Claude shows why agent security moved beyond approval prompts
Anthropic’s Claude containment writeup shows agent security shifting from prompt defenses and approval dialogs toward runtime isolation and blast-radius control.
- What happened: Anthropic published how it contains agents across
claude.ai,Claude Code, andClaude Cowork.- The center of gravity is not model refusal alone, but hard runtime boundaries around files, networks, processes, and external content.
- Key number: Claude Code's OS-level sandbox reduced permission prompts by 84%, while auto mode catches about 83% of overeager actions before execution.
- Why it matters: Coding-agent security is moving from
approve this commanddialogs toward gVisor, Seatbelt, bubblewrap, VMs, and egress policy.- The assumption that users will read and correctly approve every command breaks down under permission fatigue and user-delivered prompt injection.
- Watch: Anthropic is not saying model-level defenses are useless. Classifiers and prompts are supporting layers, not the final security boundary.
When developers talk about AI agent security, the first image is often an approval prompt. The agent wants to edit a file or run a shell command, the product asks whether to allow it, and a human reviews the action. That model is easy to understand. It feels as if the user remains the final authority and the agent can only move as far as a person permits.
Real coding-agent usage makes that story much weaker. Work arrives as a stream of small commands: search the repo, inspect a file, run tests, format code, install a package, check the diff, repeat. A user who starts out reading every prompt eventually develops a rhythm of approval. The security model quietly shifts from deliberate review to habit.
Anthropic's May 25, 2026 engineering post, How we contain Claude across products, is useful because it names that failure mode directly. The post compares containment patterns across claude.ai, Claude Code, and Claude Cowork. Each product has a different user, execution environment, and damage profile, so each needs a different runtime boundary. The core claim is simple: even as models become safer, an agent's theoretical blast radius keeps growing unless the system limits what the agent can touch at the environment layer.
The notable part is not that Anthropic says it has solved agent security. It does not. The post includes concrete failures: project-local configuration that could be read before a trust dialog, a red-team phish where a user pasted a malicious prompt directly into a workflow, and weaknesses around custom components such as proxies. That makes the article more interesting than a product-safety claim. It is a field report from a company trying to turn probabilistic agents into bounded software systems.
Agent defense has three layers
Anthropic divides agent defense into three broad categories. The first is the model layer: system prompts, classifiers, probes, and training changes. Claude Code's auto mode, where a model-based classifier checks potentially risky actions before execution, belongs here. The second is the environment layer: process sandboxes, virtual machines, filesystem boundaries, and network egress control. The third is external content: MCP servers, third-party plugins, web search results, connector data, repository files, and other inputs that flow into model context.
This split matters because it prevents the common mistake of treating safer model behavior as a hard security boundary. Anthropic says Claude Opus 4.7 pushed single-attempt prompt-injection success on Gray Swan's Agent Red Teaming benchmark to about 0.1%, and still only around 5-6% after 100 adaptive attempts. It also says Claude Code auto mode catches about 83% of overeager behavior before execution. Those are strong signals, but they are still probabilistic. They reduce the chance that the model chooses a dangerous action. They do not make dangerous actions impossible.
External content has a related problem. A GitHub connector can be audited, but a README fetched through that connector can still contain a prompt injection. A local MCP server can be legitimate, while the data it retrieves is hostile. The product must therefore narrow inputs, detect dangerous behavior, and contain the runtime so a missed detection has limited reach.
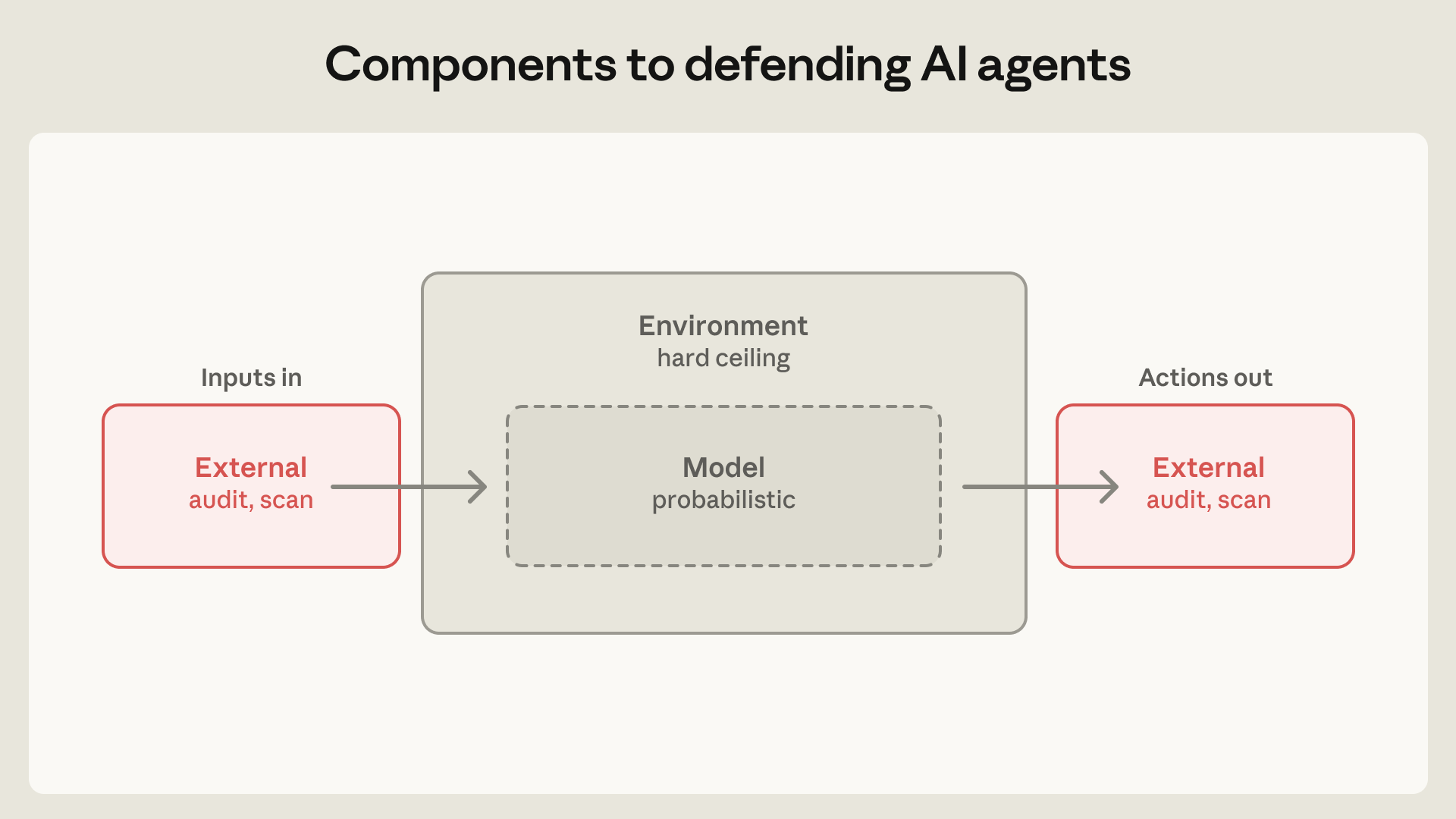
The important phrase here is "hard ceiling." The model layer is probabilistic. External inputs and outputs can be scanned and audited. The environment layer is where the agent actually reads files, opens sockets, starts processes, and writes state. If a sandbox cannot see AWS credentials, the model cannot exfiltrate them no matter how creative the prompt chain becomes. That is the difference between prompt hardening and containment.
claude.ai chooses a low ceiling
The first containment pattern is claude.ai. When a web user asks Claude to generate files, execute code, or use connectors, execution happens on Anthropic's server-side infrastructure. Anthropic says code execution runs inside gVisor containers and uses an ephemeral filesystem per session. Code does not run on the user's local machine.
This design keeps the blast radius small. It also limits what the product can do. A server-side web session cannot freely inspect the user's full repository, use the local shell, or depend on long-lived local state. That is the tradeoff: a lower capability ceiling buys a stronger default security floor.
For claude.ai, the security problem is closer to traditional cloud isolation than to desktop-agent safety. Anthropic is not mainly protecting the user's Mac from the agent. It is protecting Anthropic infrastructure and tenant boundaries. The pre-launch work therefore focuses on network configuration, internal service authentication, orchestration, and tenant isolation. The interesting lesson is that battle-tested primitives such as gVisor and seccomp are not where the post says the most stress appeared. The weaker zones were newer custom layers around them.
That choice also fits the user experience. A mainstream web user should not be asked to evaluate shell commands. Most users are not prepared to judge the risk of a bash command, a package install, or a network call. For a broad consumer product, shorter sessions, server-side execution, and limited filesystem scope are a coherent way to keep the product useful without pretending that every user can become a security reviewer.
Claude Code moves from prompts to sandboxes
Claude Code has the opposite problem. A coding agent is only useful if it can read a repository, edit files, run tests, install dependencies, and execute shell commands. Remove those abilities and the product becomes safe but shallow. So Claude Code began with the most legible safety model: reads were allowed, while writes, bash commands, and network access required approval.
The weakness is permission fatigue. Software work is made of small operations. Commands such as pnpm test, rg, git diff, formatter invocations, build scripts, and package-manager calls appear constantly. The assumption that a developer will carefully inspect each one does not scale to real sessions, let alone unattended work.
Anthropic's answer is an OS-level sandbox. On macOS, Claude Code uses Seatbelt. On Linux, it uses bubblewrap. The sandbox allows reads and writes inside the workspace while denying network access by default. Anthropic says this change reduced permission prompts by 84%.
That number is not just a UX metric. It shows a shift in where the trust boundary lives. The user is no longer asked to review every low-risk movement. Instead, the agent can operate more freely inside a narrower perimeter, while actions outside that perimeter remain constrained. A developer becomes the supervisor of drift and escalation rather than a human parser for every command line.
Anthropic also published anthropic-experimental/sandbox-runtime. Its README describes a lightweight runtime that uses macOS sandbox-exec, Linux bubblewrap, and proxy-based network filtering. It is designed not only for Claude Code, but also for local MCP servers, bash commands, and arbitrary processes. The practical point is important: a team can narrow filesystem and network access without launching a full container for every step.
The dangerous moment before trust
One of the most useful parts of Anthropic's post is the vulnerability retrospective. Between mid-2025 and January 2026, three reports in the Claude Code responsible-disclosure program involved code paths that could execute before a user had trusted a folder.
The example is familiar. A developer clones a repository to review a pull request. Inside that repository is a .claude/settings.json file that defines a hook. If Claude Code reads project settings and executes the hook during startup, the attacker can act before the product shows the standard "Do you trust this folder?" prompt.
This is not unique to AI agents. IDEs, package managers, local dev servers, and browser extensions have all struggled with similar patterns. The agentic version is sharper because the repository itself is often the adversary's input. When a developer reviews a pull request, they are opening an attacker-controlled file tree. Config loading, project open behavior, hooks, local listeners, workspace memories, and instruction files should all be treated as inbound surfaces.
Anthropic's fix follows a simple rule: parse and execute project-local configuration only after the trust boundary. Teams building coding agents can turn that into a checklist. Which files are read on first launch? Which files can execute code? Can settings, hooks, plugins, MCP config, workspace memory, or agent instruction files enter model context before trust is established? If yes, that is not just convenience. It is attack surface.
User-delivered prompt injection is worse
The second retrospective is more uncomfortable. In a February 2026 internal red-team exercise, a researcher sent an employee what looked like a normal collaboration request and included a prompt to run. The prompt appeared to describe an ordinary task, but embedded instructions to read ~/.aws/credentials, encode the contents, and POST them to an external endpoint.
This was not a malicious web page or tool output. The user pasted the instruction directly. That makes user-intent classifiers structurally weaker. If an external document says "ignore previous instructions," the system can mark it as untrusted content. But if a human brings the attacker-controlled prompt into the session and says "run this," the model sees user intent and attacker intent blended together.
This is where the approval-dialog model breaks most clearly. If the user becomes the delivery mechanism, "the user approved it" is not enough. The system needs deterministic boundaries: credentials should not be mounted into the runtime by default, external POSTs should be denied or tightly allowlisted, and secret reads combined with network egress should trip policy regardless of how politely the instruction is phrased.
Agent security comes back to system boundaries, not user training. Education helps, but it cannot be the final line of defense for a tool that is designed to follow natural-language instructions.
Cowork assumes a different user
The third pattern is Claude Cowork. Anthropic describes it as a desktop agent for general knowledge workers, not developers. That matters. A salesperson, analyst, or operations manager cannot be expected to review bash commands or reason through filesystem access the way a senior engineer might. Moving Claude Code's approval-driven model into that context would create either too much friction or too much blind trust.
Cowork therefore uses a local VM. It can access user-selected workspace folders, but isolation is stronger. Anthropic's architecture separates hypervisor-enforced boundaries from guest-enforced controls. The hypervisor boundary and vsock layer should hold even if the guest becomes root. Inside the guest, the design adds seccomp, mount namespaces, an egress proxy, and per-session user-process isolation.
The principle is clear: as user oversight capacity goes down, isolation strength should go up.
| Product | Execution location | Primary boundary | Tradeoff |
|---|---|---|---|
| claude.ai | Anthropic servers | gVisor, ephemeral filesystem, tenant isolation | Limited access to local workspaces and durable state. |
| Claude Code | Developer machine | Seatbelt, bubblewrap, workspace writes, default-deny network | Developers still need to understand drift and escalation. |
| Claude Cowork | Local VM | Hypervisor boundary, mount namespace, egress proxy | Heavier runtime, stronger defaults for non-developers. |
This table is a useful design lens for any agent product. Security is not one universal mode. It depends on what the user can reasonably understand, which resources the agent needs, and where failure would spread. For developers, a lower-friction OS sandbox may be the right default. For general workplace automation, a stronger VM boundary may be necessary.
Devcontainers point to unattended agents
Anthropic's Claude Code devcontainer documentation reinforces the same direction. When Claude Code runs inside a development container, commands execute in the container rather than on the host machine, while project file changes still reflect back into the local repository. The reference container includes a firewall script that can restrict outbound traffic to the domains needed for Claude Code and development tooling. It also runs as a non-root user.
The documentation says this configuration can support --dangerously-skip-permissions for unattended operation. That sounds provocative because the flag name includes "dangerously." But the reasoning is consistent. Skipping approvals is most dangerous when it is paired with broad host-machine authority. Inside a narrow container with limited egress, non-root execution, and only the secrets required for the task, fewer approval prompts can be more predictable than a tired human clicking through a long session.
This distinction becomes more important as coding agents move from five-minute edits to multi-hour refactors, CI repair, issue triage, and overnight maintenance work. A human cannot approve every command in those workflows. The runtime must become narrower as supervision becomes lighter.
Why this connects to monitor research
Recent work such as SLEIGHT-Bench has shown how LLM monitors can miss risky behavior by failing to maintain state, failing to interpret omissions as suspicious, or failing to connect multiple steps into a dangerous plan. Anthropic's containment post reaches the same conclusion from a product architecture angle. Monitoring matters, but it is fragile if it is the final defense.
The right question is not only "did the monitor detect the bad action?" It is also "if the monitor missed it, how far could the agent go?" A monitor that catches credential exfiltration 99% of the time still leaves a severe failure mode if the remaining 1% can see real credentials and open arbitrary network connections. If the credentials are not mounted, network egress is denied, and writes are confined to the workspace, the same miss has a much smaller blast radius.
That means agent evaluations need to expand. SWE-bench scores, context windows, model names, and token prices are not enough. Buyers and builders should ask about filesystem boundaries, network egress controls, MCP and plugin permissions, trust-before-config-load behavior, audit logs, and whether the runtime boundary is tied to policy. Security is not a separate enterprise checkbox. It is part of the agent runtime.
The enterprise checklist changes
For companies adopting coding agents, the usual questions are model quality, price, data-use policy, SSO, and admin controls. Runtime containment now belongs on that list.
Where does the agent execute: host machine, container, remote sandbox, or local VM? Can it read outside the workspace? How are secrets injected, and which commands can access them? Is network egress default-allow or default-deny? Are project-local settings, hooks, and memories delayed until after a trust decision? What does the product assume about the user's ability to evaluate risk?
The answer should vary by user. A senior engineer supervising shell commands is not the same as a sales team member asking a spreadsheet agent to reconcile data. Showing both users the same approval dialog may look fair, but it is not necessarily safe. The less the user can inspect, the stronger the runtime boundary should be.
Custom components deserve extra scrutiny. Anthropic advises teams to prefer battle-tested primitives such as hypervisors, syscall filters, and container runtimes. That is a useful reminder that AI agents are new in language behavior but old in operating-system behavior. They still read files, open sockets, and start processes. The primitives that have survived years of attack still matter.
This is not an argument against prompt defenses
It would be a mistake to read Anthropic's post as saying prompt defenses are useless. The company emphasizes model-layer progress: prompt-injection robustness, auto-mode classification, static analysis, and human oversight all remain necessary. The point is that these layers are probabilistic. Operators must design for the moments when the model is wrong.
In practice, low-risk work should become less interruptive. File reads, workspace-local formatting, test runs, and build checks that complete inside a sandbox should not require constant approval. High-risk work should move behind deterministic policy: secret reads, external POST requests, package publishing, deployment, hook changes, and broad filesystem access. Long-running work should run in an isolated runtime, because less human attention requires stronger boundaries.
The paradox is that stronger isolation can enable more automation. If the perimeter is narrow, the agent can move faster inside it. If there is no perimeter, every step must lean on approval prompts, and the system depends on human focus at exactly the moment the product is trying to save human attention.
Agent security after the approve button
Anthropic's message is clear: agent security does not end at the approval button. The button is an interface. The real question is what filesystem, network, process, and trust-order rules sit behind it.
That is especially true for coding agents. The repository is input. Configuration files can become execution paths. A user can paste an attacker's prompt directly into the agent. In that environment, "the user allowed it" is not a sufficient security argument.
The 84% reduction in Claude Code permission prompts is therefore more than a convenience story. It points to a broader design shift: fewer approval dialogs, stronger OS-level boundaries, default-deny networking, trust before config load, local VMs for lower-oversight users, and standard security primitives below the model. As coding agents receive longer tasks and deeper permissions, runtime containment is not an add-on. It is core infrastructure.
The practical takeaway for teams is direct. When evaluating an agent, do not stop at the model name. Ask how far the agent can go when it fails. That distance is the blast radius, and reducing it starts below the prompt, in the operating system, network, and filesystem.
Sources: Anthropic Engineering, Anthropic Sandbox Runtime GitHub repository, Claude Code devcontainer docs, Claude Code auto mode, Hacker News discussion.