more like release artifacts.
What development teams can check now
First, inventory the instruction files agents already read. AGENTS.md, CLAUDE.md, .agents/skills/*/SKILL.md, Copilot instructions, Cursor rules, and MCP configs are hard to validate if no one knows where they are.
Second, break recurring work into benchmark-like tasks. A broad goal such as "understand our repository" is too vague for a SkillOpt-style loop. Dependency updates, flaky-test triage, API documentation refreshes, and migration PRs have clearer inputs and validation criteria. The validation layer can combine unit tests, lint, snapshots, reviewer checklists, and static policy checks.
Third, separate automated improvement from automated deployment. SkillOpt uses a validation gate for candidate edits, but whether a production skill should change is still a release decision. A practical workflow would open a PR with the best_skill.md diff and attach the rollout context, selection score, and harness version.
Fourth, treat model and harness transfer with caution. SkillOpt reports transfer between Codex and Claude Code, but production harnesses differ in permission models and tool semantics. The instruction "run tests" can mean local shell execution, a remote sandbox, a CI job, or a managed-agent API depending on the environment. A transferred skill should pass validation again in the new harness.
SkillOpt's message sits on the other side of the model race. Instead of waiting for a better model, it asks whether the agent already in use can compress repeated failures into a verified procedure file. If the answer is yes, SKILL.md is no longer static operations documentation. It becomes a learning artifact that an agent carries across tasks. The paper and public code give that shift a concrete loop, measurable claims, and a deployable file name: best_skill.md.