100 Models Are Heading to the Pixel TPU, but On-Device AI Still Has a Narrow Gate
Google Tensor SDK Beta opens a LiteRT path to the Pixel 10 TPU, pairing 100+ models with the harder problem of shipping on-device AI.
- What happened: Google Tensor ML SDK moved to
Beta, opening a LiteRT deployment path for the Pixel 10 TPU.- The supported devices are Pixel 10, 10 Pro, 10 Pro XL, and 10 Pro Fold, while Google is pairing the SDK with 100+ models and Gemma 3 1B.
- Why it matters: On-device AI can start moving beyond OS-owned demos and into product features shipped by third-party Android apps.
- Watch: Pixel 10-only support, model licenses, TPU fallback, and Play delivery mechanics are the real adoption bottlenecks.
- The hard part is not only "running a model on a phone"; it is fitting compile, delivery, execution, and fallback into an app operations loop.
Google's May 19, 2026 Developers Blog post, Google Tensor SDK Beta with LiteRT, could look small next to the larger Gemini news around Google I/O. For Android app teams and on-device AI builders, though, it is a practical shift. Google Tensor ML SDK has moved from the Experimental Access Program into Beta, giving external developers a more official path to convert, compile, deliver, and run models against the Tensor TPU inside the Pixel 10 family.
The point is not simply that "Pixel can run AI models." Google has already shipped on-device AI features such as Pro Zoom, Add Me, Voice Translate, and Call Notes inside Pixel experiences. The more important question is who gets to use that hardware. Until now, Pixel AI has mostly meant Google-built product surfaces. This beta says third-party apps can begin treating the Pixel TPU as part of their own feature architecture.
Google frames the beta around two openings. The first is an integrated development workflow tied to LiteRT. The second is a model garden with more than 100 models prepared for optimized execution on Tensor TPU. That set includes generative models such as Gemma 3 1B, smaller language-model families such as Function Gemma and EmbeddingGemma, and vision and audio models. Together, those pieces suggest on-device AI is moving from demo territory into something closer to an app-shipped deployment unit.
Why Pixel TPU Access Is News
On-device AI is an old promise. The value proposition is clear: keep private data off the server, respond without network latency, and keep features working when the user is offline. The recurring problem has been developer experience. Models are often trained in PyTorch, mobile apps ship in Kotlin, Java, Swift, or JavaScript-adjacent stacks, and inference happens across CPUs, GPUs, NPUs, TPUs, Neural Engines, and vendor runtimes. If the compiler, runtime, driver, model format, packaging rule, or device policy slips out of alignment, a product feature breaks.
Google is positioning LiteRT as a common framework to narrow that gap. In the announcement, Google describes LiteRT as its edge framework for high-performance on-device ML deployment, abstracting low-level vendor SDKs, compilers, and runtimes behind developer-facing APIs. With Tensor ML SDK integrated into LiteRT, developers can convert PyTorch or TFLite models through LiteRT Torch, compile them into binaries for Tensor TPU, deliver runtime and model files through Play Feature Delivery and Play for On-device AI AI Packs, and call TPU inference from the LiteRT Runtime.
That workflow sounds complicated because the problem is complicated. A cloud-backed AI feature mostly asks a team to manage a server-side model endpoint, authentication, cost, and latency budgets. An on-device AI feature also asks the team to think about app packaging, accelerator availability, runtime compatibility, model size, battery use, fallback behavior, and Play delivery policy. The fact that Google describes compile, delivery, and execution as one linked path is itself the news. On-device AI has moved beyond "put a model file in the app."
The Model Garden Matters More Than the Number
Google AI Edge's Model Garden documentation makes the announcement more concrete. The docs describe a collection of machine learning models for vision, text, and audio use cases, optimized to deliver on-device performance on Pixel devices with Google Tensor SDK. The listed range is broad: depth estimation, face reconstruction, image and text understanding, image classification, image segmentation, object detection, pose estimation, speech recognition, super resolution, and text classification.
The number "100+" is useful shorthand, but it is not the most interesting part. The garden mixes classic ML models with generative models. Image classification includes EfficientNet, MobileNet, and ResNet-style families. Speech recognition includes wav2vec2-style models. The blog post also calls out Gemma 3 1B for generative AI, Function Gemma for app interactions, and EmbeddingGemma for semantic features.
That mix maps closely to how real on-device AI apps are likely to work. Users do not only want a chatbot inside the phone. They want camera frames understood, images segmented, speech transcribed with low latency, short local commands turned into function calls, and personal content organized into semantic vectors. Unlike a cloud design where one large LLM might absorb many tasks, mobile on-device AI is more likely to become a pipeline of small task-specific models.
| Layer | What Google is offering | Product meaning |
|---|---|---|
| Models | 100+ classic ML models, Gemma 3 1B, Function Gemma, EmbeddingGemma | Small feature models can spread through the app, not just a chatbot surface. |
| Compile | Convert PyTorch or TFLite models with LiteRT Torch | Research models get a route into Pixel TPU binaries. |
| Delivery | Play Feature Delivery, Play for On-device AI, AI Packs | Models and runtimes become part of release operations. |
| Runtime | LiteRT Runtime, TPU-first execution, CPU/GPU fallback | Service quality must account for device state and compatibility. |
The most operationally important line in that table is fallback. Google says developers can specify CPU or GPU as secondary options in LiteRT Runtime, and the runtime will use them depending on TPU availability. Strong products cannot only work on the ideal device path. If the TPU is unavailable, a model does not fit the TPU route, or battery and thermal state are unfavorable, the feature still needs to behave predictably. For on-device AI, reliability depends on fallback policy almost as much as model accuracy.
The Bottleneck Google Is Finally Opening
This beta matters because Google has understood this problem for a long time. Pixel devices use Google Tensor SoCs. Google has LiteRT, Gemma, and AI Edge Gallery. Yet the answer to "can an outside developer easily target the Pixel TPU?" has been less clear than the hardware story suggested. In April 2026, Beebom criticized the state of on-device AI testing on Android, arguing that Google's own Tensor SDK was still tied to experimental access and that public TPU plugin paths were limited enough to push testing back toward CPU or GPU execution.
That critique does not need to be accepted wholesale. Mobile on-device AI joins chip access, runtime stability, app distribution, security, and licensing in one surface, so a cautious rollout is understandable. But from a developer's point of view, accessible APIs, samples, model catalogs, and delivery docs matter more than the mere existence of hardware. This beta is a marker because Google is no longer only saying that Pixel runs Google-built AI features well. It is telling external apps to prepare models for the Pixel TPU.
The gate is still narrow. Supported devices are Pixel 10, Pixel 10 Pro, Pixel 10 Pro XL, and Pixel 10 Pro Fold. In the broader Android ecosystem, Pixel is closer to a reference device than a universal target. The actual market includes Qualcomm, MediaTek, Samsung, and other accelerator stacks. Even if LiteRT abstracts vendor-specific SDKs, the direct value of Tensor SDK Beta begins with the Pixel 10 family. App teams will need to decide whether to build a premium Pixel path, keep a conservative CPU/GPU path for wider Android coverage, or split implementation across platforms.
A Different Product Sense From Cloud Agents
Recent AI developer news has been dominated by coding agents, managed agents, cloud sandboxes, and long-running workflows. Against that backdrop, on-device AI can look like a smaller story. Product experience points in the other direction. Many AI features users touch every day happen around the camera, microphone, keyboard, notifications, accessibility features, and personal data. These surfaces care less about long reasoning traces and more about immediacy.
Consider an accessibility tool that transcribes speech, a camera app that understands frames, a photo tool that segments a background, or a productivity app that semantically searches local documents. Users do not want to stare at a "thinking" state for those workflows. Latency changes the character of the feature. Privacy does too. Some data can be sent to the cloud conveniently; other data becomes more trustworthy when it never leaves the device. This is why Google's announcement keeps interactive, real-time, and private experiences close together.
Still, "on-device" should not be treated as a synonym for safer, cheaper, or simpler. Putting a model inside an app can slow updates, inflate storage requirements, complicate release management, and force QA across device-specific performance profiles. Licensing also matters. Google AI Edge Model Garden entries can carry different license states, including Apache-2.0, MIT, BSD, GPL, AI-HUB-MODELS, and cases where no license file is present. For an enterprise app, "available in the model garden" is not the same as "ready to ship in our product."
Why Hugging Face Is Part of the Story
Google's mention of the Hugging Face LiteRT community is also important. The official post says developers can download precompiled model libraries directly from the LiteRT Hugging Face community. The Hugging Face litert-community model page already exposes LiteRT-compatible models such as Gemma3-1B-IT, Whisper, MobileNet, EfficientNet, and ResNet.
That means on-device AI delivery is not confined to a single vendor documentation site. Model discovery and distribution already flow through Hugging Face. Even if Google opens the hardware and runtime path with Pixel TPU and LiteRT, developers may still discover, compare, and fetch models from Hugging Face. For Google, that broadens the model ecosystem around its runtime. For developers, it means they can test more than the curated samples Google selects.
The tradeoff is distributed responsibility. Teams need to know where a model came from, what license and quantization it carries, which Pixel devices it has been measured on, what latency and memory footprint it has, and how much quality changes when fallback execution kicks in. A cloud model API abstracts much of that away behind the provider. The on-device model ecosystem hands more operational judgment back to the app team.
What Android Teams Should Check
If an Android app team wants to treat this beta as a product planning signal, the first move is narrowing the feature scope. Good candidates are features where a cloud round trip hurts the user experience: camera-preview segmentation, offline voice commands, accessibility transcription, local document embedding, or turning user actions into quick local function calls. Large reasoning tasks, current-knowledge retrieval, long-form generation, and complex coding assistants may still fit cloud models more naturally.
The second question is the delivery unit. Google mentions Play Feature Delivery and AI Packs. That is more flexible than freezing a model into the app binary and calling the job done, but it also means product and release teams need a model versioning plan. Will model updates follow app release cadence? Will they be served only to specific device families? What fallback UI appears if delivery fails? How do A/B tests, crash reporting, and performance monitoring attach to model delivery?
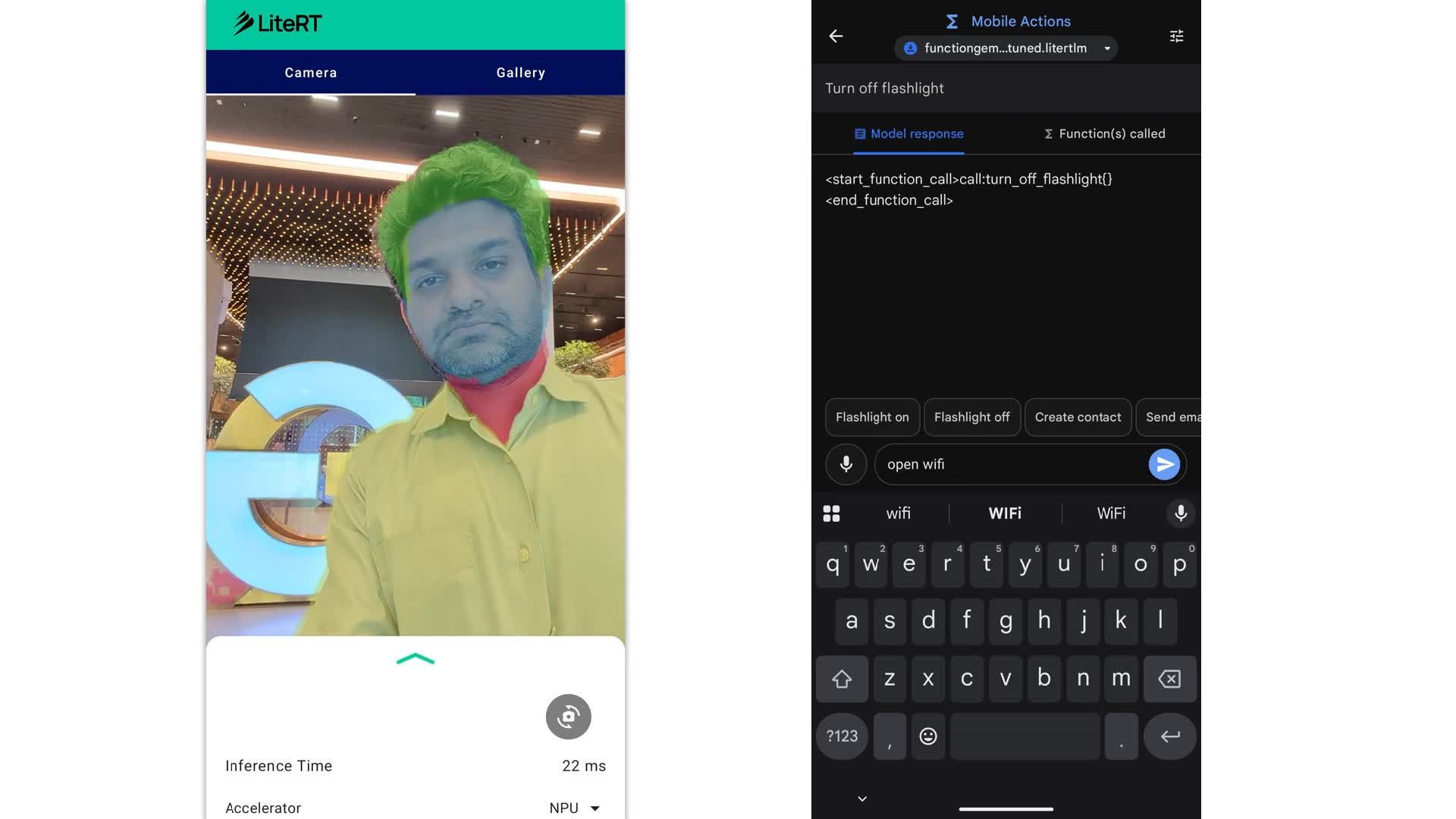
The third question is measurement. A model that gets faster on Pixel TPU does not automatically make the whole app faster. Teams still need to measure camera frame preprocessing, model load time, warm-up, memory pressure, battery impact, thermal throttling, and fallback transition time. Google's demo choices are telling: an image segmentation sample app and Function Gemma mobile actions. Both are workflows where users directly feel latency.
The fourth question is a multi-vendor strategy. Building only for Pixel TPU constrains coverage across Android. LiteRT may abstract vendor-specific SDKs, but Tensor SDK Beta most directly targets the Pixel 10 family. Product teams need to decide whether Pixel gets a premium path, whether other Android devices degrade to CPU/GPU or a different NPU stack, and whether iOS needs a separate Core ML implementation.
The Competitive Frame: Distribution Beats Model Intelligence
Apple has pushed Core ML and Neural Engine for years. Qualcomm points developers toward AI Engine Direct and AI Hub for Snapdragon NPU paths. Meta and the PyTorch ecosystem are advancing ExecuTorch for mobile and edge execution. Google's differentiator is the ability to link Android, Play, Pixel, LiteRT, Gemma, and the Hugging Face community into one flow. The fact that Play Feature Delivery and AI Packs are in the same announcement as the SDK matters. Google is trying to connect model execution to app distribution.
That advantage can also become a lock-in cost. A model optimized for Pixel TPU and shipped through a Pixel-friendly delivery stack can create a strong experience on Pixel, but expanding to broader Android and iOS adds abstraction work. The long contest in on-device AI may be less about which model is smartest and more about which delivery system works predictably across the widest set of devices.
What Google announced is the Pixel side of that contest entering public beta. It is still narrow, centered on the Pixel 10 family, and it leaves developers responsible for model behavior, licensing, runtime state, and fallback paths. Even so, the signal is clear. On-device AI is starting to move from OS-maker showcase features into third-party app features.
Conclusion: Small Models Create Big Delivery Problems
AI news usually leans toward bigger models, longer context windows, and stronger agents. Google Tensor SDK Beta with LiteRT points the other way: smaller models, closer to the user, with lower latency and more local control over private data. The delivery problem behind those small models is larger than it looks.
For this beta to matter in production, Google will need to answer more than sample-code questions. Developers will need predictable latency data across Pixel devices, clear quality expectations during fallback, reliable Play delivery and model update mechanics, and licensing and security guidance that enterprise teams can actually review. The number "100 models" is less important than whether one of those models can become a stable app feature next quarter.
The direction is clear, though. Google does not want the Pixel Tensor TPU to remain a chip only for internal Google features. By tying LiteRT, Model Garden, the Hugging Face community, and Play delivery together, it is opening a path for external developers to build on-device AI features. While cloud AI grows through agents and large-scale reasoning, mobile AI may settle into a quieter pattern: many small models running close to the user, inside the phone. Tensor SDK Beta is an early sign that this narrow gate is beginning to open.