Claude Code and the +0.83 language frontier
A 5,838-developer GitHub panel study suggests Claude Code adoption may widen the languages and repositories developers touch, not just raise output.
- What happened: A new arXiv paper tracks developer behavior before and after adopting
Claude Code.- The study analyzes 28 months of GitHub activity and 7,786,771 Claude co-authored commits.
- Key number: In the adoption month, the estimated effects were +40.7 commits, +1.5 repositories, and +0.83 programming languages.
- Why it matters: The interesting signal is not only speed. Coding agents may lower the cost of entering
unfamiliar technology.- The author frames Claude Code as a free signal channel in a Bayesian learning model of language choice.
- Watch: Adoption was voluntary, so this should be read as a sharp behavioral shift around adoption, not a clean causal proof.
The default question around AI coding tools is still "how much faster did developers get?" Since GitHub Copilot, most studies and product claims have clustered around task completion time, pull request volume, test pass rates, SWE-bench scores, and lines of code. That question matters. But for actual engineering careers and team architecture, it is incomplete. Does an AI coding tool only help a developer move faster inside languages they already know, or can it also lower the psychological and technical cost of entering an unfamiliar language, repository, or stack?
Coding Beyond Your Training: Claude Code and the Technological Frontier of Software Developers, posted to arXiv on May 25, 2026, asks the second question directly. Alexander Quispe's preliminary paper treats Claude Code adoption as a possible expansion of a developer's "technological frontier." In this paper, the frontier is not a national innovation boundary. It is the practical range of programming languages and repositories a person actually touches in public GitHub commits.
That makes the paper interesting even before the headline numbers. It is not a feature tour of Claude Code. It is an observational study built around a visible trace: Claude Code can leave a Co-Authored-By: Claude trailer in commits, and that metadata can be observed at scale through GitHub public events. The author collected 7,786,771 Claude co-authored commits from January 2025 through January 2026, identified 185,517 distinct authors, and then built a 28-month activity panel for 5,838 developers.
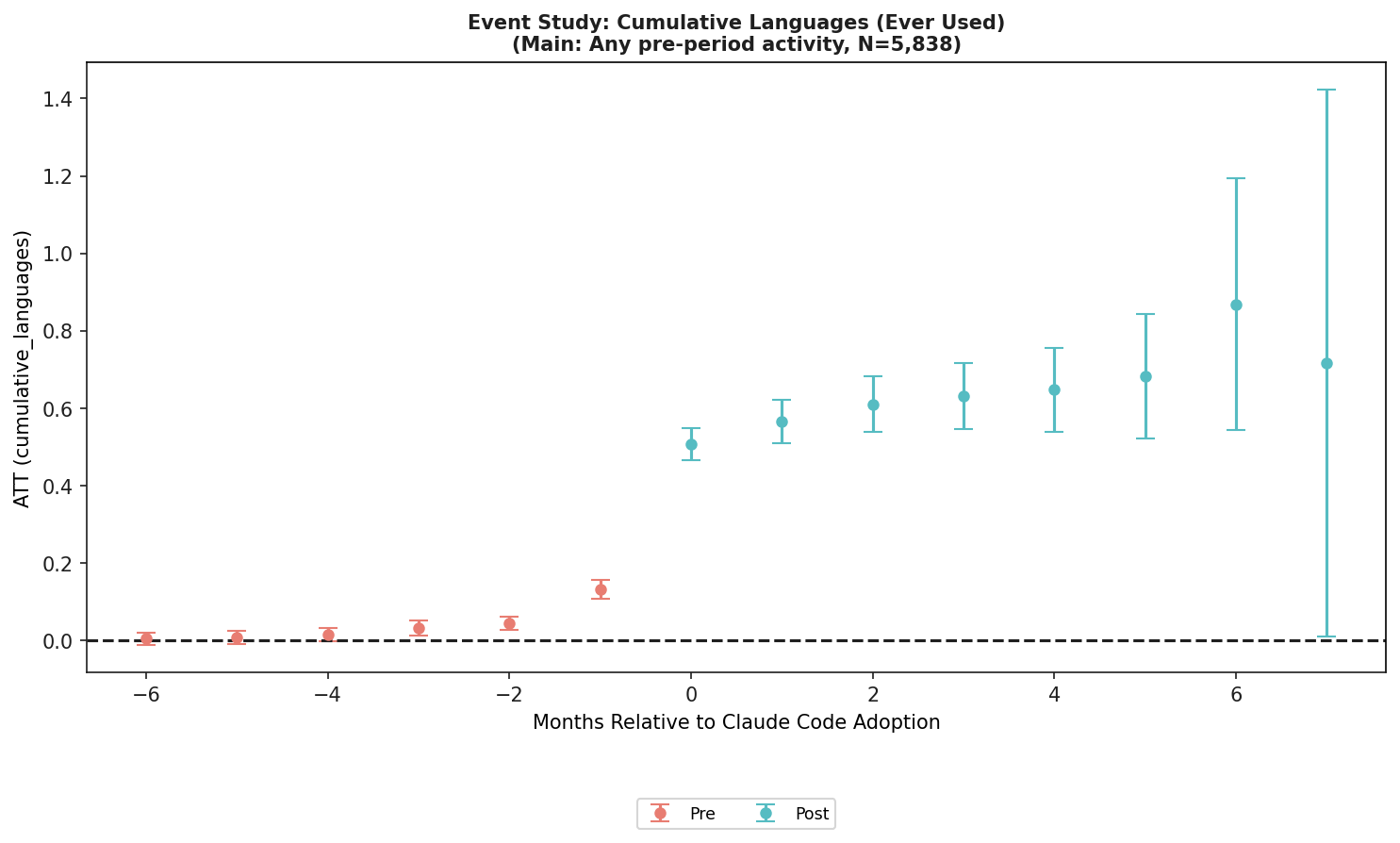
It would be easy to turn those numbers into a simple "Claude Code doubles productivity" headline. The more useful part is the language portfolio. In the adoption month, distinct programming languages rose by an estimated 0.83, and newly used languages rose by 0.31. Cumulative lifetime languages also grew over time. That is a different story from autocomplete. The signal is not merely that AI helped developers write more code. It is that developers started showing up in more places.
What the study actually measured
The paper describes Claude Code as entering beta in February 2025 and general availability in May 2025. The key empirical feature is that adoption did not happen at once. It spread across GitHub developers from May 2025 through January 2026, which lets the author compare earlier adopters with later adopters who had not yet been treated during the same calendar months.
The treated group contains developers whose first Claude commit appeared in Q2 or Q3 2025. The control group contains not-yet-treated developers whose first observed Claude adoption came in Q4 2025 or Q1 2026. Because the control developers eventually adopted Claude Code too, the comparison partially narrows broad differences between "people interested in AI coding tools" and everyone else. The paper connects this setup to a staggered adoption design in the Callaway and Sant'Anna family.
The final main sample includes 5,838 developers with pre-adoption commit activity: 3,060 treated developers and 2,778 controls. Across 28 months, that produces 163,464 developer-month observations. The author queried GitHub's GraphQL contributionsCollection endpoint from January 2024 through April 2026 and reconstructed monthly public activity, including commits, repositories, primary languages from GitHub Linguist, language byte distributions, and repository metadata.
The outcome variables are deliberately broader than raw output. The study tracks monthly commits, the number of distinct repositories touched, the number of distinct primary languages, Shannon entropy across languages, newly used languages, and cumulative distinct languages. That split matters because "more commits" and "a wider technical frontier" are not the same thing.
If commits rise, the explanation could be productivity, automation, smaller commit granularity, a new project start, or some mix of all of them. If repositories rise, the developer is touching more work surfaces. But if new languages and cumulative languages rise, the developer may be crossing into technologies that were previously outside their working range.
Why +0.83 languages matters more than +41 commits
Table 2 reports positive adoption-month average treatment effects across the measured outcomes. Monthly commits rise by 40.708. Repositories rise by 1.497. Programming languages rise by 0.830. Language entropy rises by 0.138. Newly used languages rise by 0.308. Cumulative languages rise by 0.507. The paper clusters bootstrap standard errors at the developer level and reports statistical significance for the adoption-month estimates.
The most eye-catching number is +40.7 commits. That is large, especially because treated developers averaged 21.3 monthly commits before adoption. The paper also reports a simpler post-adoption ATT of +20.8 commits, so the activity increase does not vanish entirely outside the adoption-month spike.
But commit count is a noisy signal. A coding agent can generate boilerplate. A developer can split work into smaller commits. A project can enter a busy launch phase. A team can begin using Claude Code because it already has a large new task. Programming languages +0.83 is more specific. Given that treated developers averaged 0.63 distinct languages per month before adoption, the adoption month looks close to adding one working language.
Newly used languages make the signal sharper. The adoption-month estimate is +0.308. That is harder to explain with volume alone. Forty more commits in the same JavaScript service do not create newly used languages. The metric only moves when a developer contributes in a language not previously seen in their observed history. The author treats this as an empirical signature of portfolio expansion.
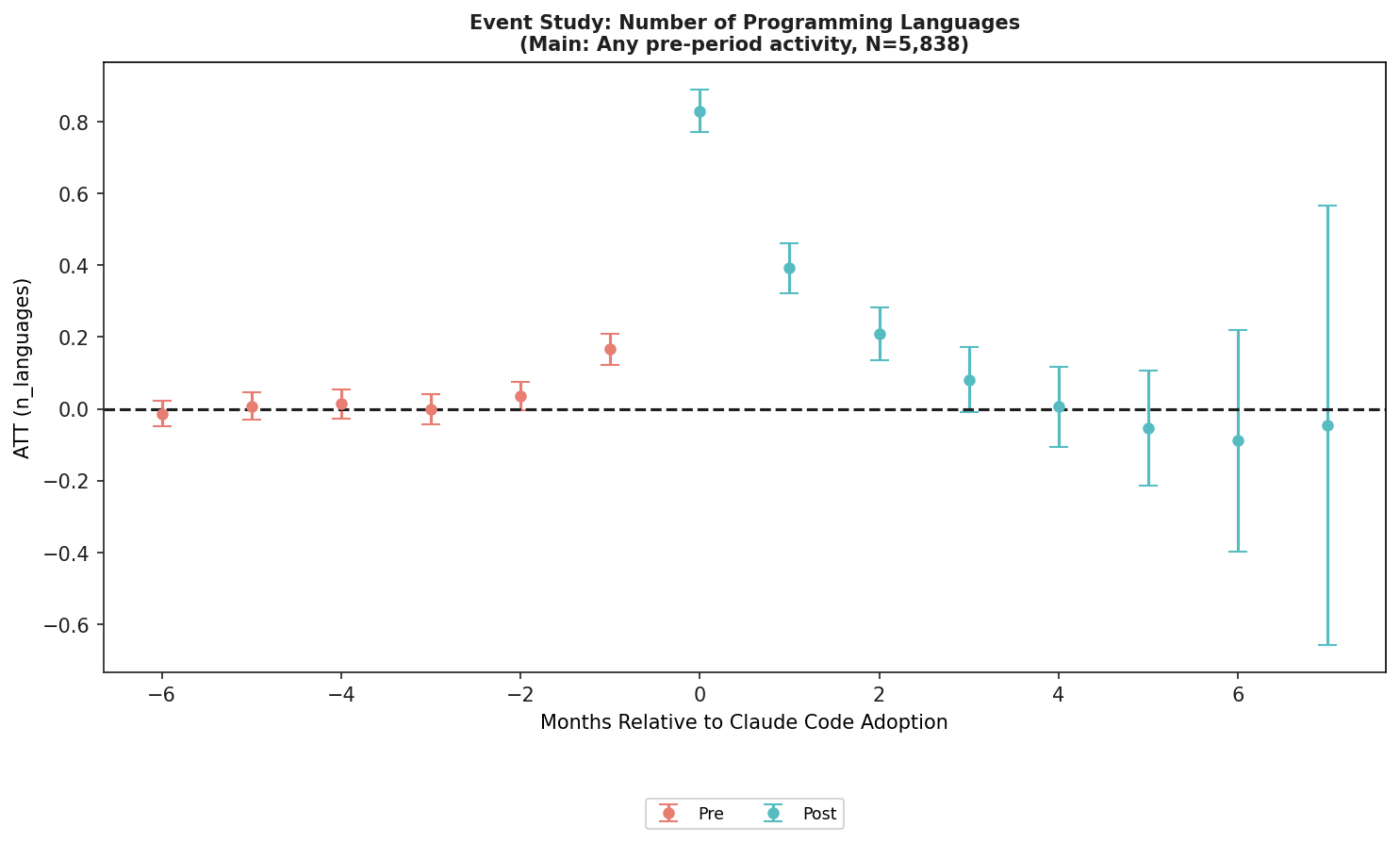
The figure above is the programming-language event study from the paper's official arXiv HTML, reused under the arXiv HTML page's CC BY 4.0 license. Its message is not that language count permanently jumps by the same amount every month. The adoption month is the sharpest movement, followed by partial reversion and stabilization. That pattern fits a story where Claude Code helps at the entry point into a new project or stack, rather than mechanically adding new languages forever.
Claude Code as a free signal channel
The paper explains the result with a Bayesian learning model. Developers have beliefs about their productivity in each programming language. For languages they already know, those beliefs have higher precision. For languages they have not used, uncertainty is higher. A risk-averse developer may avoid switching because they do not know how productive they will be in the new environment. That uncertainty becomes a switching barrier.
Claude Code enters the model as a "free signal channel." A developer does not need deep Rust experience to ask the agent to explain syntax, interpret compiler errors, suggest idiomatic patterns, wire a test, or generate a small working example. The agent does not magically transfer expertise, but it can reduce uncertainty about what the next step should be. The developer gets a low-cost signal about their likely productivity in a language or toolchain they might otherwise avoid.
This is a wider framing than autocomplete. Autocomplete is close to "the next line in code I already know." A coding agent is closer to "the first workable path through an ecosystem I do not yet understand." Language syntax, build tools, package managers, test runners, error messages, framework conventions, and small failure modes are all part of that entry cost. Often the hard part of trying a new language is not the absence of documentation. It is repeatedly interpreting unfamiliar failures.
The cumulative language result matters for the same reason. The paper reports a simple ATT of +0.586 cumulative languages, larger than the adoption-month cumulative estimate of +0.507, and describes an event-study profile that grows over time. Monthly commit counts and monthly language counts can revert. But once a developer has made a real contribution in a new language, that experience remains part of the cumulative frontier.
For companies, that changes the shape of reskilling. Moving a Python developer into Go or a TypeScript developer into Rust has traditionally been a training, mentoring, review, and project-assignment problem. If AI coding tools lower the switching barrier, teams can design onboarding differently. The goal is not only "ship faster with AI." It becomes "create a verified path for developers to explore new languages and systems with AI support."
How this differs from productivity studies
The existing AI coding literature already has task-completion studies, field experiments, benchmark results, and survey data. Those studies ask important questions. Can a developer finish the same task faster? Does quality hold? Do junior and senior developers benefit differently? How often does generated code pass the tests?
This paper changes the unit of interest. Instead of looking only at performance inside a fixed task, it looks at what developers choose to touch: which repositories, which languages, and how diverse the monthly portfolio becomes. It is less about the speed of a production function and more about the domain that production function covers.
That difference is practical. A backend developer making more commits in an existing Node.js service is one operating model. The same developer also touching a Rust CLI, a Python data pipeline, and a Terraform module is another. Both cases can increase commit count. The second one changes ownership, review load, incident response, and team boundaries.
This is where the paper becomes useful for engineering leaders. AI coding adoption metrics often stop at seats, tokens, PRs, and accepted suggestions. If coding agents expand the frontier, teams should also watch where developers move. Are AI-assisted developers entering new repositories? Are they touching languages without a domain expert nearby? Are review queues shifting? Are defects rising in first-time-language contributions? Frontier expansion is both an opportunity and a governance problem.
Why the paper does not prove causality
The paper is careful about its own limits. Claude Code adoption is voluntary. A developer may decide to start a new Rust project and install Claude Code because they expect to need help. In that case, the first Claude commit and the first Rust commit happen in the same month, but the deeper cause is the new project decision. The data would still show adoption and diversification together.
The author calls this reverse-causal selection. A staggered DiD design can reduce some cohort heterogeneity and avoid common problems in two-way fixed effects estimation, but it cannot fully solve a situation where treatment timing is tied to project starts. The paper therefore avoids a strict causal claim. The most defensible interpretation is that Claude Code adoption coincides with a sharp and persistent shift in public developer behavior, and that the pattern is consistent with an AI-as-signal mechanism.
That caveat matters for coverage. "Claude Code taught developers new languages" is too strong. A better sentence is: around Claude Code adoption, developers contributed to more repositories and languages, including languages not previously observed in their public activity, and some cumulative frontier metrics continued to grow afterward.
The paper also outlines what stronger causal evidence would require. Exogenous variation from regional rollout, price changes, organizational subscription eligibility, or similar cutoffs could support instrumental variables or regression discontinuity designs. Richer pre-period covariates could strengthen conditional parallel trends. Placebo treatment dates could probe whether the pattern appears before adoption. This study is best read as a large observational frame that other work can build on.
Why this is still news
If causality is limited, why cover the paper at all? First, it uses public GitHub metadata to measure large-scale behavioral change around AI coding tools. AI coding adoption is moving quickly, but independent evidence about developer-month behavior is still thin. Vendor dashboards and surveys are useful, but a public commit metadata study gives the ecosystem another measurement surface.
Second, the question is right for 2026. The coding-agent market is no longer only about completing a helper function. Codex, Claude Code, Cursor, GitHub Copilot, Google Antigravity, and similar tools are moving toward repository-wide work, shell access, test execution, pull request preparation, and long-running task loops. In that world, the important developer change may not be "more code per hour." It may be "more technical boundaries crossed per month."
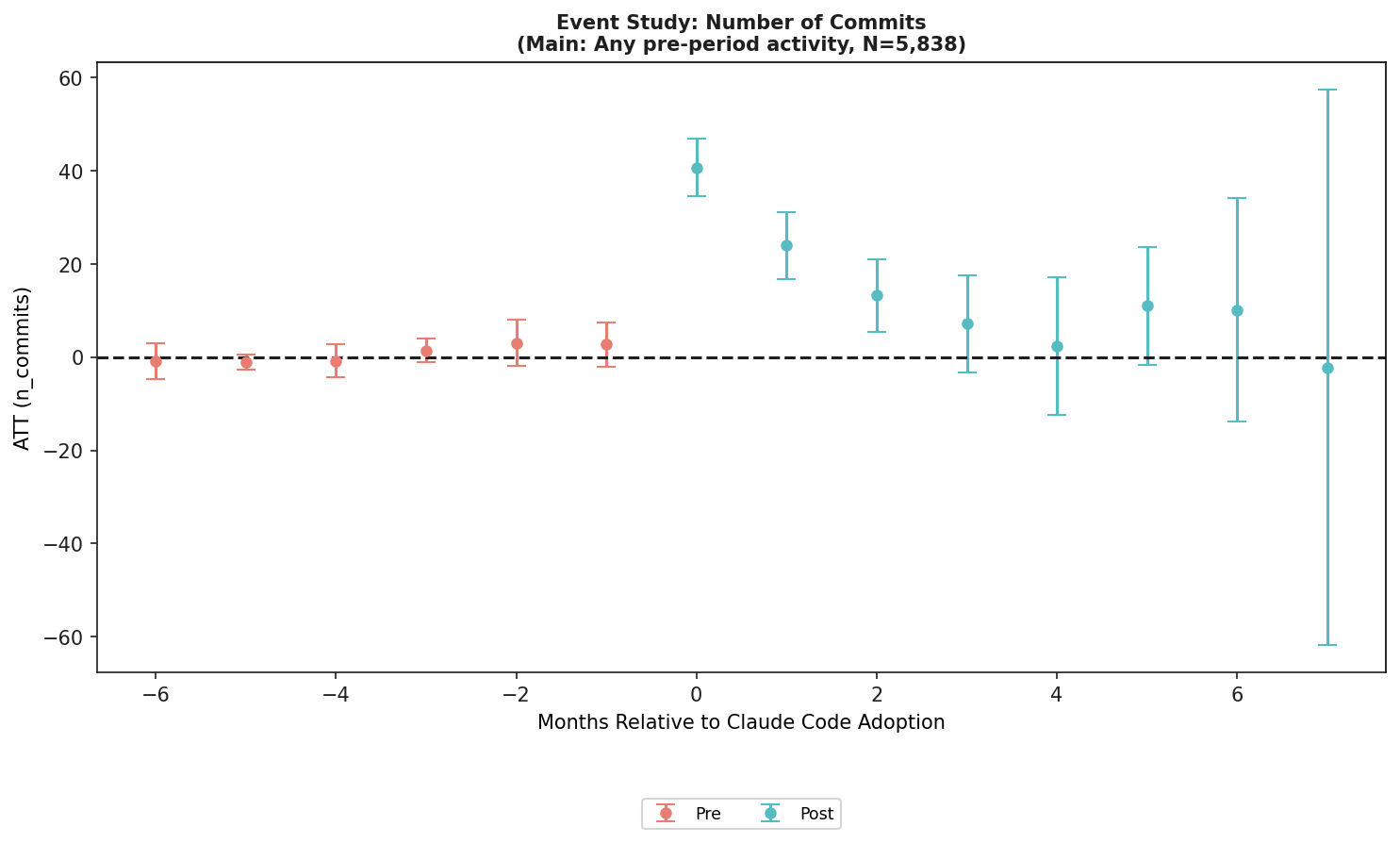
The commit event study explains the productivity headline. The adoption-month rise is large, and some activity remains elevated. But if we only look at this chart, the discussion slides back into output volume. The language chart is what makes the paper different. The core question is whether the work surface widened at the same time the work volume increased.
Questions teams should ask
Teams do not need to read this paper as a buying recommendation for Claude Code. A better use is to turn the variables into internal metrics.
First, do AI-assisted developers enter new languages and repositories more often? A company can build a similar internal panel with GitHub or GitLab data: repository count, language count, first-time language contributions, and pre/post adoption windows.
Second, does that expansion happen without quality loss? First-time-language pull requests should be paired with review cycle time, rollback rate, incidents, test failures, security findings, and ownership gaps. A larger frontier is not automatically healthier.
Third, who benefits? The paper discusses specialists and generalists in theory, but organizations will care about junior versus senior developers, platform teams versus product teams, contractors versus employees, and teams with different review depth.
Fourth, did AI lower learning cost or just move verification cost? Getting a first pull request in a new language may become easier while reviewing it safely remains just as hard, or harder. A reviewer may need to account for the fact that the author was supported by an agent in a language they do not yet deeply understand.
Fifth, how should training change? If a developer can enter Rust with AI support, the training path can focus less on lecture-style syntax coverage and more on verification loops: cargo clippy, property tests, unsafe policies, ownership review, performance profiling, and deployment conventions. The agent becomes a low-cost exploration layer, not a replacement for engineering judgment.
The risk of a wider personal frontier
The optimistic story is incomplete by itself. If developers can touch more languages, the boundary between permission and responsibility becomes fuzzier. A TypeScript developer can now ask an agent to patch Go code. Sometimes that removes a bottleneck. Sometimes it creates shallow fixes in a runtime the developer does not really understand.
There is also a difference between "used a language" and "understands the language." A GitHub contribution in Rust means the developer committed Rust code. It does not mean they understand ownership tradeoffs, async runtime behavior, unsafe boundaries, packaging norms, performance traps, or deployment conventions. AI can lower the entry barrier without transferring the operational knowledge that makes code maintainable.
That means the goal is not to expand the frontier without limits. The goal is to make the expanded frontier verifiable. New-language pull requests need stronger CI, sharper templates, code owner review, and explicit design notes. Teams should distinguish between "the agent made it run" and "the team can maintain this system." If the paper's signal is real, this governance work becomes central rather than optional.
How to read the result
The balanced reading is straightforward. Claude Code adoption appears alongside a large shift in public GitHub activity. Commits and repositories rise. Used languages and newly used languages rise. Cumulative language counts grow over time. That pattern is consistent with the idea that an AI coding agent supplies cheap signals about unfamiliar technologies and reduces switching barriers.
But the adoption was voluntary, and the study cannot rule out developers adopting Claude Code because they were already starting new projects or entering new languages. The paper should not be treated as proof that Claude Code caused every measured frontier expansion.
Even with that caveat, the paper moves the AI coding conversation forward. It is no longer enough to ask whether AI writes code faster. The sharper question is whether AI changes the range of technologies developers are willing to attempt. If the answer is yes, coding agents are not only productivity tools. They are learning infrastructure, reskilling aids, and boundary-changing systems inside engineering organizations.
For individual developers, that is an opportunity. The first step into an unfamiliar language may be less expensive. For teams, it is a responsibility. A wider contribution surface needs review, ownership, tests, and operational controls that can keep up. The next useful metric for coding agents may not be "how many lines did it write?" It may be "which technical boundary did it cross, and can the organization safely operate on the other side?"
Sources: arXiv abstract, arXiv HTML paper, arXiv PDF.