CUDA 13.3 adds a new tuning lever for LLM inference
NVIDIA CUDA 13.3 targets the lower layers of LLM inference cost with CompileIQ compiler tuning and CUDA Python 1.0.

- What happened: NVIDIA released
CUDA 13.3and introducedCompileIQ.- The official announcement landed on May 26, 2026, alongside CUDA Tile C++, CUDA Python 1.0, and C++23 support.
- Key numbers: NVIDIA says GEMM and attention account for more than 90% of LLM inference compute.
- CompileIQ showed up to a 15% speedup on already optimized Triton attention and CUTLASS GEMM kernels.
- Why it matters: Under model pricing, compiler heuristics and Python GPU runtime controls are becoming part of the real cost table.
- Watch: This is not automatic magic. It needs strong benchmarks and already tuned kernels to find the last performance margin.
NVIDIA has released CUDA 13.3. On the surface, this looks like the kind of toolkit update GPU developers expect: CUDA Tile C++ support, CUDA Python 1.0, C++23 support, CCCL 3.3, and updates across cuBLAS, cuSPARSE, and cuSOLVER. From an AI infrastructure perspective, the sharper story sits lower in the stack. NVIDIA is pulling part of the remaining LLM inference bottleneck down into the compiler decisions that shape machine code.
The key term is CompileIQ. NVIDIA describes it as a compiler auto-tuning framework for GPU kernels. A general-purpose compiler applies default heuristics that work reasonably well across many workloads. Choices such as register allocation, instruction scheduling, and loop transformation are not freshly optimized for every single production kernel. CompileIQ challenges that default. A user defines a benchmark objective, then evolutionary and genetic algorithms search through compiler configurations and leave the best-performing settings in an advanced controls file.
The reason this becomes AI news is in NVIDIA's numbers. The company says GEMM and attention account for more than 90% of LLM inference compute. It also says CompileIQ delivered up to 15% speedups on already optimized Triton attention and CUTLASS GEMM kernels. A 15% number can look modest next to model benchmark headlines. In a large inference cluster, it is not modest. It can mean more tokens from the same GPUs, the same traffic served with fewer accelerators, or a larger batch kept inside the same latency budget.
The layer below the model price sheet
In 2026, AI teams spend a lot of time staring at model price sheets. Input tokens, output tokens, batch discounts, cache hit rates, context windows, and reasoning effort all shape product decisions. The real cost sheet, however, lives below that surface. Attention kernels, MLP GEMMs, KV-cache movement, kernel launch overhead, and compiler-generated machine code all determine what inference actually costs.
Many teams have already taken the obvious optimization paths. They quantize models, tune batching, use FlashAttention-style kernels, and split tensor and pipeline parallelism carefully. After that, the profiler often points to a small number of kernels that dominate runtime. At that point, the fight moves from "use a better kernel" to "find better code generation for a kernel that is already good."
CompileIQ fits exactly there. NVIDIA's CompileIQ deep dive explains that many compiler parameters are not exposed as public flags. Developers write an objective function. For example, it can compile a kernel with one candidate compiler configuration, run a benchmark, and return runtime, power, or another score. CompileIQ searches the configuration space for better candidates. The result is saved as an ACF file, which the compiler can apply with --apply-controls.
That design is interesting because it moves performance work outside the source code. Until now, AI inference optimization has mostly been discussed through kernel code, framework graphs, runtime scheduling, and hardware topology. CUDA 13.3 adds another layer: compiler heuristics can become a versioned artifact. A team can commit an ACF file next to a kernel, test it against a specific workload, and include it in a deployment pipeline.
What CompileIQ actually automates
It would be too broad to summarize CompileIQ as "AI tunes the compiler for you." The actual claim is narrower, which makes it more practical. NVIDIA says CompileIQ has been validated on GPU and CPU targets for production workloads, with examples showing up to 15% gains on TritonBench and Helion kernels. It also draws a clear boundary: this is not a tool that magically turns poorly written code into high-performance code.
That distinction matters. CompileIQ does not rescue a weak kernel. It searches for combinations that default compiler heuristics missed in kernels that are already fairly well optimized. Many development teams can experiment with a few compiler flags. Far fewer teams routinely explore internal compiler parameter spaces over generations, select candidates from benchmark results, and repeat mutation and crossover as part of inference engineering.
NVIDIA says the search result is stored as an ACF file. That file can become part of code review and version control. For inference platform teams, this is a meaningful shift. The result of performance tuning does not have to remain a local experiment on one engineer's machine. It can become a reproducible deployment artifact, much like model weights, kernel source, container images, driver versions, and CUDA versions.
There are risks. If the benchmark does not represent production traffic, CompileIQ can optimize the wrong thing. If the only objective is fastest runtime, power consumption, compile time, binary size, stability, or tail latency can get worse. That is why NVIDIA emphasizes multi-objective optimization and Pareto frontiers. In large AI inference systems, the best single run is less important than the balance among power, latency, throughput, and reproducible deployment.
CUDA Python 1.0 has a quieter infrastructure meaning
If CompileIQ targets performance hotspots, CUDA Python 1.0 targets the operational surface. NVIDIA released CUDA Python 1.0 with a semantic versioning commitment: breaking API changes only in major releases, feature additions in minor releases, and bug fixes in patch releases. For AI builders, that is more than a version number. Python is the center of GPU serving experiments, data pipelines, and model operations. A stable API surface for controlling CUDA runtime behavior is useful precisely because Python sits so close to production AI workflows.
The announcement says cuda.core provides Pythonic interfaces for devices, streams, programs, linkers, memory resources, and graphs. It also adds green contexts, CUDA checkpointing, and IPC. Each feature maps directly to problems in AI serving.
Green contexts let developers partition GPU streaming multiprocessors and assign contexts and streams to those partitions. That can help protect latency-sensitive kernels from long throughput-oriented kernels. When interactive inference and batch jobs share the same GPU, this kind of isolation can help with tail latency.
Process checkpointing snapshots CUDA process state such as device allocations, streams, and contexts so it can later be restored. NVIDIA says this is Linux-only. The direction connects to preemption, migration, fault tolerance for long jobs, and warm-starting inference workers. One expensive part of AI infrastructure is restarting a GPU process and warming models and caches again. If checkpoint and restore matures, the operational model for GPU workers can change.
IPC matters as well. If Python processes can share GPU memory without routing data back through host memory, multi-process serving and producer-consumer pipelines can reduce copy overhead. None of this is as flashy as a new model, but it directly affects product latency and GPU utilization.
The boundary between Python and C++ gets thinner
CUDA 13.3 is not only about Python. It also brings CUDA Tile programming in C++. CUDA Tile abstracts lower-level details such as parallelism, memory movement, and asynchrony so developers can write tile-based kernels at a higher level. If the earlier CUDA Tile flow was centered on more limited environments and specific backends, C++ support brings the idea closer to existing CUDA C++ codebases and developer workflows.
AI kernel work already moves between Python and C++. Researchers experiment in Python with PyTorch, JAX, CuPy, and Triton. When performance matters, the stack often drops into CUDA C++, CUTLASS, or custom extensions. The hard part is that this boundary is fragile. Tensors live in a Python framework, while high-performance kernels deal directly with pointers, strides, and shared memory views. If shape, stride, dtype, ownership, or lifetime are wrong, both performance and stability suffer.
CCCL 3.3's DLPack and mdspan interoperability helps clean up that boundary. The announcement explains that tensors from frameworks such as PyTorch, JAX, and CuPy can be converted into cuda::std::mdspan views and then passed back through DLPack. Inside C++ kernels, developers can also create multi-dimensional shared-memory views, which makes indexing easier to reason about. That reduces the cost of moving from AI research code toward production kernels.
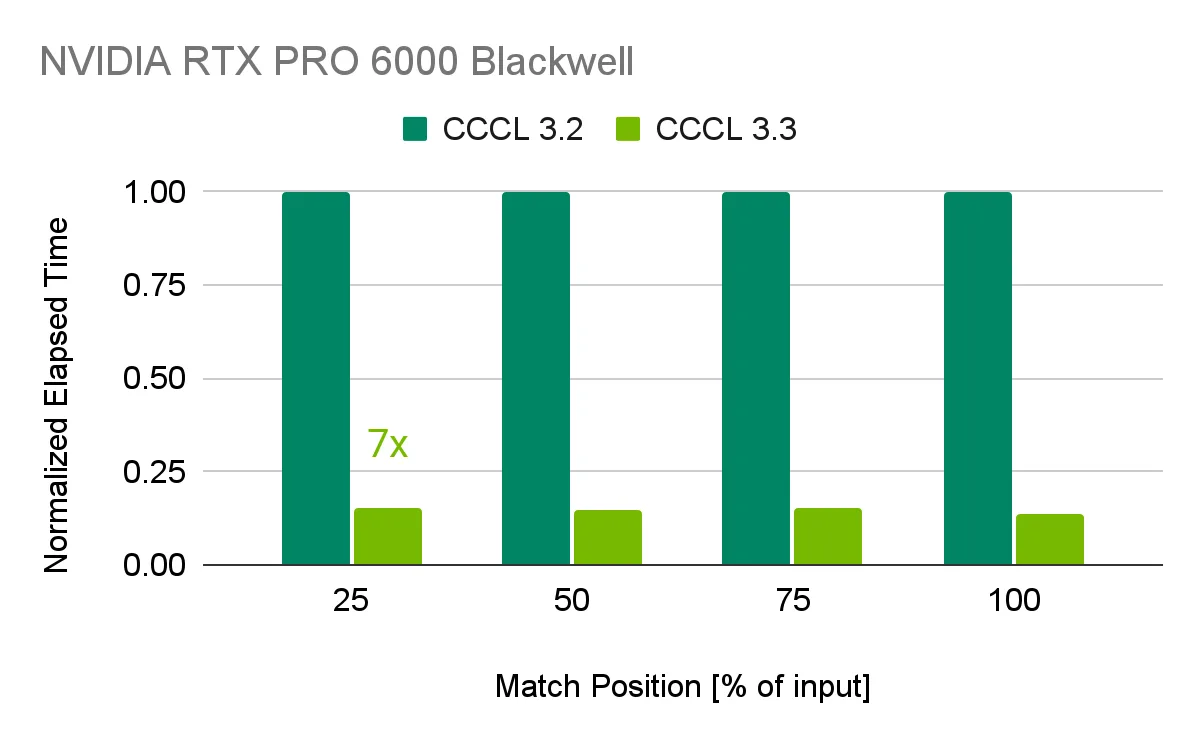
The chart also shows another axis of CUDA 13.3. CCCL 3.3's search algorithm improvements can look like a narrow API-level speedup, but these low-level primitives appear repeatedly in AI and HPC code. NVIDIA says cub::DeviceFind::FindIf is up to 7x faster than the search implementation in CCCL 3.2. Even when a primitive is not directly on the central LLM inference path, data preprocessing, retrieval, simulation, and sparse workflows can accumulate this kind of cost.
Why compiler tuning is showing up now
NVIDIA's timing is tied to the shape of the market. Frontier model companies and AI application companies can no longer treat GPU access as the whole strategy. Product competitiveness increasingly depends on how densely a team can use the GPUs it already has. While accelerator supply remains constrained and expensive, extracting another 5%, 10%, or 15% from existing hardware is effectively a capacity increase.
LLM inference also behaves differently from training. Training runs large jobs for long periods, where throughput and stability dominate. Inference deals with changing traffic, latency SLOs, cache hit rates, and shifting batch shapes. In that environment, the average speed of one kernel is not enough. Teams also need reproducibility and tail-latency behavior across shapes. Even if compiler tuning is automated, real deployment still has to consider shape profiles, model hotspots, hardware generations, power caps, driver versions, and CUDA versions.
CompileIQ does not remove that complexity. It creates a new operational object for performance engineering. Teams have to decide when to generate ACF files, which benchmarks validate them, and which hardware targets should apply them. A CUDA upgrade may require a new search. A kernel source change may make the old ACF no longer optimal. That is not only bad news. Once an artifact is managed, it can be automated, reviewed, and rolled back.
Practical questions for engineering teams
Not every team should immediately adopt CompileIQ because CUDA 13.3 shipped. If a product relies on hosted model APIs, this change may only show up indirectly through future price, latency, rate-limit, or capacity improvements from model providers. OpenAI, Anthropic, Google, xAI, Mistral, and other providers may use similar lower-layer optimizations internally without exposing them to application developers.
Teams running their own inference stack have more concrete questions. If you operate vLLM, TensorRT-LLM, Triton, custom CUDA extensions, or CUTLASS kernels, the first question is which kernels dominate your workload. The second is whether your benchmark represents real traffic shapes. The third is whether you care only about speed, or also power, compile time, binary size, and tail latency. The fourth is whether your deployment process is ready to treat compiler tuning artifacts as source-controlled infrastructure.
CUDA Python 1.0 raises similar questions. Teams that directly control GPU runtime behavior from Python may benefit from stable APIs and semantic versioning. But easier runtime control also creates responsibility. Poorly chosen green-context partitioning can starve a workload. Checkpoint and restore can complicate recovery if the failure boundaries are not understood. GPU memory IPC can reduce copies, but it also makes lifetime and ownership bugs harder to debug if the process model is vague.
The competition is moving outside the model
CUDA 13.3 is not a model release. It is not a new LLM or a new AI app. It still matters because AI competition keeps expanding outside the model. When models cluster near similar capability bands, the practical differences show up in serving cost, latency, reliability, observability, and deployment flexibility. Those properties connect to compilers, runtimes, libraries, schedulers, and hardware features.
NVIDIA is a GPU vendor, but it is also an AI software stack vendor. CUDA, cuBLAS, CUTLASS, TensorRT-LLM, Triton integration, NIM, Nsight, and Run:ai are not just accessories for selling GPUs. They are an operating environment that makes AI companies keep building around NVIDIA hardware. CompileIQ makes the compiler layer a more explicit product surface inside that stack.
AMD ROCm, Intel oneAPI, and open-source Triton and MLIR ecosystems face the same pressure. AI teams want code that runs across hardware and clouds, not only code that is fast on one vendor path. But as inference cost grows, vendor-specific optimization becomes harder to ignore. CUDA 13.3 makes the dilemma clearer: portable abstractions matter, but the last 15% may require going deep into a vendor compiler and hardware feature set.
Conclusion: 15% is not a small number
The news value of CUDA 13.3 is not just that it has many features. More precisely, it shows how low the LLM inference cost table now reaches. NVIDIA puts GEMM and attention at the center of inference compute and turns compiler heuristic search into a product. At the same time, CUDA Python 1.0, green contexts, checkpointing, and IPC refine the operational surface for Python-based GPU serving.
Most developers may not touch this directly. Someone calling ChatGPT, Claude, or Gemini does not see CompileIQ. Behind the scenes, however, someone is shaving 1% from an attention kernel, rethinking batch shapes, warm-starting GPU workers, and versioning compiler artifacts. The price, speed, and usage limits of AI products are the sum of those decisions.
That is why CUDA 13.3 is quiet but important AI infrastructure news. As models get larger and agents run longer, "how cheaply can we produce useful tokens?" becomes a more important question. The answer is not only in model architecture. As this release shows, part of the answer sits in which instructions the compiler chooses, how the Python runtime partitions GPU context, and how little copying a library primitive requires. The new tuning lever for the 90% LLM inference bottleneck is rising from below the model layer.