Cursor agents run 2,000 times a week, and automation finds its next bottleneck
Faire says Cursor Cloud Agents doubled weekly PR throughput and now run 2,000+ times per week, shifting the bottleneck from models to environment, permissions, and workflow.

- What happened: Cursor published a Faire customer story on May 26 about its Cloud Agents rollout.
- Faire cited 2x weekly PR throughput, more than 2,000 automated agent runs per week, and 25+ Cursor Automations.
- Why it matters: The coding-agent race is moving from model names to execution environments, permissions, CI recovery, and PR routing.
- Watch: This is a vendor customer story, not an independent benchmark. The missing numbers are operating cost, failure rate, and reviewer load.
- Teams should ask how many agent runs reach a useful PR, how many need human rescue, and how much CI and token budget they consume.
Cursor's May 26, 2026 Faire customer story puts concrete numbers on how far coding agents have moved inside a real engineering organization. Faire, the North American wholesale marketplace, replaced its own background-agent system with Cursor Cloud Agents. Cursor says Faire doubled weekly PR throughput after the migration. The same story cites more than 2,000 automated agent runs per week, more than 25 Cursor Automations, and an 18-month migration program coordinated by one engineer working with an agent fleet.
Read only as a success story, the post sounds like another vendor case study. The more useful reading is operational. Cursor had published a separate May 21 research post arguing that cloud agents are not just local agents moved to a server. They require dedicated virtual machines, dependency setup, network access, checkpoints, credential management, and durable workflows. Faire's numbers are an applied example of that claim. The thing increasing PR throughput was not a single model. It was a system that connected Slack, CI, GitHub, internal packages, AWS credentials, and a React migration queue.
Faire's first constraint was local parallelism. Running many agents on one laptop turns memory, CPU, terminal sessions, and worktree management into the user's problem. Faire initially built an internal cloud-agent system called Samurai, but Cursor's customer story quotes Luke Bjerring pointing to the cost of standing up servers, staffing the effort, and maintaining complex infrastructure. Faire's stated reasons for choosing Cursor include managed infrastructure, a self-hosted machine option, GitHub integration, agent reliability, an interface for managing multiple agents, and handoff between local and cloud work.
The word "cloud" does a lot of work here. Cursor's research post says each cloud agent receives a dedicated virtual machine, uses dependencies and network access, and handles unattended long-running tasks. A local agent inherits the developer's laptop. A cloud agent has to reconstruct that environment from scratch. Cursor describes this as "development environment is the product." If one part of the environment is missing, the agent may not crash cleanly. It may simply produce lower-quality work, making the team blame the model when the failure came from setup, credentials, or missing internal services.
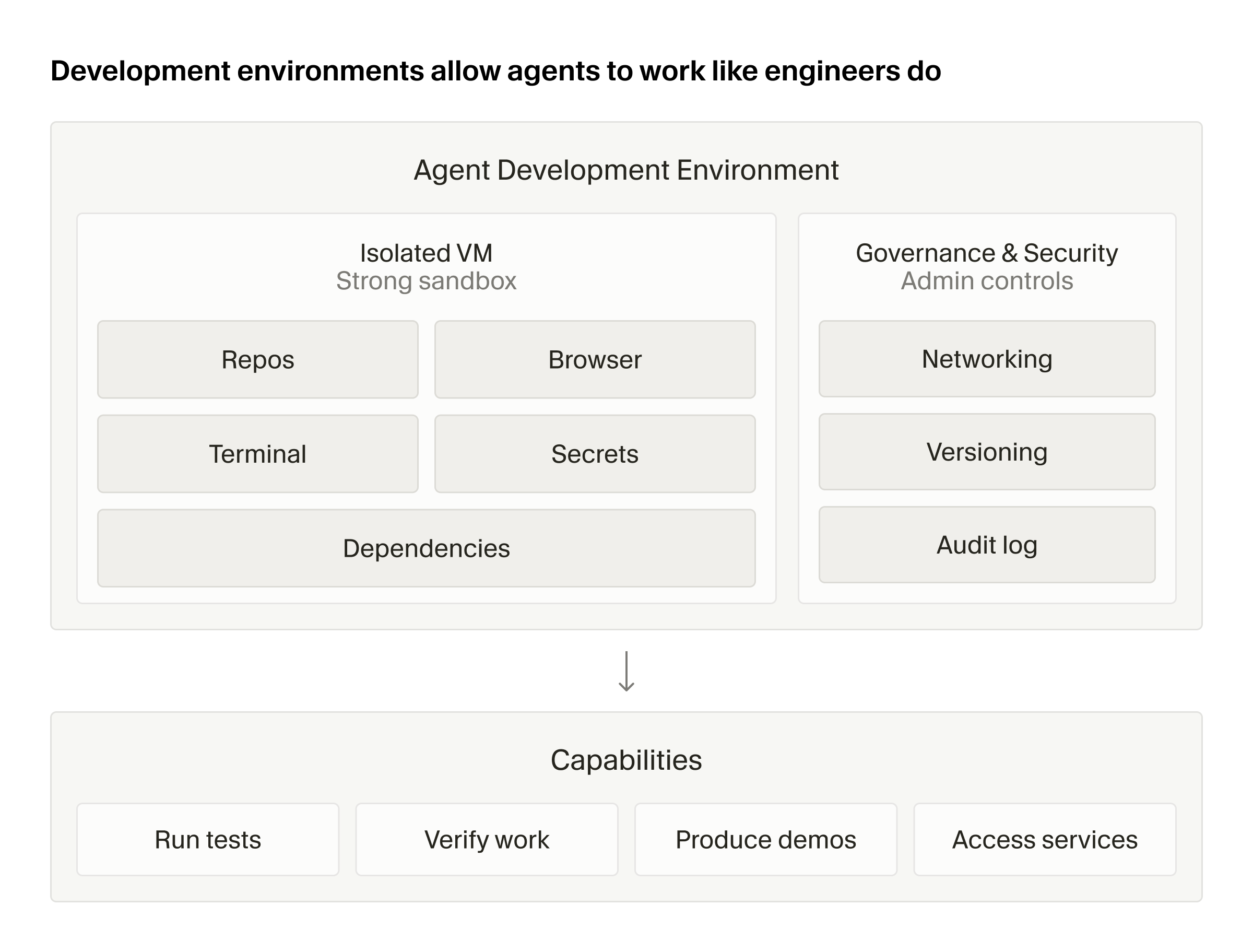
Faire's setup problem is not theoretical. Its backend and frontend live in separate repositories. Internal package dependencies are tied to Gradle and Bazel. Some tasks need separate AWS credentials. Cursor says Faire used agent-led onboarding, where Cursor inspects each repository, identifies toolchains and dependencies, and builds environment configuration. For workflows that need tighter control, Faire can define the development environment with a Dockerfile. Before an agent can write useful code, the organization has to answer build, test, internal-service access, and credential-boundary questions.
The workflow with the most immediate developer impact starts in Slack. Faire is a Slack-heavy company, and much engineering work begins as a question or bug report in a channel. An engineer can mention @cursor in a thread, pass the conversation context to a cloud agent, and receive an investigation and PR later. That sounds convenient, but it hides several control surfaces: which thread context is captured, which repository is selected, which permissions the agent receives, how the run is logged, and who reviews the resulting branch.
Faire's automation use cases go beyond one-off prompts. The company says it runs more than 25 Cursor Automations and more than 2,000 autonomous agent runs per week without manual prompting. Cursor names Slack bug-report triage, CI failure investigation with fix pushes, and PR routing as examples. For PR routing, an agent labels and routes changes by author, risk, and size. That shifts the coding agent from a "code-writing assistant" into an actor that moves the development queue. Human review may remain before merge, but the first triage and repair loop is no longer purely human.
The 18-month migration example is the most aggressive version of the same pattern. Faire needed to move a retailer-facing application from MobX to native React state management. It built a coordination system called Swarm on top of Cursor. A scraper scans the codebase for MobX usage and writes a task list to S3. Swarm reads that list and assigns migration work to Cursor cloud agents. When one agent finishes and the PR is merged, Swarm starts the next task.
That does not mean AI finished 18 months of work overnight. Cursor's public story does not disclose the total completion time, failure rate, review load, rollback cost, or changes in test coverage. The verified fact is narrower and more interesting: Faire decomposed a large migration into a list, S3-backed coordination, isolated VMs, and a PR merge loop. The reusable lesson is not magical compression. It is task shape. The successful unit is not "do the whole migration." It is closer to "fix this MobX usage site or small group of sites, then return a reviewable PR."
Cursor's May 21 research post explains why that kind of repeated work needs durable execution. Early cloud agents used a work-stealing architecture in which a worker node picked up an agent and ran the loop to completion. Cursor describes that as "one 9" reliability. After moving the agent loop to Temporal, Cursor says the system became more resilient to inference-provider outages, pod hibernation and resumption, EC2 node failure, and runs that last days or weeks. Cursor claims the migration pushed reliability beyond two 9s, and notes that Temporal handles more than 50 million actions and more than 7 million unique workflows per day.
Those numbers expose the hidden product behind a coding-agent chat box. A user types "fix this issue," but the provider operates a workflow engine, VM lifecycle, storage stream, retry semantics, log path, and network policy. Cursor says it separated the agent loop, machine state, and conversation state. The agent loop lives in Temporal. Pod lifecycle is managed separately. Conversation updates stream from append-only storage to web and desktop clients. If partial output changes during a retry, the client has to rewind the stream and display new data. That is infrastructure work, not just prompt engineering.
This is where Cursor competes with GitHub Copilot cloud agent, OpenAI Codex, and Claude Code or Cowork. GitHub has been expanding the Copilot app, cloud-agent sessions, model rules, and memory controls. Anthropic has been exposing sandbox and MCP connector boundaries across the Claude product line. OpenAI has emphasized Codex internal usage and mobile handoff. Cursor's Faire story is distinct because it does not lead with "our model is stronger." It leads with how many cloud-agent runs one company attached to its PR queue, Slack queue, CI queue, and migration queue.
For engineering leaders, the first question is cost. More than 2,000 autonomous runs per week can save triage and CI recovery time if enough runs land useful changes. The same volume can burn tokens, VM time, CI minutes, and reviewer attention if many runs stall or produce weak PRs. Cursor's customer story says Faire's engineering output is approaching 2x to 3x and that the next bottleneck may be the broader product-development process. That sentence matters. As code production speeds up, specs, design review, QA, rollout, and support triage can become the new limit. More PRs do not help if review and release capacity stay fixed.
The second question is permission. Calling @cursor from Slack is ergonomic, but the organization has to decide which channel data can enter an agent context, which secrets and internal services the agent can touch, and how far branch and CI permissions extend. Cursor's research post says cloud agents gradually became "enterprise IT for agents," with secret redaction, network policies, and credential management. That phrase is the work behind the customer-story numbers. Once agent runs scale, identity, network, and audit policy need documentation before prompt style does.
The third question is observability. Cursor's forum had a late-May support thread about Cloud Agents failing to start with a configured environment. One thread cannot define product quality, but it illustrates the failure mode. A cloud agent may fail to start, a stale completed session may occupy a concurrency quota, or a web/mobile handoff may not preserve the expected state. The developer then has an execution-platform problem, not a model-quality problem. At 2,000 runs per week, those failures become SLO issues rather than one developer's annoyance.
The practical adoption checklist from Faire's story is concrete. First, the development environment for each repository needs to be reproducible as code. Gradle, Bazel, internal package registries, AWS credentials, local-service mocks, and test commands need to exist in documentation, Dockerfiles, or agent configuration. Second, automation triggers should attach to places where people already work: Slack, CI, PR events, and migration queues. If engineers have to copy work into a separate dashboard, agent operations become another manual queue. Third, the team needs a way to merge small agent-created PRs and then open the next task automatically.
The headline number, 2,000 runs per week, should become a measurement question. What percentage of those runs end in a merged PR? What percentage require human intervention? What are the median token cost and CI-minute cost per useful change? How often do reviewers reject agent work? Cursor's reliability claim should be treated the same way. "Two 9s" is a provider metric. A customer still has to define who gets alerted when a run fails, when it should retry, and when a person should take over.
The conclusion for developers is simple but not small. Choosing a coding agent is no longer only choosing an editor extension or a model. A team that wants to run agents at Faire's scale must design the VM, build cache, credential boundary, branch policy, CI approval flow, Slack event capture, and PR review queue around those agents. Cursor and Faire show what the upper bound can look like when that system works. The same story shows why model performance is no longer the only bottleneck. At scale, environment and operations decide how much automation actually reaches production.