Perplexity Search as Code Runs Agent Search in Python
Perplexity introduced Search as Code, a Python sandbox architecture for turning repeated agent retrieval into executable search pipelines.

- What happened: Perplexity published Search as Code on June 1, 2026 as a new reference search architecture for Agent API and Perplexity Computer.
- Models compose search primitives in
Python, then run retrieval, ranking, fan-out, filtering, and state handling inside a secure sandbox.
- Models compose search primitives in
- Why it matters: Perplexity is treating agentic search as an executable retrieval program, not a chain of serial function calls or MCP-style round trips.
- Numbers: In a CVE advisory case study, Perplexity says token use fell from 288.7K to 42.9K, while WANDR scored 2.5x higher than the next system.
- Watch: WANDR is still awaiting public release, and sandbox plus search invocation costs need to be counted separately from model tokens.
Perplexity Research published Search as Code on June 1, 2026. The company abbreviates it as SaC and describes it as a new reference search architecture for Agent API and Perplexity Computer. The older AI search pattern asks a model to write a query, lets a fixed search pipeline return a result set, and then pushes those results back into the model context. SaC lowers that boundary. The model writes Python code that composes search-stack primitives, and Perplexity runs that retrieval pipeline inside a secure sandbox.
For developers, this reads less like a search-quality update and more like a runtime design change for agents. Perplexity says a single task inside Computer can invoke hundreds or thousands of retrieval operations within minutes. A human search box does not need that shape. An agent comparing hundreds of security advisories, investigating a vendor market, or moving between a codebase and web documentation needs repeated queries, parallel fetches, deduplication, filtering, ranking, and evidence checks inside one long task.
SaC does not start from the premise that search results need a better summary. Perplexity is arguing that search should become an I/O layer an agent can program directly. The model decides what evidence it needs. A deterministic runtime handles batching, parallelism, filtering, and aggregation. The search infrastructure exposes low-level handles to current-world information. SaC combines those three roles into a product and architecture story.
 .
.
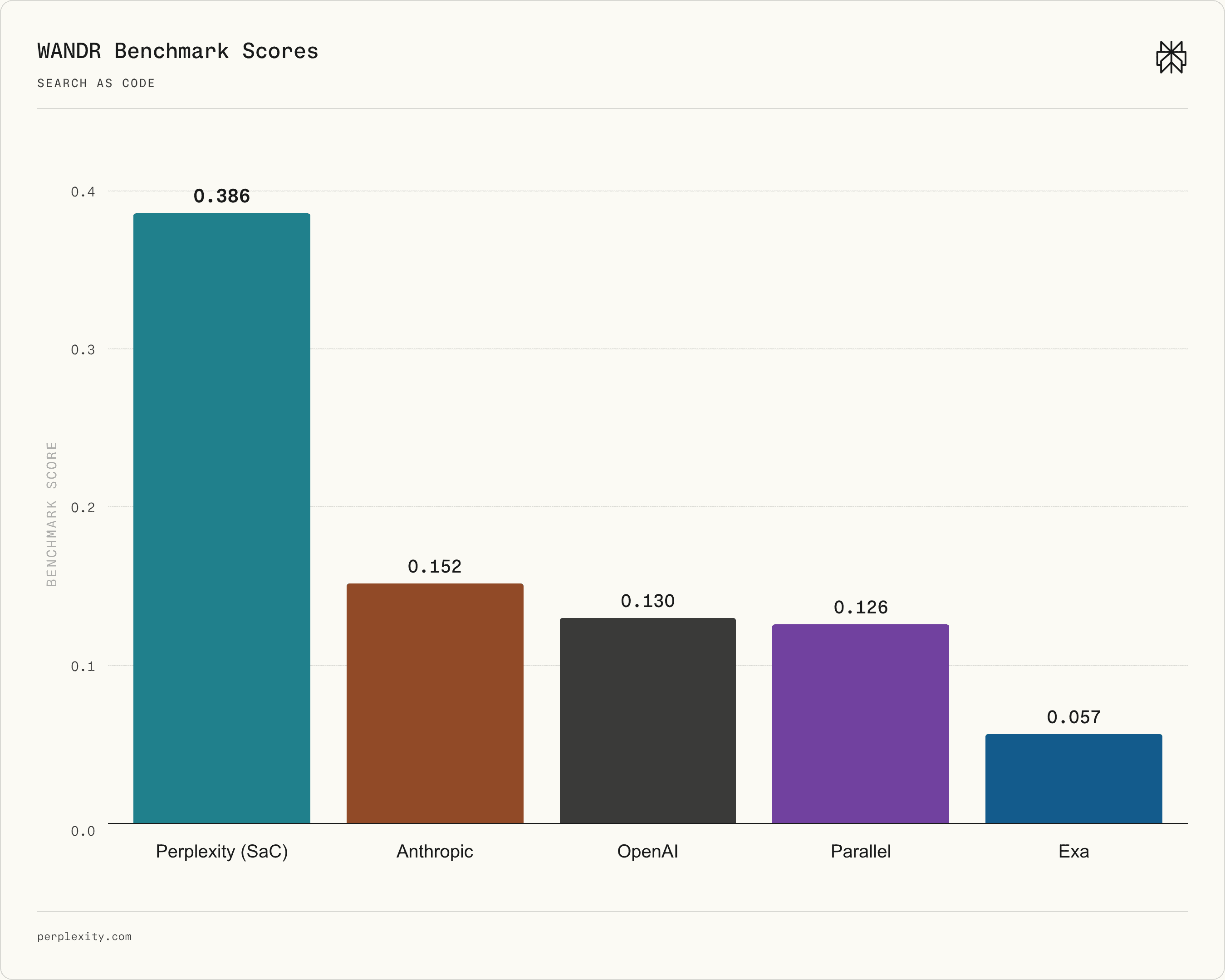
Perplexity's official Figure 5 shows SaC scoring higher than other agent-based systems on its upcoming WANDR benchmark. The chart is Perplexity's own evaluation material, so the claim should be read separately from independent replication.
From a fixed API to a search program
Perplexity breaks the failure mode of current search interfaces into three parts. First, context becomes coarse. Even when a model needs one narrow fact, a fixed endpoint may return a broad recall-oriented result set. Second, the model's domain knowledge is hard to express through query parameters. If the agent wants to prioritize a specific source, combine lexical and semantic signals, or change ranking based on task-specific evidence, the endpoint may not expose that control. Third, fan-out and deduplication workflows get pushed into repeated model turns, which raises latency and pollutes the context window.
SaC avoids representing search as a long sequence of model-visible tool calls. The model writes Python code, and that code calls the Agentic Search SDK. Perplexity says the SDK is not just a wrapper around its existing search API. It is a redesign of the search stack into modular primitives such as retrieval, ranking, filtering, fan-out, and rendering. A higher-level end-to-end search pipeline remains available, but the agent can assemble lower-level pieces when the task demands it.
Perplexity chose Python as the first runtime. The company says it evaluated Rust, TypeScript, and Bash, but internal testing made Python the most natural choice. That tracks with how developers already handle large result sets: list comprehensions, async batching, regular expressions, JSON parsing, lightweight scoring logic, and dataframe-style transformations are compact in Python. Agent-generated code is also easier to review as Python functions than as a complex shell pipeline.
| Dimension | Serial tool-call search | Search as Code |
|---|---|---|
| Control unit | The model calls a search API one request at a time | The model generates search pipeline code |
| Intermediate state | Results often enter token context directly | Sandbox files, variables, and serialized state carry the workflow |
| Parallelism | Depends on repeated turns and tool scheduling | Python performs fan-out, batching, and deduplication |
| Failure surface | The path from query to final result can become opaque | Search strategy, filters, and verification schemas remain as code |
This comparison does not make SaC the right answer for every search problem. A chatbot that only needs a few current documents can stay with a conventional search API. SaC is strongest when the query set is large, constraints change during the task, intermediate candidates need pruning, and the final answer requires a separate verification pass. Perplexity's CVE vendor advisory example fits that class.
The CVE case study claims an 85.1% token cut
Perplexity's case study asks the system to find more than 200 high-severity CVEs from 2023 through 2025. Each record has to identify the vendor advisory, affected product, fixed version, and evidence tying the CVE to that fixed version. Perplexity says SaC reached 100% accuracy on the task and reduced token use from 288.7K to 42.9K compared with a non-SaC baseline using the same Perplexity search infrastructure. That is an 85.1% reduction. Perplexity also says non-Perplexity systems scored below 25%.
The token reduction does not come from looking at fewer pages by luck. The example code constructs vendor-specific advisory URL patterns for Mozilla, Jenkins, Chrome, Android, and other sources. It expands years and months into query lists, calls sdk.search.web_many for parallel search, and structurally excludes results that are not vendor-owned advisories. The model context does not receive every seed hit. Code narrows the candidate set and leaves only the state needed for the next phase.
The second phase identifies sparse vendor-year coverage and expands the search plan. Code summarizes current coverage, then asks the LLM to propose exact-phrase queries for the missing vendor-year combinations. Those proposed queries are validated against official-source scope and CVE-year constraints before another search run. The LLM supplies reasoning, while code handles execution and checks. That differs from a model reading one search result at a time and deciding which tool call to make next.
The final phase validates the link between CVE and fixed version through a schema. Perplexity's example passes instructions to sdk.llm.extract_many that keep only cases where vendor-authored advisories connect a high or critical CVE to a specific fixed version, build, patch, or security level. The schema includes cve, vendor, product, fix_version, severity, source_url, evidence, version_bound_to_cve, and confidence. For security research automation, that distinction is material: the workflow is not just finding pages that mention a CVE number, but verifying the relation between a CVE and remediation text in a vendor source.
Strong benchmark numbers still need source separation
Perplexity says it evaluated SaC on five benchmarks: DeepSearchQA, BrowseComp, Humanity's Last Exam, WideSearch, and WANDR. WANDR is the new benchmark, inspired by knowledge-intensive professional tasks in Perplexity Computer. Perplexity says it plans to release WANDR within weeks. Readers should keep that boundary visible. DSQA, BrowseComp, HLE, and WideSearch connect to external benchmark material, while WANDR does not yet have public independent replication.
In Perplexity's official table, SaC scores 0.871 on DSQA, 0.805 on BrowseComp, 0.612 on HLE, 0.651 on WideSearch, and 0.386 on WANDR. The same table puts OpenAI slightly ahead on HLE at 0.614 and below SaC on the other four. Anthropic is strong on DSQA at 0.815 and WideSearch at 0.590, but lower on BrowseComp and WANDR. Exa and Parallel also appear in the comparison. Perplexity says it compares individual runs rather than best-of-N sampling, with the goal of evaluating the underlying architecture.
On WANDR, Perplexity shows Agent API scoring 2.5 times higher than the next system. That is a notable figure, but it should not be translated directly into a market conclusion. The benchmark is not public yet, and external reviewers cannot inspect task selection or grading protocol. The task framing still matches real agent workloads: enterprise research agents often perform vendor comparisons, regulatory research, incident-timeline reconstruction, and migration-impact analysis rather than single-document question answering.
 .
.
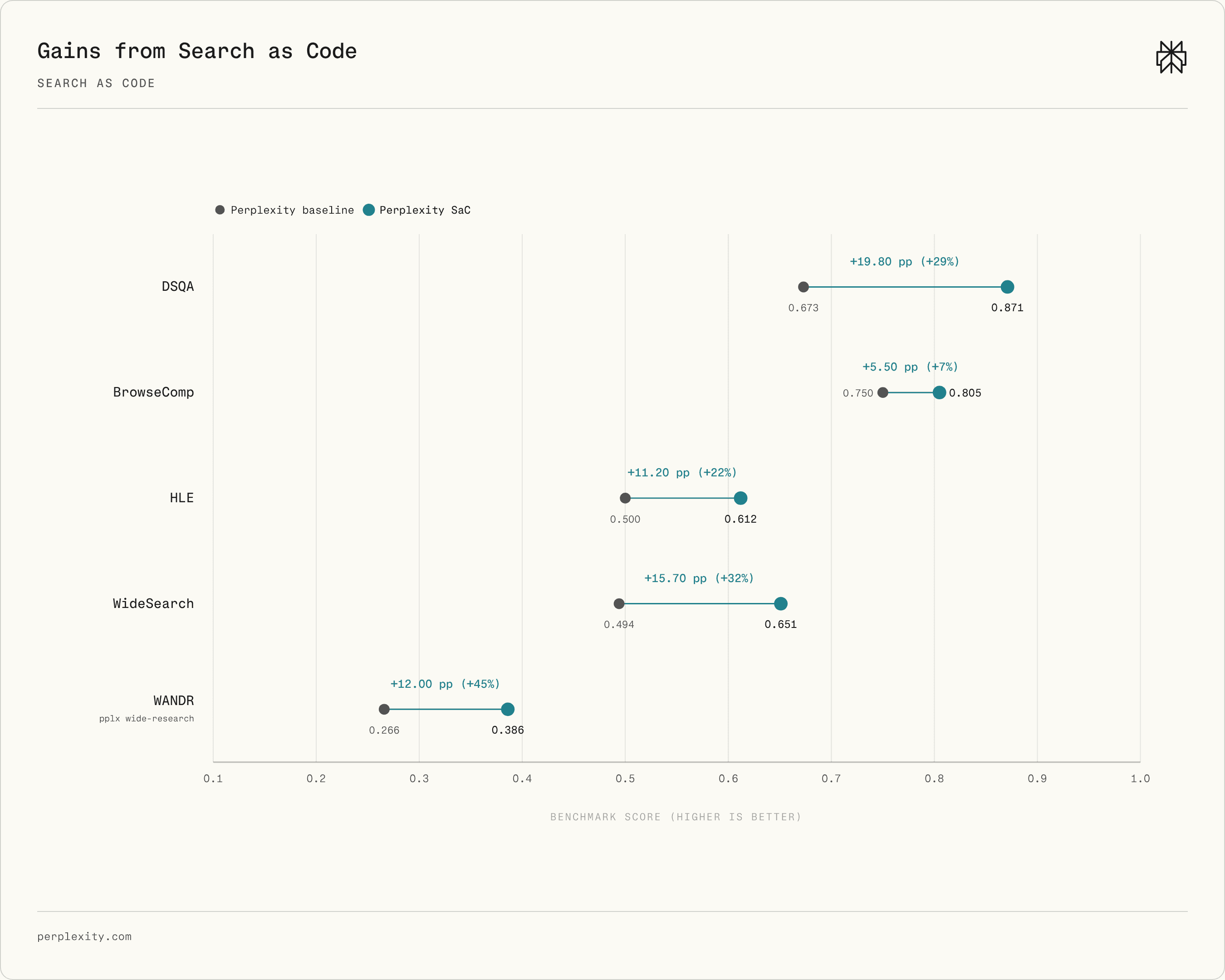
Perplexity's official Figure 6 compares SaC with a non-SaC baseline on the same Perplexity search infrastructure. The company reports +19.77 percentage points on DSQA and +12.00 percentage points on WANDR, with a 45% relative gain on WANDR.
Sandbox state uses files instead of a REPL
One of the more practical design choices in SaC is sandbox state management. Perplexity describes a scenario where an agent fetches documents in one turn, inspects selected documents in a later turn, and then builds another pipeline from the results. Passing all intermediate state through tokens inflates context and introduces noise. SaC needs the sandbox to carry state between steps.
Perplexity compared two approaches. The first uses a persistent filesystem with explicit serialization and deserialization. The model saves intermediate state to files and explicitly reads it in the next turn. The second uses a REPL model, where the runtime remains alive and later turns can refer to variables created earlier. A REPL is token efficient, but long notebook-like trajectories can make namespace state hard to audit.
Perplexity says both approaches behaved similarly in normal usage, but filesystem-based serialization was more reliable on long trajectories. SaC therefore uses explicit state transfer. That is a conservative choice for observability. Files can preserve search strategies, candidate lists, and verification results in a form people can audit. REPL-only state makes it harder to reconstruct which intermediate result affected the final answer.
Perplexity's sandbox documentation describes the Agent API sandbox as an isolated container for model-executed code. The sandbox tool is in preview, and availability, quotas, and pricing may change. Documented use cases include web search, numeric calculations, data cleaning, parsing, code execution, structured artifact generation, and multi-step workflows with intermediate files. SaC moves that sandbox into the center of retrieval-pipeline execution.
Cost is more than tokens
SaC highlights token savings, but production cost has to include model tokens, sandbox sessions, and tool invocations. Perplexity's pricing documentation says Agent API offers third-party models at direct provider rates with no markup. Model token cost still varies by provider and model. Tool cost is separate.
In the documented Agent API pricing, web_search costs $0.005 per invocation, fetch_url costs $0.0005, and people_search and finance_search each cost $0.005. sandbox costs $0.03 per session. A sandbox session is a single isolated container lifecycle with up to 20 minutes of active use as the billing window. The docs describe that as a billing window rather than a runtime cap. SDK search queries run inside the sandbox are billed like web_search at $0.005 per request.
That pricing structure makes adoption decisions workload-specific. If repeated tool calls inflate the model context and reasoning token budget, SaC can become cheaper. In the CVE case study, an 85.1% token reduction could offset sandbox and search invocation fees. For tasks that only need a few searches, the $0.03 sandbox session plus multiple SDK search calls can be more expensive than a simpler path. Engineering teams need cost traces by task class, not one aggregate agent-search number.
This is not the end of MCP
Perplexity's article explicitly discusses the limits of function calling and MCP-era tool design. If every search operation requires a full LLM inference round trip, developers are pushed to request as many results as possible in each call, which recreates a large end-to-end search pipeline. SaC tries to reduce that serial I/O. It does not mean MCP or function calling disappears.
MCP and function calls still work well for external system boundaries. CRM, ticketing, code hosting, calendar, and database tools need clear interfaces for permissions and audit. SaC targets the internal control surface of a search stack. Instead of exposing only one query endpoint, it lets an agent combine search primitives into a task-specific retrieval pipeline.
That distinction belongs in architecture review. A tool that calls a SaaS API should be designed around permission, rate limit, and data policy. A SaC-style runtime should be reviewed around intermediate state, code execution safety, result verification, and cost accounting. Reading SaC as "run every tool as code" would blur security boundaries. Perplexity's separate secure sandbox layer is part of the design for that reason.
Agent API strategy is visible too
Perplexity's Agent API quickstart describes the API as a multi-provider, interoperable API specification. It supports models from OpenAI, Anthropic, Google, xAI, and others behind one API, with integrated real-time web search, tool configuration, reasoning controls, and token budgets. The primary endpoint is POST https://api.perplexity.ai/v1/agent, and the API also accepts a POST /v1/responses alias for OpenAI SDK compatibility.
SaC strengthens that Agent API position. Perplexity is not only telling developers to attach its search API to an LLM. It is letting a multi-provider model manipulate Perplexity's search stack through lower-level primitives. In the research article's benchmarks, Perplexity SaC uses GPT 5.5 high reasoning as the underlying model. Even when the model provider is not Perplexity, Perplexity can differentiate through the search runtime, sandbox, and SDK.
That strategy overlaps with AI-facing search providers such as Exa, Tavily, Brave Search API, and SerpAPI. It also touches agent runtimes such as OpenAI Responses with web_search and code_interpreter, Anthropic Managed Agents, Parallel Tasks, and Exa Agent. Perplexity's stated difference is not "we return search results." It is "the agent orchestrates the search stack as code." Public benchmarks and third-party evaluations will determine how often that distinction holds in customer workloads.
What teams should check before adopting the pattern
Teams considering a SaC-like design should start by separating task classes. Single-answer queries, source-checking research, wide searches with hundreds of queries, and investigations that need strict verification have different cost and risk profiles. Sending every search task into sandboxed code can add latency and cost to simple work. Forcing wide research through serial tool calls can increase context compaction, duplicate fetches, and opaque state.
The second item is intermediate-state audit. SaC chooses file-based serialization. Internal products should likewise record which query patterns the agent generated, which URLs it discarded, and which evidence it used in the final answer. In security, finance, legal, healthcare, and enterprise procurement workflows, "the agent searched" is not enough. Reviewers need to know why a source was trusted and why another source was excluded. Code can preserve those decisions, but only if logging and review UI expose them.
The third item is sandbox policy. Retrieval pipeline code may perform deterministic operations, but it is still code execution. Teams need network-access boundaries, file-retention rules, secret isolation, package-import limits, timeouts, retry behavior, and billing guardrails. Perplexity's docs say sandbox errors return as sandbox_results items and distinguish timeout, runtime error, quota, and limit cases. Production agents should route those errors into retry and human-review conditions instead of hiding them inside a confident final answer.
The fourth item is benchmark interpretation. Perplexity's numbers are a signal that SaC is worth studying, but WANDR cannot be independently reproduced before publication. External benchmarks such as DSQA, BrowseComp, HLE, and WideSearch also differ from any one company's corpus. Teams should build eval sets from customer tickets, internal documents, code search tasks, vendor advisories, and policy memos. The relevant question is not only whether the model is smarter, but whether the search process is assembled and verified for the task.
Search becomes the evidence layer before agent action
The practical value of Perplexity Search as Code is that it moves search from a helper feature into the evidence layer an agent uses before acting. Quality depends on which evidence the agent retrieved, how it compared that evidence, and which intermediate results it discarded. A product where a person scans 10 search results and a product where an agent executes thousands of retrieval operations over several minutes should not rely on the same search interface.
For developers, the announcement leaves two concrete questions. First, is the agent's search failure caused by weak queries, or by insufficient control over the search pipeline? Second, can repeated tool-call tokens and latency be reduced with code execution and explicit state management? Perplexity's answer is SaC: the model composes search primitives in Python, the sandbox runs deterministic compute, and the SDK exposes lower-level handles into the search stack.
At this stage, SaC remains an architecture and benchmark package presented by Perplexity. WANDR publication, outside replication, real pricing traces, and sandbox preview stability remain open checks. Still, teams building on Agent API, Perplexity Computer, or deep research agents should not treat this as a minor search feature. Agent search is moving from "call a search API once" toward "design, execute, and verify a search program."