RTX Spark 공개, 120B LLM용 로컬 AI PC
NVIDIA와 Microsoft가 RTX Spark를 공개했습니다. 120B LLM, 128GB unified memory, OpenShell로 로컬 에이전트 PC를 겨냥합니다.

- 무슨 일: NVIDIA와 Microsoft가 RTX Spark 기반 Windows PC 범주를 공개했습니다.
- 발표일은 2026년 5월 31일이며, 제품 출시는 ASUS, Dell, HP, Lenovo, Surface, MSI를 통해 가을로 예고됐습니다.
- 핵심 숫자:
1PFLOP FP4,128GB unified memory,120BLLM, 최대100만 tokencontext가 전면에 나왔습니다. - 의미: 로컬 AI 에이전트 경쟁이 모델 API에서 PC 사양표와 OS 보안 runtime으로 내려왔습니다.
- 주의점: 가격, 발열, Windows on Arm 앱 호환성, 실제 agent 보안 경계는 출시 후 검증이 필요합니다.
NVIDIA와 Microsoft가 2026년 5월 31일 GTC Taipei at COMPUTEX에서 RTX Spark를 공개했습니다. NVIDIA Newsroom은 이를 "personal agents"를 위해 설계된 Windows PC 범주라고 설명했습니다. 발표 문구는 게임용 GPU나 creator laptop에 머물지 않습니다. NVIDIA는 1 petaflop FP4 AI performance, 최대 128GB unified memory, Windows 보안 primitive, NVIDIA OpenShell runtime을 묶어 개인 PC에서 에이전트를 실행하는 장치로 내세웠습니다.
이번 발표는 DGX Spark의 축소판이 아닙니다. DGX Spark는 이미 개발자와 연구자를 위한 소형 AI supercomputer로 팔리고 있었습니다. RTX Spark는 그보다 더 넓은 Windows PC 생태계를 겨냥합니다. NVIDIA와 Microsoft의 공동 메시지는 로컬 AI가 NPU의 작은 기능이나 cloud assistant의 화면 호출에 그치지 않고, CUDA와 TensorRT, PyTorch, llama.cpp, vLLM, Hugging Face 도구가 Windows 노트북과 소형 데스크톱 안으로 들어온다는 쪽입니다.

NVIDIA가 제시한 숫자는 공격적입니다. 공식 보도자료는 RTX Spark가 1 petaflop AI performance와 최대 128GB unified memory를 제공하고, 로컬에서 120B-parameter LLM을 agent와 함께 최대 100만 token context로 실행할 수 있다고 적었습니다. 또 90GB 이상 3D scene rendering, 12K 4:2:2 video editing, 4K AI video generation, 1440p AAA gaming 100fps 이상도 같은 bullet에 배치했습니다. 제품군을 AI 개발자 전용 기계로만 두지 않고 creator, gamer, developer를 한 장치 범주에 넣겠다는 의도입니다.
하드웨어 구성은 Grace Blackwell의 PC 버전처럼 읽힙니다. NVIDIA GeForce 발표는 Blackwell RTX GPU가 6144 CUDA cores, fifth-generation Tensor Cores, FP4 precision을 제공한다고 설명했습니다. 이 GPU는 NVLink-C2C chip-to-chip interconnect로 20-core NVIDIA Grace CPU와 연결됩니다. Microsoft의 Windows Experience Blog도 최대 6144 Blackwell RTX cores, Arm architecture 기반 20개 power-efficient cores, 최대 128GB unified memory를 같은 숫자로 확인했습니다.
이 사양표에서 개발자가 먼저 봐야 할 항목은 1PFLOP보다 128GB unified memory입니다. 로컬 LLM은 peak compute보다 memory capacity와 bandwidth에서 막힙니다. 작은 7B, 14B 모델은 고성능 GPU 한 장으로도 실험할 수 있지만, 70B 이상 모델과 긴 context, tool trace, vector cache, image/video workload가 섞이면 VRAM 24GB나 32GB는 빠르게 모자랍니다. NVIDIA는 RTX Spark를 "PC가 앱을 실행하는 기계에서 agent가 작업을 수행하는 기계로 이동한다"는 서사에 맞췄고, 그 서사의 기술적 근거를 unified memory로 둔 셈입니다.
다만 unified memory는 만능 해결책이 아닙니다. DGX Spark 제품 페이지의 참고 사양은 128GB LPDDR5x coherent unified memory, 256-bit memory interface, 273GB/s memory bandwidth, 140W GB10 TDP를 제시합니다. 같은 용량의 메모리를 모델이 쓸 수 있다는 장점은 분명하지만, memory bandwidth는 discrete high-end GPU의 HBM이나 GDDR7 기반 workstation card와 다른 병목을 만듭니다. 로컬 agent가 실사용에서 얼마나 빠른지는 model size, quantization, context length, tool call 빈도, batch size, thermal profile에 따라 갈립니다.
NVIDIA와 Microsoft가 하드웨어 숫자만 말하지 않은 이유도 여기에 있습니다. 로컬 agent는 모델을 올리는 문제만으로 끝나지 않습니다. 파일을 읽고, 화면을 보고, 마우스를 움직이고, 브라우저를 호출하고, local shell command를 실행합니다. primary PC에서 이런 일을 허용하려면 "빠른 GPU"보다 더 까다로운 질문이 따라옵니다. agent가 어떤 앱에 접근할 수 있는지, 파일 시스템 write가 어디까지 허용되는지, 사용자가 승인한 action과 자동 action을 어떻게 나누는지, network request와 credential access를 어떻게 제한하는지가 모두 제품 기능이 됩니다.
NVIDIA의 답은 OpenShell runtime과 Microsoft security primitives입니다. NVIDIA 블로그는 OpenShell이 Windows에 오고, Hermes Agent와 OpenClaw가 새 Windows 앱에서 OpenShell과 Microsoft 보안 primitive를 통합한다고 설명했습니다. 같은 글은 NemoClaw blueprint가 GeForce RTX, RTX PRO, RTX, DGX Spark, DGX Station까지 확장되고, Hermes Agent 지원과 streamlined installer가 추가된다고 적었습니다. 로컬 agent를 "개인 PC 위의 위험한 자동화"가 아니라 "OS가 감시하는 runtime"으로 포장하는 구조입니다.
이 대목은 코딩 에이전트 사용자에게 바로 연결됩니다. Claude Code, Codex, Cursor, Copilot CLI, ComfyUI 같은 도구는 이미 개발자의 로컬 환경과 cloud devbox 사이를 오가고 있습니다. Microsoft 블로그는 GitHub Copilot, Claude Code, ComfyUI, Cursor가 현대 PC silicon 전반에서 동작한다고 썼습니다. RTX Spark 쪽에는 CUDA-accelerated PyTorch, llama.cpp, TensorRT, Hugging Face frameworks, Unsloth, Kohya 같은 개발 기술을 더 가져올 계획이라고 밝혔습니다. 에이전트가 prompt 창을 넘어 local runtime이 되면, OS vendor와 GPU vendor가 통제점을 나눠 갖습니다.
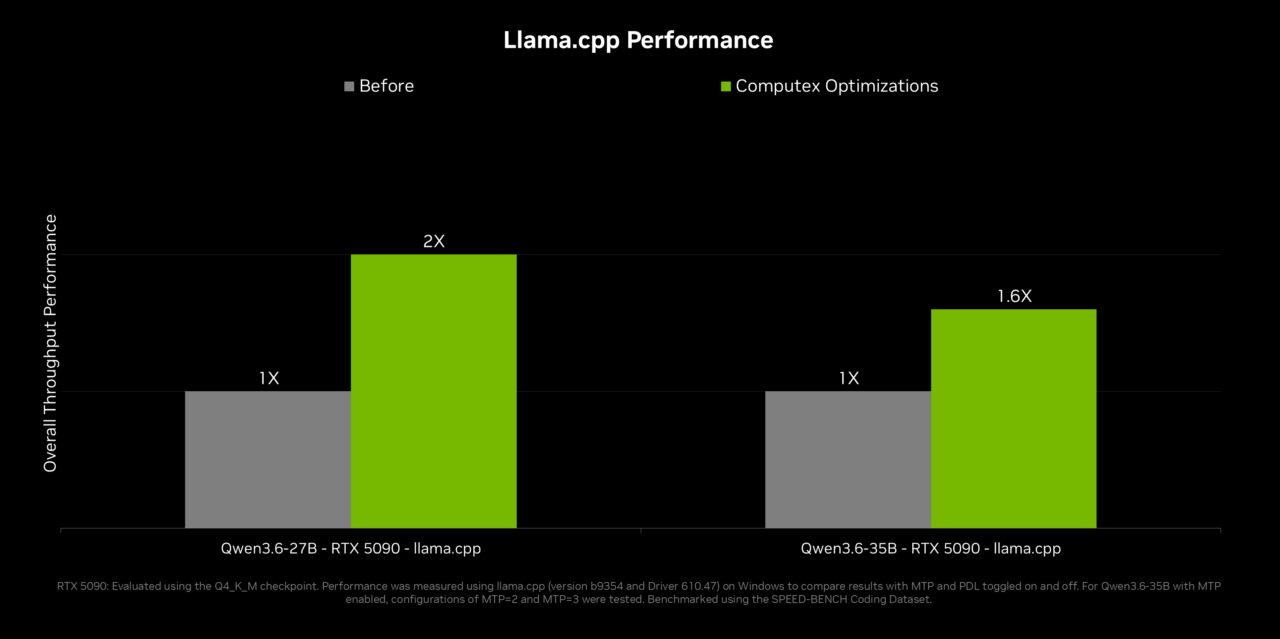
성능 발표도 agent runtime에 맞춰 배치됐습니다. NVIDIA 블로그는 llama.cpp와 vLLM의 multi-token prediction, llama.cpp와 ComfyUI의 multi-GPU optimization을 통해 top agentic models에서 2배 inference performance를 언급했습니다. 이 주장은 "RTX Spark만의 독점 성능"이라기보다 NVIDIA가 로컬 AI stack 전반을 정비하고 있다는 신호에 가깝습니다. 모델이 한 token씩 느리게 답하면 agent UI는 답답해지고, tool call 사이의 대기 시간이 길어집니다. multi-token prediction과 runtime 최적화는 사용자가 agent를 실제 앱처럼 느끼는 데 필요한 낮은 층입니다.
파트너 목록도 제품의 위치를 말합니다. NVIDIA는 ASUS, Dell, HP, Lenovo, Microsoft Surface, MSI가 2026년 가을 RTX Spark 노트북과 compact desktop을 내고, Acer와 GIGABYTE가 뒤따른다고 밝혔습니다. Microsoft는 Surface Laptop Ultra를 따로 언급했습니다. ASUS ProArt P16/P14, Dell XPS 16 Creator Edition, HP OmniBook Ultra 16과 OmniBook X 14, Lenovo Yoga Pro 9n, MSI Prestige N16 Flip AI+도 예시로 들었습니다. 같은 chip과 runtime이 여러 OEM chassis에 들어가면, 개발자는 "AI PC"를 NPU TOPS 숫자보다 memory, CUDA, agent sandbox, local model 지원으로 비교하게 됩니다.
이 발표가 Apple Silicon과 비교될 수밖에 없는 이유는 명확합니다. MacBook Pro와 Mac Studio는 이미 큰 unified memory와 조용한 local inference 장비로 개발자에게 쓰입니다. MLX와 Ollama, llama.cpp, Apple Neural Engine, Metal 기반 stack은 클라우드 비용을 피하려는 개발자에게 익숙합니다. NVIDIA는 여기에 CUDA와 TensorRT, RTX graphics, Windows 앱 호환성, OEM 다양성으로 맞섭니다. 경쟁의 축은 "로컬에서 모델이 돌아가느냐"가 아니라 "개발자가 쓰는 도구와 agent harness가 얼마나 덜 깨지느냐"로 이동합니다.
Windows on Arm 호환성은 출시 후 확인할 첫 번째 항목입니다. Microsoft 블로그는 MATLAB의 Windows on Arm 공식 지원, Epic Easy Anti-Cheat와 BattlEye, Xbox PC app, Prism emulator compatibility, League of Legends와 VALORANT, PUBG 등 게임 생태계를 함께 언급했습니다. 이 목록은 AI 개발자에게도 중요합니다. agent가 테스트해야 하는 앱, 브라우저, IDE extension, command-line tool, package manager가 Arm Windows에서 안정적으로 돌아가야 local automation이 실제 개발 workflow가 됩니다.
두 번째 항목은 가격입니다. NVIDIA의 공식 보도자료는 partner availability와 fall timing을 말했지만, RTX Spark 노트북과 데스크톱의 소비자 가격은 모델별로 갈립니다. DGX Spark를 두고 Hacker News와 Reddit에서 반복된 논점도 여기였습니다. 128GB unified memory와 CUDA stack은 매력적이지만, high-end RTX desktop, Mac Studio, cloud GPU devbox, company-provided remote environment와 비교한 총비용이 맞아야 합니다. 개인 개발자가 살 장비인지, 회사가 지급할 workstation인지, creator premium laptop인지가 가격에서 갈립니다.
세 번째 항목은 보안 경계입니다. OpenShell이라는 이름은 agent에게 안전한 shell을 주겠다는 메시지를 담고 있지만, 실제 보안은 runtime 이름보다 정책과 기본값에서 결정됩니다. agent가 package install을 실행할 때, browser credential에 접근할 때, local source tree 밖 파일을 읽을 때, camera나 microphone을 쓰려 할 때, Windows와 NVIDIA runtime이 어떤 prompt와 audit log를 제공하는지가 중요합니다. Microsoft가 말한 "new security primitives"가 developer preview 수준인지, enterprise policy와 연결되는지도 봐야 합니다.
커뮤니티 반응은 이미 회의와 기대가 섞여 있습니다. GeekNews 최신 글에서는 Claw Patrol, CodeBoarding, React Doctor, Decepticon처럼 에이전트 보안과 코드 검증 도구가 같이 올라왔습니다. 로컬 AI PC 발표가 독립 뉴스라기보다 "에이전트에게 production 권한을 줄 수 있는가"라는 질문과 함께 소비된다는 뜻입니다. HN의 DGX Spark 토론에서는 FP4 peak 성능 표기, memory bandwidth, price/performance, 배송 지연, CUDA 호환성 이야기가 길게 이어졌습니다. RTX Spark도 같은 검증 목록을 피하지 못합니다.
개발팀 입장에서 RTX Spark의 직접 효과는 세 갈래입니다. 첫째, prototype이 더 로컬로 내려옵니다. 민감한 코드와 데이터를 cloud agent에 올리기 어려운 팀은 70B 또는 120B급 모델의 quantized local run, retrieval index, UI automation, image/video generation을 한 장비에서 테스트할 수 있습니다. 둘째, agent evaluation이 사내 PC lab으로 내려올 수 있습니다. 같은 prompt를 여러 local model과 runtime에서 반복하고, tool permission과 latency를 측정하는 일이 가능해집니다. 셋째, 비용 모델이 바뀝니다. 매번 cloud token과 GPU minute을 쓰는 대신 고가 장비를 amortize하는 선택지가 생깁니다.
그 선택지는 모든 팀에 맞지 않습니다. 이미 cloud dev environment와 managed agent를 쓰는 팀은 local RTX Spark보다 policy, audit, data residency, CI integration이 더 중요할 수 있습니다. 모바일 앱이나 web SaaS 개발팀은 120B local LLM보다 빠른 browser automation과 test runner, GitHub/GitLab 권한 연결을 더 자주 필요로 합니다. 반대로 media generation, CAD/3D, robotics simulation, privacy-heavy enterprise prototype을 다루는 팀은 GPU와 unified memory, local security runtime을 한 장치에서 받는 편이 유리할 수 있습니다.
RTX Spark 발표에서 가장 구체적인 변화는 "AI PC"의 비교 기준이 바뀐다는 점입니다. 2024년과 2025년의 AI PC는 NPU TOPS와 Copilot key로 설명되는 경우가 많았습니다. 2026년의 NVIDIA식 AI PC는 agent가 로컬 파일, 앱, shell, model runtime을 다루는지로 설명됩니다. 이 차이는 제품 문구보다 구매 기준에 가깝습니다. 개발자는 이제 NPU 숫자만 보지 않고, unified memory 용량, CUDA/TensorRT 지원, local LLM runtime, sandbox 정책, audit log, OEM thermal design을 함께 봐야 합니다.
NVIDIA와 Microsoft의 이해관계도 분명합니다. NVIDIA는 CUDA와 RTX 생태계를 cloud GPU에서 개인 장치까지 늘리고 싶습니다. Microsoft는 Windows를 local agent의 기본 실행 표면으로 만들고 싶습니다. 둘의 발표가 맞물린 지점은 "개인 PC가 다시 developer infrastructure가 될 수 있다"는 주장입니다. 클라우드 모델 API가 강해질수록, 로컬 PC는 단순 client로 밀려날 수 있었습니다. RTX Spark는 반대로 PC를 model execution, agent permission, creative rendering, game runtime이 모이는 장치로 다시 세웁니다.
가을 출시 전까지 남은 질문은 제품 시연보다 실측입니다. 120B LLM이 어떤 quantization과 latency로 도는지, 100만 token context에서 메모리와 응답 속도가 어떻게 흔들리는지, OpenShell이 실제로 어떤 API와 정책을 제공하는지, Windows on Arm에서 개발 도구가 얼마나 덜 깨지는지 확인해야 합니다. NVIDIA는 사양표와 파트너를 공개했고, Microsoft는 OS 생태계의 문을 열었습니다. 개발자에게 필요한 다음 자료는 benchmark 영상보다 reproducible repo, driver version, runtime policy, 가격표입니다.
RTX Spark가 성공하면 로컬 에이전트는 취미용 LLM launcher를 넘어 PC 구매 사양의 일부가 됩니다. 실패하면 강한 숫자를 가진 niche workstation으로 남을 수 있습니다. 발표만 놓고 보면 NVIDIA는 후자를 피하려고 Windows, Surface, OEM, Adobe, Blender, llama.cpp, vLLM, OpenShell을 한 번에 묶었습니다. 이 묶음이 실제 개발 workflow에서 통과해야 할 시험은 단순합니다. 에이전트가 빠르게 돌고, 사용자가 통제하고, 기존 앱이 깨지지 않고, cloud bill보다 납득 가능한 비용을 보여줘야 합니다.