Xiaomi MiMo Code 공개, 200스텝 넘는 코딩 에이전트의 메모리 실험
Xiaomi MiMo Code는 OpenCode 기반 MIT 코딩 에이전트입니다. 200스텝 장기 작업에서 메모리, 체크포인트, 완료 검증을 전면에 세웠습니다.

- 무슨 일: Xiaomi MiMo 팀이 2026년 6월 10일
MiMo Code를 MIT 라이선스로 공개했습니다.- OpenCode 기반 터미널 코딩 에이전트이며, 공식 블로그는 장기 작업 병목을
computation,memory,evolution으로 나눕니다.
- OpenCode 기반 터미널 코딩 에이전트이며, 공식 블로그는 장기 작업 병목을
- 숫자: 내부 A/B 평가는 576명 개발자, 474개 비공개 저장소, 1,213개 비교 pair를 제시했습니다.
- Xiaomi는 200 step 이하 작업에서는 Claude Code와 win rate가 50%에 가깝고, 200 step 초과 작업에서는 MiMo Code가 65%를 넘었다고 설명합니다.
- 주의점: 벤치마크와 A/B 결과는 공식 발표 기준이며, 외부 재현과 실제 저장소 검증이 필요합니다.
Xiaomi가 공개한 MiMo Code는 "또 하나의 AI 코딩 CLI"로만 읽기 어렵습니다. 공식 블로그는 2026년 6월 10일 MiMo Code를 "long-horizon automated programming tasks"용 터미널 기반 코딩 에이전트라고 소개했습니다. GitHub 저장소는 MIT 라이선스이며, README는 OpenCode 위에 만든 fork라고 적습니다. 이 조합은 모델 발표보다 런타임 발표에 가깝습니다. 언어 모델을 호출하는 부분보다, 수십 또는 수백 번의 tool call 뒤에도 에이전트가 왜 같은 목표를 기억해야 하는지를 제품 구조로 다룹니다.

이 뉴스의 시점도 흥미롭습니다. 같은 주에 GitHub는 Agentic Workflows로 자연어 Markdown을 Actions YAML 쪽으로 가져갔고, Cohere는 North Mini Code를 통해 작은 활성 파라미터 코딩 모델을 전면에 세웠습니다. MiMo Code는 그 둘과 다른 질문을 던집니다. "어떤 모델이 더 똑똑한가"가 아니라 "긴 작업에서 상태를 누가 저장하고, 언제 다시 주입하고, 완료 여부를 누가 독립적으로 판정하는가"입니다. 코딩 에이전트 시장의 비교 단위가 모델명에서 runtime, memory, verifier, workflow로 쪼개지고 있다는 신호입니다.
Xiaomi가 문제로 본 것은 긴 대화의 희석입니다
MiMo 블로그의 문제 정의는 간단합니다. 짧은 작업, 예를 들어 10 turn 미만의 수정에서는 전체 대화 history를 모델에 넣어도 충분할 수 있습니다. 하지만 수십 turn을 지나면 tool output, code snippet, error log가 context window를 채웁니다. 일부 기록을 요약하거나 버려야 하는데, 단순 요약은 가까운 정보는 강화하고 먼 정보는 약하게 만듭니다. 블로그는 이를 Mamba 같은 recurrent model의 딜레마에 비유합니다. 상태는 있지만 필요할 때 마음대로 되돌아볼 수 없다는 뜻입니다.
두 번째 문제는 더 실무적입니다. context window가 충분히 커도 입력이 길어지면 instruction-following이 흔들립니다. 사용자 의도, repository rule, 이전 실패, 보안 제한, 테스트 조건이 tool output 사이에서 희석됩니다. MiMo는 이 병목을 세 시간축으로 나눕니다. 한 turn 안의 판단 품질은 computation이 좌우하고, 한 session 안의 연속성은 memory가 좌우하며, session을 넘는 학습은 evolution이 좌우한다고 봅니다.
이 프레이밍은 코딩 에이전트를 "모델을 감싼 CLI"가 아니라 "상태를 다루는 runtime"으로 보게 합니다. 특히 OpenCode 기반이라는 점이 중요합니다. README는 MiMo Code가 OpenCode의 multiple providers, TUI, LSP, MCP, plugins를 유지한다고 설명합니다. 여기에 persistent memory, intelligent context management, subagent orchestration, goal-driven autonomous loops, compose workflows, dream/distill을 추가했습니다. Xiaomi가 모델 회사의 성능표만 들고 나온 것이 아니라, 이미 쓰이는 오픈소스 코딩 에이전트 구조 위에서 장기 실행 기능을 덧붙인 셈입니다.
Max Mode는 한 번 더 생각하게 만드는 병렬 비용입니다
첫 번째 축인 computation에서 눈에 띄는 기능은 Max Mode입니다. 공식 블로그 기준으로 Max Mode는 각 turn에서 기본 N=5개의 후보 solution을 병렬로 만듭니다. 후보들은 reasoning과 tool-call plan을 독립적으로 완성하지만 실제 실행은 하지 않습니다. 이후 같은 모델이 judge가 되어 reasoning process와 action plan을 비교하고, 가장 견고한 후보 하나를 실행 대상으로 고릅니다.
Xiaomi는 SWE-Bench Pro에서 Max Mode가 single sampling 대비 10-20% 성능을 올렸고, token consumption은 약 4-5배 든다고 설명합니다. 이 숫자는 제품 설계의 tradeoff를 그대로 드러냅니다. 코딩 에이전트는 한 번의 잘못된 파일 수정이 다음 20번의 tool call을 오염시킬 수 있습니다. 한 turn의 결정 오류를 줄이기 위해 병렬 후보와 judge 비용을 먼저 쓰는 방식은, 긴 작업에서 누적 오류를 줄이려는 test-time compute 전략입니다.
다만 이 기능은 아직 실험적입니다. 블로그는 Max Mode를 configuration에서 수동으로 켜야 한다고 적습니다. 따라서 "기본 성능"으로 읽기보다 "복잡한 작업에 비용을 더 태워 decision risk를 낮추는 옵션"으로 보는 편이 맞습니다. 개발팀 입장에서는 이 지점이 비용 정책과 곧바로 연결됩니다. 4-5배 token을 쓰는 모드는 모든 issue triage에 켤 기능이 아니라, migration, architecture rewrite, production incident처럼 실패 비용이 큰 작업에 붙일 기능입니다.
Goal은 에이전트의 조기 종료를 따로 심사합니다
두 번째 computation 기능은 Goal입니다. 블로그는 긴 작업에서 에이전트가 기존 progress를 보고 "끝났다"고 선언하거나, 자동 실행 중 질문을 던지고 멈추는 실패를 흔한 위험으로 봅니다. 사용자는 "all tests pass and the code has been committed" 같은 자연어 stopping condition을 설정합니다. 이후 에이전트가 종료하려 할 때 독립 모델 호출이 전체 conversation history와 실제 tool output을 다시 보고 조건 충족 여부를 판단합니다.
이 verifier는 실제 작업에 참여하지 않습니다. 그래서 작업을 진행한 에이전트가 자기 결과에 맞춰 판단을 완화하는 bias를 덜 받습니다. Xiaomi는 false passing보다 false blocking이 더 흔하고, 주로 environment issue 때문에 이미 충족된 조건을 아직 아니라고 판단하는 경우가 많다고 설명합니다. infinite loop 확률은 0.5% 미만이며, 한계에 도달하면 자동 종료할 수 있다고도 적었습니다.
이 설명에서 개발자가 확인해야 할 지점은 "자연어 목표를 누가 증명 가능한 조건으로 바꾸는가"입니다. Goal은 테스트 실행, commit 여부, diff 상태처럼 tool output에 남는 증거가 있을 때 강합니다. 반대로 "품질이 충분히 좋다", "사용자가 만족할 UI다" 같은 조건은 judge 모델의 선호에 의존합니다. MiMo Code의 설계가 흥미로운 이유는 완전한 해결책을 주장해서가 아니라, 조기 종료를 runtime-level failure mode로 명명했다는 데 있습니다.
장기 작업의 핵심은 checkpoint writer입니다
MiMo Code의 두 번째 축인 memory는 이번 발표의 중심입니다. 공식 블로그는 logical session과 physical window를 분리합니다. 하나의 작업은 논리적으로 계속되지만, 실제 모델 context window는 언젠가 꽉 찹니다. MiMo Code는 window가 한계에 가까워질 때 급히 요약하지 않고, 더 이른 시점에 checkpoint를 만듭니다. trigger 지점은 configured budget의 약 20%, 45%, 70%입니다.
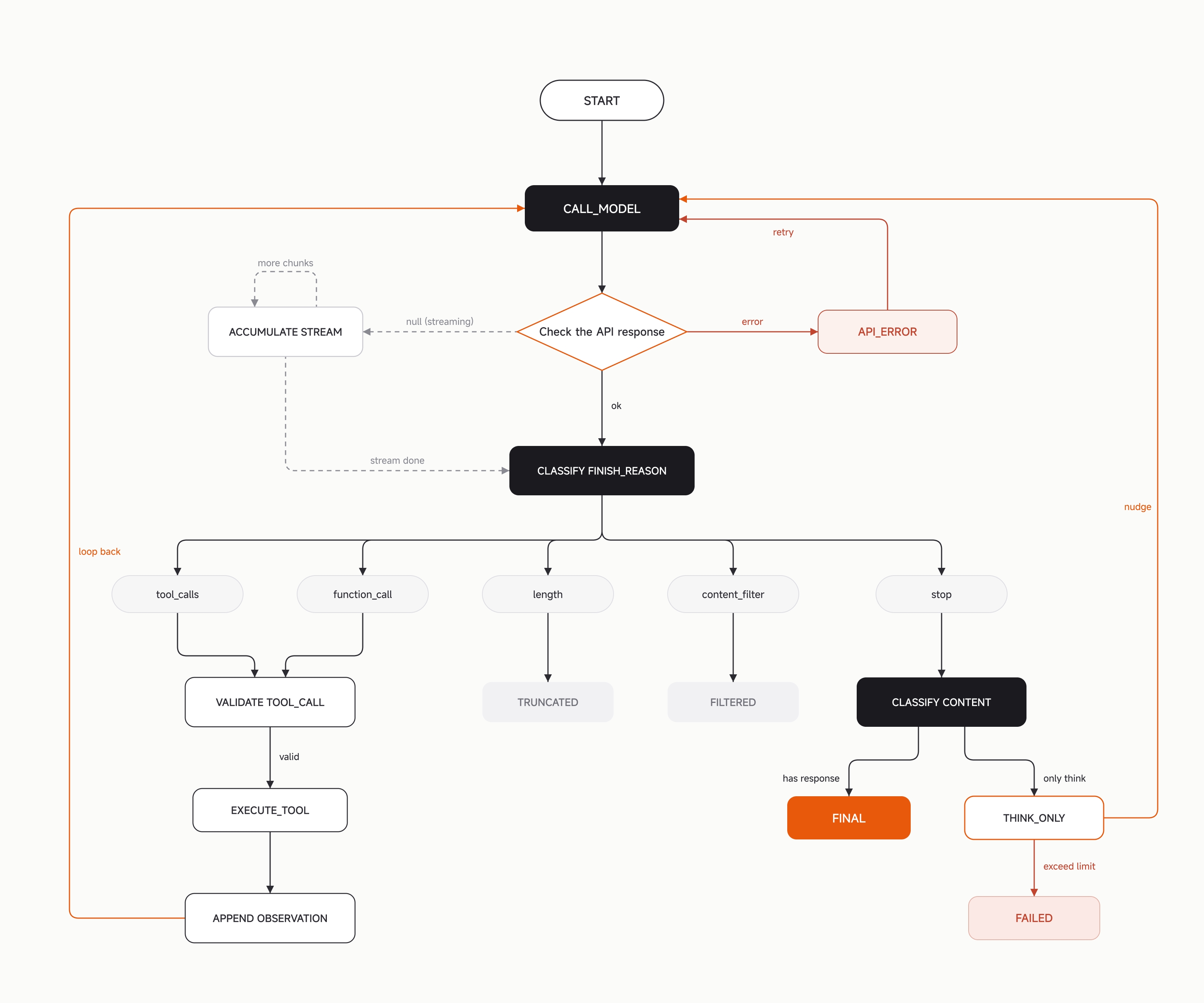
이 일을 main agent가 직접 하지 않는다는 점도 중요합니다. Xiaomi는 debugging 중인 모델에게 동시에 structured log를 유지하게 하면 두 작업 모두 나빠진다고 봅니다. 그래서 runtime이 독립적인 writer subagent를 실행합니다. writer는 현재 intent, next action, working constraints, task tree, current work, involved files를 checkpoint file에 씁니다. errors and fixes, runtime state, design decisions까지 포함해 총 11개 field를 유지합니다. 각 structured file에는 정확히 한 actor만 write permission을 갖도록 해 concurrent write inconsistency를 줄입니다.
이 방식은 기존 "대화 요약"과 다릅니다. 요약은 보통 context가 가득 찬 뒤 마지막 순간에 생성됩니다. MiMo는 capability degradation이 심해지는 시점에 중요한 추출을 맡기면 안 된다고 주장합니다. 30% 안팎의 여유 있는 window에서 incremental extraction을 해두고, 한계 근처에서는 이미 저장된 구조를 새 window에 주입합니다. 이 주장은 실제 장기 agent 운영에서 설득력이 있습니다. 긴 log가 쌓인 뒤 모델에게 "중요한 것만 남겨줘"라고 맡기는 방식은, 정작 중요한 실패 조건이 중간 어딘가에 묻힐 때 약합니다.
MEMORY.md와 SQLite history의 역할이 다릅니다
MiMo Code의 memory layer는 네 개입니다. 첫째, checkpoint.md는 현재 logical session의 complete working state를 담습니다. 둘째, MEMORY.md는 project-level knowledge입니다. architecture decision, user rule, 반복 검증된 technical fact가 여기에 들어갑니다. 셋째, global memory는 project를 넘는 user-level preference를 담습니다. 넷째, history는 SQLite trace입니다. 모든 message와 tool call의 raw text를 indexing 없이 저장하고, structured memory에서 못 찾는 디테일을 원본 기록으로 따라갈 때 사용합니다.
이 구조에서 위쪽 layer는 더 작고 정제되어 있으며, 아래쪽 layer는 더 크고 완전하지만 느립니다. writer는 아래쪽 기록을 위쪽 memory로 distill합니다. main agent에게 허용된 예외적 write channel은 notes.md입니다. main agent는 흩어진 발견을 여기에 append할 수 있고, checkpoint마다 writer가 이를 읽어 적절한 structured field로 옮긴 뒤 notes를 비웁니다.
파일 기반 memory를 택한 이유도 실용적입니다. 공식 블로그는 memory가 agent 행동에 영향을 주면 사용자가 무엇을 기억했는지 보고, 틀린 항목을 지우고, 오래된 내용을 고칠 수 있어야 한다고 설명합니다. 순수 vector database보다 Markdown file과 full-text index를 조합한 이유입니다. 이는 Codex, Claude Code, Cursor rules를 쓰는 개발자에게 익숙한 방향입니다. 에이전트가 "기억한다"고 말하려면, 기억의 편집 가능성과 감사 가능성이 같이 있어야 합니다.
Dynamic Workflow는 prompt 절차를 JavaScript로 바꿉니다
MiMo Code는 대규모 병렬 orchestration도 별도 문제로 다룹니다. 블로그는 "A를 먼저 하고, B를 하고, C가 발생하면 D를 하라"는 절차를 SKILL.md 같은 자연어 prompt에 넣는 방식이 복잡한 workflow에서 무너진다고 지적합니다. context compression이 step을 삼키거나, 모델이 특정 stage를 건너뛰거나, branching과 retry logic이 모델 판단에 맡겨지는 문제가 생긴다는 설명입니다.
대안은 Dynamic Workflow입니다. main agent가 JavaScript script를 생성하고, isolated sandbox가 이를 실행합니다. script는 agent(), parallel(), pipeline()으로 sub-agent를 dispatch하고 concurrency를 제어합니다. if 문은 branch를 잊지 않고, for loop는 임의로 빠져나가지 않으며, barrier는 sub-agent를 놓치지 않는다는 것이 Xiaomi의 설명입니다. model judgment는 code 이해와 생성에 쓰고, flow control은 code가 맡게 하겠다는 설계입니다.
이 대목은 Anthropic Dynamic Workflow와도 연결됩니다. Xiaomi는 core semantics와 호환되며, workflow() primitive로 script가 다른 script를 호출할 수 있게 했다고 설명합니다. 또한 각 agent() call 결과를 disk에 동기적으로 기록해 interruption 후 log에서 복구할 수 있게 했습니다. 이 방향은 앞으로 "agent skill"이 자연어 instruction에서 executable workflow로 옮겨갈 가능성을 보여줍니다. 반복 가능한 release, migration, audit 작업은 prompt보다 code가 더 검증하기 쉽습니다.
Dream과 Distill은 메모리 정리를 제품 기능으로 넣습니다
세 번째 축인 evolution은 session을 넘는 축적입니다. MiMo Code는 /dream과 /distill을 README와 블로그 양쪽에서 강조합니다. Dream은 7일마다 자동 trigger됩니다. 독립 agent가 historical session conversation과 memory file을 읽고, merge, deduplication, path-validity verification, compression을 수행합니다. 목적은 흩어진 memory를 현재 상태에 맞는 compact representation으로 수렴시키는 것입니다.
Distill은 30일마다 실행됩니다. 여기서 대상은 지식이 아니라 process입니다. 반복되는 manual workflow를 찾아 skills, CLI commands, custom agents, SOP documents 같은 재사용 가능한 artifact로 굳힙니다. 이 구조는 장기 사용자를 겨냥합니다. 같은 repository에서 매주 release note를 쓰고, 같은 test failure를 추적하고, 같은 deployment checklist를 반복하는 팀이라면, agent가 매번 처음 배우는 것보다 process artifact로 남기는 편이 낫습니다.
물론 이 기능들은 검증 부담도 같이 만듭니다. Dream이 잘못된 memory를 압축하면 다음 session 전체가 틀어진 전제를 갖고 시작할 수 있습니다. Distill이 낮은 품질의 반복 패턴을 skill로 굳히면 자동화된 나쁜 습관이 됩니다. 그래서 공식 블로그가 파일 기반 reviewability를 강조한 것은 장점입니다. 메모리 자동화의 핵심은 "얼마나 많이 기억하느냐"보다 "틀린 기억을 사람이 어디서 고칠 수 있느냐"입니다.
576명 A/B 테스트, 하지만 외부 재현은 아직 남았습니다
평가 파트에서 Xiaomi는 두 종류의 근거를 냅니다. 먼저 공식 블로그 Figure 3는 MiMo Code와 Claude Code를 세 가지 benchmark에서 비교합니다. Xiaomi는 MiMo Code + MiMo-V2.5-Pro가 Claude Code + Claude Sonnet 4.6보다 세 평가에서 앞선다고 주장합니다. 다만 블로그 자체도 이 benchmark가 individual repository-level issue의 one-shot problem-solving에 가깝다고 인정합니다. MiMo Code가 노리는 multi-turn memory, background state maintenance, completion verification, cross-session evolution의 가치는 실제 장기 개발에서 드러난다는 설명입니다.

더 강한 숫자는 human double-blind A/B입니다. Xiaomi는 내부 beta가 576 developers, 474 real private repositories, 1,213 A/B pairs를 포함했다고 설명합니다. 같은 target model 아래에서 MiMo Code와 Claude Code를 익명으로 실행하고, 개발자가 결과를 평가했으며 trajectory scoring과 diff quantification을 함께 사용했다고 합니다. 결과는 task complexity가 커질수록 MiMo Code 쪽으로 기울었다는 주장입니다. execution steps가 200 이하일 때는 win rate가 50%에 가깝고, 200을 넘으면 65% 이상으로 올라갔다고 밝혔습니다.
이 숫자는 기사 제목에 넣을 만큼 구체적입니다. 동시에 아직 공식 자체 평가입니다. 저장소가 비공개이고, task selection, target model, scoring rubric, 실패 케이스 분포를 외부에서 재현할 수 없습니다. 따라서 "Claude Code를 이겼다"보다 "200 step을 기준으로 장기 작업 평가를 들고 나왔다"가 더 정확한 해석입니다. 코딩 에이전트 평가가 SWE-Bench 한 줄에서 실제 사내 저장소 A/B로 이동하고 있다는 점이 더 큰 뉴스입니다.
사용 경로는 낮지만, 운영 질문은 무겁습니다
사용법은 간단합니다. 공식 블로그와 README는 한 줄 설치로 curl -fsSL https://mimo.xiaomi.com/install | bash를 제시하고, npm 설치로 npm install -g @mimo-ai/cli를 제공합니다. 첫 실행에서는 MiMo Auto, Xiaomi MiMo Platform OAuth login, Claude Code configuration import, custom OpenAI-compatible API provider를 고를 수 있습니다. MiMo Auto는 제한된 기간 무료 channel이며, 블로그는 MiMo-V2.5 기반 100만 token context를 지원한다고 설명합니다.
개발자가 먼저 봐야 할 질문은 세 가지입니다. 첫째, memory file과 history가 어떤 범위의 code, secret, command output을 저장하는지입니다. README에는 project memory, checkpoint, scratch notes, task progress가 나오고, 공식 블로그에는 SQLite history가 나옵니다. 회사 repository에서 쓰려면 저장 위치, retention, export, deletion, secret masking 정책을 확인해야 합니다.
둘째, custom provider를 붙였을 때 reasoning trace와 tool output이 어디까지 외부 API로 나가는지입니다. MiMo Code는 mainstream LLM provider API 연결을 지원한다고 설명하지만, 각 provider의 data retention과 enterprise policy는 다릅니다. 셋째, Goal verifier와 Max Mode 비용입니다. 독립 judge와 N=5 병렬 후보는 안정성을 올릴 수 있지만, latency와 token bill도 함께 올립니다. 장기 작업에서 성공률과 비용을 같이 계측하지 않으면 "더 똑똑한 에이전트"가 아니라 "더 오래 비싼 에이전트"가 될 수 있습니다.
Xiaomi가 보여준 것은 모델보다 운영체제에 가깝습니다
MiMo Code는 Xiaomi라는 이름 때문에 의외성이 큽니다. 하지만 기술적으로 보면 휴대폰 회사의 곁가지보다, 중국 AI 팀들이 open model과 agent runtime을 함께 밀어붙이는 흐름의 한 사례입니다. 같은 HN 첫 페이지에는 Moonshot의 Kimi K2.7-Code도 올라왔습니다. Kimi는 coding-focused agentic model의 token efficiency를 이야기하고, MiMo Code는 그 모델을 긴 작업에서 버티게 하는 memory와 workflow를 이야기합니다. 모델과 runtime이 동시에 공개 경쟁에 들어간 셈입니다.
devlery 독자에게 더 직접적인 포인트는 "장기 실행 에이전트의 제품 표준"입니다. 앞으로 코딩 에이전트를 비교할 때 단순히 SWE-Bench 점수만 보기는 어렵습니다. checkpoint를 언제 쓰는지, memory가 파일로 보이는지, verifier가 독립적인지, workflow가 code로 실행되는지, 실패 후 복구가 가능한지, 반복 작업을 skill로 distill하는지까지 봐야 합니다. MiMo Code의 공식 수치가 모두 재현되더라도, 또는 일부만 재현되더라도, 이번 발표는 그 비교표의 항목을 구체화했습니다.
Xiaomi의 주장이 시장 표준이 될지는 아직 모릅니다. 하지만 2026년 6월 10일 MiMo Code 발표는 코딩 에이전트가 IDE 자동완성의 후계자가 아니라, memory file, checkpoint writer, judge, workflow runtime, history store를 가진 개발 작업 운영체제로 진화하고 있음을 보여주는 사례입니다. 200 step을 넘는 작업에서 모델이 똑똑한지보다 먼저 물어야 할 질문은 이것입니다. 그 에이전트는 방금 무엇을 했는지, 왜 했는지, 다음에 무엇을 해야 하는지, 그리고 끝났다는 증거가 어디 있는지 스스로 복구할 수 있습니까.