Claude Code Dynamic Workflows Put 1,000-Agent Runs Behind a Token Warning
Anthropic introduced Claude Code dynamic workflows, a research preview that lets Claude write orchestration scripts for large coding tasks while exposing new cost and permission risks.

- What happened: Anthropic released Claude Code
dynamic workflowsas a research preview on May 28, 2026.- Claude writes a task-specific JavaScript orchestration script, then a separate runtime coordinates dozens or hundreds of subagents.
- The numbers: The official docs list a
16-agent concurrency limit and a1,000-agent cap per workflow run.- Anthropic points to Bun's Zig-to-Rust port:
99.8%of the existing test suite passing, about750,000lines of Rust, and an11-day path from first commit to merge.
- Anthropic points to Bun's Zig-to-Rust port:
- Watch: Workflows consume plan usage and rate limits, and early community reactions focus on
ultracodetoken burn, loops, and per-agent guardrails.
Anthropic introduced Claude Code dynamic workflows on May 28, 2026, alongside Claude Opus 4.8. The announcement headline is easy to summarize: Claude Code can now run dozens or hundreds of subagents in parallel. The more durable change is where orchestration lives. Instead of deciding the next tool call inside a normal chat turn, Claude writes a JavaScript script for the task, and a workflow runtime executes that script outside the conversation loop.
The official launch frames the feature as a research preview for problems that one agent should not handle in a single pass: codebase-wide bug hunts, profiler-guided optimization audits, security reviews, framework migrations, API deprecations, and language ports. Claude decomposes a task, sends independent agents into different parts of the repository, asks other agents to challenge the findings, and returns only the synthesized result. That moves Claude Code closer to a scheduler for software work, not just a response generator with tools.
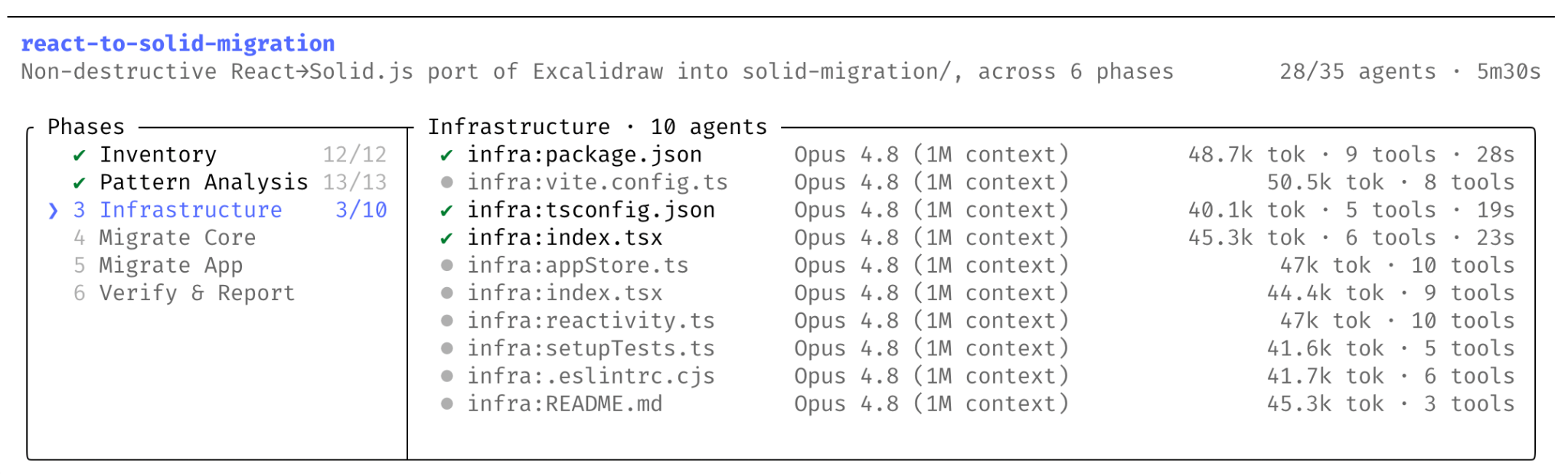
The Claude Code workflow docs define the mechanism more narrowly. A dynamic workflow is a JavaScript script written by Claude and run by a separate runtime. Intermediate state stays in script variables rather than expanding Claude's context window. Anthropic's docs distinguish the primitives this way: a subagent is a worker, a skill is an instruction, and a workflow is an executable script. The reusable asset is not only a prompt or an agent definition, but the orchestration itself.
That design attacks two familiar bottlenecks in long coding-agent runs: context pressure and coordination. In a conventional subagent pattern, Claude decides what to spawn turn by turn, and each result flows back into the conversation. Dynamic workflows keep loops, branches, and intermediate results in the runtime, so the main context can receive a final report instead of every investigation log. The tradeoff is direct: context may stay cleaner, but total token use can rise because many more agents are doing work.
Anthropic publishes concrete limits. The runtime can execute up to 16 agents concurrently, and a single workflow run can create up to 1,000 agents. The script itself does not directly access the filesystem or shell. Agents do the reading, writing, and command execution, while the script coordinates them. That is different from giving an AI an arbitrary shell script to run, but the practical risk is still real because spawned agents inherit the session's tool allowlist and permission posture.
Developers can invoke the feature in two ways. For a one-off workflow, the user includes the word workflow in the prompt. Claude Code highlights that word and enters script-writing mode instead of the ordinary chat loop. For sessions where Claude should decide when orchestration is useful, the user can enable /effort ultracode. Anthropic describes ultracode as xhigh reasoning effort plus automatic workflow orchestration. The docs also recommend returning to /effort high for routine work, which is a cost signal as much as a quality setting.
| Item | Subagent | Skill | Dynamic workflow |
|---|---|---|---|
| Where the plan lives | Claude context | Claude context and instructions | JavaScript script |
| Intermediate results | Returned to conversation turns | Returned to conversation turns | Held in script variables and runtime state |
| Scale | A few tasks per turn | Depends on instruction scope | 16 concurrent agents, 1,000 total agents per run |
| Resume behavior | Restart the turn | Restart the turn | Pause and resume inside the same session |
Availability is described slightly differently across launch surfaces. The blog says dynamic workflows are available in Claude Code CLI, Desktop, and the VS Code extension for Max, Team, and Enterprise plans, with Enterprise requiring an admin enablement step. It also names Claude API, Amazon Bedrock, Vertex AI, and Microsoft Foundry. The docs add a Claude Code version requirement, v2.1.154 or later, and describe paid-plan availability, with Pro users enabling the feature from the Dynamic workflows row in /config. The safest reading is that the launch post and docs are speaking to different user groups: product users, enterprise admins, and API or cloud-platform customers.
Anthropic's strongest proof point is the Bun port. The company says Jarred Sumner used dynamic workflows to port Bun from Zig to Rust. According to Anthropic, the port passed 99.8% of the existing test suite, produced roughly 750,000 lines of Rust, and went from first commit to merge in 11 days. One workflow mapped appropriate Rust lifetimes for each struct field in the Zig codebase. Another wrote corresponding .rs files for .zig files, with hundreds of agents working in parallel and two reviewer agents assigned per file.
Those numbers deserve attention, but not a victory lap. Anthropic explicitly says the Bun port is not yet production. The useful interpretation is narrower: codebase-scale migration has advanced far enough that Anthropic is willing to package agent orchestration as a product feature. A real engineering team still has to inspect failing tests, performance regressions, memory-safety behavior, public API compatibility, and the human review path that turned generated changes into an acceptable merge.
Claude Opus 4.8 gives the model-side context for the release. Anthropic says Opus 4.8 improves over Opus 4.7 on coding, agentic skill, reasoning, and professional-work benchmarks while keeping the same regular API price: $5 per million input tokens and $25 per million output tokens. Fast mode is listed at $10 per million input tokens and $50 per million output tokens. Anthropic says the new fast mode is 2.5 times faster and one-third the price of the previous fast mode.
For coding teams, the more practical model claim is about honesty. Anthropic says Opus 4.8 is roughly one-quarter as likely as the previous model to omit mention of flaws in code it wrote. That matters in a workflow system where multiple agents may generate, review, and reconcile changes before a user sees the final report. In long agent runs, the valuable signal is not only that a result was produced. It is whether uncertainty, skipped checks, and failure conditions survived the synthesis step.
The same release cycle also updates the Messages API. Anthropic says the API now accepts a system entry inside the messages array. Developers can update mid-task instructions without breaking prompt caches or abusing a user turn. Anthropic's examples include changing permissions, token budgets, and environment context. Dynamic workflows are a Claude Code product surface, but this API change points at the same runtime problem for custom agent harnesses: constraints need to change while a task is already running.
The workflow UI is built around observability rather than a single progress bar. The /workflows view shows each phase's agent count, token total, and elapsed time. Users can drill into phase and agent details, inspect prompts, recent tool calls, and results, pause or resume a run with p, stop an agent or the entire workflow with x, restart a running agent with r, and save the run script with s. The Desktop app presents an approval card with the workflow name, phase list, and token-usage warning.
Permissions need a careful read. The CLI prompt shows planned phases and lets the user run the workflow, skip further confirmation for that workflow, inspect the raw script, or cancel. The docs say Auto mode asks only before the first launch, while ultracode skips the prompt. The Desktop docs state that subagents spawned by a workflow always run in acceptEdits mode and inherit the session's tool allowlist. File edits are auto-approved in that path. Before a long workflow touches a real repository, branch isolation and tool permissions are not optional operational details.
Anthropic repeats the cost caveat in the launch post and docs. Dynamic workflows can use substantially more tokens than an ordinary Claude Code session because many agents run in parallel. Runs count against plan usage and rate limits, and all agents use the session model unless the script routes them differently. The docs suggest checking /model before large runs and explicitly telling Claude when weaker models are acceptable for stages that do not need the strongest model.
Early community reaction has centered on the same issue. Reddit threads in Claude Code and ClaudeAI communities describe ultracode as a large jump for code audits, research, and planning, but also warn about token black holes, subagent loops, and the need for per-agent fuses or hard iteration caps. The official 1,000-agent cap is not a guarantee against waste. It is the maximum blast radius for one run.
For team adoption, three questions come first. Which tasks are actually workflow-grade? A five-file bug fix is usually cheaper and faster as a normal session. Which branch, test command, package-install behavior, and network access may the workflow use? Those boundaries should be set before the run, not reconstructed afterward. How will phase-level token totals and agent results be attached to code review? "An AI reviewed it" is not auditable unless reviewers can see what was checked and what failed.
The competitive signal is that Claude Code is pulling agent orchestration into the product surface. OpenAI Codex, GitHub Copilot coding agent, Google Antigravity, Cursor, and other coding-agent tools are all trying to connect models to real repositories and development workflows. Claude Code's version is distinctive because the user does not have to design an agent team up front. Claude writes the workflow script, runs it, and can leave a saved command behind. For recurring audits, migrations, dependency cleanup, or review checklists, the script can become a team asset rather than a one-time transcript.
The failure mode also changes. A single-agent mistake can be reviewed through the diff and transcript. A hundred-agent workflow can fail because the task was decomposed poorly, one reviewer agent accepted a bad premise, a phase looped, or a command consumed budget without improving the result. In that world, /workflows token totals, elapsed time, phase details, and saved scripts become incident records. Coding-agent observability is moving from model logs toward orchestration logs.
A conservative first experiment is read-heavy and easy to sample: missing auth checks, deprecated API inventory, dead-code candidates, dependency upgrade risk, or security review scoping. Production migrations, broad rewrites, and deploy scripts that need secrets should wait until the team has branch isolation, permission boundaries, spending limits, and rollback paths in place. Anthropic's own first-run plan and token warnings are the product's way of saying this preview belongs inside a controlled workflow.
Claude Code dynamic workflows are less about "more agents" than "moving the plan out of chat and into an executable script." That can reduce context clutter and make orchestration reusable. It also adds new operating responsibilities: token budgets, loop control, permission inheritance, script review, and phase-level evidence. Opus 4.8 may be the model release attached to the announcement, but dynamic workflows are the part likely to shape how coding-agent tools are judged next: not only by answer quality, but by execution plans and reviewable verification records.