99.82% Cache Hits, the New Variable in Coding Agent Costs
The Reasonix debate shows that coding agent costs depend not only on model pricing, but on harness design that keeps prefix cache intact.

- What happened: The independent open-source coding agent
Reasonixtriggered an HN debate by optimizing its harness around DeepSeek prefix cache behavior.- As of May 24, 2026, npm lists
reasonix0.50.1, while GitHub has adesktop-v0.50.0release.
- As of May 24, 2026, npm lists
- The number: The project cites a one-day workload with
435Minput cache-hit tokens, a99.82%hit ratio, and about$12.34in cost. - Why it matters: Coding agent cost competition is moving beyond model price sheets toward session design that avoids destabilizing the
prefix.- The caveat is important: Reasonix is not an official DeepSeek product, and its benchmarks and security assumptions need independent validation.
The next price sheet for coding agents will not be readable from per-million-token model prices alone. Even when two tools call the same model, the actual bill can diverge depending on how the agent harness serializes the system prompt, tool schemas, working log, and session state on every turn. If those bytes stay stable, the provider can reuse cached prefix computation. If they move, the cache starts over. That is the narrow but consequential point behind the Hacker News debate around Reasonix, an independent open-source coding agent built for DeepSeek.
Reasonix presents itself in simple terms: a terminal coding agent for DeepSeek, designed around prefix-cache stability. As of May 24, 2026, the latest npm package version for reasonix is 0.50.1, and GitHub lists a desktop-v0.50.0 release from the same day. The repository esengine/DeepSeek-Reasonix, checked through the GitHub API during the Korean article's reporting, was created on April 21, 2026, uses the MIT license, and had 6,443 stars and 366 forks. The growth is notable, but the more interesting signal is what the project chooses to emphasize. It is not only saying "smarter agent." It is saying "an agent whose cache does not break."
That framing needs one clarification up front. Reasonix is not an official DeepSeek product. It is an independent open-source project that assumes DeepSeek's API and pricing mechanics deeply enough to optimize around them. So the news is not that DeepSeek shipped a new coding agent. The more precise story is that low-cost models plus cache-aware billing are pushing coding agent harness design into the cost-competition layer.
Why cache became news
Prompt cache or prefix cache is not a new LLM API concept. When a request starts with the same content as a previous request, the provider can reuse work it has already done. The user gets lower input-token cost and usually lower latency. The problem is that real coding-agent conversations are not clean repetitions. An agent reads files, runs shell commands, lists tool schemas, reports the current directory, includes approval modes, tracks git state, and carries tool results forward. If a tiny piece of the early byte sequence changes, the provider can no longer reuse everything after that point.
Reasonix's architecture document treats that as a first-class product constraint. It describes DeepSeek cached input as being charged at roughly 10% of the miss rate, and assumes automatic prefix caching only works when the byte prefix exactly matches a prior request. Reasonix therefore splits context into three zones: an immutable prefix fixed at session start, an append-only log behind it, and volatile scratch state that is not sent upstream as part of the cached prefix.
The point is not simply "compress the prompt." In some ways it is the opposite. The goal is to avoid rewriting or reordering the old prefix. System instructions and tool specs are calculated once at session start. The conversation log grows only by appending. Temporary planning state or scratch reasoning is kept away from the upstream log so it does not contaminate the next request's cacheable prefix. Large tool results may be summarized after later turns, but the design intent is to append those summaries instead of editing the earlier history.
That sounds like a small optimization until you look at how easily coding agents break it. A mode switch can alter the tool list. A timestamp can sneak into the front of the system prompt. A compaction pass can rewrite the entire prior conversation. A provider abstraction layer can serialize the same tool schema with different whitespace or ordering. In those cases, cache support exists on paper but is weak in the actual loop. That is why the HN discussion became contentious. Some commenters treated Reasonix's claim as basic harness hygiene. Others argued that keeping those basics intact inside a real product loop is exactly where the cost savings appear.
The 435M-token one-day example
Reasonix's most eye-catching number appears in its real-world cache hit benchmark. The project says it anonymized a DeepSeek dashboard shared by a user for a single day, May 1, 2026. The reported counts are 435,033,856 input cache-hit tokens, 767,616 input cache-miss tokens, and 179,763 output tokens. On input tokens, that is a 99.82% cache-hit ratio.
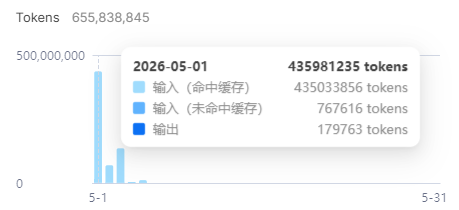
Using the project's deepseek-v4-flash price assumptions, that day of work cost about $12.34. If the same input had been billed with a 0% cache-hit baseline, the estimate rises to about $60.63. That is roughly $48.29 saved in one day, or around 80%. The benchmark document adds that the savings would be larger under its v4-pro assumptions. If the example is representative, cache-hit rate becomes more than a nice optimization once a developer keeps an agent running through an all-day workflow.
The limits of the number matter. This is closer to a project-published case study than a neutral product benchmark. It does not compare task type, session length, files read, failure rate, or the quality of the final engineering output. It also does not show, under a standardized public harness comparison, how much cache hit rate mature coding agents already maintain when pointed at the same DeepSeek API. HN commenters asked for exactly that: comparisons against other harnesses under the same workload.
Still, the example is useful because it moves the cost conversation from "which model is cheap" to "which loop preserves cacheable bytes." Model prices are set by providers. Whether a client keeps rewriting its prefix is a harness decision. In repeated coding work, that decision can become as visible in the bill as model choice.
The three harness principles Reasonix is selling
The first principle is an immutable prefix. System instructions and tool specifications are calculated at the beginning of the session and then held stable. Values that change often, such as current time, current branch, working directory, or approval state, become dangerous when they sit near the front of the request. One byte change there can turn a long tail of otherwise identical context into a cache miss. The analogy is familiar from build systems: if the volatile layer sits too early in a Dockerfile, the useful cache disappears.
The second principle is an append-only log. Even when an agent needs to summarize old tool results or manage context length, Reasonix tries not to overwrite the old prefix. Classic compaction is attractive because it shortens context, but if it rewrites history, it can erase a large reusable prefix from the cache's point of view. Reasonix positions turn-end auto-compaction as a cost-control mechanism while attempting to avoid the kind of reserialization that would defeat prefix reuse.
The third principle is volatile scratch. An agent can keep internal planning state, but that temporary state should not shake the next request's cached prefix. This becomes especially relevant with reasoning models and long tool-use loops. Carrying every intermediate thought and noisy tool result forward may look like "more context," but it can also increase latency and cost quickly. Reasonix's answer is to separate scratch from the upstream cached log.
Those decisions connect directly to its DeepSeek-specific posture. Reasonix narrows provider breadth to optimize more aggressively for one provider's economic mechanics. That tradeoff may show up elsewhere. If OpenAI, Anthropic, Google, DeepSeek, Moonshot, and Qwen-style providers each expose different caching policies and pricing incentives, agent builders will face a choice between broad provider abstraction and provider-tuned harnesses that preserve cache in very specific ways.
Why the HN skepticism matters
The HN reaction was not one-sided, and that is part of the story. Some users said they could already get high cache-hit rates by connecting DeepSeek v4-class models to Claude Code, OpenCode-style harnesses, or other mature tools. Others saw Reasonix as marketing cache-first behavior that any careful harness should already implement. The blunt version of the critique was: should this not be how every model and coding harness works?
That skepticism is fair. Prefix-cache preservation is not a new computer science discovery. Identical bytes hit the cache; changed bytes break it. The harder question is whether a product loop keeps obeying that simple rule as features accumulate. Coding agents now add permission modes, tool schemas, MCP servers, subagents, memory, approval UI, background jobs, file diffs, checkpoints, and session summaries. Each new feature can disturb prompt serialization. Reasonix's claim is less "we invented caching" and more "we are willing to structure the harness around not breaking it."
Security concerns also deserve space. Reasonix uses DeepSeek API keys, and any coding agent can send project files, error logs, command output, design notes, and sometimes secrets-adjacent context to the model provider. HN commenters split between people who saw that as acceptable for personal open-source work and people who would not send private corporate code or user-data-adjacent repositories through that path. This is not only about DeepSeek or any one country. A coding agent connected to any external model provider creates a data-boundary question. For some teams, that comes before cost.
What engineering teams should take from it
First, do not measure agent cost only by output tokens. Coding agents can generate huge input volumes because they read files and carry tool outputs across turns. Long sessions need input cache-hit tokens, cache-miss tokens, and output tokens separated in telemetry. The core of the Reasonix example is not the 179,763 output tokens. It is that almost all of the 435M input tokens were reported as cached.
Second, add prompt stability to the harness evaluation checklist. If a team is building an internal agent or customizing an open-source one, it should inspect whether changing values enter the system prompt early, whether tool schema ordering is deterministic, whether compaction rewrites history, and whether subagents or mode switches alter the tool list near the front of the request. These details rarely appear on model quality scorecards. They can still show up clearly on the monthly invoice.
Third, "cheap model plus high cache hit rate" is not automatically a better developer experience. Preserving cache may push a harness toward conservative pruning or append-only history. That can make the model see too much stale context, or lose details it actually needed after summarization. Reasonix describes flash-first usage, /pro one-shot escalation, and failure-signal auto-escalation, but actual quality still depends on task type. Frontend tweaks, documentation edits, test hardening, large refactors, and security patches do not share one cost-quality curve.
Fourth, enterprise constraints may make the direct tool less relevant than the design principle. Some organizations cannot use the DeepSeek API. Some repositories cannot call external APIs at all. But cache-friendly harness design still applies with on-prem models, internal gateways, VPC inference, or self-hosted endpoints. The practical lesson is portable even when the specific project is not.
The market signal: harnesses are becoming the battleground
Recent coding-agent news has mostly focused on model capability, IDE integration, remote control, browser execution, permissions, security, and benchmarks. Reasonix points at a different axis. Once models are good enough for sustained work and price differences become sharp, the product question shifts from "can this agent call a model" to "can this agent keep using the model without wasting repeated context."
That pattern is familiar from infrastructure. When a database query is slow, teams inspect indexes and query plans before changing the whole engine. When a container build is slow, they look at cache layer order before adding more CPU. LLM agents are entering a similar phase. Bigger models, longer contexts, and more tools are not always the answer. Preserving repeated prefix bytes can shape both product feel and operating cost.
Whether Reasonix becomes a durable alternative to Claude Code, Codex, Cursor, or other large coding-agent products is a separate question. Independent projects can move quickly, but they still need scrutiny around reliability, security review, enterprise support, data handling terms, and long-term maintenance. The question Reasonix raises is likely to outlast the specific project: in an era where developers leave coding agents running all day, "how smart is it?" sits next to "how stable is its prefix?"
The practical takeaway is straightforward. When evaluating a new coding agent, do not stop at the model name and demo video. Check whether session telemetry exposes cache hit and miss counts, how cost accumulates during long tasks, and whether compaction and tool-schema serialization are deterministic. Reasonix's 99.82% figure is a project claim that still deserves comparison and validation. But the direction it points to is hard to ignore: the coding-agent cost sheet is being rewritten outside the model price sheet.