2.03배 토큰 처리량, EAGLE 3.1이 고친 추측의 흔들림
vLLM EAGLE 3.1은 speculative decoding의 attention drift를 줄여 long-context와 코딩 워크로드의 서빙 병목을 겨냥합니다.
- 무슨 일: vLLM, EAGLE, TorchSpec 팀이 EAGLE 3.1을 공개하고 vLLM main에 통합했습니다.
- 공식 발표일은 2026년 5월 26일이며, vLLM nightly와 upcoming
v0.22.0경로가 예고됐습니다.
- 공식 발표일은 2026년 5월 26일이며, vLLM nightly와 upcoming
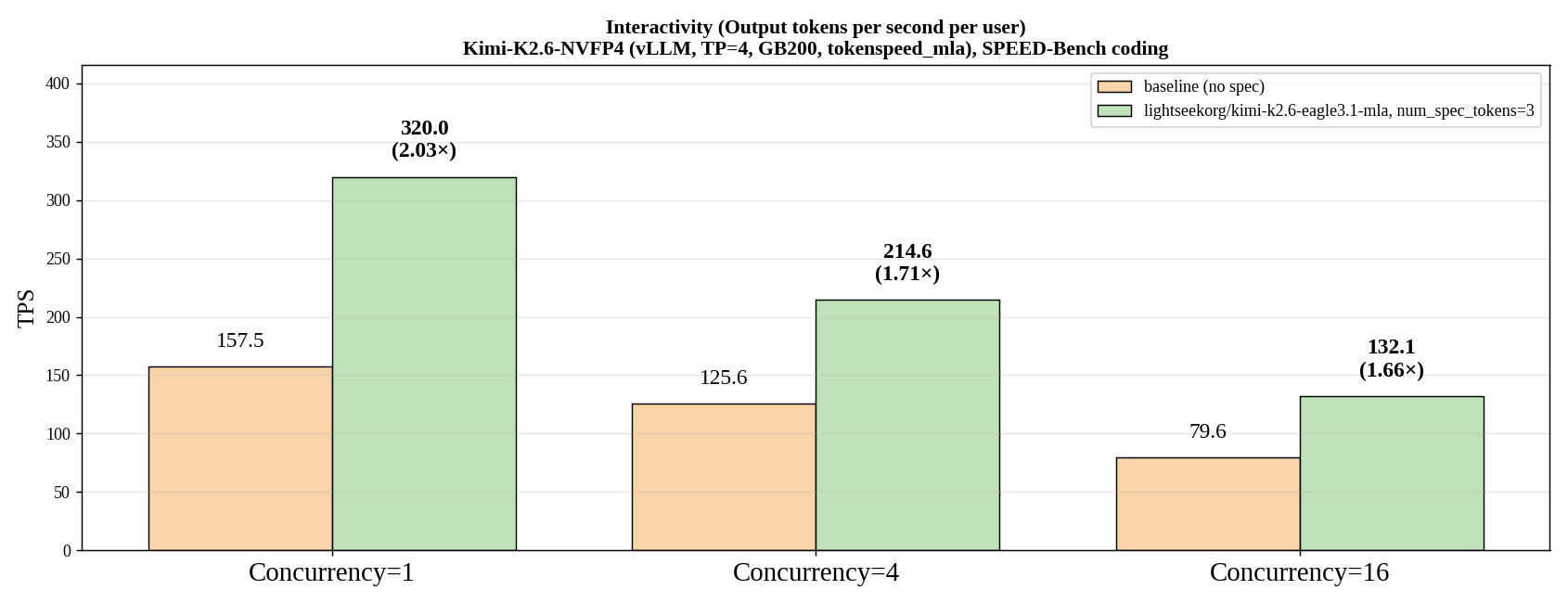
- 핵심 수치: Kimi-K2.6-NVFP4, GB200, SPEED-Bench coding에서 concurrency 1 기준 2.03배 per-user output throughput입니다.
- 의미: speculative decoding의 병목이 "작은 drafter를 붙인다"가 아니라 drafter가 언제 흔들리는지를 관리하는 문제로 이동했습니다.
- 논문은 이를
attention drift라고 부르며, long-context와 template perturbation에서 acceptance length가 흔들리는 이유를 설명합니다.
- 논문은 이를
- 주의점: 수치는 특정 모델, 하드웨어, benchmark 조건의 초기 결과입니다. 실제 서비스에서는 prompt 형식, batch, quantization, fallback 정책을 같이 봐야 합니다.
vLLM 블로그에 올라온 EAGLE 3.1 발표는 겉으로 보면 작은 런타임 업데이트처럼 보입니다. 새 frontier model도 아니고, 소비자용 앱도 아니며, 화려한 UI도 없습니다. 하지만 AI 제품을 실제로 서빙하는 팀에게는 꽤 중요한 신호입니다. LLM 추론 비용의 병목이 점점 "어떤 모델을 쓰는가"에서 "토큰을 어떤 방식으로 검증하고 흘려보내는가"로 내려오고 있기 때문입니다.
이번 발표의 주체는 EAGLE Team, vLLM Team, TorchSpec Team입니다. 세 팀은 2026년 5월 26일 EAGLE 3.1을 공개하면서, speculative decoding의 안정성과 배포성을 개선했다고 설명했습니다. vLLM 쪽에서는 이미 main branch에 지원이 merge됐고, nightly release와 upcoming v0.22.0에서 사용할 수 있을 예정이라고 밝혔습니다. Hugging Face에는 Kimi-K2.6-NVFP4용 draft model인 lightseekorg/kimi-k2.6-eagle3.1-mla도 공개됐습니다.
뉴스의 표면적인 숫자는 선명합니다. vLLM 발표는 Kimi-K2.6-NVFP4, tensor parallel size 4, GB200, non-disaggregated serving, SPEED-Bench coding dataset 조건에서 EAGLE 3.1이 no-spec baseline 대비 per-user output throughput을 concurrency 1에서 2.03배 높였다고 말합니다. concurrency가 4로 올라가도 1.71배, 16에서도 1.66배의 speedup이 남았다고 합니다. 대규모 에이전트 워크로드는 단일 사용자의 빠른 응답만이 아니라 여러 세션이 동시에 긴 tool loop를 도는 조건에서 버텨야 하므로, concurrency가 올라간 뒤에도 이득이 남는지가 중요합니다.
speculative decoding의 약속과 운영 현실
Speculative decoding은 간단히 말해 "작은 모델이 먼저 추측하고, 큰 모델이 빠르게 검증한다"는 전략입니다. target model이 한 토큰씩 순차적으로 생성하는 동안 작은 drafter가 미래 토큰 후보를 여러 개 만들어 두고, target model이 그 후보를 병렬로 확인합니다. 후보가 맞으면 여러 토큰을 한 번에 받아들이고, 틀리면 다시 target model의 경로로 돌아갑니다. 이론적으로는 target model의 출력 분포를 유지하면서 지연시간을 줄일 수 있습니다.
그래서 지난 1년 동안 모델 발표와 런타임 발표에서 speculative decoding은 자주 등장했습니다. Google은 Gemma 4용 MTP drafter를 공개했고, NVIDIA는 Nemotron 계열에서 diffusion-style drafting과 self-speculation을 이야기했습니다. vLLM, SGLang, TensorRT-LLM, llama.cpp 같은 런타임도 각자 다른 방식으로 draft, verify, KV cache, batching 문제를 흡수하고 있습니다. 중요한 변화는 이것이 더 이상 연구 논문 속 가속 아이디어가 아니라, 실제 서빙 스택의 설정값이 되고 있다는 점입니다.
하지만 운영 현실은 더 까다롭습니다. speculative decoding은 drafter가 얼마나 자주 맞히는지에 따라 이득이 결정됩니다. 쉬운 문장 완성에서는 acceptance length가 길어질 수 있지만, 긴 컨텍스트, 복잡한 system prompt, 도구 호출, 코딩 benchmark, 다른 chat template이 섞이면 drafter의 예측은 흔들립니다. target model이 결국 검증하기 때문에 품질이 보존된다는 설명은 맞지만, acceptance rate가 낮아지면 속도 이득은 사라집니다. worst case에서는 작은 모델을 같이 돌리는 비용만 늘어날 수 있습니다.
EAGLE 3.1이 흥미로운 이유는 바로 이 실패 모드를 정면으로 이름 붙였기 때문입니다. arXiv에 2026년 5월 11일 제출된 논문 "Attention Drift: What Autoregressive Speculative Decoding Models Learn"은 speculative decoding drafter가 깊은 chain으로 들어갈수록 prompt나 sink token보다 자신이 방금 생성한 토큰 쪽으로 attention을 옮기는 현상을 attention drift라고 설명합니다. 논문은 이것이 EAGLE3 drafter뿐 아니라 MTP head에서도 관찰된다고 적습니다. 즉 특정 구현의 버그라기보다, autoregressive drafter 설계가 갖는 구조적 불안정성으로 볼 여지가 있습니다.
EAGLE 3.1이 바꾼 것은 작지만 낮은 계층입니다
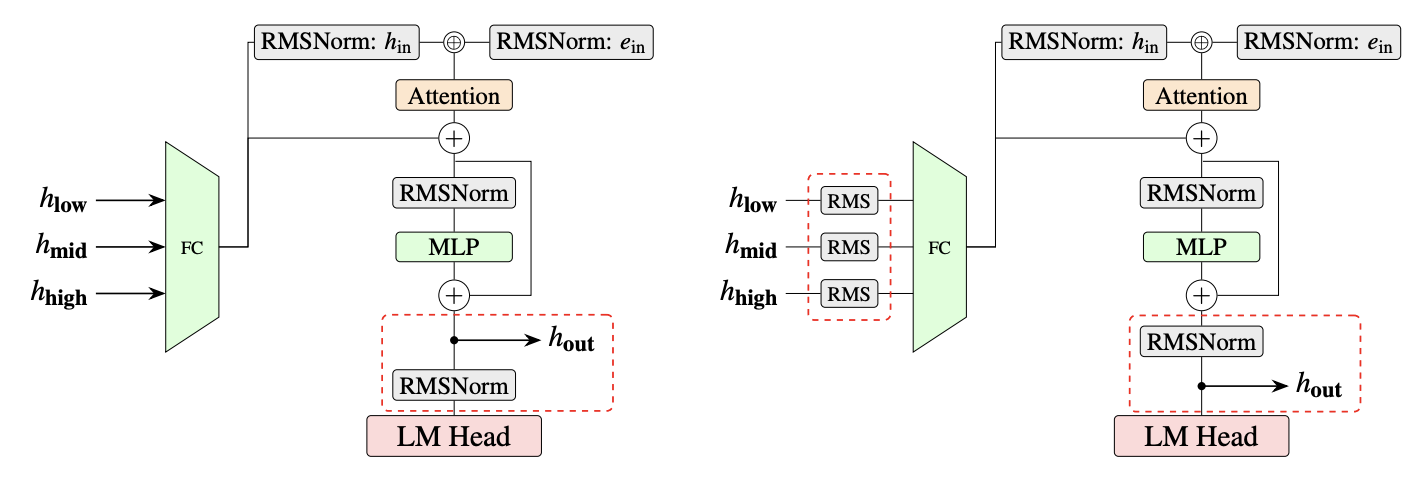
vLLM 발표가 설명하는 EAGLE 3.1의 핵심 변경은 두 가지입니다. 첫째, target hidden state를 받은 뒤 FC layer에 넣기 전에 FC normalization을 적용합니다. 둘째, 다음 decoding step에는 post-norm hidden state를 feed합니다. 표현만 보면 아주 작은 신경망 블록 수정처럼 보입니다. 하지만 이 변화가 겨냥하는 지점은 명확합니다. speculation step이 깊어질수록 hidden-state magnitude가 커지고, unnormalized residual path 때문에 drafter가 target model 위에 layer를 더 얹은 것처럼 행동하는 문제를 줄이려는 것입니다.
공식 발표는 이 설계를 "단순히 target model에 layer를 계속 붙이는 것"보다 "drafter를 decoding step마다 재귀적으로 호출하는 것"에 더 가깝게 만든다고 설명합니다. 이 비유가 중요한 이유는 EAGLE 3.1의 목표가 더 똑똑한 작은 모델을 새로 만드는 데만 있지 않기 때문입니다. 이미 있는 drafter 구조가 다른 prompt 형식, long-context 입력, system prompt 변화에서 덜 흔들리게 만드는 것이 핵심입니다.
논문 abstract의 수치도 이 관점을 뒷받침합니다. 저자들은 post-norm drafter hidden state와 target hidden state별 RMSNorm 개입으로 template perturbation 조건에서 pre-norm EAGLE3 대비 최대 2배 acceptance length, long-context task에서 1.18배, multi-turn chat, math, coding을 포함한 7개 benchmark에서 1.10배 개선을 보고했습니다. vLLM 블로그의 2.03배 throughput 수치는 이 논문적 개선이 실제 serving engine 안에서 어떤 형태로 드러날 수 있는지를 보여주는 초기 운영 데이터에 가깝습니다.
vLLM main에 들어갔다는 것이 뉴스입니다
AI 인프라 뉴스에서 논문 수치만큼 중요한 것은 배포 경로입니다. EAGLE 3.1은 vLLM의 기존 EAGLE 3 구현을 config-driven extension으로 확장하는 방식으로 들어갔습니다. 발표에 따르면 통합에는 FC normalization support, post-norm hidden-state feedback, target hidden state에 대한 hardcoded assumption 제거가 포함됩니다. 동시에 기존 EAGLE 3 checkpoint와 backward compatibility를 유지합니다.
이 지점은 실무적으로 큽니다. inference runtime에서 새 decoding algorithm을 붙이는 일은 단순히 모델 파일을 다운로드하는 것과 다릅니다. tokenizer, chat template, target hidden state, KV cache, tensor parallel, attention backend, quantization, tool call parser가 맞물립니다. 이번 예시 command만 봐도 --tool-call-parser kimi_k2, --enable-auto-tool-choice, --reasoning-parser kimi_k2, --attention-backend tokenspeed_mla, --speculative-config가 함께 등장합니다. 코딩 에이전트나 tool-using model을 운영하는 팀에게 speculative decoding은 더 이상 "토큰을 빨리 뽑는 옵션" 하나가 아닙니다. 도구 호출 파싱과 reasoning format, attention backend까지 같이 검증해야 하는 실행 경로입니다.
Hugging Face의 lightseekorg/kimi-k2.6-eagle3.1-mla 모델 카드도 같은 사실을 보여줍니다. 이 draft model은 Kimi-K2.6-NVFP4용 EAGLE3 draft model이며, fc_norm과 norm_output을 통해 기존 kimi-k2.6-eagle3-mla보다 개선됐다고 설명합니다. 모델 크기는 3B parameters, tensor type은 BF16입니다. 모델 카드의 benchmark table에서는 GSM8K, CEval, HumanEval, MATH500, AIME24, MTBench, SPEED-Bench 하위 항목별 acceptance length 비교가 제시됩니다. 모든 항목에서 일방적으로 개선되는 것은 아닙니다. 예컨대 HumanEval, MATH500, AIME24는 작은 하락이 있고, CEval과 SPEED-Bench multilingual/math 등은 개선됩니다. 이것은 EAGLE 3.1을 무조건 켜면 된다는 이야기가 아니라, workload별 acceptance profile을 봐야 한다는 경고이기도 합니다.
에이전트 워크로드에서 왜 더 중요해졌나
EAGLE 3.1 발표가 단순 latency 최적화 이상의 의미를 갖는 이유는 에이전트 워크로드의 모양이 달라졌기 때문입니다. 예전 챗봇 요청은 비교적 짧은 prompt와 짧은 answer가 많았습니다. 지금의 coding agent, research agent, enterprise assistant는 긴 repository context, tool result, system instruction, policy text, user correction을 계속 누적합니다. 같은 세션 안에서도 prompt template이 자주 바뀌고, tool output이 끼어들며, long context가 기본값이 됩니다.
이 조건에서는 drafter가 "다음 몇 토큰"을 맞히는 일이 더 어려워집니다. 특히 coding agent는 자연어 설명과 코드, JSON, shell command, stack trace, test output을 오갑니다. 쉬운 자연어에서는 acceptance length가 길어져도, 코드 diff나 tool call boundary에서는 갑자기 짧아질 수 있습니다. agent loop가 길어질수록 system prompt와 tool schema가 반복되며 KV cache와 prefix cache의 효율도 중요해집니다. 결국 모델 품질, runtime batching, cache policy, speculative decoding이 한 덩어리로 움직입니다.
이런 맥락에서 attention drift라는 이름은 꽤 유용합니다. 성능이 안 나왔을 때 "drafter가 작아서 그렇다"거나 "benchmark가 달라서 그렇다"로 끝내지 않고, speculation depth가 깊어질수록 attention이 어디로 이동하는지 분석할 수 있게 하기 때문입니다. 운영팀 입장에서는 acceptance length, per-user throughput, TPOT, TTFT, GPU utilization, fallback ratio를 함께 봐야 합니다. EAGLE 3.1은 그 관측 지표 중 acceptance length와 throughput을 개선하려는 알고리즘/런타임 공동 작업입니다.
경쟁은 모델보다 런타임 계층에서 빨라집니다
이번 발표의 또 다른 포인트는 open-source collaboration입니다. EAGLE 팀은 알고리즘과 논문을 밀고, TorchSpec은 training support를 제공하며, vLLM은 production serving path를 흡수합니다. 이 구도는 최근 오픈 모델 생태계에서 반복됩니다. 모델 제공자는 checkpoint를 공개하고, Hugging Face는 배포 표면을 제공하며, vLLM이나 SGLang 같은 런타임은 실제 요청을 처리할 수 있게 만듭니다. 이제 "좋은 모델"은 충분조건이 아닙니다. 좋은 model card, 좋은 serving command, 좋은 runtime integration, 좋은 fallback path가 있어야 제품팀이 실험할 수 있습니다.
경쟁 구도도 이 계층에서 갈라집니다. EAGLE 3.1은 MTP heads, Medusa, self-speculation, diffusion-style drafting 같은 가속 전략과 같은 문제를 다룹니다. vLLM은 SGLang, TensorRT-LLM, TGI, llama.cpp, Ollama와 다른 배포 철학을 갖고 경쟁합니다. TorchSpec은 drafter training을 반복 가능한 실험으로 낮추려는 역할을 맡습니다. Kimi-K2.6-NVFP4라는 target model은 NVIDIA와 LightSeek, Hugging Face 생태계를 통해 실제 실험 대상으로 연결됩니다.
이 흐름은 AI 개발자에게 두 가지 질문을 던집니다. 첫째, 우리 제품의 병목은 모델 선택인가, decoding path인가, cache인가, concurrency인가. 둘째, 새 가속 기능을 켰을 때 품질을 어떻게 검증할 것인가. speculative decoding은 target model이 후보를 검증하기 때문에 이론적으로 출력 분포를 유지할 수 있지만, 실제 제품에서는 parser, sampling, quantization, timeout, tool boundary가 모두 관찰 대상입니다. 특히 tool-using agent에서는 빠른 토큰보다 잘못된 tool call이나 부분 JSON이 더 비쌀 수 있습니다.
아직은 초기 수치입니다
주의할 점도 분명합니다. vLLM 블로그의 2.03배 수치는 특정 조건의 benchmark입니다. Kimi-K2.6-NVFP4, TP=4, GB200, non-disaggregated serving, SPEED-Bench coding이라는 조건을 벗어나면 결과가 달라질 수 있습니다. Hugging Face 모델 카드의 acceptance length table도 benchmark별로 개선과 하락이 섞여 있습니다. 논문의 template perturbation 최대 2배 수치도 모든 long-context 실서비스 요청에서 같은 결과를 보장하지 않습니다.
따라서 실무 적용은 feature flag에 가까워야 합니다. 먼저 nightly나 v0.22.0 이후 staging 환경에서 같은 traffic sample을 replay해야 합니다. prompt template별 acceptance length, tool call 성공률, streaming 중단, GPU memory, batch size별 throughput을 분리해서 봐야 합니다. 코딩 agent라면 HumanEval 같은 짧은 함수 benchmark보다 실제 repository task, test repair, lint fix, multi-file edit에서 체감 지연시간과 실패율을 함께 측정해야 합니다.
그럼에도 이번 발표는 의미가 있습니다. EAGLE 3.1은 "새 LLM이 더 똑똑해졌다"는 뉴스가 아닙니다. 오히려 더 낮은 계층의 뉴스입니다. 같은 target model을 더 안정적으로, 더 빠르게, 더 예측 가능하게 서빙하려면 drafter의 hidden state와 attention drift까지 봐야 한다는 신호입니다. 에이전트가 길게 생각하고, 많은 도구를 호출하고, 긴 컨텍스트를 다루는 방향으로 갈수록 이런 작은 수술이 비용표를 바꿉니다.
결국 EAGLE 3.1의 핵심은 2.03배라는 숫자 하나가 아닙니다. 그 숫자가 나온 경로입니다. 논문에서 실패 모드를 정의하고, TorchSpec에서 training support를 넣고, vLLM main에서 runtime path를 열고, Hugging Face에 실제 draft model을 공개했습니다. 모델 경쟁이 계속되는 동안, 토큰을 빠르고 안정적으로 흘려보내는 하부 구조도 같은 속도로 진화하고 있습니다. AI 팀이 봐야 할 다음 병목은 모델 이름표가 아니라, 그 모델이 매 토큰을 어떤 방식으로 추측하고 검증하는지일 수 있습니다.