450% 더 많은 트래픽, 에이전트가 WAN을 다시 쓰는 이유
Cisco의 WAN 보고서는 AI 에이전트가 추론 호출을 네트워크 병목으로 바꾸며 용량, 보안, 관측성 설계를 흔든다고 분석합니다.

- 무슨 일: Cisco가
AI Impact on Wide Area Networks보고서에서 AI 추론과 agentic AI의 WAN traffic 변화를 계량했습니다.- 공식 보고서는 agent task가 인간 수동 작업보다 450% 더 많은 traffic을 만들고, 증가분의 70%가 AI inference라고 분석합니다.
- 의미: 에이전트 제품의 병목이 GPU와 token price를 넘어 upstream capacity, flow state, QoS, path security로 확장됩니다.
- 주의점: 2035년 AI inference 25%와 enterprise traffic 9배 전망은 Cisco model입니다. 숫자보다 traffic shape 변화가 핵심입니다.
Cisco가 2026년 5월 21일 AI가 WAN traffic을 어떻게 바꾸는지를 다룬 블로그와 함께 AI Impact on Wide Area Networks: Cisco Report 2026을 공개했습니다. 제목만 보면 네트워크 장비 회사의 자연스러운 인프라 보고서처럼 보입니다. 하지만 개발자와 AI product team에게 더 중요한 메시지는 따로 있습니다. 에이전트가 늘어나면 AI 비용은 모델 호출 요금표에서 끝나지 않고, 네트워크의 흐름, 상하향 대칭성, 보안 장비의 상태 관리, 관측성 설계까지 끌고 들어갑니다.
보고서에서 가장 눈에 띄는 숫자는 450%입니다. Cisco는 Open Deep Research 스타일의 agent 실험에서 같은 작업을 사람이 수동으로 수행할 때보다 agent-driven task가 약 450% 더 많은 네트워크 traffic을 만들었다고 설명합니다. 그 증가분의 약 70%는 AI inference traffic입니다. 다시 말해 사용자는 "자료 조사해줘"라고 한 번 요청하지만, 내부에서는 agent, web proxy, data sources, LLM provider, tool 사이를 오가는 긴 실행 그래프가 만들어집니다.
이 숫자가 중요한 이유는 단순히 bandwidth가 더 필요하다는 뜻이 아니기 때문입니다. Cisco는 AI inference path를 agent의 spinal cord라고 부릅니다. 모델이 두뇌라면 agent logic과 모델 사이의 연결 경로는 신경계에 가깝다는 설명입니다. 이 경로가 지연되거나 막히면 UX가 조금 느려지는 수준을 넘어 agent 기능 자체가 실패합니다. 특히 long-running agent, background workflow, multi-tool task, MCP 기반 연결이 늘어날수록 이 경로는 production reliability의 일부가 됩니다.
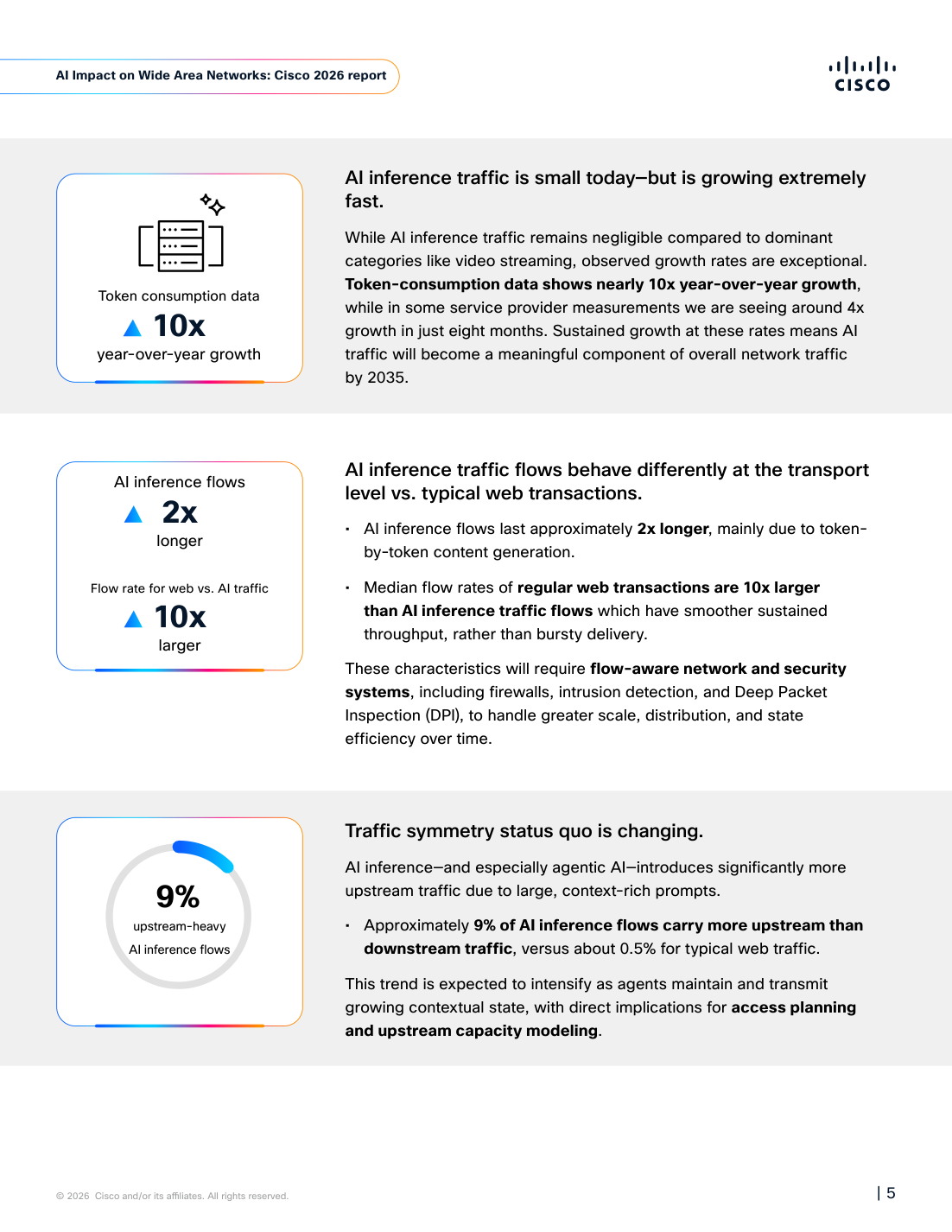
AI traffic은 웹 traffic처럼 움직이지 않습니다
웹 traffic에 대한 오래된 상식은 대체로 downstream 중심입니다. 사용자가 페이지나 영상을 요청하면 서버나 CDN이 큰 payload를 내려보냅니다. 물론 upload, realtime collaboration, video call도 있지만, 소비자 인터넷과 많은 enterprise network planning은 오랫동안 bursty downstream traffic을 중심으로 최적화됐습니다. Cisco 보고서는 AI inference와 agentic AI가 이 전제를 흔든다고 봅니다.
첫째, AI inference flow는 더 오래 지속됩니다. 보고서는 AI inference flow가 일반 웹 트랜잭션보다 약 2배 오래 이어진다고 설명합니다. 이유는 익숙합니다. LLM은 결과를 한 번에 내려보내기보다 token-by-token으로 생성합니다. 사용자가 보는 stream은 자연스럽지만, 네트워크와 firewall 입장에서는 더 오래 살아 있는 flow입니다. 이 차이는 단일 요청에서는 작아 보일 수 있습니다. 하지만 agent가 수십 번, 수백 번 모델과 tool을 오가면 flow-aware system의 state table, intrusion detection, DPI, telemetry pipeline에는 누적 부담이 됩니다.
둘째, throughput의 모양이 다릅니다. Cisco는 일반 웹 트랜잭션의 median flow rate가 AI inference traffic보다 10배 크다고 분석합니다. 일반 웹은 더 높은 peak를 만들고 빠르게 내려받는 경우가 많습니다. 반면 AI inference는 더 낮지만 꾸준한 흐름을 유지합니다. 네트워크 운영자가 peak bandwidth만 보면 이 traffic을 과소평가할 수 있습니다. 하지만 긴 flow와 많은 동시 session이 쌓이면 다른 종류의 capacity 문제가 생깁니다.
셋째, upstream traffic의 비중이 커집니다. 보고서는 AI inference flow의 약 9%가 downstream보다 upstream traffic이 많다고 말합니다. 일반 HTTP web flow에서는 이 비율이 약 0.5%입니다. 이 차이는 agentic AI에서 더 커질 수 있습니다. 에이전트는 사용자의 짧은 prompt만 보내지 않습니다. 긴 context, retrieved chunk, conversation state, tool output, file diff, log, schema, policy를 모델 쪽으로 계속 보냅니다. AI 제품을 만드는 개발자에게는 이 말이 더 직접적입니다. context window를 크게 쓰고, tool trace를 풍부하게 넣고, retrieval 결과를 많이 붙이는 설계는 모델 비용뿐 아니라 upstream path와 observability 비용도 키웁니다.
450% traffic 증가는 agent loop의 가격표입니다
Cisco의 agent 실험은 Open Deep Research agent를 예로 듭니다. 보고서의 figure는 agent가 44개 source를 탐색하고, web proxy, data sources, OpenAI, agent 사이를 오가며 26.8MB의 agent-triggered traffic을 만들었다고 설명합니다. 핵심은 absolute byte 수가 아닙니다. 같은 작업을 사람이 수행했을 때보다 agent가 훨씬 더 빠른 속도로 더 많은 request를 만들 수 있다는 점입니다.

사람은 브라우저 탭을 열고, 검색 결과를 읽고, 몇 개 링크를 클릭하고, 문장을 복사합니다. agent는 같은 일을 software speed로 수행합니다. 검색하고, page를 가져오고, 요약하고, 다음 query를 만들고, 다시 검색하고, model에 판단을 맡기고, tool output을 또 model에 넣습니다. 각 단계는 작을 수 있지만 전체 task graph는 길어집니다. 사용자의 request 수가 늘지 않아도 내부 traffic은 크게 늘어납니다.
이 흐름은 AI 앱의 unit economics와도 연결됩니다. 많은 팀이 비용을 token price로만 계산합니다. input token * price + output token * price라는 식은 시작점으로는 유용합니다. 하지만 agent product에서는 부족합니다. agent가 web, database, vector store, storage, sandbox, browser, code runner, notification API를 계속 호출하면 네트워크와 주변 인프라 비용이 함께 움직입니다. 특히 enterprise deployment에서는 egress, private connectivity, region choice, firewall inspection, log retention, trace sampling까지 비용과 latency에 영향을 줍니다.
따라서 450%라는 숫자는 "Cisco가 네트워크를 더 팔고 싶어 한다"는 문장으로만 소비하기에는 아깝습니다. 더 실용적인 해석은 이렇습니다. agentic AI는 사용자 한 명의 intent를 내부적으로 많은 machine-to-machine transaction으로 분해합니다. 그 transaction의 상당 부분은 model inference path에 묶입니다. 그래서 agent reliability를 설계할 때는 model retry, tool retry, queue, cache뿐 아니라 network path의 resiliency와 visibility도 같이 봐야 합니다.
GPU 병목의 다음 질문은 WAN입니다
지난 2년간 AI infrastructure 논의는 GPU가 중심이었습니다. H100, H200, B200, TPU, MI300X, inference chip, data center power, liquid cooling이 headline을 차지했습니다. 이 관점은 여전히 맞습니다. 모델을 훈련하고 빠르게 서빙하려면 compute가 필요합니다. 하지만 Cisco 보고서가 던지는 질문은 compute 다음 단계입니다. 모델이 아무리 빠르더라도 agent가 모델에 도달하는 경로, context를 보내는 경로, tool 결과를 되돌리는 경로가 불안정하면 전체 product는 흔들립니다.
보고서는 2035년 AI inference가 전체 network traffic의 약 25%를 차지할 수 있다고 예측합니다. 또 enterprise traffic은 agentic AI가 없으면 2026년부터 2035년까지 약 2.5배 증가하지만, agentic AI adoption을 넣으면 약 9배 증가할 수 있다고 봅니다. consumer network에서도 AI와 agentic AI가 non-AI scenario 대비 약 63%의 추가 성장을 만들 수 있다고 분석합니다.
이 장기 전망은 그대로 확정값으로 받아들이면 안 됩니다. Cisco model이고, agent adoption speed와 product design, on-device inference, cache, compression, model efficiency, regulation, pricing에 따라 크게 달라질 수 있습니다. 예를 들어 더 많은 inference가 edge나 on-device에서 처리되면 WAN 영향은 줄어들 수 있습니다. 반대로 agent가 더 많은 tool과 real-time data를 붙잡으면 traffic은 더 커질 수 있습니다. 따라서 숫자의 정확도보다 중요한 것은 방향입니다. Cisco는 AI traffic이 "더 많아진다"가 아니라 "다르게 생겼다"고 말합니다.
이 차이는 capacity planning의 질문을 바꿉니다. 기존에는 "얼마나 많은 bandwidth가 필요한가"가 중심이었다면, agentic AI에서는 "어떤 path가 mission-critical인가", "어떤 flow를 더 오래 추적해야 하는가", "어떤 upstream 구간이 병목인가", "어떤 inference provider와 region이 failure domain인가", "QoS와 path security를 어디에 적용해야 하는가"가 중요해집니다.
보안 장비와 관측성도 새 압력을 받습니다
AI inference traffic이 길고 꾸준해지면 firewall, intrusion detection system, proxy, DPI, SASE 같은 계층도 영향을 받습니다. 보고서는 flow-aware network and security systems가 더 큰 규모와 분산, state efficiency를 다뤄야 한다고 설명합니다. 일반 웹 요청보다 오래 살아 있는 inference flow가 늘어나면 state table이 커지고, encrypted transport와 QUIC 사용이 늘면 visibility도 복잡해집니다.
Converge Digest는 Cisco 보고서를 전하며 Cisco data set에서 QUIC이 measured AI inference traffic volume의 57%를 차지한다고 보도했습니다. 이 수치는 보고서의 어떤 traffic sample과 방법론에 의존하므로 모든 환경에 일반화할 수는 없습니다. 그래도 방향은 분명합니다. AI traffic은 TLS로 보호되고, 다양한 provider와 endpoint로 흩어지고, agent runtime과 tool 사이를 오갑니다. 보안팀이 단순히 destination domain을 허용하거나 차단하는 방식만으로는 충분하지 않을 가능성이 큽니다.
개발자에게도 영향이 있습니다. agent product가 production에 들어가면 보안팀은 "이 agent가 어디와 통신하는가", "어떤 model provider로 어떤 data가 나가는가", "tool output이 prompt에 포함되는가", "민감한 파일이 retrieval context에 들어갔는가", "실패 시 retry가 어디까지 확산되는가"를 묻습니다. 이 질문에 답하려면 application trace와 network trace가 이어져야 합니다. 모델 호출 log만 있고 network path가 없으면 장애 분석이 반쪽이 됩니다. 반대로 network telemetry만 있고 agent step trace가 없으면 어떤 task가 traffic spike를 만들었는지 알기 어렵습니다.
latency는 아직 전부가 아니지만 무시할 수도 없습니다
Cisco는 흥미롭게도 "network latency is not the dominant bottleneck yet"이라고 선을 긋습니다. 현재 end-to-end AI inference latency는 주로 model processing이 지배하고, 짧은 query라도 first token까지 수백 ms, 전체 응답은 수 초가 걸릴 수 있습니다. 이 관점에서는 모든 inference를 edge로 옮겨야 한다는 결론은 성급합니다.
하지만 이 말이 network를 무시해도 된다는 뜻은 아닙니다. agent loop에서는 작은 latency가 여러 단계에 누적됩니다. model call, retrieval, tool call, browser automation, validation, second model review, human approval이 이어지면 각 hop의 tail latency가 전체 작업 시간을 밀어 올립니다. 특히 interactive coding agent나 customer support agent처럼 사용자가 기다리는 흐름에서는 p95와 p99가 중요해집니다. background agent라면 latency보다 reliability와 cost가 더 중요할 수 있습니다. 결국 network design은 workload type에 따라 달라져야 합니다.
이 지점에서 edge inference의 역할도 더 복잡해집니다. 단순 chatbot 응답을 빠르게 하는 목적이라면 model processing이 병목이라 edge만으로 해결되지 않을 수 있습니다. 하지만 data sovereignty, private data locality, tool proximity, offline tolerance, regulatory boundary, cost control 때문에 inference 위치를 바꾸는 것은 충분히 의미가 있습니다. Cisco 보고서는 latency 하나만으로 edge 전환을 설명하기보다, scale, data sovereignty, security와 함께 봐야 한다는 쪽에 가깝습니다.
개발팀이 지금 재야 할 지표들
이 보고서의 실무적 가치는 장기 예측보다 measurement checklist에 있습니다. AI 앱을 운영하는 팀이라면 agent run을 단일 API call이 아니라 distributed workflow로 봐야 합니다. 먼저 한 작업이 몇 개 model call을 만드는지, 각 call의 input/output token이 얼마인지, 어느 단계에서 context가 커지는지 기록해야 합니다. 그 다음에는 tool call과 data source access를 함께 봐야 합니다. web fetch, database query, vector search, file upload, sandbox execution, browser session, MCP tool invocation이 어느 region과 provider를 거치는지 알아야 합니다.
네트워크 관점에서는 최소한 네 가지를 분리하는 편이 좋습니다. 첫째, model inference path입니다. agent logic이 model provider 또는 private inference cluster에 도달하는 경로입니다. 둘째, retrieval/data path입니다. vector store, database, object storage, document source가 여기에 들어갑니다. 셋째, tool execution path입니다. third-party API, internal service, browser, code runner가 포함됩니다. 넷째, telemetry path입니다. logs, traces, eval result, audit record가 어디로 흐르는지입니다.
이 네 가지가 분리돼야 장애가 보입니다. 사용자가 "agent가 느리다"고 말할 때 모델이 느린지, retrieval이 느린지, tool provider가 rate limit을 걸었는지, network path가 packet loss를 만들었는지, trace exporter가 병목인지 구분할 수 있습니다. 비용도 마찬가지입니다. 모델 단가를 낮췄는데 전체 비용이 줄지 않는다면 주변 path의 traffic, egress, storage, log retention, retry storm을 봐야 합니다.
에이전트가 많아지면 upstream이 제품 문제가 됩니다
upstream traffic은 AI product team이 자주 놓치는 항목입니다. 사용자가 긴 파일을 업로드하거나 repository 전체를 분석시키는 코딩 에이전트, 고객 데이터를 요약하는 CRM agent, 회계 문서를 검토하는 finance agent, web research agent는 모두 큰 context를 model 쪽으로 보냅니다. output이 길지 않더라도 input이 큽니다. 특히 prompt caching, delta encoding, retrieval chunk selection, context compaction이 제대로 동작하지 않으면 upstream payload는 빠르게 커집니다.
이 문제는 네트워크 설계만의 문제가 아닙니다. application architecture도 영향을 줍니다. 예를 들어 매 agent step마다 전체 conversation과 전체 retrieved documents를 다시 보내는 설계는 단순하지만 비쌉니다. tool output을 구조화하고, 필요 없는 chunk를 잘라내고, state를 요약하고, provider별 cache hit을 높이는 설계는 model cost와 network load를 동시에 줄입니다. agent가 더 똑똑해지는 만큼 context hygiene도 인프라 최적화가 됩니다.
MCP와 agent connector 생태계가 커지면 이 질문은 더 중요해집니다. MCP server가 여러 SaaS와 내부 시스템을 agent에 붙여주면 개발 경험은 좋아집니다. 하지만 agent가 어떤 data를 어느 model로 보냈는지, tool result를 어느 step에서 재사용했는지, 민감한 field가 prompt에 포함됐는지 추적하지 못하면 보안과 비용 모두 불투명해집니다. Cisco가 말하는 WAN traffic 변화는 결국 application layer의 설계 습관과 연결됩니다.
Cisco 보고서를 어떻게 읽어야 하나
Cisco는 네트워크 장비와 security, observability 제품을 파는 회사입니다. 따라서 보고서의 결론이 "AI-ready network가 필요하다"로 향하는 것은 자연스럽습니다. 독자는 이 vendor context를 알고 읽어야 합니다. 2035년 25%, enterprise traffic 9배, consumer traffic additional 63% 같은 수치는 예측 model입니다. AI adoption curve, on-device model, compression, regulation, pricing, product design이 달라지면 결과도 달라집니다.
그렇다고 보고서를 단순 마케팅으로 버릴 필요는 없습니다. 이 보고서의 강점은 AI traffic을 일반 웹 traffic과 구분해 측정하려는 framework입니다. token-by-token streaming, longer-lived flows, upstream-heavy prompts, agent-driven tool traversal, inference path criticality는 이미 현장에서 관찰되는 문제입니다. AI product team이 지금 production trace를 보면 비슷한 패턴을 찾을 가능성이 큽니다.
Network World와 Converge Digest도 보도에서 같은 지점을 강조했습니다. 이 뉴스가 의미 있는 이유는 "인터넷 전체가 곧 AI traffic으로 가득 찬다"는 과장 때문이 아니라, agentic AI가 기존 network planning assumptions를 하나씩 흔든다는 데 있습니다. 특히 AI agent가 enterprise workflow에 들어갈수록 traffic은 더 이상 사람의 클릭 속도에 묶이지 않습니다. software speed로 움직이는 agent가 여러 provider와 tool을 호출하면, 작은 UX 기능 하나가 infrastructure graph 전체를 움직입니다.
결론은 agent reliability의 범위가 넓어진다는 것입니다
AI agent를 안정적으로 운영한다는 말은 이제 prompt를 잘 쓰고 model을 잘 고른다는 뜻만으로 부족합니다. model selection, prompt caching, RAG quality, tool permission, sandbox isolation, eval, human approval에 더해 network path와 traffic shape도 봐야 합니다. agent logic과 model 사이의 경로가 agent의 spinal cord라면, 그 경로의 latency, loss, congestion, security inspection, observability는 product reliability의 일부입니다.
개발팀이 당장 Cisco의 장기 예측을 믿고 네트워크를 새로 사야 한다는 뜻은 아닙니다. 더 현실적인 첫 단계는 자기 agent의 run trace와 traffic trace를 연결하는 것입니다. 어떤 task가 몇 번 inference를 호출하는지, 어떤 provider와 region을 거치는지, upstream payload가 왜 커지는지, retry가 traffic을 얼마나 증폭하는지, long-running flow가 security stack에 어떤 state 부담을 주는지 확인해야 합니다.
그 데이터를 갖고 나면 선택지가 생깁니다. context를 줄일지, retrieval을 더 좁힐지, cache를 붙일지, model을 가까운 region으로 옮길지, private inference를 둘지, QoS를 적용할지, 특정 agent path를 별도 monitoring할지 판단할 수 있습니다. AI infrastructure의 다음 병목은 GPU 밖에서 나타날 가능성이 큽니다. Cisco 보고서의 가장 유용한 메시지는 바로 그 지점입니다. 에이전트는 모델을 쓰는 애플리케이션이 아니라, 네트워크를 계속 움직이는 소프트웨어 노동자입니다.