MiniMax M3 공개, 1M 컨텍스트 오픈웨이트 코딩 모델
MiniMax M3는 1M 컨텍스트, 멀티모달, 코딩 에이전트 벤치마크를 묶었지만 weights와 리포트는 아직 검증 대상입니다.
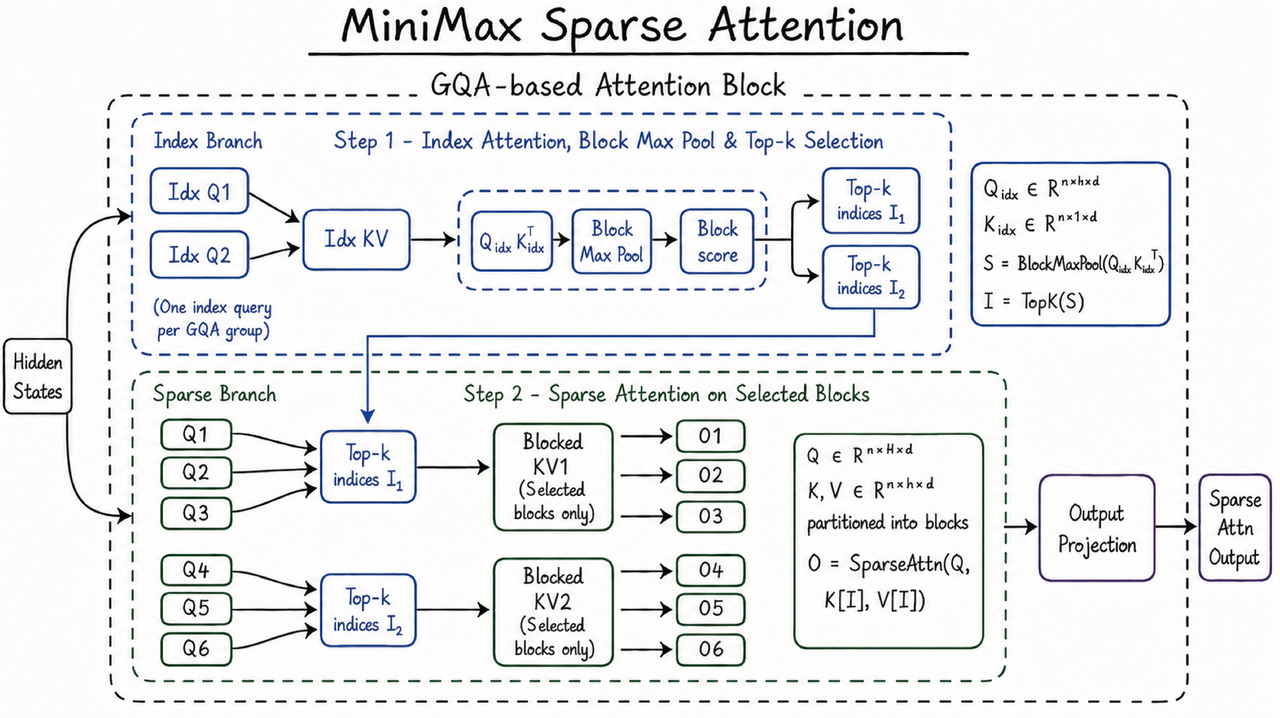
- 무슨 일: MiniMax가 2026년 6월 1일 M3를 공개했습니다.
- 공식 페이지는
MiniMax-M3API, MiniMax Code, 여러 코딩 도구 통합을 열었고, weights와 technical report는 10일 안에 공개하겠다고 적었습니다.
- 공식 페이지는
- 제품 주장: M3는 1M token context, native multimodality, coding·agent benchmark를 한 모델에 묶은 open-weight 후보입니다.
- 개발자 영향: Claude Code, Codex CLI, Cursor, OpenCode 같은 도구에 붙는 자체 배포 모델 후보가 늘어납니다.
- 주의점: 발표 시점에는 parameter count와 weights가 공개되지 않았고, 다수 benchmark는 MiniMax 내부 조건으로 측정됐습니다.
MiniMax가 2026년 6월 1일 M3를 공개했습니다. 회사는 M3를 코딩과 에이전트 작업, 1M token context, native multimodality를 한 모델에 묶은 frontier-class 모델로 소개합니다. 모델 페이지는 API에서 최대 1M token context window와 최소 512K token 보장을 제공한다고 설명합니다. 같은 페이지는 MiniMax-M3 model name, https://api.minimax.io/v1/text/chatcompletion_v2 endpoint, MiniMax Code와 여러 코딩 도구 통합을 함께 제시합니다.
이번 발표에서 가장 조심해서 읽어야 할 단어는 open-weight입니다. MiniMax는 M3가 open world에 complete frontier capability를 가져오는 첫 모델이라고 말하지만, 발표 시점인 2026년 6월 1일에는 weights와 technical report가 아직 내려오지 않았습니다. 공식 블로그는 model serving stability와 throughput을 계속 개선한 뒤, 10일 안에 technical report와 corresponding model weights를 공개하겠다고 적었습니다. 즉 오늘 확인 가능한 것은 API, 제품 통합, 벤치마크 설명, 공식 이미지와 footnote입니다.
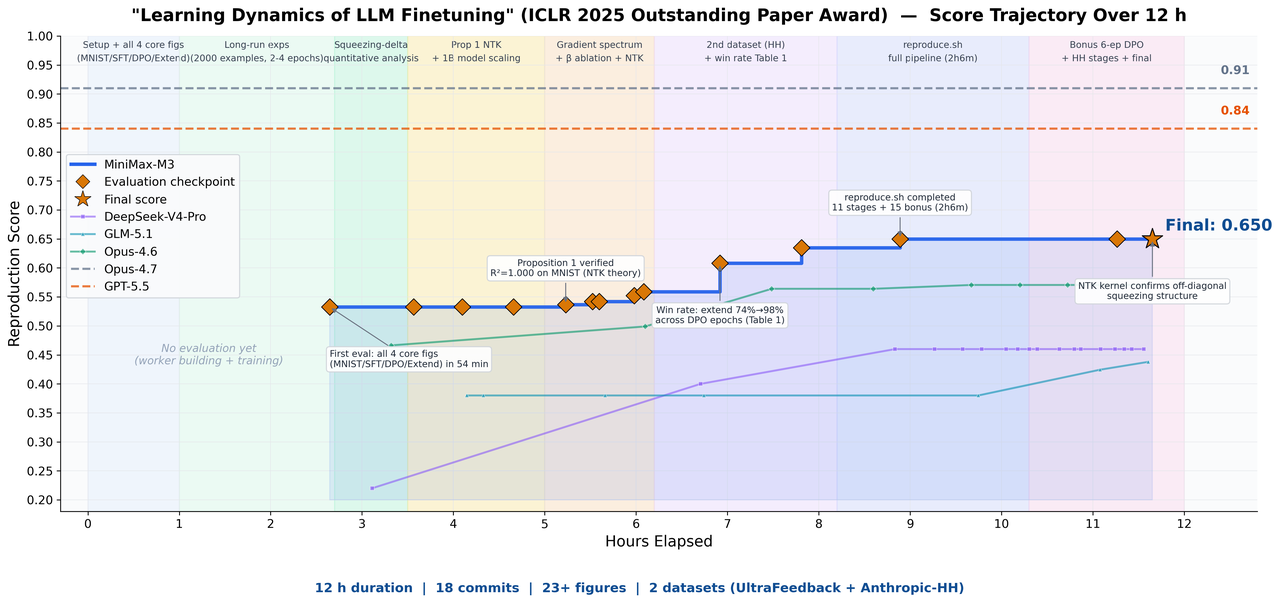
공식 이미지는 M3의 장기 논문 재현 사례를 보여줍니다.
1M 컨텍스트가 앞에 나온 이유
MiniMax는 M3의 architecture 이름을 MiniMax Sparse Attention, 줄여서 MSA라고 부릅니다. 공식 설명은 MSA가 native ultra-long context pretraining을 가능하게 하고, 1M context가 long-range agent tasks, long-range coding, long-video understanding의 infrastructure라고 말합니다. 긴 context를 단순한 숫자로만 내세우지 않고 코딩 에이전트와 멀티모달 입력을 함께 묶은 점이 M3 발표의 구조입니다.
코딩 에이전트에서 context window는 repository 전체를 한 번에 넣는 광고 문구로 자주 쓰입니다. 실제 작업에서는 더 좁은 질문이 남습니다. 모델이 100만 token을 받을 수 있어도, 어떤 파일을 읽어야 하는지 고르지 못하면 긴 window는 노이즈를 키웁니다. 반대로 대형 migration, 긴 log, test failure history, design doc, issue thread를 한 작업 안에 묶어야 할 때는 512K나 1M context가 retrieval과 memory 압박을 줄일 수 있습니다. M3가 실제로 평가받을 지점은 "얼마나 많이 볼 수 있는가"보다 "긴 입력에서 필요한 근거를 얼마나 오래 유지하는가"입니다.
공식 모델 페이지는 M3가 cache를 자동 지원한다고 설명합니다. 이 항목은 비용과 latency에 직접 연결됩니다. 장기 코딩 세션은 같은 repository context를 여러 차례 다시 씁니다. cache가 잘 작동하면 반복 입력 비용이 줄고, tool call 뒤에 같은 문맥을 다시 설명하는 overhead도 줄어듭니다. 다만 cache hit policy, stale context 처리, private deployment에서의 cache boundary는 발표문만으로 확인하기 어렵습니다.
벤치마크는 강하지만 조건이 붙어 있습니다
MiniMax가 전면에 내세운 수치는 코딩·에이전트 benchmark입니다. 모델 페이지는 PostTrainBench에서 M3가 37.1점으로 3위이며, Opus 4.7 42.4와 GPT-5.5 39.3 뒤라고 적었습니다. 같은 페이지는 BrowseComp 83.5점으로 Opus 4.7의 79.3을 넘었다고 주장합니다. 공식 블로그와 모델 페이지는 SWE 계열, Terminal, MCP Atlas, Claw-Eval, OSWorld-Verified, OmniDocBench, VideoMMMU 같은 항목을 길게 나열합니다.
벤치마크 footnote는 더 중요합니다. SWE Atlas-Test Writing에서 GPT-5.5, Claude Sonnet 4.6, Gemini 3.1 Pro 점수는 labs.scale.com에서 가져왔습니다. Claude Opus 4.7, MiniMax-M2.7, MiniMax-M3는 MiniMax 내부 infrastructure에서 Claude Code scaffolding, 4C8G sandbox, 3시간 timeout으로 4회 평균을 냈다고 설명합니다. LiveSQLBench는 600 questions와 22 PostgreSQL databases를 썼고, 각 question은 PostgreSQL이 설치된 dedicated sandbox에서 25분 timeout으로 실행됐다고 적었습니다. VIBE-V2, SVG-Bench, GPDval-Rubrics 등 일부 항목은 internal benchmark 또는 internal evaluation입니다.
이 조건은 M3를 깎아내리는 근거가 아니라 검증 순서를 정하는 근거입니다. 개발팀이 실제로 필요한 것은 leaderboard 숫자 하나가 아닙니다. 자신의 repo, test suite, private docs, coding style, security rule, CI time budget에서 모델이 몇 번의 tool call로 pull request를 끝내는지 봐야 합니다. MiniMax가 공개한 수치는 후보군에 올릴 이유를 줍니다. production 모델로 라우팅할지는 독립 benchmark와 팀 내부 eval로 다시 확인해야 합니다.
| 확인 항목 | MiniMax 공식 주장 | 도입 전 질문 |
|---|---|---|
| Context | 최대 1M tokens, 최소 512K 보장 | 긴 repo 입력에서 관련 파일과 제약을 끝까지 유지하는가 |
| Coding agent | SWE, terminal, Claw-Eval, MCP Atlas 등에서 상위권 | 팀 CI와 review rule에서 patch 품질과 실패 복구가 안정적인가 |
| Open weight | Hugging Face와 GitHub 공개 예정 | license, parameter count, serving memory, quantization 경로가 공개됐는가 |
| Tool integration | Claude Code, Codex CLI, Cursor, OpenCode 등 연결 | 기존 approval, audit log, secret policy와 충돌하지 않는가 |
24시간 CUDA 사례는 agent durability를 겨냥합니다
MiniMax가 M3의 장기 실행 능력을 설명할 때 든 사례는 FP8 GEMM kernel optimization입니다. 공식 모델 페이지는 M3가 약 24시간 동안 147 benchmark submissions와 1,959 tool calls를 수행했고, hardware peak utilization을 7.6%에서 71.3%로 높여 9.4배 speedup을 냈다고 적었습니다. 시작점은 non-runnable Triton skeleton과 task description이었고, human intervention은 없었다고 설명합니다.
이 사례는 일반적인 코딩 assistant 데모와 다릅니다. 코딩 에이전트가 어려워지는 순간은 첫 patch를 만드는 때가 아니라, 실패한 benchmark를 보고 다시 시도하고, 성능 plateau를 넘고, 이전 실험을 기억하고, 도구 호출이 길어져도 방향을 잃지 않는 때입니다. MiniMax가 147 submissions와 1,959 tool calls를 강조한 이유도 여기에 있습니다. 모델 품질만큼 agent loop durability가 구매 기준으로 올라왔다는 뜻입니다.
하지만 이 사례도 public reproduction이 필요합니다. CUDA kernel optimization은 hardware, benchmark harness, timeout, scoring rule, allowed libraries, compiler version에 민감합니다. 내부 데모가 좋은 신호일 수는 있지만, 기업 개발팀이 M3를 선택하려면 비슷한 장기 작업을 자기 환경에서 돌려야 합니다. 예를 들어 flaky test triage, dependency migration, database query optimization, mobile UI snapshot failure 같은 작업은 각 팀의 toolchain이 평가 조건입니다.
Paper reproduction 사례는 multimodal과 긴 context를 묶습니다
공식 블로그는 M3에게 ICLR 2025 Outstanding Paper인 "Learning Dynamics of LLM Finetuning" 재현을 맡겼다고 설명합니다. MiniMax는 이 작업이 거의 12시간 동안 실행됐고, M3가 18 commits와 23 experimental figures를 만들었다고 밝혔습니다. 글의 설명에 따르면 M3는 논문 속 chart와 formula를 multimodal capability로 읽고, paper, code, experiment log를 긴 context에 넣은 뒤, coding과 agentic capability로 실험을 이어갔습니다.
이 사례는 M3가 단순 code completion 모델이 아니라 research assistant와 coding agent 사이를 겨냥한다는 점을 보여줍니다. 논문 재현은 텍스트 이해, 수식·그림 해석, repository 작성, 실험 실행, figure 생성, 결과 비교가 한 작업 안에 들어갑니다. 제품팀 관점에서는 benchmark score보다 이런 mixed workload가 더 가깝습니다. 사내 model eval, report generation, data analysis, migration design review는 모두 텍스트와 코드, 표, 그림, 실행 로그가 섞입니다.
동시에 논문 재현은 과장되기 쉬운 데모 형식입니다. "18 commits"와 "23 figures"는 activity 수치이지 correctness 그 자체가 아닙니다. 어떤 실험이 original paper와 얼마나 일치했는지, random seed와 compute budget이 어떻게 맞춰졌는지, 실패한 시도는 무엇이었는지, 사람이 어느 지점에서 review했는지는 technical report가 공개돼야 더 깊게 볼 수 있습니다. M3 기사에서 이 사례는 가능성의 증거로 두되, 독립 검증 전에는 결론으로 쓰면 안 됩니다.
API와 코딩 도구 통합은 이미 열렸습니다
M3 모델 페이지는 developer choice를 전면에 둡니다. 표시된 도구 목록에는 Claude Code, Roo Code, Kilo Code, Cline, Codex CLI, OpenCode, Droid, TRAE, Grok CLI, Cursor가 포함됩니다. API 예시는 Python과 curl로 제공됩니다. 요청 payload는 model에 MiniMax-M3를 넣고 messages 배열을 보내는 단순한 chat completion 형태입니다. 발표문은 API versions가 동일한 결과를 제공하되 더 빠른 speed를 제공한다고 설명합니다.
이 접근은 open-weight 공개 전에도 시장 반응을 빠르게 모읍니다. 개발자는 기존 코딩 도구에 endpoint를 연결해 M3를 비교할 수 있고, MiniMax는 usage와 failure trace를 보며 serving stability를 개선할 수 있습니다. OpenRouter나 third-party routing을 기다리지 않고 provider endpoint로 바로 붙는 경로도 생깁니다. 기업 입장에서는 procurement와 data boundary가 문제입니다. API를 먼저 테스트하더라도, 최종 목표가 private cluster deployment라면 weights, license, inference stack이 공개된 뒤 다시 평가해야 합니다.
M3가 실제로 매력적인 팀은 세 부류입니다. 첫째, closed frontier model 비용이 커서 일부 코딩 작업을 open-weight model로 내리고 싶은 팀입니다. 둘째, 200K context로는 부족한 repo와 문서 묶음을 다루는 팀입니다. 셋째, 멀티모달 입력을 코딩 작업에 넣고 싶은 팀입니다. UI screenshot, architecture diagram, paper figure, spreadsheet screenshot을 함께 읽는 workflow는 text-only coding model과 다른 실패 양상을 가집니다.
커뮤니티는 parameter count와 weights를 묻습니다
Reddit r/LocalLLaMA의 초기 반응은 발표의 장점과 빈칸을 동시에 짚었습니다. 한 사용자는 "open weights + 1M context + multimodal" 조합이 드물다며 기대를 보였습니다. 다른 사용자는 weights가 아직 없고 parameter count도 보이지 않는다고 물었습니다. 또 다른 댓글은 API output cost 상승과 token plan 변경을 문제 삼았고, 일부는 SWE-Bench류 점수보다 independent tests를 기다리겠다고 적었습니다.
이 반응은 open-weight 모델 커뮤니티의 기준을 잘 보여줍니다. API benchmark만으로는 충분하지 않습니다. model size, active parameters, MoE routing, license, quantization, memory footprint, local serving throughput, tool-call formatting, long-context degradation이 함께 공개돼야 합니다. 특히 M3처럼 1M context와 native multimodality를 내세우면, 단일 GPU나 일반 workstation에서 어떤 형태로 쓸 수 있는지 질문이 바로 따라옵니다.
Context에 대한 회의도 의미가 있습니다. 한 반응은 긴 window 안에 잡음이 가득하면 작은 clean context보다 나쁠 수 있다는 취지였습니다. 이는 코딩 에이전트 제품에서 실제로 반복되는 문제입니다. repository 전체를 넣는 기능보다 dependency graph, recent diff, test failure, owner rule, security policy를 골라 넣는 context selection이 더 중요할 때가 많습니다. M3의 1M context는 이 문제를 없애는 기능이 아니라, 좋은 context selection이 있을 때 더 큰 작업을 담는 인프라입니다.
오픈웨이트 경쟁은 다시 실무 비용으로 내려옵니다
M3의 경쟁자는 한 모델이 아닙니다. closed frontier API 쪽에는 OpenAI GPT-5.5와 Codex, Anthropic Claude Opus/Sonnet, Google Gemini가 있습니다. open-weight와 self-hosting 쪽에는 Qwen, DeepSeek, GLM, Kimi, Mistral, Cohere 계열이 있습니다. inference와 routing 쪽에는 OpenRouter, Fireworks, Together, CoreWeave 같은 경로가 있습니다. 코딩 도구 표면에서는 Cursor, Claude Code, Codex CLI, Cline, OpenCode가 모델 선택을 사용자 workflow 안으로 끌어옵니다.
MiniMax의 차별점은 M3를 "모델 하나"보다 "코딩 도구에 꽂히는 agent model"로 포장했다는 점입니다. Claude Code scaffolding으로 여러 benchmark를 돌렸다는 footnote도 이 포지션과 맞닿아 있습니다. 개발자는 모델 API를 직접 호출하기보다 기존 agent harness에 넣어 비교합니다. 따라서 M3의 품질은 raw chat answer보다 diff quality, shell command 선택, 실패 로그 해석, test rerun 전략, review comment 반영 능력으로 평가됩니다.
비용도 같은 방식으로 봐야 합니다. official page는 M3가 ultra-low commercial threshold를 제공한다고 말하지만, 실제 비용은 token price, cache hit rate, context length, output length, tool-call 반복 횟수, rerun rate가 함께 결정합니다. 1M context 모델이 항상 싸지는 않습니다. 많은 context를 매번 새로 넣고 실패를 반복하면 저렴한 per-token 가격도 빠르게 무너집니다. 반대로 cache가 잘 맞고 한 번의 긴 작업에서 반복 탐색을 줄이면 비싼 closed model보다 총액이 낮아질 수 있습니다.
지금 할 수 있는 검증
개발팀이 M3를 검토한다면 첫 실험은 leaderboard 복제가 아닙니다. 자신의 workflow에서 작은 eval set을 만드는 것이 먼저입니다. 예를 들어 bug fix 20건, dependency migration 10건, flaky test investigation 10건, UI screenshot 기반 수정 10건을 모을 수 있습니다. 각 task에는 시작 branch, 기대 test, 금지된 파일, review rule, budget을 붙입니다. M3, 기존 closed model, 기존 open-weight model을 같은 harness에서 돌려 diff acceptance rate와 total tokens, wall-clock time, human intervention count를 비교해야 합니다.
두 번째 실험은 long-context degradation입니다. 같은 task를 50K, 200K, 512K, 1M context로 나눠 넣고, 필요한 file과 irrelevant file 비율을 바꿔야 합니다. 모델이 큰 context에서 더 나아지는지, 아니면 command selection이 흐려지는지 봐야 합니다. 코딩 에이전트는 "읽을 수 있다"보다 "읽고도 안전하게 행동한다"가 중요합니다. secret file, destructive command, unrelated refactor, generated file edit 같은 policy test도 함께 들어가야 합니다.
세 번째 실험은 weights 공개 후의 serving입니다. Hugging Face와 GitHub에 실제 model card와 technical report가 올라오면 license, parameter count, active parameters를 확인해야 합니다. recommended inference stack, quantization support, GPU memory, throughput도 별도 체크리스트에 넣어야 합니다. API 성능과 self-hosted 성능은 다를 수 있습니다. 같은 M3라도 MiniMax hosted endpoint의 cache와 scheduler, private cluster의 vLLM 또는 다른 runtime 조건은 latency와 failure mode를 바꿉니다.
M3 발표가 남긴 기준
MiniMax M3는 open-weight coding model 경쟁의 기준을 높였습니다. 발표가 사실이라면 개발자는 1M context, multimodal input, 코딩·에이전트 benchmark, tool integration, private deployment 가능성을 한 모델 후보에서 검토하게 됩니다. 이 조합은 closed frontier model API에 의존하던 장기 코딩 workflow를 일부 자체 인프라로 옮길 수 있다는 기대를 만듭니다.
아직 결론은 보류해야 합니다. 2026년 6월 1일 현재 weights와 technical report가 공개되지 않았고, parameter count와 license 세부 조건도 확인 대상입니다. benchmark 상당수는 내부 infrastructure와 내부 평가 조건을 포함합니다. 그래서 M3는 "당장 production에 넣을 모델"보다 "10일 안에 weights가 나오면 바로 eval queue에 넣을 모델"에 가깝습니다.
그래도 이 발표의 방향은 분명합니다. 코딩 에이전트 시장의 비교 기준은 모델명 하나에서 context length, tool-call stability, long-run durability, multimodal parsing, cache economics, self-hosting 가능성으로 쪼개지고 있습니다. MiniMax M3는 그 항목들을 한 번에 묶어 던졌습니다. 이제 개발팀이 확인할 일은 공식 수치가 자신의 repository와 CI, 보안 정책, 비용표에서도 같은 의미를 갖는지입니다.