QVAC TurboQuant brings KV cache compression to local AI
Tether QVAC published a TurboQuant implementation for local inference, with 3-bit KV cache compression, Vulkan kernels, long-context benchmarks, and caveats.

- What happened: Tether AI added Google Research's TurboQuant-style KV cache compression to the QVAC SDK and
qvac-fabric-llm.cpp.- Tether announced the release on June 1, 2026, after Google Research published TurboQuant on March 24, 2026.
- The concrete target: QVAC says a 4B model can use about 8 GB of KV cache at 262,000 tokens.
- The implementation exposes formats such as
TBQ3_0,TBQ4_0,PQ3_0, andPQ4_0, plus CPU quantization/dequantization and Vulkan inference kernels.
- The implementation exposes formats such as
- Why builders should care: Long-context local assistants are limited by cache memory, not only by model weights.
- Watch: QVAC's own benchmark tables show small quality deltas in some rows and prompt-processing slowdowns in others.
Tether AI Research Group announced a QVAC SDK update on June 1, 2026, saying it had brought Google Research's TurboQuant work into its local and edge AI stack. The phrase "data-center-sized memory" sits in the announcement, but the developer-facing issue is narrower and more testable: KV cache memory. When an LLM keeps a long conversation, a large document, or a codebase context alive, it stores key and value tensors for the tokens it has already read. That cache grows with context length and can become the practical limit before the model itself changes.
QVAC's explanation gives the scale. At 262,000 tokens, Tether says the KV cache for a 4B model can consume about 8 GB. Four sessions at that length can push cache memory to roughly 32 GB before counting the model weights. That is the kind of number that matters on a laptop, Android device, workstation GPU, or shared-memory system. Local AI products often talk about privacy and offline control, but long-context work eventually becomes a memory-allocation problem.
This is not a new model launch. It is an implementation and distribution story. QVAC Fabric is a local inference engine built from a llama.cpp fork, and the public tetherto/qvac-fabric-llm.cpp README lists TurboQuant KV cache quantization as an exclusive feature not present in upstream. The useful question is therefore not whether Tether has become an AI model lab. It is what changes when a long-context memory-compression technique moves from a research post into a buildable local inference path.
Google Research published the TurboQuant blog post on March 24, 2026. The related arXiv paper, 2504.19874, was submitted on April 28, 2025, under the title "TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate." The abstract describes TurboQuant as online vector quantization with near-optimal distortion, and it reports quality neutrality for KV cache use at 3.5 bits per channel. Google framed the work together with Quantized Johnson-Lindenstrauss and PolarQuant, aimed at memory pressure in LLM KV caches and vector search.
 .
.
KV cache is easy to underestimate because the first local LLM constraint is usually model weight memory. A 7B or 13B model either fits on the device or does not. After the model fits, the next limit appears when the context grows. A short chat at 8K tokens may not expose it. A legal contract review, full research report, multi-hour assistant session, large code repository, or long RAG trace can. In those cases, context length and concurrent sessions consume memory even when the model weights stay fixed.
TurboQuant attacks that second limit. Google Research describes PolarQuant as applying a randomized rotation and polar-coordinate-style compression to reduce overhead from full-precision constants in traditional vector quantization. QJL then applies a 1-bit transform to the residual to reduce bias when estimating inner products for attention scores. The math is more detailed in the paper, but the implementation question is direct: can the engine store keys and values at much lower bit width while preserving enough attention behavior for long-context inference?
QVAC exposes that research direction through cache formats such as TBQ3_0, TBQ4_0, PQ3_0, and PQ4_0. The README also lists 64-wide variants for models with smaller attention head dimensions. The backend details matter. QVAC's documentation says this release includes CPU quantization/dequantization and Vulkan inference kernels. It also says CUDA and Metal do not include TurboQuant kernels in this release.
That backend boundary is a real product constraint. A Mac user cannot assume the Apple Silicon Metal path has the same TurboQuant kernel coverage. A CUDA server cannot take Google's H100 research numbers and map them directly onto QVAC's implementation. QVAC says its SDK targets Android, Windows, Linux, macOS, and iOS, but TurboQuant kernel support is narrower than the overall platform list. For a team evaluating this release, Vulkan stability and model-specific head-dimension support are part of the adoption test.
Google's published results are strong. The Research blog says TurboQuant reduced key-value memory size by at least 6x while preserving needle-in-a-haystack performance in long-context benchmarks. It also says 3-bit KV cache quantization preserved accuracy without training or fine-tuning, and that 4-bit TurboQuant made attention-logit computation up to 8x faster than 32-bit unquantized keys on H100. Google evaluated open-source LLMs including Gemma and Mistral on LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval.
Tether translates that into a local-inference claim. Its QVAC announcement says TurboQuant can compress KV cache by up to 5x and includes a full quantization pipeline, common inference framework adapters, developer documentation, and workload-tuned profiles. The number is lower than Google's "at least 6x" memory reduction, which is not necessarily a problem. It is a reminder that research settings, released formats, backend kernels, and production-oriented guardrails rarely line up perfectly.
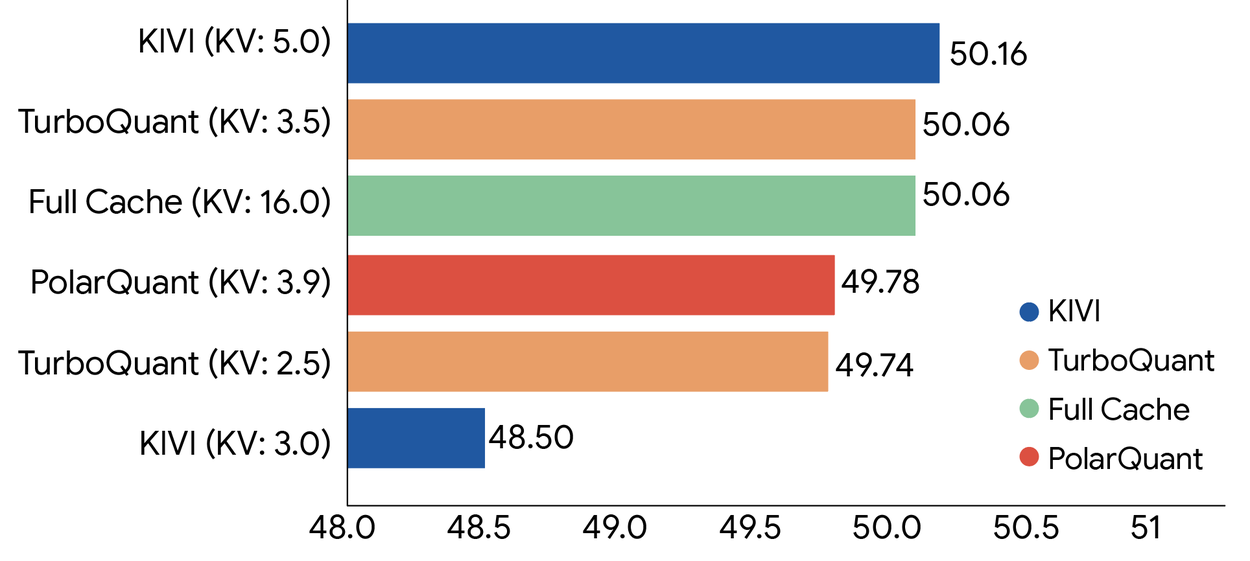
The QVAC benchmark document is more useful than the headline. For Qwen3.5-4B Q8_0, the table reports tbq4_0/pq4_0 with a -0.03% perplexity delta versus f16/f16. In the cross-evaluation table, f16/f16 scores RULER main 96.2 and LongBench average 37.52. The tbq4_0/pq4_0 row scores RULER main 94.8 and LongBench average 37.04. That gap may be acceptable for many workloads, but it is not the same as saying every evaluation is unchanged.
The speed tables deserve an even more cautious reading. On Qwen3.5-4B Q8_0 with 8K context, pq4_0/pq4_0 is close to baseline: RTX 5090 prompt processing at 0.89x and token generation at 0.96x. The tbq4_0/pq4_0 row is different: RTX 5090 prompt processing at 0.42x and token generation at 0.94x. On Strix Halo, the same row shows prompt processing at 0.32x and token generation at 0.97x. Memory compression and generation throughput need to be separated from initial prompt ingestion.
That split changes product design. If an app repeatedly ingests a long document from scratch, prompt-processing slowdown becomes user-visible latency. If an assistant reads a large context once and then keeps many turns alive, resident cache memory and token generation may matter more. Codebase assistants, local research workbenches, and long-lived personal assistants fit the second shape better than stateless "upload and summarize this file" flows.
The community reaction follows the same split. On March 28, 2026, a r/LocalLLaMA post about an MLX implementation reported Qwen2.5-32B on an M4 Pro with 48 GB of memory, 4.6x cache compression, 0.98x FP16 speed, and a 16K context cache dropping from 4.2 GB to 897 MB. That is exactly the kind of local-user pain point TurboQuant-style work can address: high context on smaller machines where memory and speed are both visible.
Other discussions were less enthusiastic. An April 2026 About TurboQuant thread argued that comparisons against full precision were less useful than comparisons against the q4 or q8 KV cache settings many users already run. Some commenters asked for long-chat tests over 50 to 100 turns, where quality degradation may appear differently than in synthetic retrieval benchmarks. A May 2026 discussion about 16 GB VRAM reported that one HIP implementation hit out-of-memory even at 512 tokens because of fixed overhead, while another user suggested Vulkan might be more stable.
Those criticisms do not make QVAC's release unimportant. They turn the release into a clearer checklist. First, KV cache compression does not shrink model weights. Whether a 30B model fits in 16 GB still depends on weight quantization, offload strategy, backend allocator behavior, and runtime overhead. Second, "quality neutrality" comes from specific models, benchmarks, and context patterns. A production assistant with tool-call traces, code diffs, retrieved chunks, and long conversational state needs its own regression suite.
Third, QVAC being a llama.cpp fork is both useful and costly. The benefit is familiarity: GGUF, local server usage, command-line experimentation, and Vulkan build flows are already part of many local inference setups. The cost is tracking divergence from upstream. The README identifies the current upstream baseline as llama.cpp b7248 and lists QVAC-specific features separately. A production team should watch whether upstream llama.cpp adopts similar cache formats and how quickly QVAC keeps up with model and backend changes.
The Tether name also makes the release unusual. Tether is widely known for USDT, but this announcement is about local AI infrastructure rather than blockchain payment rails. QVAC's public direction emphasizes running AI on personal devices and distributed networks. For builders, that story becomes credible through supported models, backend-specific speed, quantization artifacts, and reproducible benchmark documents. The GitHub release matters because it gives developers something to build and measure instead of only a privacy-centered product claim.
The immediate evaluation path is concrete. Check whether the target hardware has a stable Vulkan route. Separate workloads that repeatedly ingest long prompts from workloads that keep a long context resident across turns. Compare f16/f16, q4_0/q4_0, pq4_0/pq4_0, and tbq4_0/pq4_0 on the same prompt set, same model, and same seed. Measure prompt processing, token generation, peak memory, final answer quality, and failure cases rather than relying on a single compression ratio.
The cost model also changes between cloud and local inference. In a cloud API, long context is mainly visible through token pricing, latency, and rate limits. On a local device, it becomes VRAM, shared memory, memory bandwidth, battery drain, and thermal throttling. KV cache compression touches memory capacity and bandwidth directly. If the compression and decompression kernels add enough overhead, however, a user may trade memory headroom for slower prompt ingestion. QVAC's own tables show that trade-off in specific rows.
Reading this release as "local AI will replace cloud AI" overstates the case. A more accurate interpretation is that cache memory is becoming an independent optimization target for long-context local inference. Weight quantization, speculative decoding, retrieval chunking, paging strategies, and KV cache quantization address different bottlenecks. QVAC's TurboQuant implementation pulls one of those bottlenecks into a product-facing feature that local LLM builders can test.
The remaining question is reproducibility across real devices. Google Research, Tether's announcement, and QVAC's benchmark document do not all speak at the same layer. Google explains the algorithm and long-context benchmark behavior. Tether describes local and edge deployment with up to 5x more context. GitHub shows model-specific quality and speed rows with backend details. Put together, they make "3-bit KV cache" look less like a magic setting and more like an engineering option: save memory for long context, then decide whether the workload can pay the processing cost.
QVAC TurboQuant is useful because it moves that option closer to ordinary local inference experiments. Teams building long-document assistants, local codebase assistants, offline research tools, or private personal assistants now have a reason to add KV cache format to their benchmark matrix. The number that matters is not the announcement's largest compression ratio. It is how f16/f16, q4_0/q4_0, pq4_0/pq4_0, and tbq4_0/pq4_0 behave on the user's device, with the user's context length, backend, and quality bar.