Mythos found 10,000 vulnerabilities, now patching is the bottleneck
Anthropic Project Glasswing says Claude Mythos Preview and partners can find vulnerabilities faster than teams can validate, disclose, and patch them.

- What happened: Anthropic says
Claude Mythos Previewand about 50 Project Glasswing partners found more than 10,000 high or critical vulnerabilities in one month.- The same update reported 23,019 potential findings across more than 1,000 open-source projects, including 6,202 that the model estimated as high or critical.
- The bottleneck: Anthropic frames validation, disclosure, and patch throughput as the new limit, not vulnerability discovery itself.
- Operator reaction: Cloudflare and Mozilla both point to parallel harnesses, independent validation, and release pipelines rather than generic coding agents.
- Watch: Most individual vulnerabilities remain undisclosed, and the numbers come from a controlled preview run by Anthropic and selected partners.
Anthropic published its first Project Glasswing update on May 22, 2026. The headline number is large: Claude Mythos Preview and roughly 50 partners found more than 10,000 high or critical vulnerabilities in important software during the first month. Anthropic's own framing puts the operational queue ahead of the model launch story. Security work used to be constrained by how quickly teams could find new bugs. In this report, Anthropic argues that AI can generate more findings than organizations can validate, disclose responsibly, and patch.
Project Glasswing began in April 2026 as a restricted preview rather than a public model release. Anthropic's Frontier Red Team post says Mythos Preview is not available through a general API. Instead, Anthropic offered it first to partners operating critical software and to open-source maintainers. That same post describes Mythos Preview as a system capable of finding zero-days in major operating systems and browsers, building exploits, and autonomously discovering and exploiting CVE-2026-4747, a 17-year-old remote code execution bug in the FreeBSD NFS server.
For development teams, the new question is no longer whether an AI model can find vulnerabilities. Cloudflare, Mozilla, and the UK AI Security Institute each published related notes, and all three shift attention to what happens after discovery. A large vulnerability stream forces teams to triage reports, reproduce proofs, remove duplicates, trace reachability, schedule releases, write advisories, and update customers. Adding more model calls does not automatically shrink those stages.
The numbers grew in one month
Anthropic says most Glasswing partners found hundreds of critical or high-severity vulnerabilities in their own software. The official update cites Cloudflare as finding 2,000 bugs in critical-path systems, including 400 high or critical issues. Anthropic also quotes Cloudflare's assessment that the false-positive rate was better than what the team sees from human testers.
Anthropic separately disclosed open-source scan numbers. Over the previous few months, it used Mythos Preview to scan more than 1,000 open-source projects and found 23,019 potential vulnerabilities. The model estimated 6,202 of those as high or critical. Applying current post-triage true-positive rates, Anthropic expects about 3,900 high or critical open-source vulnerabilities to surface even without additional discovery.
The downstream metric is narrower. As of May 22, 2026, Anthropic had directly disclosed 1,596 vetted findings to maintainers of 281 open-source projects. Of those, 97 had been patched and 88 had received a CVE or GitHub Security Advisory. A Cloud Security Alliance research note from May 24 cited the same numbers and read them as evidence of a maintainer capacity gap, even allowing for the fact that not every 90-day disclosure window had elapsed.
Anthropic says a high or critical bug takes two weeks to patch on average, and some maintainers asked the company to slow down the disclosure pace. That number matches the everyday reality of open-source security. A maintainer receiving a critical report has to reproduce it, understand the impact boundary, fix the root cause, prevent regressions, prepare a release, and coordinate an advisory. When several reports arrive at once, each one carries its own disclosure clock.
Mythos is described as an exploit-building model
Anthropic's Frontier Red Team post does not describe Mythos Preview as a static analyzer. It says the model found a FreeBSD NFS server RCE that let an unauthenticated user gain root access, then built an exploit using a 20-gadget ROP chain split across multiple packets. In a separate Firefox 147 JavaScript engine experiment, Opus 4.6 produced two JavaScript shell exploits across hundreds of attempts. Running the same experiment with Mythos Preview produced 181 working exploits and 29 additional cases of register control, according to Anthropic.
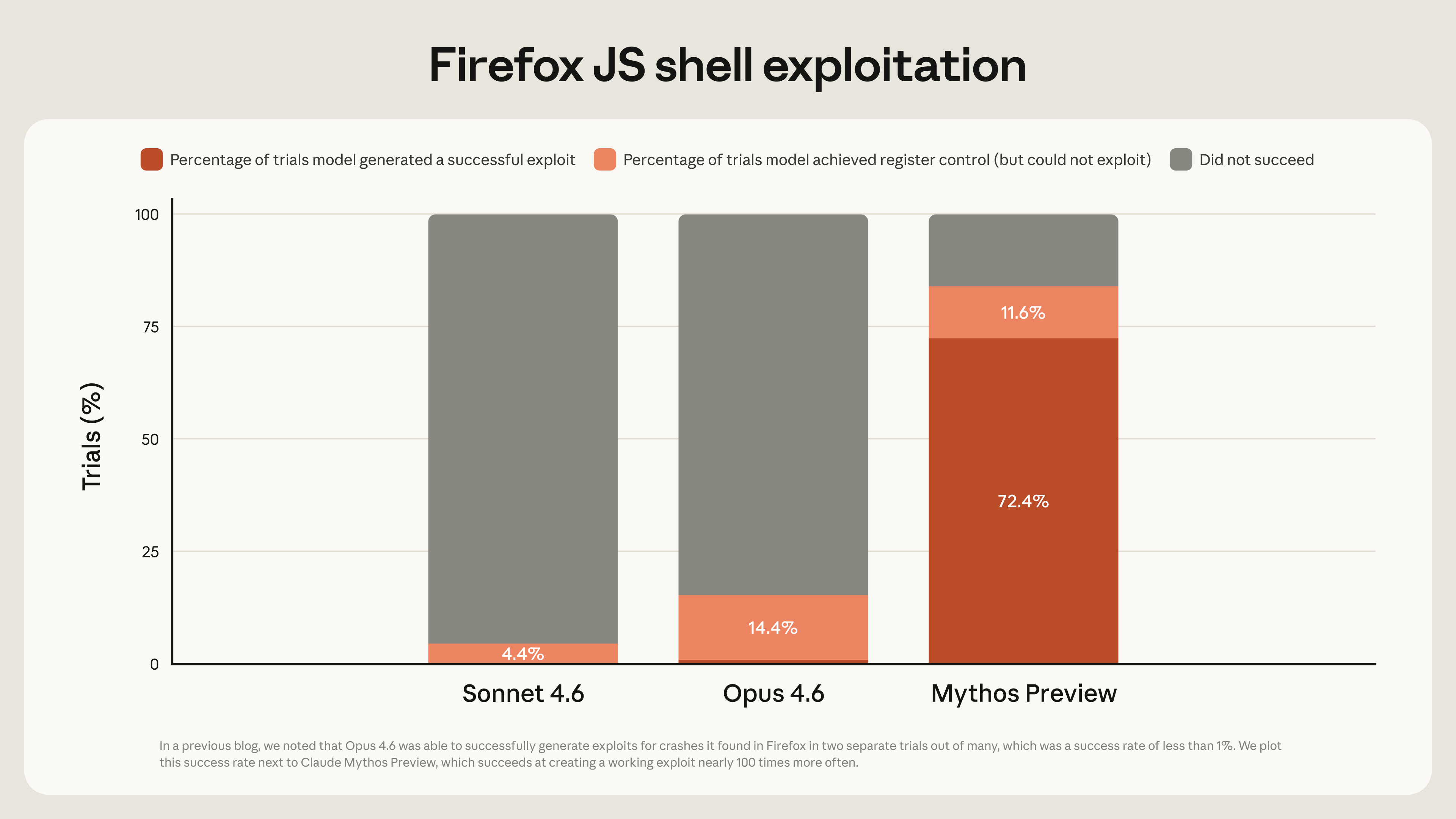 .
.
That chart is a useful reminder for engineers: a vulnerability report and a practical exploit are different artifacts. Many scanners stop after flagging a suspicious code path. Cloudflare's May 18 post emphasizes chain construction and proof generation as the difference. Cloudflare says Mythos Preview connected small primitives into a working proof, compiled and ran code inside scratch environments, and revised its hypothesis after failures. A finding with a proof can reduce the triage question from "is this real?" to "how do we repair and ship this safely?"
Proof still does not mean automatic patching. Cloudflare says it saw cases where model-written patches fixed the original bug while quietly breaking behavior that other systems depended on. Its conclusion is therefore about architecture and pipeline, not simply faster patch generation. If regression testing takes a day, a two-hour security SLA can push teams toward skipping tests and introducing worse bugs.
Firefox 150 included 271 fixes
Mozilla wrote on April 21, 2026 that Firefox 150 included fixes for 271 vulnerabilities confirmed during early Claude Mythos Preview evaluation. It compared that with an earlier Firefox 148 effort that fixed 22 security-sensitive bugs through collaboration with Claude Opus 4.6. Mozilla's team said computers had become good at a category of work they could not do at all a few months earlier, while also stressing the importance of keeping the codebase understandable to humans.
A May 7 Mozilla Hacks post gave more internal detail. Firefox 150's internal rollup CVEs consisted of 154 bugs in CVE-2026-6784, 55 bugs in CVE-2026-6785, and 107 bugs in CVE-2026-6786. Those three rollups add up to 316, and Mozilla explained why that differs from the earlier 271 figure. Across the April 2026 Firefox release, Mozilla fixed 423 security bugs: 41 came from external reports, while the remaining 111 came from pipelines outside Mythos Preview, other models, fuzzing, and related work.
The practical details are the bug classes. Mozilla's examples include a WebAssembly GC struct initialization removed by JIT optimization and a 15-year-old bug in the legend element. It also listed a possible sandbox escape through an IPC race manipulating IndexedDB reference counts, a 20-year-old XSLT use-after-free, and a 16-bit overflow involving rowspan=0 semantics in HTML tables. These are not the easiest code paths for linting or known-pattern matching.
The useful unit is a harness, not a generic coding agent
Cloudflare's post answers the obvious developer question: can a team attach a generic coding agent to a large repository and get the same result? Its answer is no. Cloudflare says one broad agent session over a large repo does not create meaningful coverage. Vulnerability research repeats narrow investigations thousands of times: one feature, one trust boundary, one vulnerability class, one hypothesis at a time. General coding agents are shaped for feature work or bug fixes, not systematic coverage.
The harness Cloudflare describes has multiple stages. A recon agent identifies build commands, trust boundaries, entry points, and attack surfaces. Hunters run in parallel with a vulnerability class and a scoped hint. A validation agent rereads the original finding with the goal of disproving it. Gapfill queues areas that received less coverage. Dedupe merges findings with the same root cause. Trace checks whether a confirmed issue in a shared library is reachable from external attacker input in each consumer repository. The final report stage submits schema-constrained reports to an ingest API rather than free-form prose.
That structure applies beyond security. For AI coding workflows, a single prompt such as "fix this repository" can look impressive in a demo but is weak for tasks that require coverage: security review, large migrations, dependency upgrades, or API deprecations. The operational pattern is to split work into narrow scopes, add independent validation, collapse duplicates, trace reachability, and force structured output so the queue remains usable.
AISI's cyber autonomy result
The UK AI Security Institute wrote on May 13, 2026 that frontier models' cyber task time horizon has been doubling over a span of months. In February 2026, AISI estimated a 4.7-month doubling trend since late 2024. It says Claude Mythos Preview and GPT-5.5 then substantially exceeded that trend.
AISI's cyber range results line up with Anthropic's report. The latest Mythos Preview checkpoint solved "The Last Ones" six times out of ten and solved the previously unsolved "Cooling Tower" three times out of ten. AISI says that checkpoint was the first model to complete both cyber ranges. It also states the limits clearly: these benchmarks do not fully represent real defended systems, and long-task time-horizon estimates still have a small sample of longer tasks.
Those caveats matter. Large numbers from Anthropic and its partners do not mean every production system has become instantly exploitable. Real enterprise defense includes network segmentation, WAFs, sandboxing, patch management, asset inventory, and incident response. A model's ability to complete a lab range is not identical to an attacker's success rate in a defended production network. The defensive upside is also real if the same model and harness are used to find latent bugs before attackers do.
A closed model and public vulnerabilities
Project Glasswing creates a specific tension. Anthropic says misuse risk is the reason Mythos-class capabilities are not broadly released. At the same time, Anthropic has to disclose the vulnerabilities the model finds to maintainers. The model remains closed, but vulnerability handling still runs through 90-day windows, patch releases, CVEs, advisories, and user updates.
Anthropic points to its coordinated vulnerability disclosure policy, where new vulnerabilities are typically disclosed 90 days after discovery or about 45 days after a patch is available. AI-generated volume turns that convention into a lagging indicator. Before the details are public, outsiders see counts and selected examples. Maintainers prepare patches, while users and downstream vendors wait for specifics. Delayed disclosure makes independent verification hard; early disclosure can put unpatched users at risk.
Security community reaction centers on that same tension. Some readers focused less on the 10,000-finding headline than on who has to patch the backlog. Others questioned the true-positive rate, severity classification, Anthropic's public-relations incentive, and the restricted preview's access model. That skepticism does not require dismissing the numbers. Maintainers have already spent time on low-quality AI-generated bug reports, so a large finding stream has to be evaluated alongside proof quality, deduplication, disclosure status, and patch status.
What engineering teams should check now
First, vulnerability-finding agents should not be designed only as chat interfaces. Cloudflare and Mozilla converge on the need for a harness: buildable scratch environments, reproduction tests, independent validation, duplicate collapse, reachability analysis, and structured reports. Without those pieces, the bug queue grows instead of shrinking.
Second, patch throughput deserves its own metric. Discovery counts fit dashboards, but risk reduction depends on vetted findings patched, releases shipped, advisories published, and downstream adoption. Anthropic's own numbers show 97 patched issues out of 1,596 vetted findings as of May 22. The 90-day window is still in progress, but the gap between discovery and remediation is already visible.
Third, AI-written security patches should not be merged directly. Cloudflare's example shows the failure mode: a patch can close the reported vulnerability while breaking an implicit behavior elsewhere. Security fixes often have a wider regression surface than unit tests capture. Browsers, kernels, cryptography libraries, and distributed control planes contain invariants that are not always encoded in tests.
Fourth, AI-generated application code should be reviewed through the same lens. Mozilla's warning about human-comprehensible codebases matters because AI can increase both code volume and latent complexity. If architecture becomes harder for humans to understand, stronger vulnerability-finding models will still run into the same bottleneck at the patch stage.
Project Glasswing's first-month report makes AI security harder to summarize as a race to find more zero-days. The discovery numbers are already large: more than 10,000 partner findings, 23,019 potential open-source findings, 271 Firefox 150 fixes, and 2,000 Cloudflare bugs are all in one news cycle. The next operational numbers to watch are validation backlog, average patch time, release arrival rate, and stale deployment share. Mythos Preview raises a model-access question, but it also raises a more practical engineering question: can human-run security processes absorb AI-speed vulnerability discovery?
Sources
- Anthropic, Project Glasswing: An initial update.
- Anthropic Frontier Red Team, Claude Mythos Preview.
- Cloudflare, Project Glasswing: what Mythos showed us.
- Mozilla, The zero-days are numbered.
- Mozilla Hacks, Behind the Scenes Hardening Firefox with Claude Mythos Preview.
- UK AISI, How fast is autonomous AI cyber capability advancing?.
- Cloud Security Alliance, AI Vulnerability Discovery Velocity and the Disclosure Crisis.