Cohere North Mini Code 공개, 3B 활성 모델의 코딩 에이전트 실험
Cohere가 30B 중 3B만 활성화하는 Apache 2.0 코딩 모델 North Mini Code를 공개했습니다.

- 무슨 일: Cohere가 2026년 6월 9일
North Mini Code를 공개했습니다.- 모델은 30B total / 3B active MoE 구조이며, Hugging Face에서 Apache 2.0 라이선스로 받을 수 있습니다.
- 개발자 영향: 256K context, 64K output, tool-call template, vLLM 설정을 앞세운 코딩 에이전트용 공개 모델입니다.
- 주의점: Cohere가 적은 최소 하드웨어는 1개 H100 @ FP8입니다.
- "로컬 코딩 모델"로 읽기보다, 회사 내부 GPU나 전용 inference 환경에서 돌릴 수 있는 open-weight 선택지로 보는 편이 정확합니다.
Cohere가 2026년 6월 9일 North Mini Code를 공개했습니다. 이름처럼 작은 모델이라는 인상을 주지만, 숫자를 보면 더 정확한 표현은 "작게 활성화되는 코딩 에이전트 모델"입니다. Cohere 공식 발표는 이 모델을 자사 첫 agentic coding model이자 North 계열의 첫 개발자용 모델로 소개합니다. 모델 크기는 30B total parameters이고, token마다 활성화되는 parameter는 3B입니다. 라이선스는 Hugging Face 모델 카드 기준 Apache 2.0입니다.
이번 발표가 단순한 모델 카드 업데이트로 끝나지 않는 이유는 Cohere가 겨냥한 사용처 때문입니다. Cohere는 North Mini Code를 code generation, agentic software engineering, terminal tasks에 맞췄다고 설명합니다. 일반 챗봇이 아니라, 저장소를 읽고, 터미널을 호출하고, tool result를 다시 대화 기록에 넣는 코딩 에이전트 흐름을 전제로 둔 모델입니다. 공개 모델 진영에서도 이제 "코드를 잘 쓰는가"보다 "도구 호출과 긴 작업 상태를 얼마나 견디는가"가 별도 제품 조건이 됐습니다.
30B 모델인데 3B만 활성화한다는 말
North Mini Code의 중심 숫자는 30B와 3B입니다. Hugging Face 모델 카드는 이 모델을 30B-A3B parameter model이라고 적습니다. 전체 용량은 30B이지만, token 처리 시 활성화되는 전문가 경로는 그보다 작습니다. 구조 설명에는 128개 expert 중 8개가 token마다 선택되는 sparse Mixture-of-Experts 모델이라고 적혀 있습니다. feed-forward block은 SwiGLU activation을 쓰고, attention은 sliding-window attention과 global attention을 3:1 비율로 섞습니다.
이 구조는 코딩 에이전트에서 중요한 두 비용을 동시에 건드립니다. 하나는 모델 capacity입니다. 저장소 구조, 여러 파일의 의존성, terminal output, 이전 추론을 다루려면 단순한 작은 dense 모델보다 더 큰 표현력이 필요합니다. 다른 하나는 inference 비용입니다. 코딩 에이전트는 짧은 답변 하나보다 긴 plan, diff, test log, retry를 많이 생성합니다. active parameter가 작으면 token당 계산량을 낮출 여지가 있습니다. Cohere가 "small, efficient"를 전면에 둔 이유도 이 지점입니다.
다만 이 모델을 가정용 노트북 모델처럼 읽으면 곤란합니다. Cohere 공식 snapshot은 최소 하드웨어를 1x H100 @ FP8로 적었습니다. "3B active"는 실행 비용을 줄이는 설계이지, 8GB VRAM 노트북에서 바로 돌린다는 뜻이 아닙니다. 공개 weight가 있다는 사실과 편한 로컬 실행은 다른 문제입니다. 팀 단위에서는 자체 GPU, private inference, Model Vault, OpenRouter, OpenCode 같은 경로가 논의 대상이 됩니다.
벤치마크가 말하는 강점과 빈칸
Cohere는 North Mini Code의 agentic coding benchmark를 공식 이미지와 모델 카드에 함께 공개했습니다. 숫자는 꽤 구체적입니다. SWE-Bench Verified 67.6, SWE-Bench Pro 40.2, Terminal-Bench v2 36.0, Terminal-Bench Hard 31.1, SciCode 38.2, LiveCodeBench v6 70.3입니다. 비교 대상으로 Devstral Small 2, Poolside XS.2, Gemma4, Qwen3.6이 등장합니다.
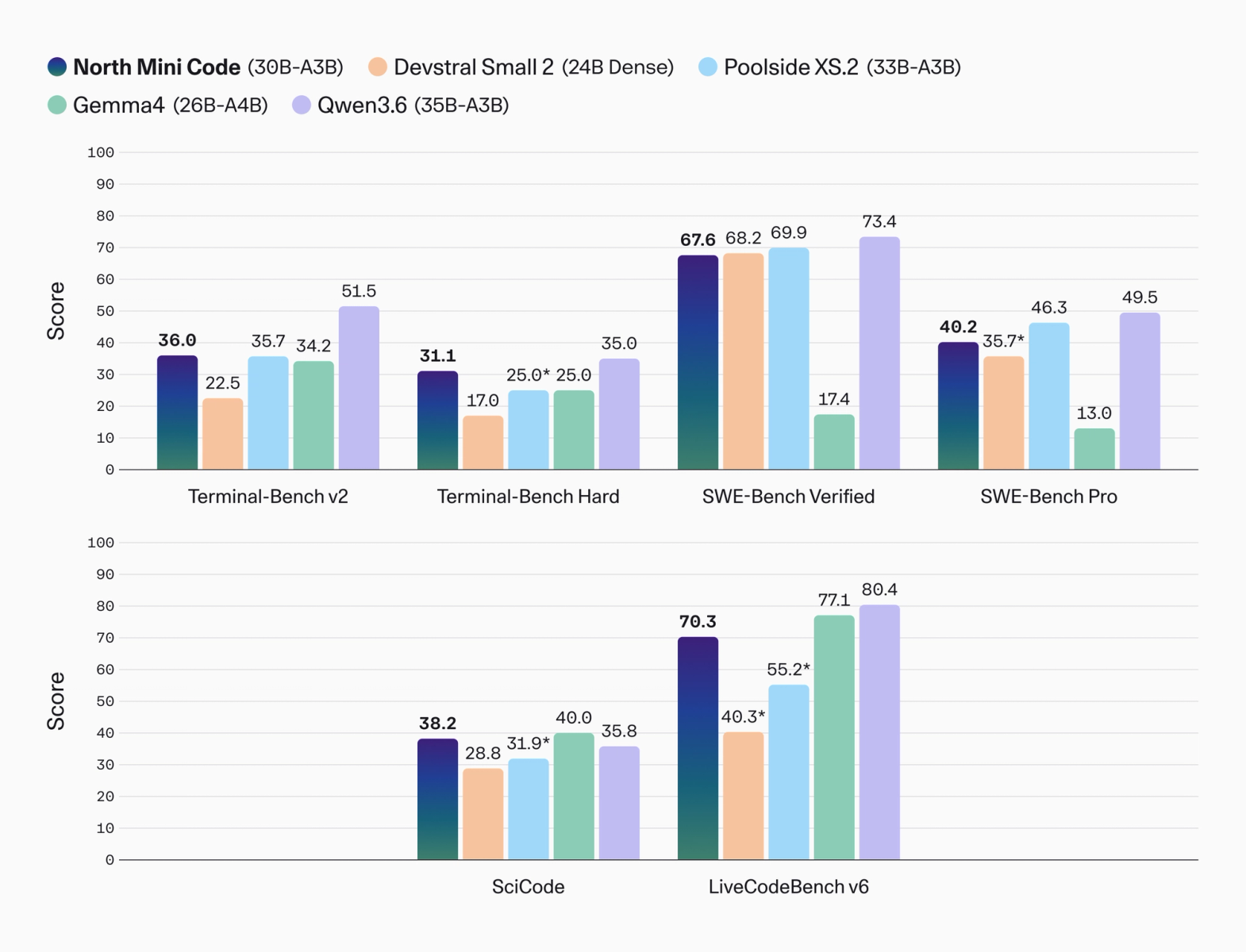
차트에서 North Mini Code가 모든 축을 이기지는 않습니다. SWE-Bench Verified에서는 Poolside XS.2와 Devstral Small 2가 근소하게 앞서고, Qwen3.6은 더 높은 73.4를 보입니다. LiveCodeBench v6에서도 Qwen3.6과 Gemma4가 North Mini Code보다 높습니다. 대신 North Mini Code는 Terminal-Bench Hard에서 31.1을 기록해 Devstral Small 2의 17.0, Poolside XS.2의 25.0, Gemma4의 25.0보다 앞섭니다. 이 차이는 단순 코드 생성보다 terminal 기반 작업에서 Cohere가 모델을 어떻게 조정했는지를 보여주는 부분입니다.
평가 방법도 읽어야 합니다. 모델 카드는 SWE-Bench에 SWE-agent harness v1.1.0을 썼고, Terminal-Bench v2에는 Harbor의 Tmux session 기반 single terminal-use ReAct harness를 사용했다고 설명합니다. Terminal-Bench Hard는 Artificial Analysis Intelligence Index와 같은 방법론을 따르는 Terminus-2를 사용했습니다. 일부 경쟁 모델의 빠진 공개 점수는 Cohere가 내부 권장 설정으로 실행했다고 표시했습니다. 기사나 구매 검토에서 이 숫자를 그대로 순위표로만 쓰면 위험합니다. 내부 실행 점수와 공개 점수가 섞여 있고, harness 차이가 agent benchmark에서는 결과를 크게 바꿀 수 있습니다.
그래도 이 벤치마크가 남기는 질문은 분명합니다. 코딩 에이전트 모델의 비교 축은 HumanEval 같은 짧은 함수 풀이에서 벗어나고 있습니다. 저장소 수정, terminal command, 장기 context, tool result 반영, test failure 복구가 더 중요한 평가 대상입니다. North Mini Code는 이 축에서 "작은 active MoE도 agentic benchmark를 전면에 걸 수 있다"는 사례를 만들었습니다.
속도 주장은 Devstral Small 2를 직접 겨냥합니다
Cohere 발표에서 가장 공격적인 숫자는 처리량입니다. Cohere는 내부 테스트에서 North Mini Code가 Devstral Small 2보다 최대 2.8배 높은 output throughput을 냈고, inter-token latency도 30% 우위였다고 주장합니다. 동시에 time-to-first-token에서는 Devstral Small 2가 약간 앞섰다고 적었습니다. 이 문장은 마케팅보다 실무에 가까운 힌트입니다. 코딩 에이전트에서 첫 token이 조금 빠른 것보다 긴 diff와 test log를 끝까지 생성하는 처리량이 더 중요할 수 있기 때문입니다.
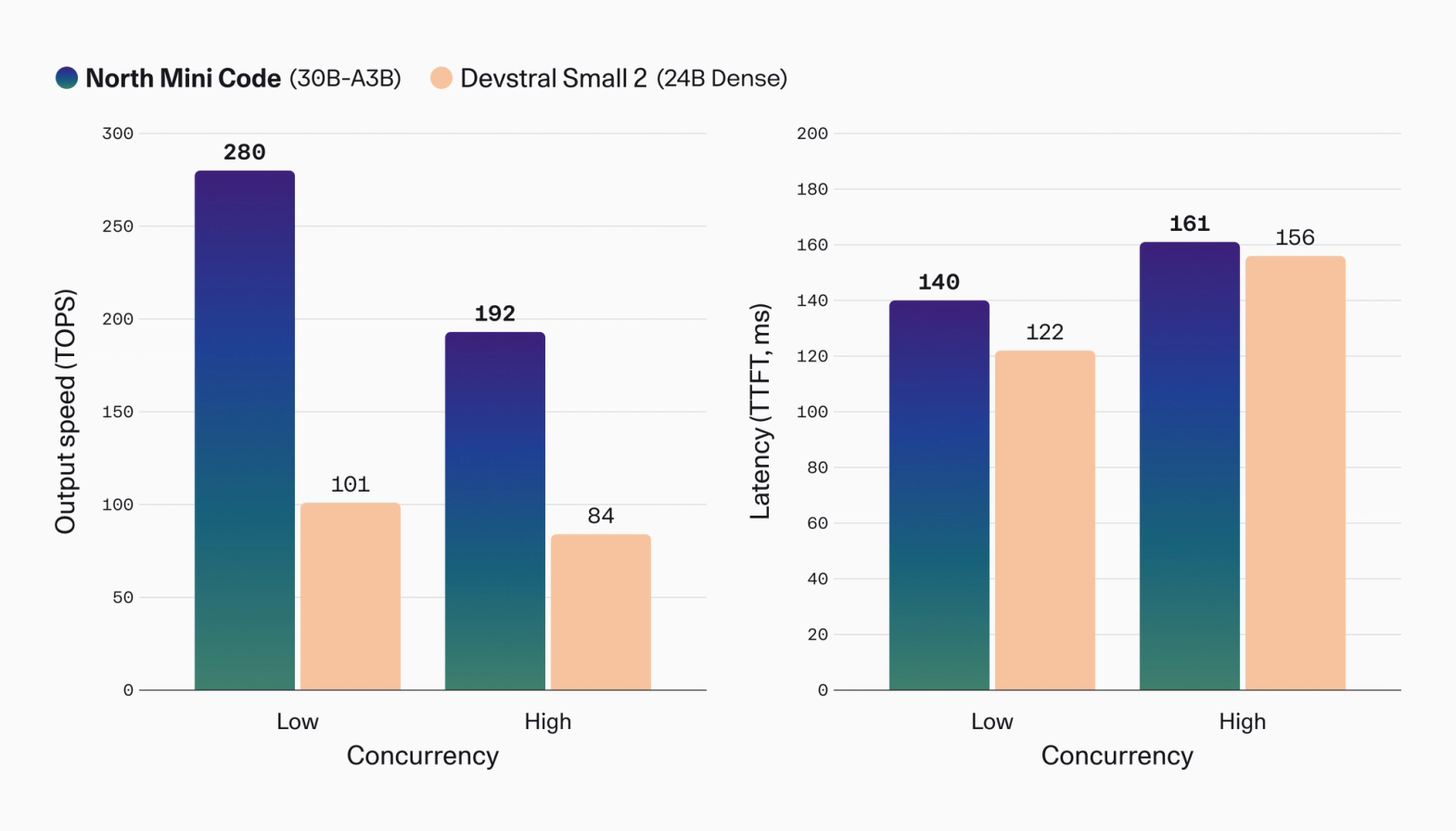
차트 수치는 처리량 차이를 크게 잡습니다. low concurrency에서 North Mini Code는 280 TOPS, Devstral Small 2는 101 TOPS로 표시됩니다. high concurrency에서는 각각 192와 84입니다. latency는 low concurrency에서 North Mini Code 140ms, Devstral Small 2 122ms입니다. high concurrency에서는 161ms와 156ms입니다. Cohere의 주장대로라면 North Mini Code는 첫 응답 지연을 압도적으로 줄이는 모델이 아니라, 같은 하드웨어 조건에서 더 많은 output을 밀어내는 모델입니다.
이 차이는 코딩 에이전트 제품에서 비용 언어로 바뀝니다. 에이전트가 PR 하나를 만들 때 plan, file read, edit proposal, test run, failure analysis, patch retry를 반복하면 output token이 많이 쌓입니다. 속도가 느리면 개발자는 기다리고, 비용이 높으면 팀은 자동 실행 범위를 줄입니다. North Mini Code의 설계가 맞아떨어지는 사용처는 "최고 품질 frontier model 한 번 호출"보다 "반복적인 agent step을 빠르게 많이 실행"하는 곳입니다.
tool call은 모델 성능만큼 배포 구현을 요구합니다
North Mini Code의 모델 카드에서 흥미로운 부분은 tool use 설명입니다. Cohere는 JSON schema로 tool description을 제공하는 chat template 방식을 안내합니다. 예시는 bash tool을 정의하고, 모델이 thinking content와 tool call을 생성하면 둘 다 chat history에 다시 넣으라고 설명합니다. tool result는 dictionary 형태로 tool role에 넣습니다. 이 방식은 코딩 에이전트에서 흔히 보는 pattern이지만, 공개 모델에서는 parser와 template의 안정성이 실제 사용성을 결정합니다.
vLLM 설정도 아직 단순하지 않습니다. 모델 카드는 North Mini Code를 위해 vLLM main branch를 쓰고, cohere_melody>=0.9.0을 설치하라고 안내합니다. 실행 예시에는 --tool-call-parser cohere_command4, --reasoning-parser cohere_command4, --enable-auto-tool-choice가 함께 들어갑니다. OpenCode에서 쓰려면 interleaved reasoning field를 설정하는 config도 필요합니다. 즉 weight를 받는 순간 agent runtime이 완성되는 것은 아닙니다. tokenizer, chat template, reasoning field, tool-call parser, history serialization이 맞아야 모델 성능이 유지됩니다.
이 부분은 North Mini Code의 장점이자 채택 장벽입니다. 폐쇄형 API는 provider가 tool-call 형식과 streaming event를 관리합니다. 공개 모델은 팀이 그 경계를 직접 맞춥니다. 대신 성공하면 모델 업데이트 주기, 데이터 경로, inference 위치를 더 많이 통제할 수 있습니다. 규제 산업이나 코드 유출을 걱정하는 조직에서는 이 통제권이 비용을 정당화할 수 있습니다.
Cohere의 소버린 AI 메시지가 개발자 모델로 내려왔습니다
Cohere는 최근 몇 달 동안 "sovereign AI"를 반복해 왔습니다. Command A+에서는 private deployment와 open model을 강조했고, Reliant AI 인수에서는 규제 산업의 workflow를 붙였습니다. North Mini Code는 같은 메시지를 개발자 인프라 쪽으로 내립니다. 발표문은 "sovereign developer ecosystem"이라는 표현을 씁니다. 개발자가 vendor API에만 묶이지 않고, 자체 환경에서 코딩 에이전트를 돌릴 수 있어야 한다는 주장입니다.
이 포지션은 OpenAI, Anthropic, GitHub, Google과 정면으로 맞물립니다. 폐쇄형 코딩 에이전트는 대체로 더 강한 frontier model, 관리형 tool execution, 쉬운 제품 경험을 제공합니다. 반대로 공개 weight 모델은 실행 위치와 비용 구조를 더 많이 열어 둡니다. North Mini Code가 던지는 질문은 "Claude Code나 Codex보다 똑똑한가" 하나가 아닙니다. "내부 저장소와 terminal trace를 외부 API로 보낼 수 없는 팀이 쓸 수 있는 에이전트 모델인가"가 더 직접적인 질문입니다.
| 검토 항목 | North Mini Code | 폐쇄형 코딩 에이전트 API |
|---|---|---|
| 데이터 경로 | 자체 GPU, Model Vault, 선택한 inference 경로로 통제 가능 | provider API와 제품 정책에 의존 |
| 운영 부담 | vLLM, parser, scaling, monitoring을 직접 맞춰야 함 | tool execution과 streaming 형식을 provider가 관리 |
| 비용 단위 | GPU, serving engineer, utilization, quantization이 핵심 | token, seat, premium request, action minute가 핵심 |
| 성능 검증 | 팀별 저장소 trace와 tool-call 안정성 평가가 필요 | provider benchmark와 제품 로그를 함께 확인 |
커뮤니티 반응은 기대와 하드웨어 현실로 갈립니다
공개 직후 반응은 빠르게 모였습니다. Reddit r/LocalLLaMA에는 Cohere 관계자가 North Mini Code 공개 글을 올려, unreleased version에 대한 주말 피드백 뒤 공식 출시했다는 맥락을 설명했습니다. 다른 LocalLLaMA 게시글은 30B parameters, 3B active, Apache 2.0, Artificial Analysis Coding Index 33.4, Hugging Face 공개를 요약했습니다. OpenCode는 X에서 North Mini Code를 256K context로 무료 제공한다고 알렸습니다.
반응의 양쪽은 자연스럽습니다. 긍정적인 쪽은 Apache 2.0 모델이 agentic coding benchmark와 tool-use 설명을 함께 들고 나온 점을 봅니다. 회의적인 쪽은 "single H100" 조건을 봅니다. 공개 weight 모델이라도 serving 비용은 사라지지 않습니다. 특히 256K context와 64K output을 실제로 쓰려면 KV cache, concurrency, tool log 길이가 비용을 빠르게 키웁니다. North Mini Code는 개인 취미용 로컬 모델보다 사내 에이전트 인프라 후보에 가깝습니다.
Hugging Face 모델 페이지도 같은 방향을 보여줍니다. 모델 카드는 Transformers, vLLM, SGLang, Docker Model Runner, quantization 경로를 안내하지만, Inference Providers 섹션에는 현재 배포된 provider가 없다고 표시됩니다. 공개 모델 생태계에서 채택은 weight 공개 다음 단계에서 결정됩니다. llama.cpp, Ollama, LM Studio, vLLM, SGLang, OpenCode가 얼마나 매끄럽게 붙는지가 실제 사용자의 첫 경험을 좌우합니다.
개발팀이 바로 확인할 질문
North Mini Code를 검토하는 팀은 벤치마크 표보다 자기 저장소 trace를 먼저 만들어야 합니다. 작은 bug fix, 테스트 실패 복구, 다중 파일 refactor, migration script 작성, CI log 분석 같은 실제 작업 20개를 뽑습니다. 같은 작업을 North Mini Code, Devstral Small 2, Qwen3.6, Claude, Codex 같은 후보에 걸고, 성공률만이 아니라 command count, retry count, wall time, output token, human review diff를 같이 기록해야 합니다.
두 번째 질문은 tool-call format입니다. 모델이 bash, read_file, edit_file, run_tests 같은 tool schema를 얼마나 안정적으로 지키는지 봐야 합니다. reasoning field를 다음 turn에 넘겼을 때 성능이 나아지는지, 반대로 오래된 추론이 잘못된 확신으로 쌓이는지도 확인해야 합니다. Cohere 모델 카드는 model-generated thinking contents를 미래 agentic step과 chat turn에 넘기라고 권합니다. 이 권장은 성능에는 도움이 될 수 있지만, product logging과 privacy policy, audit trail에서는 별도 설계가 필요합니다.
세 번째 질문은 비용입니다. H100 한 장으로 시작할 수 있다는 말은 조달 입장에서는 긍정적이지만, 코딩 에이전트는 idle과 burst가 심합니다. 낮 시간에는 여러 developer가 동시에 agent task를 돌리고, 밤에는 CI나 scheduled refactor가 몰릴 수 있습니다. GPU utilization을 확보하지 못하면 managed API보다 싸지 않을 수 있습니다. 반대로 보안 때문에 외부 API가 불가능한 팀에게는 비용 비교가 아니라 가능 여부의 문제가 됩니다.
North Mini Code가 남기는 신호
North Mini Code는 "가장 강한 코딩 모델"이라는 단순한 결론을 주지 않습니다. 공개된 그래프만 봐도 모든 benchmark에서 1위가 아닙니다. 대신 발표가 보여주는 신호는 더 실무적입니다. 코딩 에이전트 시장에서 모델 선택지는 frontier API, IDE 통합 제품, cloud agent, open-weight self-hosting으로 나뉘고 있습니다. Cohere는 이 중 open-weight self-hosting과 enterprise/private deployment 쪽에 개발자용 모델을 직접 넣었습니다.
이 모델의 성공 여부는 다음 몇 주 동안 공개될 사용 후기에 달려 있습니다. 실제 repository에서 tool-call parser가 얼마나 안정적인지, 256K context가 긴 코드베이스에서 어떤 비용을 만드는지, H100 한 장 조건이 quantization과 batching에서 어디까지 줄어드는지가 관건입니다. Artificial Analysis Coding Index 33.4나 SWE-Bench Verified 67.6은 출발점입니다. 실전에서는 test pass rate, diff quality, review burden, token budget, GPU invoice가 더 냉정한 평가표가 됩니다.
그래도 Cohere가 던진 방향은 분명합니다. 코딩 에이전트는 폐쇄형 챗봇 제품 안에만 갇히지 않습니다. 모델 weight, inference stack, tool-call parser, terminal harness, IDE/CLI 표면이 한 묶음으로 경쟁합니다. North Mini Code는 그 묶음에서 "작은 active MoE를 자체 경계 안에 올려 코딩 에이전트를 운영할 수 있는가"라는 실험입니다. 결과가 성공이든 제한적이든, AI 개발팀이 앞으로 모델을 고를 때 보게 될 질문은 더 구체적입니다. 누가 더 큰 모델을 냈는가가 아니라, 우리 코드와 우리 터미널과 우리 보안 경계 안에서 얼마나 오래 일할 수 있는가입니다.