AI
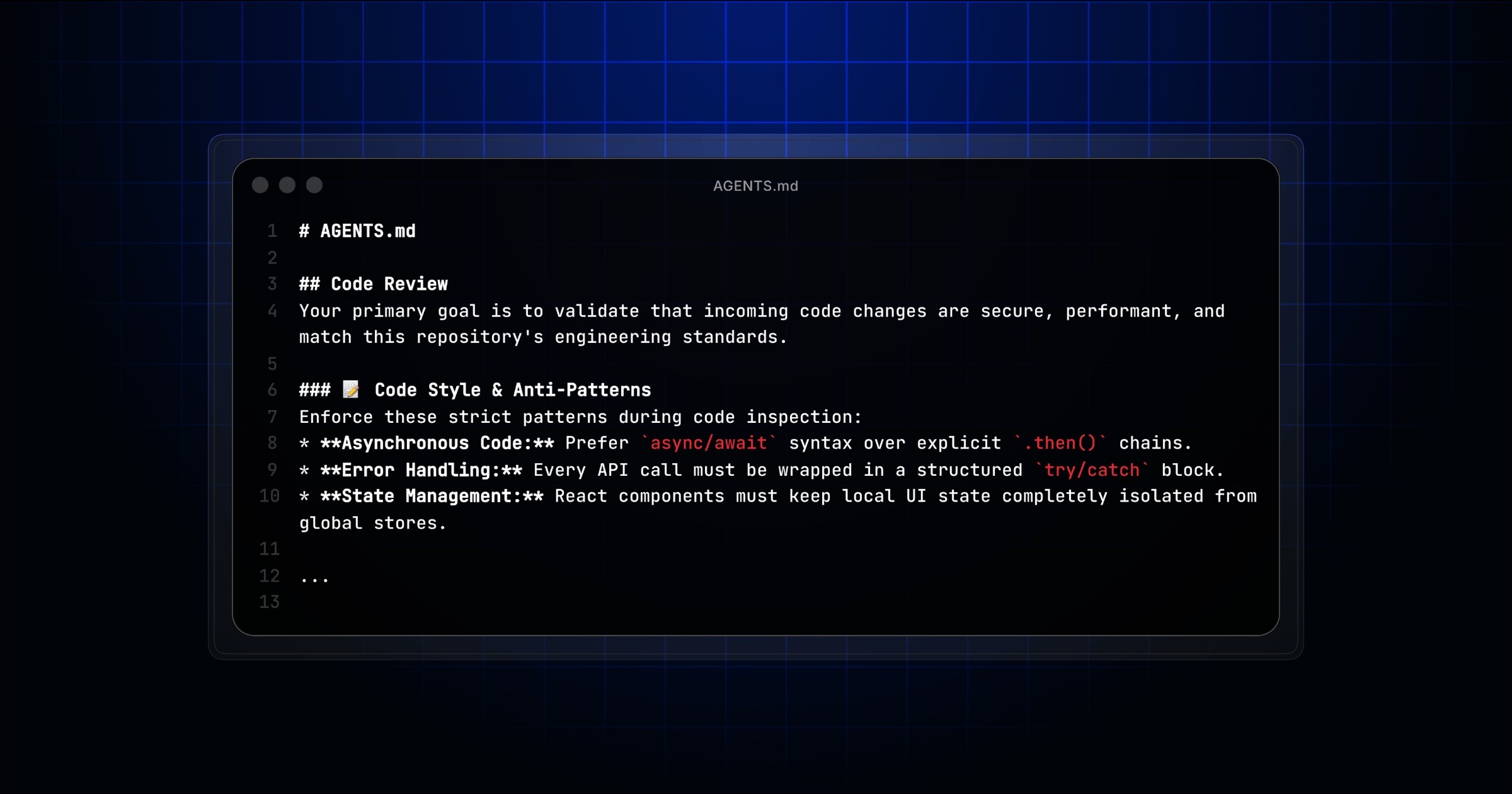
Copilot 코드 리뷰가 AGENTS.md를 읽는다, PR 지시문의 새 기준
GitHub가 Copilot code review에 루트 AGENTS.md 지원을 추가했습니다. PR 리뷰 에이전트가 저장소 지시문을 읽을 때의 실무 경계를 짚습니다.
AI
GitHub가 Copilot code review에 루트 AGENTS.md 지원을 추가했습니다. PR 리뷰 에이전트가 저장소 지시문을 읽을 때의 실무 경계를 짚습니다.

AI
Google ARD는 MCP 서버, 스킬, A2A 에이전트를 실행 시점에 찾고 검증하는 공개 명세입니다. 에이전트 도구 검색의 병목을 짚습니다.
AI
Google DeepMind가 내부 AI 에이전트를 잠재적 내부자 위협처럼 감시하고 차단하는 AI Control Roadmap을 공개했습니다.

AI
Chrome DevTools for agents가 서드파티 개발자 도구를 도입해 프레임워크 내부 상태와 컴포넌트 계층을 MCP로 노출합니다.

AI
OpenAI가 실제 대화를 재생해 새 모델의 원치 않는 행동 빈도를 출시 전에 예측하는 Deployment Simulation 연구를 공개했습니다.

AI
GitHub가 Models 신규 사용을 막고 Code Quality를 7월 20일 유료화합니다. AI 코드 품질 기능의 접근권과 과금 단위를 정리합니다.

AI
Google DeepMind와 파트너들이 다중 에이전트 안전 연구에 1000만 달러를 배정했습니다. 단일 모델 평가 밖의 위험을 봅니다.
AI
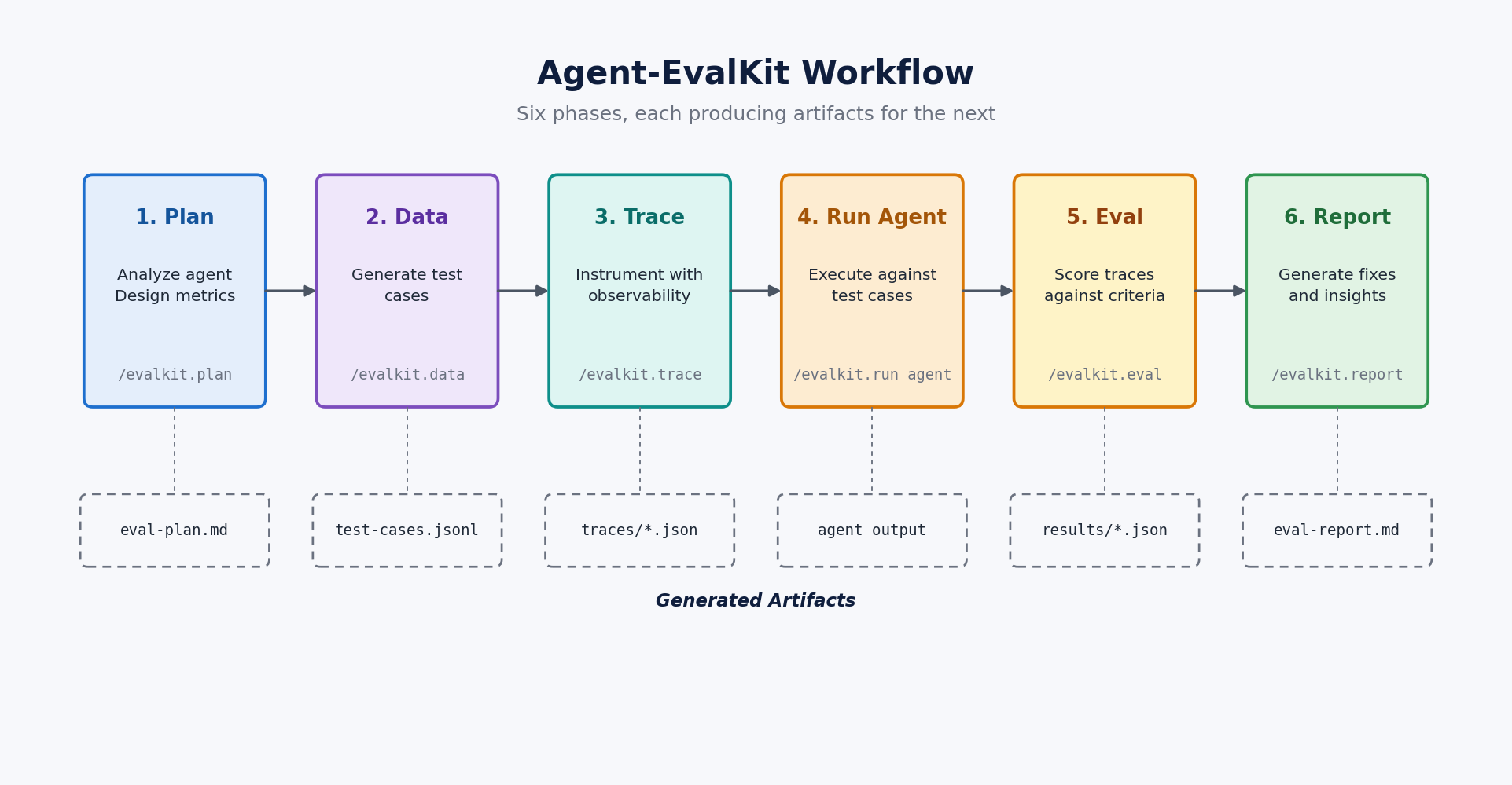
AWS Agent-EvalKit은 최종 답변이 아니라 도구 호출, trace, faithfulness, CI 품질 게이트로 에이전트 평가를 재구성합니다.

AI
Arcade.dev가 6000만 달러 Series A를 유치했습니다. 모델보다 에이전트 권한, 감사, 실행 통제가 투자 대상으로 떠오릅니다.
AI
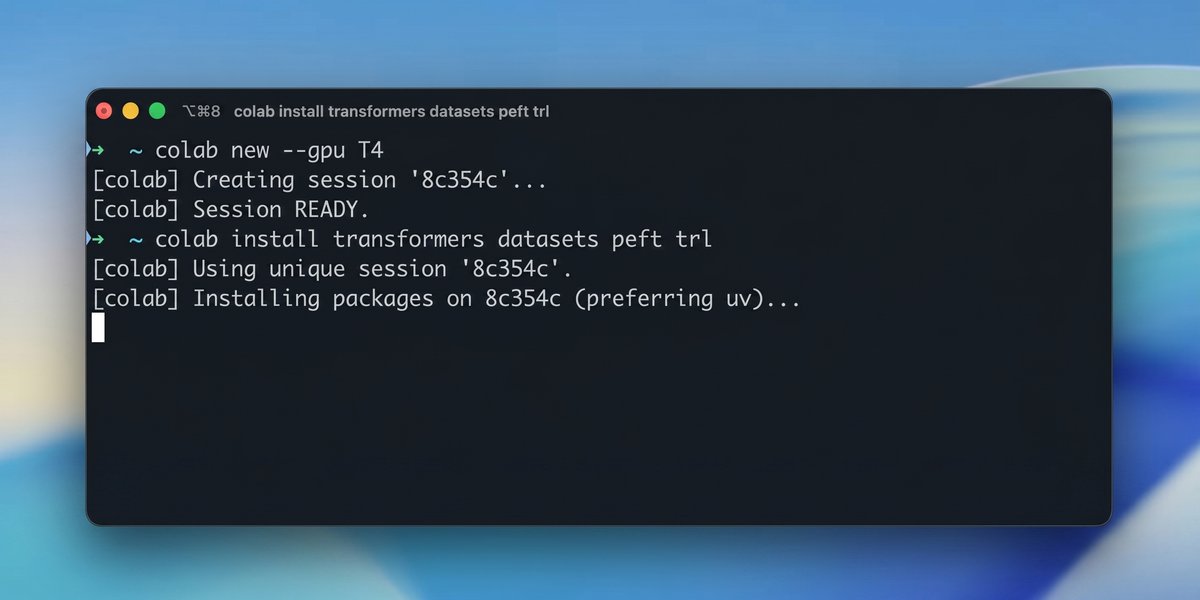
Google Colab CLI가 공개됐습니다. Codex·Claude Code 같은 터미널 에이전트가 원격 GPU/TPU 작업을 직접 실행하는 조건을 봅니다.

AI
Anthropic Fable 5와 Mythos 5가 미국 수출통제 지시로 중단됐습니다. GitHub Copilot까지 멈춘 사건의 개발자 영향을 봅니다.

AI
OpenAI가 파트너 네트워크와 1억5000만 달러 투자를 발표했습니다. Codex·agent 전문화가 기업 AI 배포 기준을 바꿉니다.