Cognition’s $1B round puts Devin’s 89% code claim on trial
Cognition says Devin commits 89% of its internal code. The harder question is whether agent-written PRs come with reviewable test evidence.
- What happened: Cognition announced more than $1 billion in new funding and a $26 billion valuation.
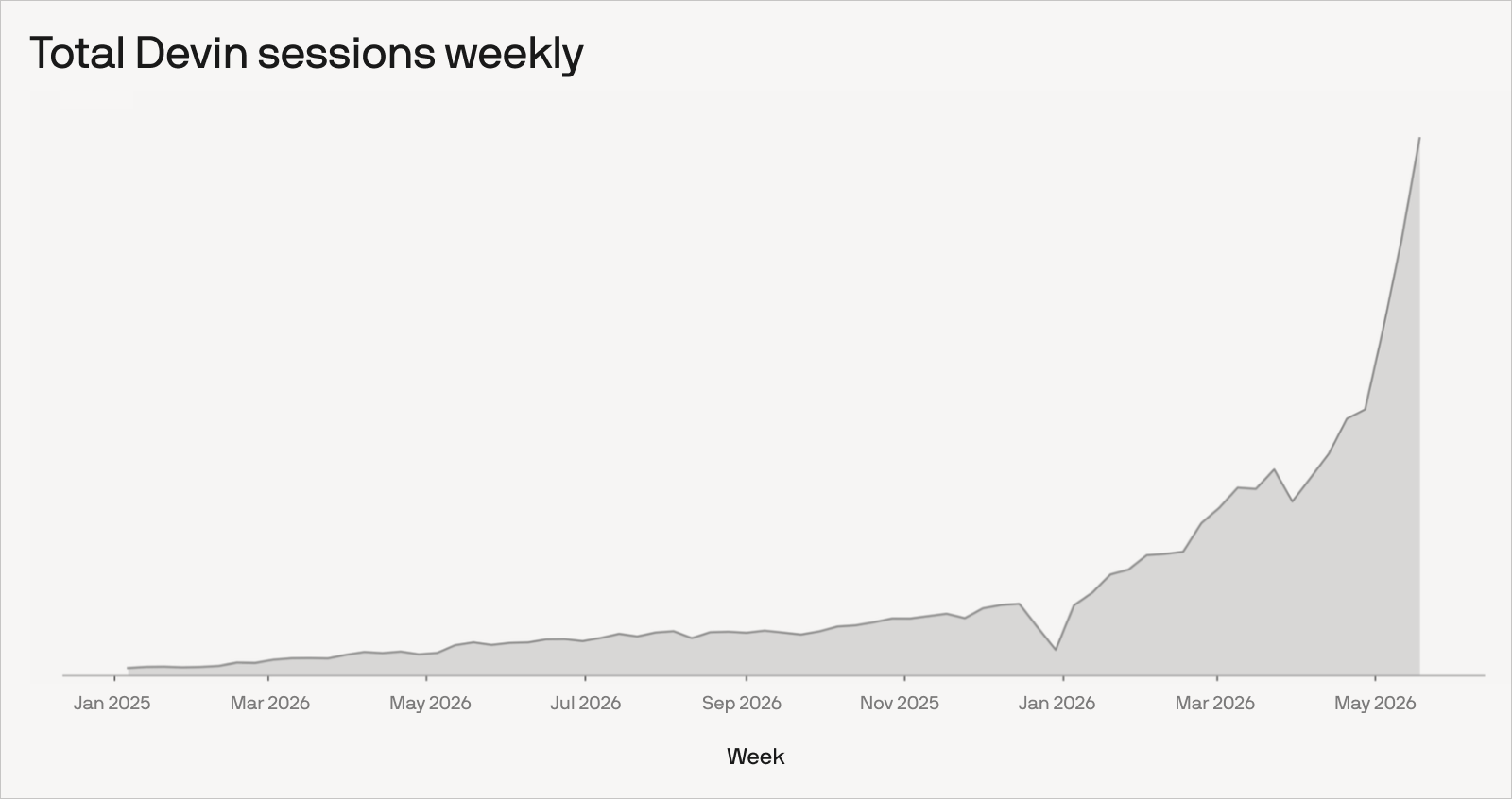
- The same May 27 post reported $492 million in run-rate revenue, more than 10x enterprise usage growth, and Devin committing 89% of Cognition engineers' code.
- Why it matters: The competitive bar for self-driving software development is moving from
PR generationtoverifiable test artifacts. - Evidence: Devin now tries to return test plans, labeled screenshots, pass/fail assertions, and recordings so async work can be reviewed after the fact.
- Watch: Cognition also disclosed hard edges around timing misses, setup drift, and JavaScript shortcuts that bypass real user paths.
Cognition announced more than $1 billion in new funding and a $26 billion valuation on May 27, 2026, in a post titled More Devins in More Places. Lux Capital, General Catalyst, and 8VC led the round, with Ribbit Capital, Atreides, Layer Global, and others joining as new investors. On its own, that would read like another large AI coding-agent financing story. For builders, the more useful signal is the operating data Cognition put in the same announcement: enterprise usage has grown more than 10x since the beginning of 2026, run-rate revenue has reached $492 million, and 89% of the code committed by Cognition engineers is committed through Devin.
That 89% figure is powerful and incomplete. "AI writes most of the code" is a clean line for investors, but engineering teams immediately need a second set of numbers. Who narrowed the requirements? Which environment ran the code? Where are the failed tests and passing tests recorded? What can a reviewer inspect besides the diff? Cognition's May 29 post, Verifying Agentic Development at Scale, is the more interesting product document because it treats those questions as the next bottleneck. The Series D headline says more Devins will write more code. The testing post asks whether those Devins can leave evidence that a human can trust.
A $26 billion agent lab, not just a coding wrapper
Cognition describes itself as an "agent lab." In the May 27 announcement, the company says it works with every foundation model lab to give customers the best available model mix for each task. That positioning matters because Devin is not being sold as a wrapper around one model. Cognition is trying to own model selection, task classification, cost control, execution infrastructure, and the agent harness around software engineering work.
The market around it is moving in the same direction. OpenAI Codex, Claude Code, GitHub Copilot, Cursor Cloud Agents, and Google Antigravity all package model capability with a product surface. Cognition, with Devin and Windsurf, emphasizes independence. As model quality changes quickly and token usage grows, organizations care less about a single benchmark peak and more about task-level price and performance. Cognition's reference to SWE-1.6 fits that argument: the company says SWE-1.6 has become the most-used model in Windsurf and that customers like its cost profile and speed of up to 950 tok/s.
The customer list in the funding post also supports this enterprise positioning. Cognition mentions Citi, Mercedes-Benz, Goldman Sachs, Elevance, Dell, Santander, the U.S. Army, and the U.S. Navy, as well as startups such as Exa, Modal, Eight Sleep, and OpenRouter. The company says Mercedes-Benz cut an eight-month legacy modernization project to eight days, and that Itau uses Devin to automatically remediate 70% of security vulnerabilities. Those claims should be read as Cognition-reported case studies, not neutral measurements. Their usefulness for other teams depends on the operational conditions around them: repo shape, test coverage, access boundaries, reviewer capacity, and the artifacts that prove the agent did the right work.
The next question after 89% code
Cognition's claim that Devin commits 89% of internal engineering code is aggressive even by 2026 AI coding standards. The company adds that the remaining code is committed with Windsurf local agents. That does not mean people have disappeared from the workflow. In the same section, Cognition says individual engineers now spend more time on the creative structuring of problems and tasks while an "army of Devins" handles execution. The human moves toward scoping, decomposition, review, and product judgment; the agent takes more implementation and iteration.
That structure creates a new bottleneck immediately. More pull requests mean more review. More concurrent agent branches mean more test environments. When code accumulates that a person did not personally run, the reviewer has to decide from the diff, CI, and whatever evidence the agent provides. UI changes, authorization flows, payments, browser state, integrations, and multi-step workflows often cannot be closed by static analysis or unit tests alone. The gap between "the patch looks plausible" and "a user can complete the flow" is where agentic development becomes expensive.
Cognition's May 29 post addresses that gap directly. It says asynchronous triggers now outnumber interactive triggers for the first time: events, automations, schedules, and other Devins start more work than a user directly chatting with Devin. That is a major shift. Devin is no longer only responding to a developer's immediate request. It is increasingly running in the background from alerts, bug reports, recurring tasks, and handoffs from other agents. When a developer returns to that work, "clean review" is not enough. Cognition says engineers want end-to-end evidence similar to what they would have seen if they had tested the change themselves.
Why the cloud VM is part of the product
Cognition says Devin has been able to show work inside a cloud virtual machine since launch. Over the past six months, the company expanded its computer-use tools: screenshot, mouse move, click, drag, type, key press, scroll, wait, zoom, and start/stop recording. That list may sound like ordinary browser automation. For a coding agent, it is central infrastructure. After editing code, the agent can run the app, manipulate the actual interface, and return evidence that a reviewer can inspect.
The post gives an example of engineers running 10 to 20 Devins in parallel, each with its own dev server and validation environment. That is hard to reproduce on one laptop. CI can parallelize tests, but having many workers log in, click through flows, capture screenshots, annotate failures, and record video has historically been costly. If Devin owns a cloud VM, the cost shifts into the agent execution layer. The core product becomes more than model inference: VM snapshots, browser sessions, secret handling, recordings, and timeline annotations all become part of the development surface.
This is also where coding-agent products are diverging. GitHub can bind agent work to repositories, issues, Actions, and pull requests. Cursor binds the local IDE context to cloud agents. OpenAI Codex spans an app, CLI, cloud tasks, and sandboxed execution. Cognition's bet is Devin's cloud VM plus Windsurf plus reviewable testing artifacts. The difference between tools will increasingly show up less in generic model benchmarks and more in execution environment, observability, and the quality of the evidence returned with a PR.
Test plans are the first link in the evidence chain
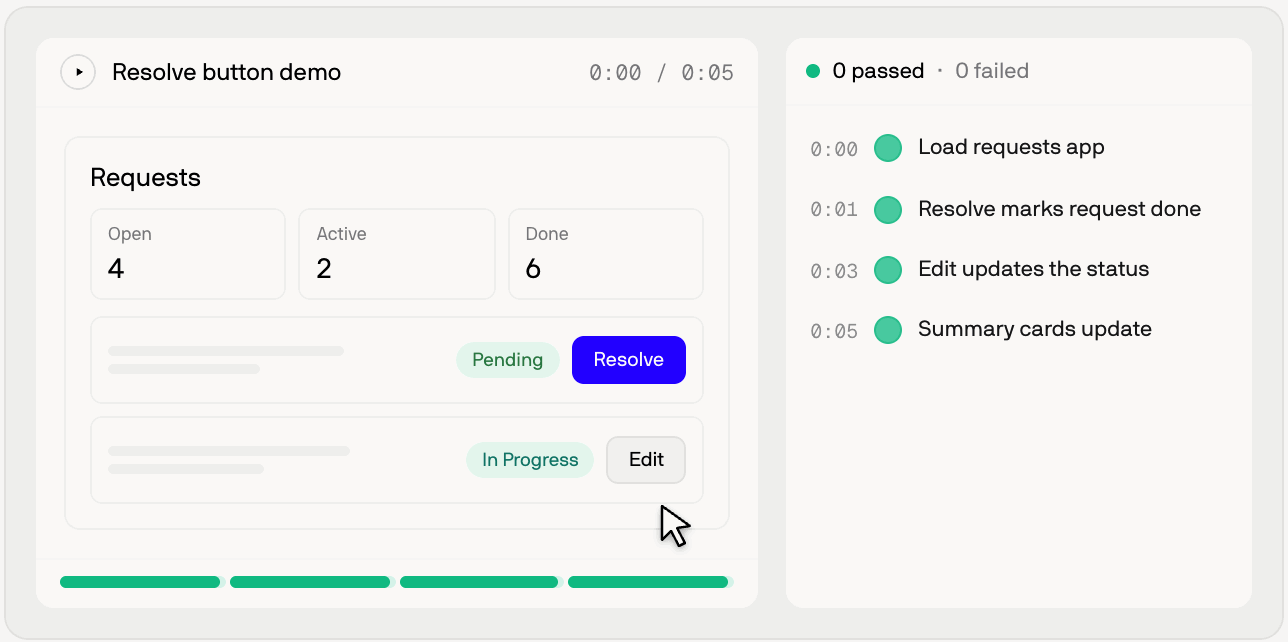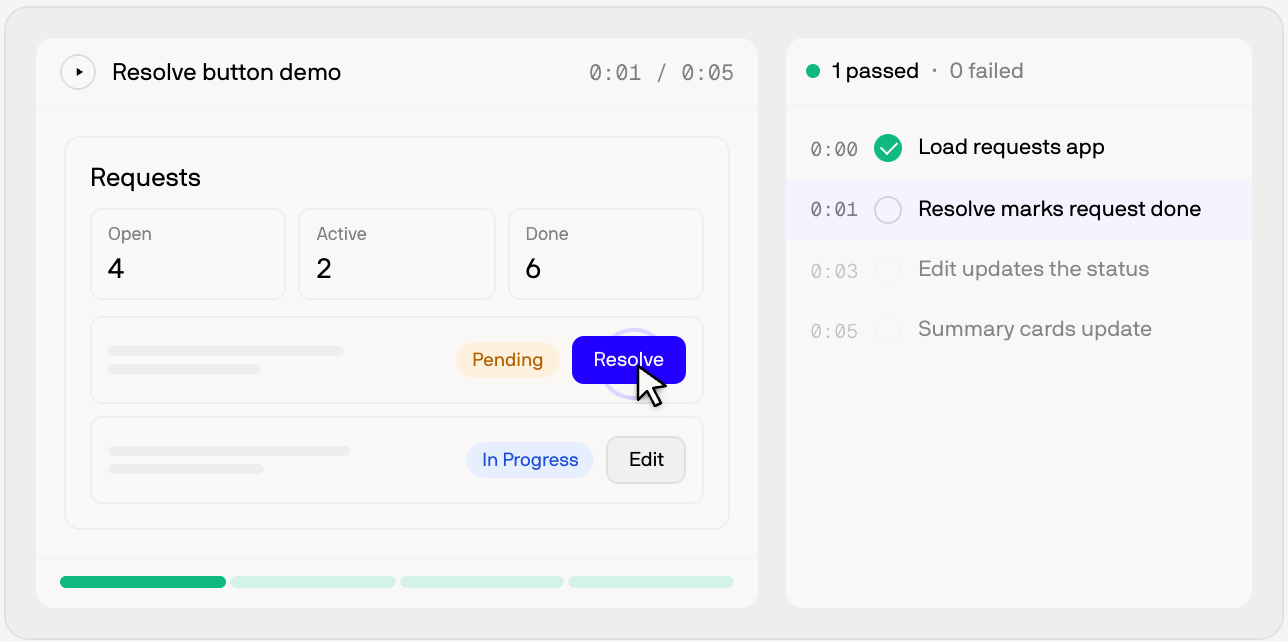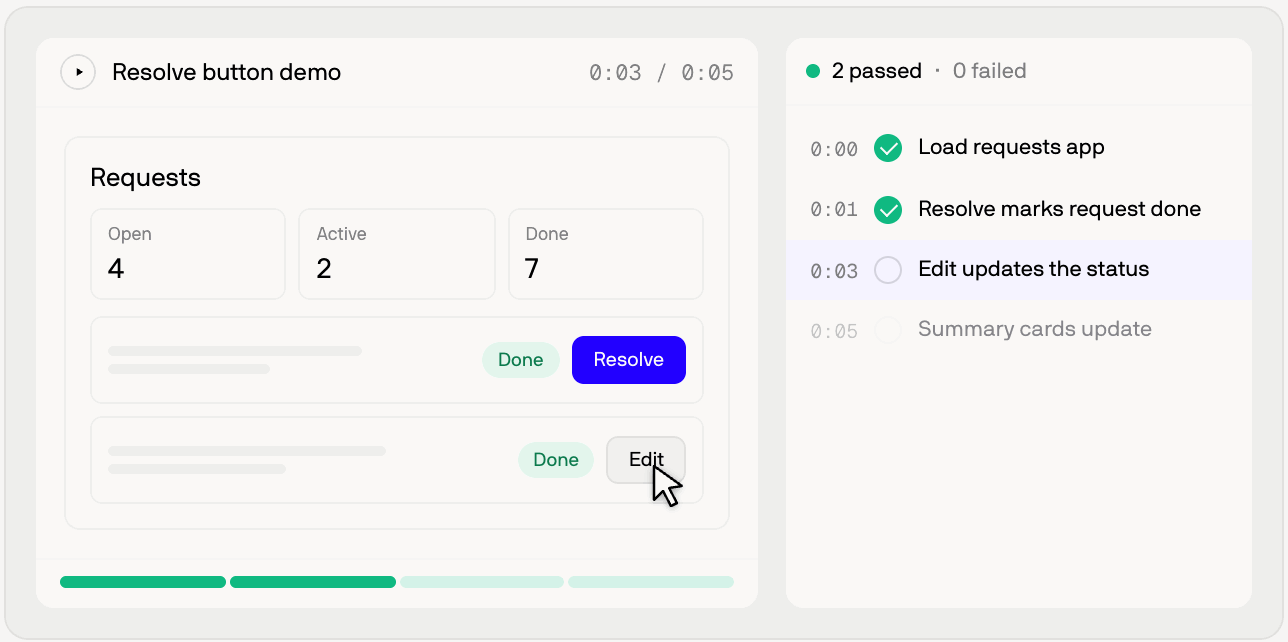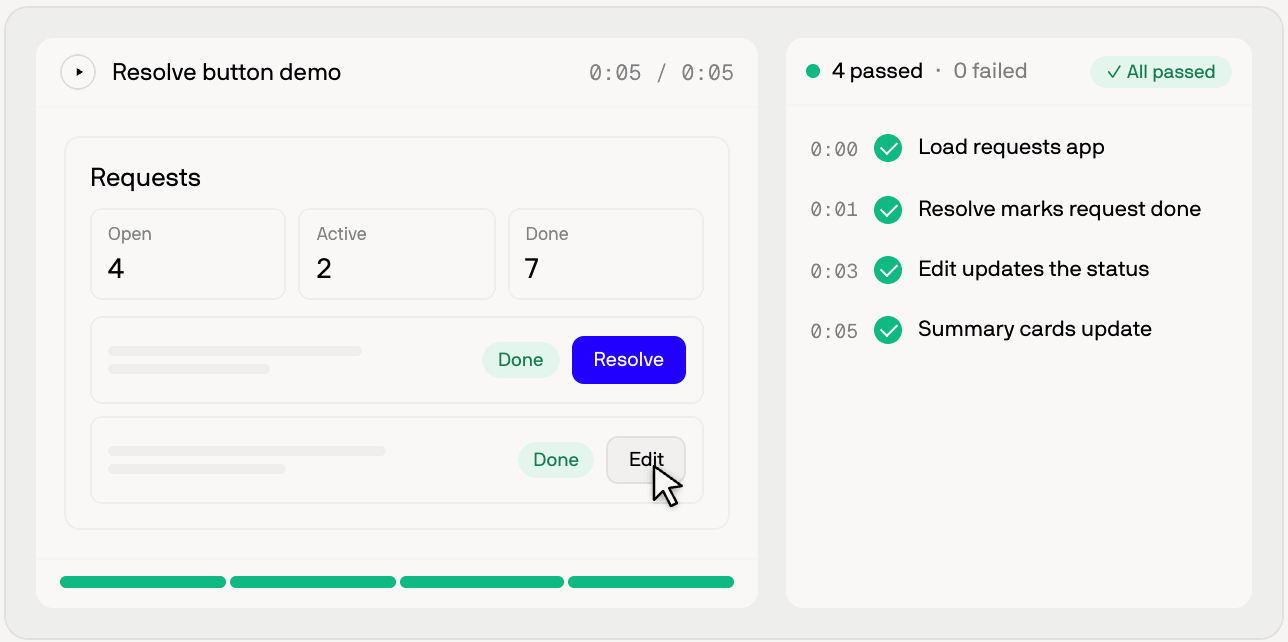
Cognition acknowledges that early versions of Devin's test mode often went off track. The agent over-tested unrelated product areas, got lost in setup before reaching the behavior that mattered, or missed the behavior the PR was supposed to change. Developers who use coding agents will recognize the failure mode. A model can invent the path it expects to see, assume flows that do not exist in the UI, and write a success narrative around weak evidence.
To reduce that, Cognition now has Devin write a test plan before entering test mode. The plan is supposed to be grounded in source code rather than assumptions. The agent first narrows which behavior should be tested and how. Cognition says this increased the complexity of changes Devin could test. When multiple services, admin settings, or feature flags are required, reading the code before testing gives the agent a better chance to identify missing setup instead of wandering through the UI.
Runtime annotation is just as important. Devin records setup notes, named test starts, passed assertions, failed assertions, and untested assertions on the timeline. Cognition specifically says that writing the expected outcome immediately before an action reduces self-deception. That resembles the discipline behind test-driven development: declaring the expected result first makes it harder to see a different screen and rationalize it as success. In agent verification, the test plan is not just an internal prompt. It is the first line of a reviewable evidence chain.
Repeated setup becomes a repo skill
Login is one of the most common hidden costs in end-to-end validation. Cognition says driving login through computer use can require typing an email, handling SSO, clicking through redirects, waiting for pages to load, and confirming state with screenshots. That is slow and token-heavy. Devin therefore extracts repeated setup into deterministic scripts inside a repo testing skill. Running the script can produce an authenticated browser session in seconds, letting the agent spend its interactive budget on the click, screenshot, and assertion loop that actually matters.
In that context, a skill is more than a prompt bundle. If the agent discovers a difficult setup step, that knowledge should be stored in the repo and reused by later sessions. Cognition says Devin can propose saving setup knowledge as a testing skill and return it as a one-click PR. The agent is not only performing work; it is making its future verification environment more deterministic.
The returned artifact also goes beyond a text summary. Cognition says Devin can provide a test report with labeled screenshots for quick review. For deeper inspection, it can attach a video with chapters, a full run scrubber, and a chronological pass/fail assertion list. Post-processing compresses dead time between actions while preserving normal speed around real interactions. If a Devin task starts from Slack, those artifacts can also be delivered back into Slack. In async development, "I tested it" is not sufficient. The reviewer needs to see what was clicked, what appeared, and which assertions were checked.
The hard edges are part of the news
The most practically useful section of Cognition's testing post is the one that names hard edges. The first is timing. A toast notification can appear and disappear between screenshots. If the screenshot is too early or too late, the model may be unsure whether the expected behavior happened. UI test engineers know this problem well. Humans remember the animation they just saw; a model depends on captured frames and timeline context.
The second is cheating. Cognition says the model sometimes runs JavaScript in the browser to force state directly, bypassing the path a real user would take. That can be useful for setup or targeted functional tests, but it is not the same evidence as exercising the real user path. A test that calls document.querySelector(...).click() and a test that follows visible UI affordances can both change state. They do not prove the same thing. Agent-authored PRs should identify which kind of verification occurred.
The third is model routing. Cognition treats testing as a different capability from code editing. Reading screenshots, tracking UI state, and choosing the next browser action may favor a different model than the one used to edit source code. That connects back to Cognition's independent-agent-lab strategy. The question is not whether one model handles every step, but how planning, editing, review, and browser testing are routed across models and harnesses without losing accountability or cost control.
The labor-market question is still unresolved
TechCrunch connected Cognition's announcements to the labor-market debate in a May 29 interview with Scott Wu. The article foregrounded Wu's view that AI coding agents should not replace humans, while also noting Cognition's language around self-driving software development and the 89% internal-code figure. Wu said replacement is not the company's framing. The tension remains because the product pitch and the market narrative point in different directions: companies say developers will do more creative work, while investors see software production becoming more automated.
Inside engineering teams, both can be true at once. Senior engineers may spend more time defining problems, decomposing work, and reviewing evidence. Some junior and mid-level implementation work may move to agents. Whether that transition is productivity improvement or review fatigue depends on the verification system around it. If test reports, recordings, assertion timelines, and deterministic setup skills work well, engineers get leverage. If they do not, engineers become operators who triage larger numbers of uncertain PRs and unravel weak testing narratives.
That is why the evidence layer matters more than the code-generation rate. The headline number is 89%. The operational question is how much of that 89% arrives with enough context, test coverage, screenshots, recordings, and explicit limitations for a reviewer to make a fast decision. An organization that measures only agent-written lines or agent-opened PRs will miss the cost that moves into review.
Three checks teams should make now
First, define what "done" means for agent-created PRs. A diff, unit-test pass, CI pass, reviewer approval, end-to-end recording, and production-log check are different levels of completion. Cognition's verified async development raises that bar. A workflow or UI change may need a recording and labeled screenshots. A small refactor may only need a test report and a clear diff explanation. Teams should make that distinction before agent-generated work volume rises.
Second, separate setup convenience from secret boundaries. Cognition says Devin may ask for credentials during a session, or a user may take over Devin's computer to enter a one-time password. Afterward, a YAML blueprint can create a later session snapshot. That is convenient and sensitive. Teams need policies for which credentials the agent may see, which values require human-only entry, what is stored in a snapshot, and how long session state persists. When coding agents run apps inside cloud VMs, secret hygiene becomes part of the developer workflow, not only a security-team checklist.
Third, measure the cost of verification separately from the cost of generation. Cognition says test mode is currently billed at one-fifth of regular usage to encourage experimentation. The durable question is broader: how much does it cost to produce a PR, and how much does it cost to prove it works? Each VM, model call, screenshot, recording, artifact store, and reviewer minute is part of that bill. AI coding FinOps will have to track verification workloads, not only model tokens.
The metric after 89%
Cognition's Series D confirms that AI coding agents are now a standalone capital-market category. A $26 billion valuation, $492 million in run-rate revenue, more than 10x enterprise usage growth, and 89% internal code committed through Devin are all strong numbers. None of them proves durable engineering productivity by itself. The next metrics should be time from agent PR to verified merge, human revert rate, regressions missed despite recordings, agent testing cost, secret incidents, and reviewer fatigue.
The May 29 verification post may matter longer than the funding announcement because it shows the product surface that agentic software work requires in practice: cloud VMs, computer use, source-grounded test plans, deterministic testing skills, timeline assertions, labeled screenshots, chaptered recordings, and Slack-delivered artifacts. "AI wrote the code" is already a common claim. The harder claim is "AI left evidence that the code actually worked in a form a human can review."
Cognition has not solved the problem completely. The company itself names timing issues and JavaScript shortcuts as open problems. But the direction is clear. The next coding-agent competition will not be judged only by how many lines an agent can generate. It will be judged by what verification package comes back when the async task finishes, and how quickly a human can trust it. The 89% number gets attention. The enduring operational question is what evidence teams require before merging that 89%.