Mistral Search Toolkit 공개, RAG 실패를 검색 평가로 분리
Mistral Search Toolkit public preview는 RAG와 에이전트 검색 실패를 모델 문제가 아니라 retrieval 평가와 pipeline 문제로 나눕니다.

- 무슨 일: Mistral AI가 2026년 5월 28일 Search Toolkit을 public preview로 공개했습니다.
ingestion,retrieval,evaluation을 하나의 Python framework로 묶고, open source로 cloud, on-premises, edge 실행을 내세웁니다.
- 의미: RAG 오류를 prompt나 모델 교체로 덮기 전에, retriever가 맞는 문맥을 가져왔는지 따로 측정하라는 제품 메시지입니다.
- 개발자 영향: BM25, dense vector, hybrid search, reranking, recall·precision·MRR·NDCG 평가가 agent data path의 기본 점검표로 올라옵니다.
- 주의점: public preview와 Python 3.12+ 조건이 있으며, 실제 품질은 팀별 corpus와 relevance judgment로 다시 재야 합니다.
Mistral AI가 2026년 5월 28일 Search Toolkit public preview를 공개했습니다. Mistral은 이 도구를 AI 애플리케이션용 production search pipeline을 만들기 위한 composable framework라고 설명합니다. 발표문에서 강조한 범위는 세 가지입니다. 데이터를 읽고 쪼개고 index에 넣는 ingestion, 질문에 맞는 문서를 찾는 retrieval, 검색 품질을 따로 재는 evaluation입니다. Mistral은 Search Toolkit이 open source이며 cloud, on-premises, edge 어디서든 실행된다고 밝혔습니다.
이번 발표는 새 모델 출시가 아닙니다. 개발팀이 RAG와 enterprise agent를 production에 올릴 때 자주 만나는 실패 원인을 모델 바깥으로 꺼냅니다. 답변이 틀렸을 때 "LLM이 hallucination했다"고 닫기 전에, 검색기가 올바른 문서를 가져왔는지, chunk가 잘렸는지, 최신 문서가 index에 들어갔는지, relevance judgment가 있는지 확인해야 합니다. Mistral은 이 문제를 별도 glue code가 아니라 제품화된 검색 framework의 영역으로 끌어옵니다.
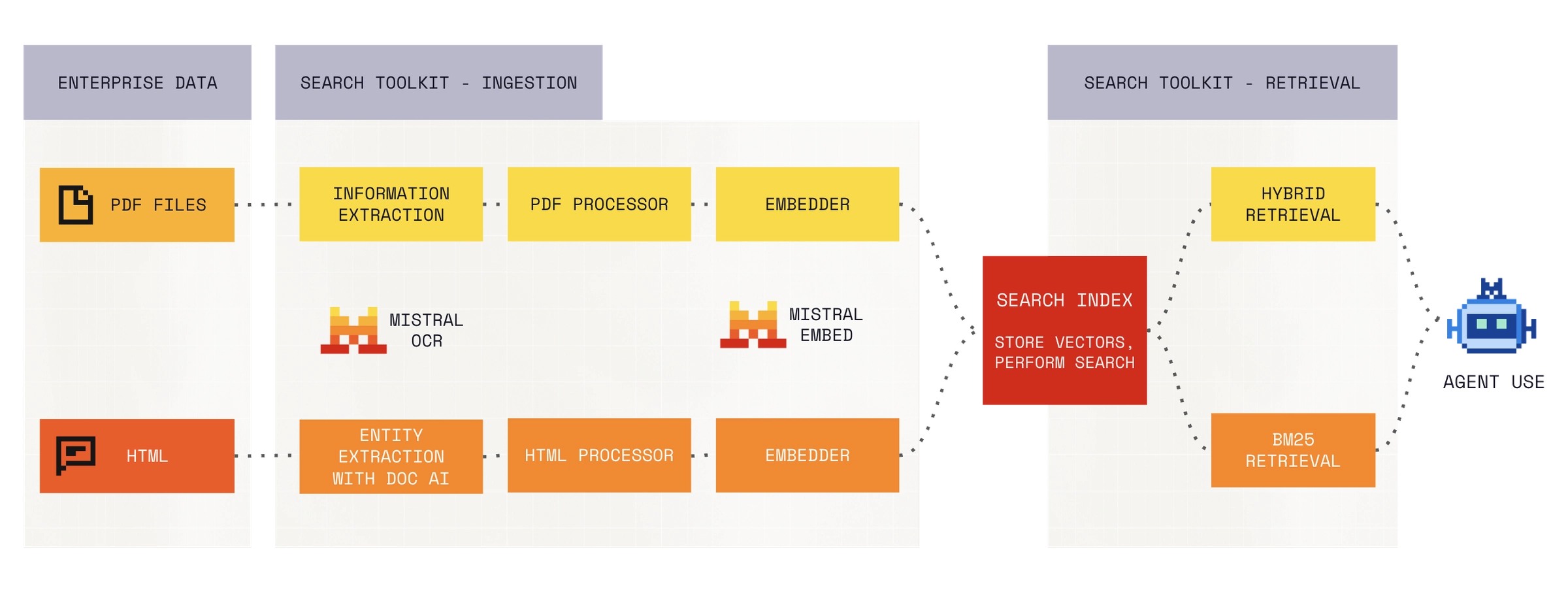
공식 아키텍처 이미지는 ingestion과 retrieval 경로를 분리해 보여줍니다.
Search Toolkit은 무엇을 묶었나?
Mistral 문서는 Search Toolkit을 production-ready Information Retrieval 시스템을 만들기 위한 Python framework라고 정의합니다. 문서 기준으로 ingestion은 file loader, document extractor, text splitter, optional chunk enricher, embedder, vector store indexing으로 구성됩니다. retrieval은 optional query preprocessor, retriever, optional reranker를 거쳐 관련 chunk를 반환합니다. 이 두 workflow는 각각 Pipeline과 QueryEngine으로 orchestration됩니다.
구성 요소 목록은 RAG 장애 지점을 그대로 보여줍니다. file loader가 어떤 원본을 읽는지, PDF와 spreadsheet를 어떻게 구조화하는지, chunk size가 표와 코드 블록을 망가뜨리지 않는지 확인해야 합니다. metadata가 tenant와 권한을 보존하는지, embedding model이 domain vocabulary를 처리하는지, reranker가 top-k에서 필요한 문서를 살리는지도 별도 점검 대상입니다. Search Toolkit은 이 항목들을 하나의 추상 계층으로 모읍니다. 모든 component를 교체할 수 있다고 문서에 적은 이유도 여기에 있습니다.
발표문에서 Mistral은 기존 팀들이 ingestion, retrieval, evaluation을 각각 다른 도구로 붙인다고 지적합니다. 이 방식은 demo 단계에서는 빠릅니다. 하지만 corpus가 늘어나고 source가 많아지면 장애 원인이 흩어집니다. 내부 wiki, support ticket, file storage, codebase는 문서 구조와 metadata가 다릅니다. 각 source마다 다른 parser와 chunker를 쓰면, 검색 품질을 비교할 때 실험 조건이 맞지 않습니다. Search Toolkit은 source별 처리 방식은 바꾸되 pipeline interface는 유지하는 쪽을 택합니다.
RAG 실패를 generation과 retrieval로 나눕니다
Mistral 발표에서 가장 실무적인 문장은 RAG 품질을 다루는 대목입니다. RAG 시스템이 나쁜 결과를 반환할 때 첫 질문은 문제가 retrieval인지 generation인지여야 합니다. 발표문은 많은 팀이 이 구분 없이 prompt를 고치고, chunking 전략을 바꾸고, 모델을 교체한다고 설명합니다. 이 과정에서 retriever가 맞는 context를 실제로 surfacing했는지 측정하지 못하면 같은 오류가 다른 모델에서도 반복됩니다.
Search Toolkit은 built-in evaluation으로 retrieval quality를 generation quality와 분리하겠다고 합니다. 공식 발표와 문서에 나온 지표는 recall, precision, MRR, NDCG입니다. recall은 정답 문서가 후보 안에 들어왔는지, precision은 가져온 결과 중 관련 문서가 얼마나 되는지 봅니다. MRR은 첫 번째 관련 결과의 위치를 보고, NDCG는 순위가 좋은 결과를 위에 올렸는지 평가합니다. 이 숫자들은 답변 문장 품질이 아니라 검색 단계의 품질을 봅니다.
| 장애 질문 | 모델만 볼 때 | Search Toolkit 관점 |
|---|---|---|
| 정답 문서가 없었습니다 | prompt에 "모르면 모른다"고 추가 | recall과 index freshness를 먼저 측정 |
| 비슷하지만 틀린 문서가 상위에 왔습니다 | 더 큰 LLM으로 교체 | BM25, vector, hybrid, reranking을 같은 eval set으로 비교 |
| 표와 정책 조항이 잘렸습니다 | 답변 형식을 더 강하게 지시 | extractor와 splitter를 source type별로 교체 |
| 도메인 용어가 검색되지 않았습니다 | system prompt에 용어집을 추가 | sparse, dense, hybrid retrieval과 query rewrite를 분리 실험 |
이 관점은 agent 제품에서 더 직접적입니다. 사람이 검색어를 고르는 RAG 챗봇과 달리, 에이전트는 plan 단계에서 여러 검색을 스스로 실행합니다. 검색 한 번의 오류가 다음 tool call, 다음 승인 요청, 다음 파일 수정으로 이어집니다. retriever가 오래된 pricing page를 가져오면 agent는 틀린 금액으로 견적 메일을 만들 수 있습니다. codebase 검색이 비슷한 이름의 deprecated API를 상위에 올리면 agent는 compile은 되지만 정책에 맞지 않는 patch를 만들 수 있습니다.
BM25와 벡터 검색을 같이 봅니다
Search Toolkit은 dense embedding retrieval만 내세우지 않습니다. 발표문은 BM25 sparse retrieval, dense embedding-based retrieval, 두 방식을 결합한 hybrid configuration을 지원한다고 설명합니다. starter app도 pre-configured Vespa indexing과 hybrid retrieval을 포함합니다. 이 선택은 production RAG에서 자주 나오는 실패와 맞닿아 있습니다.
벡터 검색은 의미가 비슷한 문서를 찾는 데 강합니다. 하지만 error code, API parameter, invoice number, product SKU, 법 조항 번호처럼 정확한 문자열이 중요한 분야에서는 sparse search가 더 안정적인 경우가 있습니다. BM25는 오래된 기술처럼 보이지만, enterprise corpus에서는 여전히 강한 baseline입니다. 반대로 사용자가 자연어로 "지난 분기 갱신 조건"을 묻는 상황에서는 dense embedding이 관련 문서를 넓게 찾을 수 있습니다. hybrid retrieval은 두 신호를 합쳐야 하는 이유를 제공합니다.
문서에는 retrieval component로 vector search with optional reranking, query preprocessing, semantic caching이 제시됩니다. query preprocessing은 LLM reformulation 또는 query extension으로 사용자의 질문을 검색에 맞게 바꿉니다. reranking은 LLM reranker, cross-encoder reranker, custom reranker 옵션을 둡니다. semantic caching은 유사한 query의 결과를 재사용해 반복 검색 비용을 줄이는 장치입니다. 각각은 품질과 비용, latency를 바꿉니다.
개발팀이 여기서 얻을 실무 질문은 명확합니다. top-k를 늘려 답변 품질이 오르는가, 아니면 noise만 늘어나는가. BM25를 추가하면 exact term query가 살아나는가.
reranker를 넣으면 첫 관련 문서의 순위가 올라가는가. query rewrite가 domain-specific abbreviation을 망가뜨리지는 않는가.
semantic cache가 stale result를 오래 붙잡지는 않는가. Search Toolkit은 이 질문들을 같은 eval set 위에서 비교하도록 설계됐습니다.
문서 처리 범위는 enterprise source를 겨냥합니다
Mistral 문서는 ingestion 기능으로 PDF, DOCX, PPTX via Mistral OCR, HTML, spreadsheets, emails, plain text를 적었습니다. file loader는 local filesystem에서 읽거나 custom loader를 붙일 수 있고, splitter는 character, token, markdown-aware, separator 기반을 선택할 수 있습니다. enricher는 metadata나 LLM-generated summary를 chunk에 추가할 수 있습니다. storage는 Vespa 또는 custom vector store를 사용할 수 있습니다.
이 범위는 "문서를 vector DB에 넣는다"보다 넓습니다. enterprise search에서는 PDF 계약서, spreadsheet 가격표, email thread, HTML handbook, slide deck이 함께 섞입니다. 같은 chunking rule을 적용하면 표가 잘리고, footnote가 본문과 분리되고, email reply chain이 중복됩니다. extractor와 splitter를 source type별로 바꾸지 않으면 retrieval 품질 문제를 모델 문제처럼 오해하기 쉽습니다.
PyPI 페이지 기준 최신 패키지 mistralai-search-toolkit 0.0.8은 2026년 5월 22일 release됐습니다. requires는 Python 3.12 이상 3.15 미만이고, license는 Apache-2.0으로 표시됩니다. optional extra에는 vespa, extractor-pymupdf, extractor-spreadsheet, extractor-email, storage-azure, storage-gcs, text-splitter-langchain 등이 있습니다. PyPI는 source distribution과 wheel 모두 Trusted Publishing attestation을 표시합니다.
이 조건은 adoption 판단에도 영향을 줍니다. Python 3.12+는 새 프로젝트에는 무리가 적지만, 오래된 enterprise ML runtime에서는 runtime upgrade가 필요할 수 있습니다. PyPI release는 beta classifier를 달고 있고, Mistral의 발표도 public preview입니다. production RAG의 핵심 경로에 넣기 전에는 API 안정성, observability, error handling, version pinning, rollback 경로를 확인해야 합니다.
Starter app은 Vespa 중심입니다
Mistral 발표의 "Get started"는 uvx copier copy gh:mistralai/search-starter-app my-search-project로 시작합니다. starter repository는 Copier template입니다. generated project 안에는 Vespa local setup, ingestion entrypoint, search entrypoint, Vespa app migration이 들어갑니다. README 기준으로 Docker와 uv가 필요하고, sample data를 index한 뒤 make search query="hello world"로 검색을 실행합니다.
Vespa 선택은 우연이 아닙니다. Vespa는 vector search와 lexical search, ranking profile을 함께 다루는 open-source search engine입니다. Mistral starter app은 local Vespa를 띄우고 hybrid retrieval을 테스트하는 방향으로 구성돼 있습니다. Search Toolkit의 추상화가 backend-agnostic을 내세우더라도, 빠른 시작 경로는 Vespa에 맞춰져 있습니다. 이미 Elasticsearch, OpenSearch, Pinecone, Weaviate, Qdrant, Postgres pgvector를 운영하는 팀은 plugin과 custom store 비용을 따져야 합니다.
이 지점에서 Search Toolkit은 LangChain이나 LlamaIndex의 일반 retrieval abstraction과 경쟁합니다. 동시에 Azure AI Search, AWS Bedrock Knowledge Bases, Google Vertex AI Search 같은 cloud-managed RAG 제품과도 겹칩니다. Mistral의 차이는 Studio, Connectors, Agents, Workflows와 연결되는 자체 agent stack 안에서 retrieval path를 제공한다는 점입니다. 특정 cloud search service보다 portable한 framework를 선호하는 팀에게는 장점이고, managed service의 운영 책임 이전을 원하는 팀에게는 부담이 될 수 있습니다.
에이전트는 index와 live data를 함께 씁니다
Mistral은 발표문에서 agentic world를 별도 절로 다뤘습니다. enterprise task를 수행하는 agent는 enterprise context에 접근해야 하고, autonomous하게 많은 retrieval decision을 내리기 때문에 아래 검색 인프라 품질이 downstream step에 직접 영향을 준다고 설명합니다. 큰 문서 corpus를 검색할 때는 indexed semantic search를 쓰고, 최신 상태가 필요할 때는 Connectors를 통해 CRM, code repository, productivity tool 같은 source system에서 live data를 끌어온다는 구분도 제시했습니다.
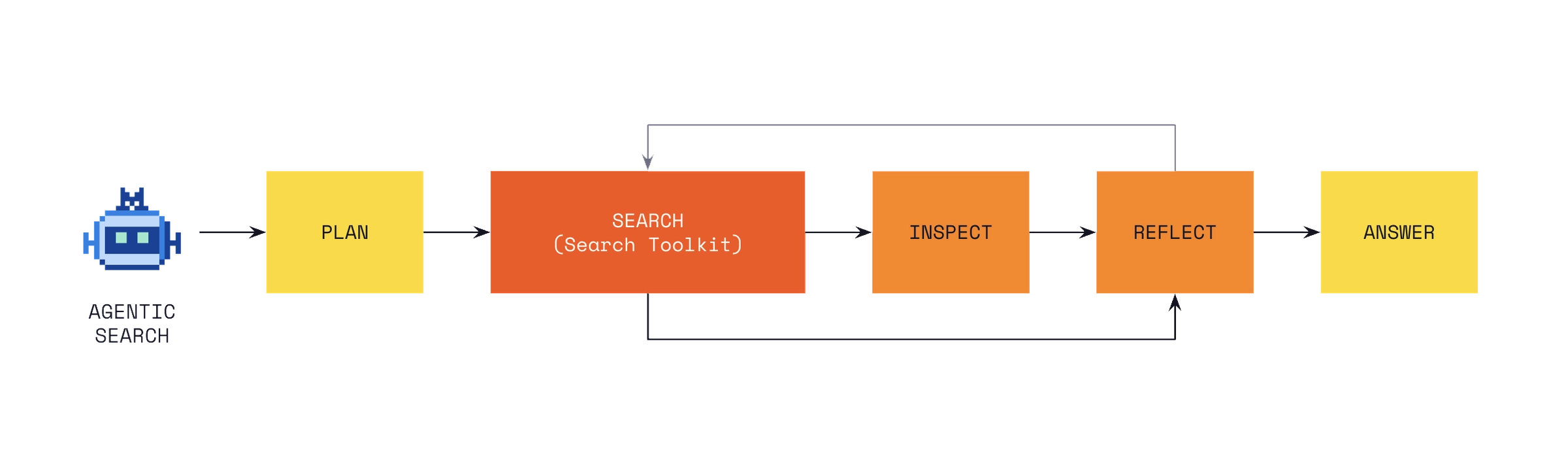
이 구분은 실제 architecture review에서 중요합니다. 모든 데이터를 매번 live connector로 읽으면 latency와 rate limit이 커집니다. 반대로 모든 데이터를 index에 넣으면 최신성과 권한 전파가 문제됩니다. 예를 들어 internal handbook, API docs, past support tickets는 indexed corpus가 적합할 수 있습니다. 현재 account status, open incident, latest invoice, branch protection setting은 live source가 더 적합합니다. agent는 두 경로를 구분해야 합니다.
Search Toolkit은 indexed search path를 맡습니다. Connectors와 MCP integrations는 live source access를 맡습니다. 두 경로가 섞이면 observability도 둘로 나뉩니다. 어떤 답변이 index에서 온 오래된 문서 때문인지, connector 호출 실패 때문인지, model reasoning 때문인지 추적해야 합니다. Mistral의 발표는 이 분리 자체를 제품 메시지로 삼습니다. "모델이 틀렸다"가 아니라 "검색 경로 중 어디가 틀렸는가"를 묻도록 합니다.
CMA CGM 사례는 15초 alert를 말합니다
Mistral은 Search Toolkit이 financial services, manufacturing, public sector, media and entertainment 분야에서 battle tested됐다고 적었습니다. 공개 수치가 있는 사례는 CMA CGM입니다. 발표문에 따르면 CMA CGM은 Search Toolkit을 Voxtral과 함께 사용해 journalist가 fake news를 감지하도록 돕습니다. 이 pipeline은 세 개 audio data source를 처리하고 15초 end-to-end로 alert를 반환한다고 Mistral은 설명했습니다.
이 사례는 benchmark paper가 아닙니다. corpus 규모, relevance judgment, false positive, false negative, 운영 비용은 발표문에 공개되지 않았습니다. 그래도 AI agent와 search pipeline의 관계를 보여주는 데는 유용합니다. fake news detection에서 모델은 audio나 text를 해석하는 한 단계일 뿐입니다. 어떤 source를 얼마나 빨리 가져오는지, transcription과 indexing이 늦지 않는지, alert 기준이 검증 가능한지, 사람이 확인할 근거를 남기는지가 전체 제품 품질을 정합니다.
15초 end-to-end라는 숫자는 "검색은 offline preprocessing"이라는 가정을 흔듭니다. production AI application에서는 ingestion과 retrieval이 사용자 요청과 가까운 시간 안에서 움직입니다. 음성, support ticket, incident log, code review comment처럼 데이터가 계속 들어오는 환경에서는 index freshness가 품질 지표가 됩니다. Search Toolkit이 ingestion과 evaluation을 retrieval과 같은 framework에 넣은 이유도 이 시간 축과 연결됩니다.
경쟁은 검색 저장소보다 넓습니다
Search Toolkit의 직접 경쟁자는 retrieval framework입니다. LangChain, LlamaIndex, Haystack은 이미 loader, splitter, retriever, evaluator 조합을 제공합니다. vector database와 search engine 쪽에서는 Pinecone, Weaviate, Qdrant, Elasticsearch, OpenSearch, Vespa, pgvector가 있습니다. evaluation 영역에서는 Ragas, TruLens, Phoenix, Braintrust 같은 도구가 RAG 또는 LLM pipeline 품질 측정을 다룹니다.
하지만 Mistral의 포지션은 단일 library보다 넓습니다. Mistral은 Studio에서 agents and apps를 만들고, Connectors로 MCP와 enterprise systems를 붙이며, Workflows로 long-running process를 운영하는 방향을 내세웁니다. Search Toolkit은 이 묶음에서 "agent가 신뢰할 수 있는 검색 경로"를 맡습니다. 모델 회사가 retrieval framework를 공개했다는 점보다, agent platform 회사가 검색 평가를 control point로 삼았다는 점이 더 큽니다.
개발팀에게 이 경쟁 구도는 선택 기준을 바꿉니다. 이미 cloud-managed search를 쓰고 있다면 Search Toolkit은 evaluation과 pipeline portability를 보강하는 후보입니다. 이미 LangChain이나 LlamaIndex로 custom RAG를 만들었다면 component별 실험 관리와 Mistral stack 통합 여부가 판단 기준입니다. Mistral models, Mistral OCR, Voxtral, Studio, Workflows를 함께 쓰는 팀이라면 통합 비용이 낮아질 수 있습니다. 반대로 multi-provider governance가 중요한 팀은 Search Toolkit이 Mistral 생태계에 묶이는 정도를 확인해야 합니다.
도입 전에 eval set부터 만들어야 합니다
Search Toolkit을 검토하는 팀이 가장 먼저 할 일은 설치가 아닙니다. 작은 relevance dataset을 만드는 일입니다. 고객 지원 RAG라면 실제 문의 100개와 정답 문서 ID를 묶어야 합니다. 개발 문서 검색이라면 API 이름, error message, migration guide, deprecated function을 섞은 query set을 만들어야 합니다. 법무나 금융 문서라면 조항 번호와 유사 조항을 함께 넣어 false positive를 봐야 합니다. eval set이 없으면 BM25, vector, hybrid, reranker 비교가 취향 싸움이 됩니다.
두 번째는 freshness와 permission test입니다. RAG pipeline은 검색 품질이 높아도 권한 필터를 놓치면 production에 들어갈 수 없습니다. tenant별 문서, role별 문서, 삭제된 문서, embargo 문서가 query 단계에서 제외되는지 봐야 합니다. stale document test도 필요합니다. 문서를 수정한 뒤 index와 cache가 몇 초 또는 몇 분 안에 바뀌는지 측정해야 합니다. agent가 오래된 정책으로 tool call을 실행하면 단순한 답변 오류보다 큰 운영 문제가 됩니다.
세 번째는 latency budget입니다. Search Toolkit은 semantic caching, reranking, query rewrite 같은 기능을 제공합니다. 이 기능들은 품질을 높일 수 있지만, 호출 수와 latency도 늘립니다. 사용자가 기다리는 chat answer와 background agent의 nightly analysis는 허용 latency가 다릅니다. code search agent가 repository context를 찾는 경로와 customer support copilot이 실시간 상담 중 답하는 경로도 다릅니다. 같은 retrieval stack을 쓰더라도 budget은 workflow마다 나눠야 합니다.
모델 탓을 줄이는 도구입니다
Mistral Search Toolkit 발표의 실무 가치는 RAG를 새로 배우게 하는 데 있지 않습니다. 이미 많은 팀이 RAG를 만들었습니다. 문제는 production에서 실패가 났을 때 원인을 구분하는 장치가 부족하다는 점입니다. 사용자가 틀린 답을 받으면 model, prompt, retriever, indexer, permission filter, source connector, cache가 모두 용의자가 됩니다. Search Toolkit은 이 중 retriever와 pipeline 품질을 별도로 측정하는 구조를 제공합니다.
이 발표는 AI application 개발자에게 불편한 숙제를 줍니다. 좋은 모델을 붙였다는 말로는 enterprise agent 품질을 설명할 수 없습니다. corpus별 relevance set, source별 extractor, sparse와 dense retrieval 비교, reranking 실험, index freshness, access filter, audit log가 필요합니다. Mistral은 이 숙제를 framework로 포장했지만, 정답 문서와 업무 기준을 만드는 일은 여전히 팀 안에 남습니다.
그래도 방향은 분명합니다. agent가 더 많은 일을 맡을수록 검색은 보조 기능이 아니라 실행 전 판단 근거가 됩니다. RAG 실패를 모델 이름으로만 설명하는 팀은 장애를 반복합니다. Mistral Search Toolkit은 그 실패를 retrieval 평가로 분리하라고 말합니다. public preview인 만큼 성급한 migration 대상은 아니지만, 기존 RAG와 agent search path를 점검하는 기준표로는 충분히 구체적입니다.