Two H100s Are Enough, Command A+ Targets Private Agents
Cohere Command A+ lowers the bar for private AI agents with Apache 2.0 open weights and a two-H100 deployment target.

- What happened: Cohere released
Command A+as an Apache 2.0 open-weights model.- It is a 218B total parameter MoE model with 25B active parameters, and Cohere points to W4A4 deployment on 2 H100s or 1 B200.
- Why it matters: The open-model race is shifting from benchmark scores to the operating cost of private agents.
- Watch: Two H100s are still not cheap, and Cohere's internal North evaluations should be separated from independently reproducible evidence.
Cohere released Command A+ on May 20, 2026. On the surface, this is another open-weights LLM launch. The more important sentence in the announcement is not "the strongest model." It is the claim that the model can run on "2 H100s or 1 B200." When AI teams try to move agents into real workflows, model scores are only one part of the problem. They also have to ask whether data can leave the organization, whether inference cost fits the loop, whether latency breaks multi-step work, and whether security teams can accept the deployment path.
Cohere's official announcement frames Command A+ around "sovereign agentic capabilities." That can sound like marketing language, but the model card tries to back it with numbers. Command A+ is a sparse MoE model with 218B total parameters, while a single inference activates 25B parameters. It supports a 128K input context, up to 64K tokens of generation, image input, reasoning, tool use, and text workflows in one model. The license is Apache 2.0.
That combination sends a clear signal to developers. Cohere is aiming at the space between "enterprise models that are only consumed through an API" and "large open models that communities can download but struggle to put into production." Whether Command A+ actually occupies that space is still an open question. But the launch changes the question that matters in open-model competition. It is no longer enough to ask how many points a model gets on a benchmark. Teams also need to ask whether they can run it as an agent inside their own data boundary.
The numbers Cohere chose to emphasize
Start with the core specs. Cohere's documentation lists the model ID as command-a-plus-05-2026 and names reasoning, multilingual support, image inputs, citations, tool use, and structured outputs as capabilities. The same documentation describes Command A+ as Cohere's first Mixture-of-Experts model and says it supports 48 languages. The key detail is less the feature list than the hardware requirement. Cohere says the MoE architecture is intended to balance accuracy, throughput, latency, and GPU demand.
The Hugging Face W4A4 model card is more direct. Cohere publishes BF16, FP8, and W4A4 quantizations. Its sample minimum GPU requirements are 4 B200s or 8 H100s for BF16, 2 B200s or 4 H100s for FP8, and 1 B200 or 2 H100s for W4A4. Cohere says the quality differences between the three quantizations are negligible and recommends W4A4 for most use cases. That claim needs independent validation, but the message is clear: Cohere wants to lower the minimum line for private deployment.
This is not the same as saying the model is cheap. Two H100s are still not casual hardware for an individual developer or a small team. Inside enterprise AI budgets, however, the threshold has a different meaning. If an organization has heavy API usage, strict data security requirements, or a need to run models in a specific region or dedicated infrastructure, two H100s can be the difference between "impractical research model" and "operational option worth evaluating." Agents intensify that calculation because they make repeated calls. Tool selection, retrieval, verification, retries, file reads, and table analysis quickly accumulate tokens and latency. That makes the cost profile of an agent model more sensitive than a chatbot price sheet.
25B active matters more than 218B total
The most marketable number in Command A+ is 218B. From an operations perspective, the more important number is 25B active. MoE models do not use every parameter on every inference. They activate a subset of experts for a given input and try to trade a large total capacity for lower active compute. If that works well, a model can preserve breadth across tasks while reducing inference cost. If routing, cache behavior, quantization, or kernels are unstable, the advantage on the spec sheet can fade in production.
This is also why Cohere keeps returning to North in the announcement. North is Cohere's enterprise AI platform for work. The launch post says Command A+ came from a year of deploying North with customers and learning what they needed. In other words, Cohere is not positioning this as an open chat leaderboard model first. It is arguing that the model was shaped around work agents that repeatedly touch enterprise documents, file systems, spreadsheets, memory, and tools.
That claim is interesting because agent quality differs from general chat quality. An agent has to do more than write a plausible paragraph. It must remember instructions inside a constrained context, choose the right tool, recover after failure, leave evidence, and run repeated tasks without blowing up cost or latency. A slightly smarter model can still be a bad fit if it is slow and expensive. A model that does not lead every leaderboard can be a better workhorse if it is fast, steady, and deployable in the right environment.
The benchmarks point toward agents
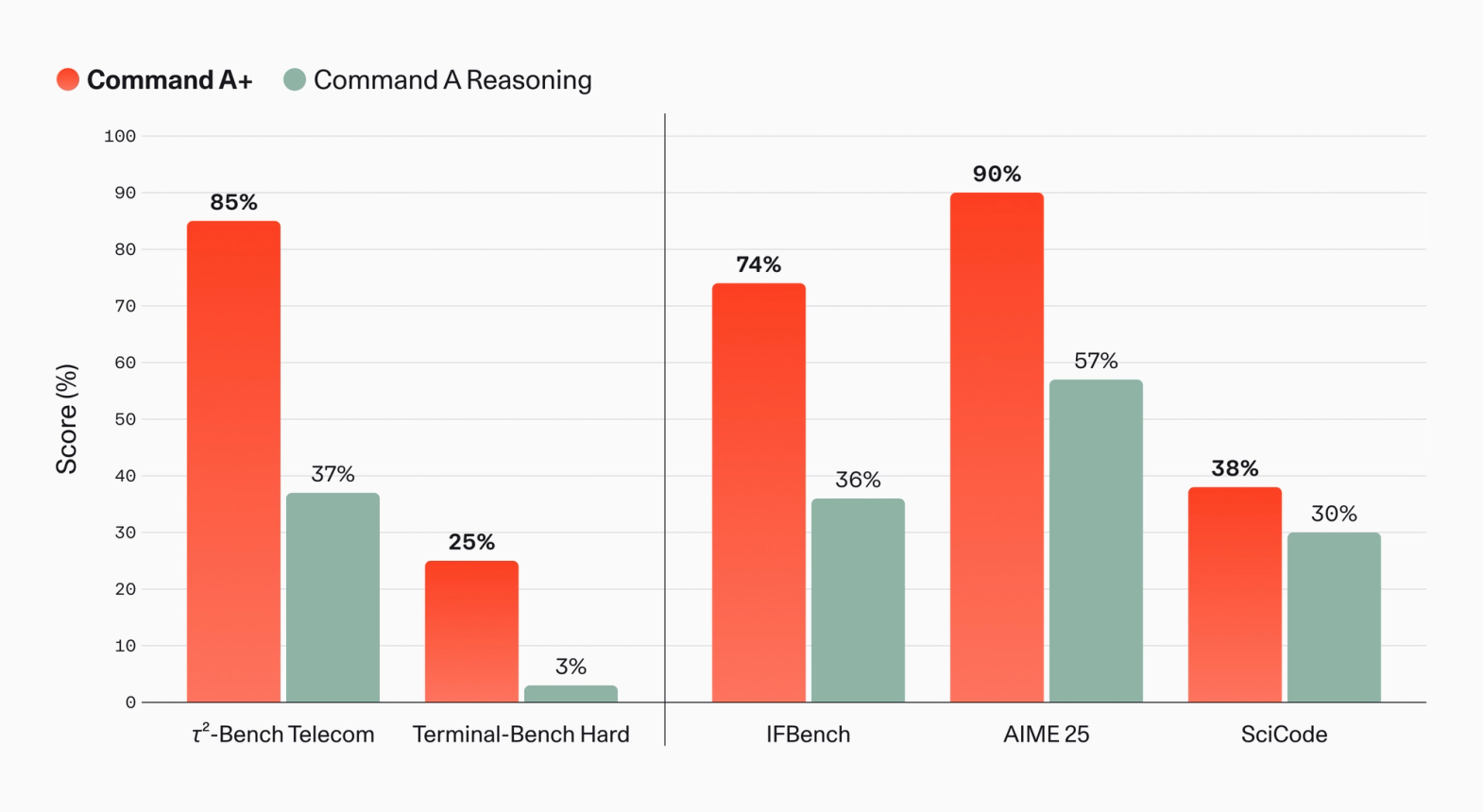
The most interesting numbers in Cohere's chart are not only the traditional math scores. Cohere says Command A+ improves over Command A Reasoning from 37% to 85% on tau2-Bench Telecom and from 3% to 25% on Terminal-Bench Hard. It also reports gains from 36% to 74% on IFBench, from 57% to 90% on AIME 25, and from 30% to 38% on SciCode. For readers who care about agents and code execution loops, Terminal-Bench Hard and tau2-Bench Telecom are especially relevant. Terminal-Bench-style tasks try to measure how well a model can complete longer work in a terminal environment.
Benchmarks are questions, not conclusions. Cohere's chart indicates the direction of improvement, but teams still care about failure rates on their own work. A coding agent fixing pull requests in an internal repository needs test execution, log interpretation, file navigation, patching, and review comment handling. A customer support agent needs ticket state, CRM data, knowledge-base retrieval, permission boundaries, and audit logs. A telecom or financial institution adds internal terminology and system constraints. Public benchmarks compress that complexity into a few numbers.
Cohere also published internal North evaluations. According to the announcement, Agentic Question Answering accuracy improved by 20% over Command A Reasoning, spreadsheet analysis quality improved by 32%, and memory performance rose from 39% to 54%. The company also states that these internal evaluations use an LLM-as-a-judge method. That method is useful for comparing product behavior quickly, but it is sensitive to the judging prompt, judge model, and sample design. These figures are useful for understanding which work Cohere cares about. They should not yet be treated as externally reproducible performance.
The open-model competition is moving
Open-model competition has split into several directions. DeepSeek and Qwen have pushed strong performance and broad developer access. Mistral has combined European open models with enterprise deployment. Meta's Llama family still has enormous ecosystem and tooling gravity. Cohere is entering the same arena while choosing a different set of words: sovereign, private deployment, enterprise workhorse, and North.
Those words can sound dull to developers. In real buying and operations decisions, dull words move budgets. Teams need to know where data goes, whether logs remain under control, whether weights can be inspected, whether a model can run in a specific region, whether customer data is used for training, and how incident response and SLAs work. Open weights do not solve all of those requirements automatically. They do, however, create the option to download, test, deploy privately, fine-tune where appropriate, and change routing strategies.
Apache 2.0 matters in this context. Many "open" models carry commercial restrictions or require separate agreements for some uses. Apache 2.0 is comparatively straightforward for enterprise legal and security review. Teams still need to evaluate model usage policies, dataset provenance, and regulatory requirements in their deployment environment. But a clear license reduces the friction of internal experimentation. Developers can build a proof of concept first, while legal and security teams review concrete deployment conditions rather than an abstract model announcement.
A small signal for multilingual cost
One less flashy but important detail in the Command A+ announcement is the tokenizer. Cohere says its newer tokenizer reduces the number of tokens needed to generate the same responses, with claimed efficiency gains of 20% for Arabic, 16% for Korean, and 18% for Japanese. This is less dramatic than a benchmark jump, but it matters for global product teams. LLM cost is not only about the number of model calls. It also depends on how many tokens the same meaning requires.
Teams that have attached English-centric models to Korean products know this problem. If token segmentation is inefficient, both input and output costs rise for the same content. Retrieval-augmented generation makes document chunks longer, and agents keep adding intermediate state and tool results into context. A 16% improvement can look minor on a single answer, but it compounds in high-volume automation. For languages that often pay a penalty with English-centered tokenizers, tokenizer efficiency belongs in the deployment cost model.
That still needs to be measured on real data. Tokenizer efficiency varies by document type. Support conversations, legal documents, developer docs, tables, logs, and code comments tokenize differently. A team evaluating Command A+ should measure token counts and latency on 1,000 to 10,000 internal samples before over-indexing on public benchmarks. Model choices are finalized by cost tables and incident tables, not by launch charts.
The community will test practicality first
The LocalLLaMA community reaction fits the same theme. Cohere co-founder Nick Frosst shared Command A+ in a Reddit thread and described the goal as building a fast, responsive, practical model rather than optimizing only for top-line performance. He also pointed to quantization work intended to make the model run well on one or two GPUs. That message is close to what open-model users actually ask: not just "How smart is it?" but "Does it run on my hardware?", "Is the license usable?", and "Are tool calling and long context stable?"
The reaction is not purely optimistic. A separate LocalLLaMA post about MLX porting discussed attempts to run the W4A4 model on Apple Silicon, but the reported memory requirement was around 132GB, leaving a 128GB M3 Max short of direct verification. That is the reality of Command A+. When Cohere says "2 H100s," the model becomes more accessible to enterprises and advanced labs, but it remains a large model for ordinary local LLM users. Open weights do not automatically mean broadly local-friendly.
The start of community verification still matters. Open models are tested almost immediately across vLLM, SGLang, Transformers, MLX, and other serving paths. Someone measures memory usage. Someone tests tool calling. Someone compares quantization quality. Someone finds failure modes. For enterprises, that public verification is valuable. Closed API models require customers to trust the vendor's quality and SLA. Open-weights models allow the community to slowly accumulate failure evidence. That evidence can reduce the risk of internal adoption.
The checklist for development teams
Command A+ does not primarily ask development teams to swap models. It adds another option to the agent deployment strategy. First, teams should decide whether sensitive workflows can continue using API models or need private deployment. Second, they should measure the number of calls and average context length inside their agent loops. Third, they should test failure recovery, tool use, citations, structured output, and latency distribution instead of only benchmark scores. Fourth, they should calculate the opportunity cost of dedicating two H100s or one B200 to a single model path.
An internal agent is not "one model." It also needs a retrieval index, permission filters, file connectors, queues, task logs, approval UI, evaluation sets, human review, and monitoring. Apache 2.0 does not make that operating layer free. But private model deployment gives teams more freedom in how they design it. They can avoid sending prompts and logs to an external API, process sensitive documents inside their network, and tune inference servers and cache policies for a specific workload.
This is where Command A+ connects to Cohere's broader strategy. Cohere has been pushing enterprise work through North, while also building a model portfolio around transcription, embedding, reranking, and regulated document workflows. Command A+ is positioned as the central model in that stack. So this news is less "Cohere released a bigger model" and more "Cohere is trying to productize the minimum conditions for privately deployed agents."
The conclusion is still in deployment
The strongest claim around Command A+ is not the model size. It is the operating claim. Opening a 218B MoE model under Apache 2.0 and saying that W4A4 can run on 2 H100s is an attempt to shift the baseline of open-model competition. If the model is fast and reliable enough for enterprise agent workloads, private deployment stops being only the compromise teams make for security. It becomes a practical option for cost, control, and auditability.
The conclusion is not in the launch post yet. It will come from external benchmarks, community serving logs, internal proofs of concept, and long-running agent failure rates. The two-H100 promise is attractive, but the operating system built around it remains heavy. Teams still need to verify whether the agent reads files well, chooses tools correctly, maintains state over long work, and actually reduces cost on multilingual documents.
That makes Command A+ less a model every team should immediately adopt and more a marker for where the open-model race is heading. Bigger models, higher scores, and longer context windows are not enough. As AI agents move inside organizations, the decisive factors become deployment rights, cost, latency, auditability, and the operational surface for observing failure. The numbers Cohere published point clearly in that direction. The next competition for private agents may be less about model size and more about how far a model can be brought inside an organization.