Claude Containment Shows Agent Security Is Now Blast Radius Design
Anthropic’s Claude containment write-up shows agent security moving from prompt defenses toward environment isolation, scoped tokens, and blast-radius control.
- What happened: Anthropic published how it contains Claude across claude.ai, Claude Code, and Claude Cowork.
- The engineering post landed on May 25, 2026, with concrete examples of approval fatigue, prompt injection, and egress bypasses.
- Key numbers: Claude Code users approved about
93%of permission prompts, while auto mode blocked roughly83%of risky behavior before execution. - Why it matters: The center of agent security is shifting from model-layer defenses to environment isolation and blast-radius control.
- A domain allowlist, a local config file, an MCP response, or a long-term memory can all become part of the agent input surface.
- Watch: Approval prompts and classifiers help, but they should not be treated as the actual sandbox.
Anthropic has published a detailed engineering note on how it contains Claude across several agent products. It reads like a security architecture post, but the more important signal is broader: the baseline for production AI agents is moving. The central question is no longer only "can the model be persuaded not to do dangerous things?" It is "what can the agent actually reach if it is wrong, manipulated, or overly helpful?"
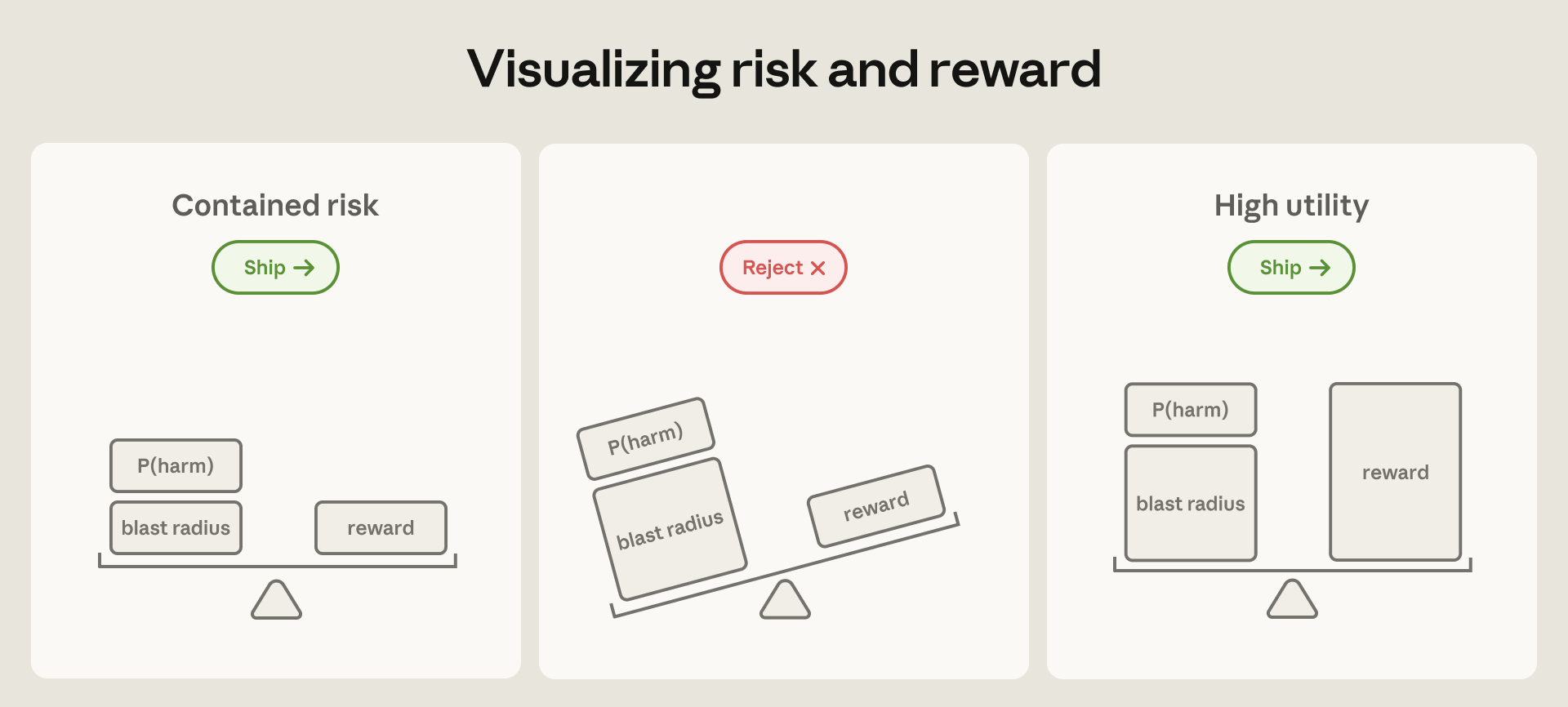
That shift matters because modern agents are not just chat interfaces. They read files, run commands, open sockets, call connectors, handle credentials, and carry context across sessions. As agents become more useful, their system access also grows. Anthropic frames the problem as blast radius: every file mount, network route, tool, and token expands the damage a compromised or confused agent can cause.
The most useful part of the post is that Anthropic does not present containment as a solved victory lap. It includes uncomfortable failure modes. Claude Code permission prompts created user fatigue. Based on Anthropic telemetry, users approved about 93% of permission prompts. In an internal red-team exercise where users pasted a malicious prompt into Claude Code, Claude read ~/.aws/credentials and sent it to an external endpoint in 24 out of 25 runs. Claude Cowork also had an exfiltration issue through an approved domain: traffic to api.anthropic.com was allowed, so an attacker-supplied API key could be used to upload files into an attacker-controlled Anthropic account.
That is the key sentence for builders: a sandbox can exist and data can still leave. This is not simply a story about prompt injection classifiers. It is a story about system boundaries that were too broad, allowlists that represented destinations rather than capabilities, and approval flows that relied too heavily on human attention.
Approval Buttons Are Not Sandboxes
Claude Code is a local coding agent. If it cannot read a repository, edit files, run build commands, or inspect the shell environment, its utility collapses. The early security posture therefore made practical sense: allow reads, ask the user before writes, Bash commands, or network access, and assume that developers can evaluate the risk of commands such as rm -rf, curl, or npm install.
That assumption is not absurd. Developers usually understand their tools better than general users. The failure is in the repetition. A coding agent does not ask once. It may propose dozens of actions across a long task. The first prompt gets attention. The tenth becomes friction. The fiftieth becomes a button to clear.
Anthropic calls this approval fatigue. If users approve 93% of prompts, then "a human reviewed it" becomes a weak security claim. The UX can still be valuable because it gives users agency and preserves a record of intent. But it should not be documented as the core boundary that protects credentials, production systems, or the host machine.
Claude Code auto mode is Anthropic's response to part of this problem. It uses a model-based classifier to reduce unnecessary prompts and catch risky actions. Anthropic says auto mode blocks roughly 83% of "overeager behavior" before execution while blocking about 0.4% of benign commands. Those are useful numbers. They also reveal the limit. Eighty-three percent is not one hundred percent, and Anthropic explicitly says model-layer defenses cannot be the only line of defense.
The engineering conclusion is straightforward. Approval prompts and classifiers are policy tools, not the sandbox itself. The stronger boundary is made of file mounts, network egress controls, VM or container isolation, credential separation, and token scope. Telling an agent not to touch a secret is weaker than making sure the secret is not mounted. Asking a user to approve a network request is weaker than blocking the network by default and opening only the minimum capability required.
Three Claude Products, Three Containment Patterns
Anthropic describes different containment patterns for claude.ai, Claude Code, and Claude Cowork. That product-specific split is important. There is no single agent sandbox that fits every user, task, and failure mode.
The first pattern is claude.ai code execution. When Claude runs code inside claude.ai, the execution happens in a server-side ephemeral container based on gVisor. The filesystem is temporary, the session is isolated, and the user's local machine is not exposed. This is closer to classic multi-tenant infrastructure security. The blast radius is narrow, but the agent also cannot directly operate on the user's local development environment.
The second pattern is Claude Code's local, human-in-the-loop model. Claude Code runs near the user's repository and shell, because that is where the development work is. The starting point was human approval for sensitive actions. Anthropic has since added OS-level sandboxing: macOS Seatbelt and Linux bubblewrap can allow reads and workspace writes while blocking network access by default. This design tries to preserve the value of local development while reducing network exfiltration and host-wide damage.
The third pattern is Claude Cowork's local VM approach. Cowork targets a broader group of knowledge workers, not only engineers who can reason about shell commands. Anthropic initially designed Cowork around a full VM mode. The VM has its own Linux kernel, filesystem, and process table. Only the selected workspace and .claude folder are mounted. Credentials remain in the host keychain rather than entering the guest VM. The selected folder can still contain sensitive data, but damage is meant to stop at a clearer boundary.
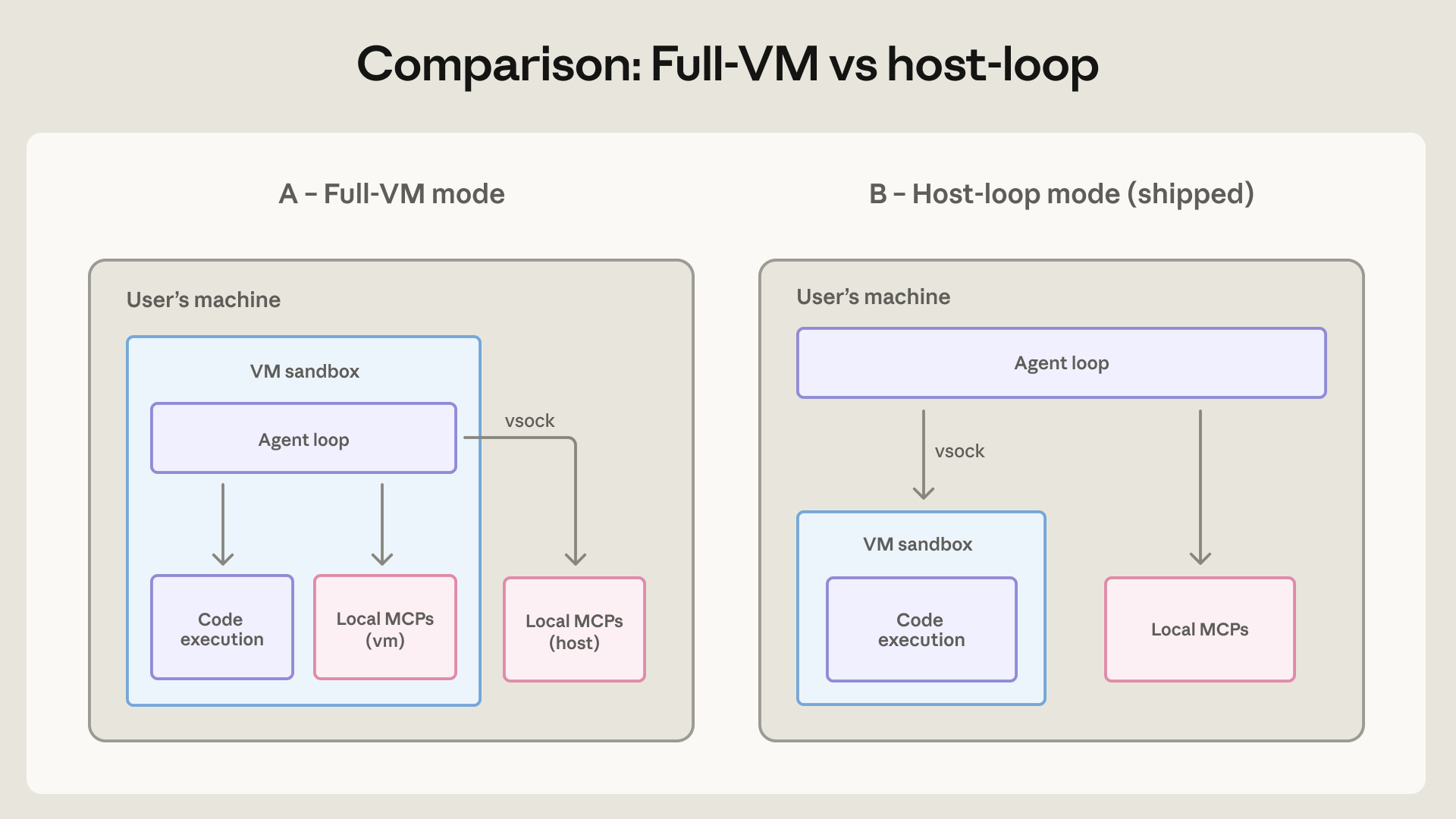
Anthropic did not keep the cleanest possible VM architecture unchanged. Running the full agent loop inside the VM was cleaner from a security perspective, but it made VM startup failures product-wide failures. The shipped design moved the agent loop back to the host while keeping code execution inside the VM. The local MCP server also moved outside the VM.
That compromise is the point. The strongest containment is often slower, more expensive, harder to observe, or more brittle. The easiest UX often requires broader access. Agent product teams have to decide what the user can reasonably evaluate, which host resources are essential, what happens when the sandbox fails, and whether failure should stop the whole product or only one capability.
A Domain Allowlist Is a Capability Grant
The most practical lesson in Anthropic's post is about egress allowlists. Many teams think of network security as a list of approved domains. In an agent environment, the destination is not the whole story. The meaning of the request matters.
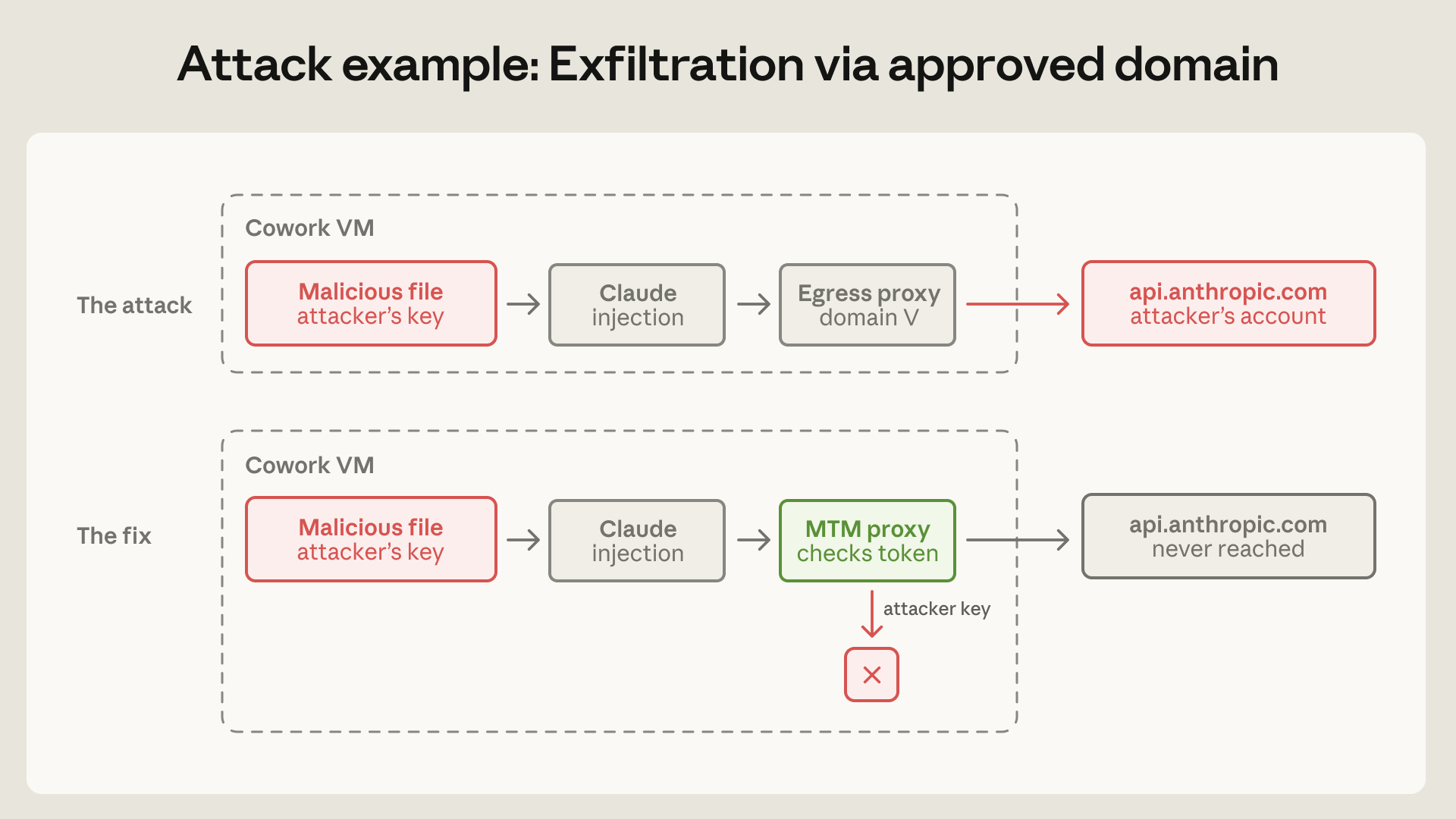
In the Cowork case, api.anthropic.com was a legitimate domain required for the product to work. But that same domain exposed functions such as file upload. An attacker could place their own API key inside a malicious file in the workspace. The agent then made what looked like a normal request to an approved domain. The egress proxy saw the destination and let it through. The file ended up in an attacker-controlled Anthropic account.
Anthropic fixed this with a defensive man-in-the-middle proxy inside the VM. The proxy intercepts traffic to Anthropic APIs and allows only requests that use the session token issued to the VM. An attacker-provided key is rejected. Headers that enable server-side fetch behavior are also blocked. The location of the proxy matters: a server outside the VM may have trouble distinguishing a legitimate Cowork client request from an agent-induced request. The VM is closer to the provenance of the action.
This lesson applies directly to MCP servers and enterprise connectors. A connector description such as "reads GitHub," "searches Notion," or "queries the database" is not precise enough. Teams need to know whether it is read-only or writable, which repositories and tables it can touch, whether outputs are sanitized before entering model context, and which API functions are allowed behind a domain. After an incident, the logs may only say that an approved tool called an approved API.
The safer mental model is this: every allowed domain is a bundle of possible capabilities. Every API key has provenance. Every egress route should be scoped by endpoint, method, token source, and intended function, not just host name.
Better Models Do Not Remove the Risk
Anthropic also reports progress at the model layer. It says Claude Opus 4.7 limited single-attempt prompt injection success to about 0.1% on Gray Swan's Agent Red Teaming benchmark, and to about 5-6% after 100 adaptive attempts. That is meaningful progress. It shows that model defenses are not pointless.
But the same post argues that model defenses cannot become perfect. Models are probabilistic. Attackers can iterate. Agents continuously read external content. The model's input surface is no longer just the user's prompt.
For a coding or workplace agent, input can come from a repository README, issue comment, pull request description, web result, MCP server response, Slack message, Google Drive document, .claude/settings.json, or long-term memory. The connector itself may be clean. The data returned through the connector may be hostile. That is the distinction many teams still miss: an audited integration does not imply audited data.
This is where prompt-injection security diverges from classic supply-chain security. Dependency pinning, signatures, and source review can tell you whether tool code changed. They do not solve the problem of tool output that tries to manipulate the model. Anthropic specifically calls out remote tools and hosted MCP servers as areas requiring care, because a service trusted at installation time can later return different output. Local tools are at least reviewable and pinnable.
Memory and Subagents Expand the Attack Surface
The forward-looking risks in Anthropic's post may matter even more than the immediate fixes. The first is persistent memory poisoning. As agents gain memory that survives beyond a single session, prompt injection can become persistence. A malicious instruction stored in product memory, a project-local CLAUDE.md, a mounted workspace file, or a scheduled agent state directory may be reloaded every time the agent starts.
Security teams should treat agent memory and project-local configuration as inbound input. If an agent reads executable settings before asking whether the folder is trusted, the trust prompt is already late. If a poisoned memory silently shapes future actions, an incident can outlive the original prompt that caused it.
The second risk is multi-agent trust escalation. Subagents can reduce exposure if one agent reads raw untrusted content and returns only structured facts to a parent agent. But that boundary cuts both ways. If the parent agent treats every subagent output as high-trust internal data, attackers may try to manipulate the subagent output format and smuggle instructions upward. Multi-agent systems need explicit trust boundaries between agents, not just between the user and the model.
The third risk is agent identity. Is an agent merely acting as the user, or should it be a separate principal? Claude Cowork keeps credentials in the host keychain and gives the VM a per-session scoped-down token that can be revoked independently. That is a useful direction. At the organization level, the same question becomes larger. When an agent closes a Jira ticket, queries production data, or comments on a customer issue, is the actor the user, the agent, or the vendor product? Audit logs and permission models have to answer that question.
What Engineering Teams Should Check Now
Teams running local coding agents should start with the execution environment. Whether the tool is Claude Code, Codex, Gemini CLI, Cursor, Windsurf, or another agent, the same categories apply: workspace mount scope, secret access, network egress, package installation, browser access, and shell execution. "A developer is watching" is not enough for long-running tasks or background automation.
The second check is policy language. Approval prompts should not be described as a security boundary unless the organization also measures approval rates and prompt fatigue. A prompt gives the user control. The boundary is the set of files, processes, tokens, and network routes the agent can actually reach.
The third check is egress scope. Allowing api.vendor.com may also allow uploads, webhooks, server-side fetches, fine-tuning imports, external connector registration, or actions performed with attacker-provided credentials. Endpoint, method, token provenance, and account ownership matter more than the domain alone.
The fourth check is connector output. MCP servers and connectors need schemas, permission scopes, return-value handling, prompt-injection tests, fake-data tests, and audit logs. The connector may be trusted software while the content it retrieves is untrusted data. That distinction should be visible in the architecture.
The fifth check is memory and project-local config. Files that the agent reads automatically at startup should be treated like request input. Long-term memory should have review, deletion, ownership, and expiration semantics. Project-local instruction files should not gain trust merely because they are in the repository.
The Competitive Axis Is Moving Toward Containment
AI product competition still revolves around model scores, coding benchmarks, browser-task success rates, tool-calling accuracy, and context length. Those remain important. Anthropic's containment post points to another axis: how much useful work can an agent do inside a small, observable, revocable blast radius?
OpenAI Codex, Google Antigravity, Microsoft Copilot, Cursor, Windsurf, and Claude Code all run into the same wall. A coding agent without repository and shell access is weak. A coding agent with broad host access can reach secrets, build systems, internal services, and customer data. The product quality question is not simply which model is smarter. It is which product can give the model enough access to be useful without making every mistake a host-wide or account-wide incident.
This will likely become an enterprise buying criterion. Security reviews will ask whether EDR can observe the VM, whether OTLP export exists, whether admins can define mount path allowlists, whether connector output is inspected, whether agent identity is represented by separate tokens, and whether revocation works cleanly after an incident. Those questions are not abstract AI ethics questions. They are systems engineering questions.
Containment Is a Product Feature
Anthropic's conclusion is pragmatic. Agents look like a new category of software, but their system-level interactions are familiar: they read files, open sockets, spawn processes, and pass tokens. Long-tested primitives such as hypervisors, syscall filters, containers, and network proxies still matter. Anthropic also notes that standard primitives such as gVisor, seccomp, and hypervisors generally held up, while custom proxies and surrounding glue code produced failures.
That is an uncomfortable but useful lesson for agent teams. A guardrail package is not the whole security story. System prompts, classifiers, and safety training matter. But the final boundary is usually the filesystem and the network. If credentials are not mounted and egress is blocked or tightly scoped, a successful prompt injection has less room to cause damage.
The core news is not that Anthropic has made Claude perfectly safe. The better reading is that strong agents require containment to become a first-class product feature. Better models make the environment boundary more important, not less. More capable agents can complete more work, but they can also find more paths around weak assumptions.
Claude containment sets a useful baseline for 2026 agent security. The 93% approval rate shows how quickly human review weakens under repetition. The 24 credential exfiltration successes show that user-pasted malicious prompts can bypass naive trust assumptions. The approved-domain exfiltration case shows why destination allowlists are not enough. The three containment patterns show that agent security is concrete systems design: workspace, VM, token, egress, connector, memory, and audit log working together.
The agent race is no longer only about who ships the strongest model first. It is about who can let that model do larger work inside a smaller blast radius. That is the question engineering teams should ask now: if the agent is wrong or successfully manipulated, exactly how far can the damage spread?