Google ARD 공개, 에이전트 도구 검색의 새 표준
Google ARD는 MCP 서버, 스킬, A2A 에이전트를 실행 시점에 찾고 검증하는 공개 명세입니다. 에이전트 도구 검색의 병목을 짚습니다.

- 무슨 일: Google이 6월 17일
Agentic Resource Discovery를 공개했습니다.- MCP 서버, A2A 에이전트, 스킬, API를
ai-catalog.json으로 공개하고 레지스트리가 검색하게 하는 초안 명세입니다.
- MCP 서버, A2A 에이전트, 스킬, API를
- 의미: 에이전트가 미리 연결된 도구만 쓰는 구조에서 실행 시점 검색과 검증으로 이동합니다.
- 주의점: 호출 프로토콜을 대체하지 않으며, 검색 순위와 신뢰 검증은 새 공격 표면이 될 수 있습니다.
Google이 에이전트 생태계의 다음 병목을 "도구를 어떻게 부르나"가 아니라 "도구를 어떻게 찾고 믿나"로 옮겼습니다. Google Developers Blog는 2026년 6월 17일 ARD를 발표했습니다. 정식 이름은 Agentic Resource Discovery입니다. ARD는 MCP 서버, A2A 에이전트, 스킬, OpenAPI 도구, 사내 워크플로를 한 프로토콜로 다시 만들겠다는 제안이 아닙니다. 각 기능을 웹에 공개하고, 검색하고, 게시자 신원을 확인한 뒤, 원래 프로토콜로 연결하게 하는 발견 계층입니다.
발표문이 든 예시는 운영 에이전트입니다. 장애를 조사하는 에이전트가 관측성 시스템을 조회하고, 엔지니어링 문서를 찾고, 배포 이력을 확인하고, 지원 티켓을 열고, 전문 문제 해결 에이전트에 물어야 한다고 가정합니다. 지금도 각 플랫폼에는 자체 레지스트리가 있지만, Google은 이 레지스트리들이 특정 생태계 안에 갇혀 있다고 봅니다. ARD의 주장은 단순합니다. 에이전트가 조직과 플랫폼 경계 밖의 기능을 찾으려면, 검색 가능한 카탈로그와 검증 가능한 신원 정보가 필요합니다.
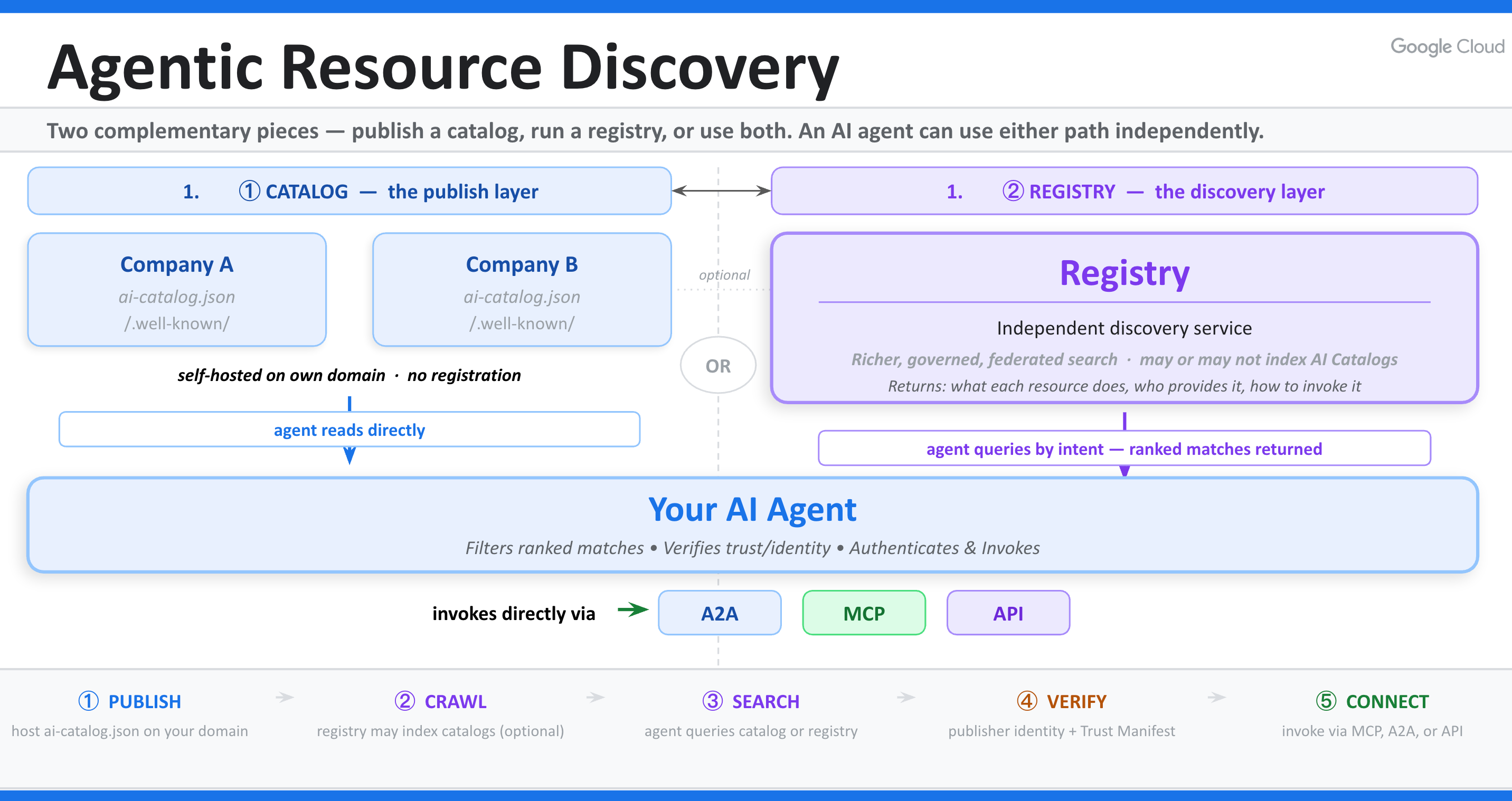
ARD가 요구하는 첫 번째 파일은 ai-catalog.json입니다. AI Catalog Standard는 게시자가 정적 JSON 매니페스트를 올리는 방식을 제시합니다. 표준 위치는 https://<publisher-domain>/.well-known/ai-catalog.json입니다. 루트에는 specVersion, host, entries, collections가 들어갑니다. 각 항목은 identifier, displayName, type, url, description 같은 필드를 갖습니다. 예시 항목은 OCR MCP 서버처럼 특정 기능의 URN, 표시 이름, 미디어 타입, 호출 URL, 설명을 담습니다.
이 설계에서 카탈로그는 앱스토어 등록 양식이 아니라 웹에 놓인 발견 문서에 가깝습니다. 게시 가이드도 공개 인터넷에 카탈로그를 올린다고 해서 특정 레지스트리가 반드시 색인한다는 뜻은 아니라고 적습니다. 기업 내부에서는 공개 크롤링 대신 내부 레지스트리, 엄선된 목록, 벤더 피드로 수집할 수 있습니다. 그래서 ARD는 중앙 디렉터리 하나를 만들자는 제안보다, 여러 레지스트리가 읽을 수 있는 공통 문서 형식을 만들자는 제안에 가깝습니다.
두 번째 구성 요소는 레지스트리입니다. Google은 레지스트리를 "에이전트형 웹의 검색 엔진"으로 설명합니다. 레지스트리는 공개된 카탈로그를 크롤링하고, 항목을 색인하고, 에이전트가 보낸 검색 요청에 맞는 기능을 돌려줍니다. Hugging Face는 같은 날 ARD 소개 글에서 이 문제를 더 실무적으로 풀었습니다. 지금의 에이전트 기능 사용 방식은 "먼저 설치하고 나중에 쓰는" 구조입니다. 개발자가 MCP 서버 URL을 설정 파일에 넣고, 사용자가 플러그인을 연결하고, 에이전트는 이미 연결된 도구만 봅니다. 이 방식은 매일 쓰는 몇 개 도구에는 맞지만, 수천 개 임시 기능으로 커지면 작동하지 않습니다.
Hugging Face가 지적한 대안도 한계가 있습니다. 모든 도구 설명을 LLM 컨텍스트에 넣고 모델에게 고르게 하면 컨텍스트 예산을 소모합니다. 설명이 짧으면 모델이 기능을 구분하기 어렵고, 설명을 길게 넣으면 더 비싸집니다. ARD는 이 선택을 모델 내부가 아니라 레지스트리 검색으로 빼냅니다. 레지스트리가 게시자 신원, 대표 질의, 컴플라이언스 증명, 태그 같은 신호를 들고 검색 결과를 만들고, 에이전트는 필요한 결과만 읽습니다.
| 층위 | 담당 문제 | 실무 질문 |
|---|---|---|
| ARD | 기능을 게시, 검색, 검증합니다. | 이 작업에 쓸 수 있는 신뢰 가능한 도구가 어디 있나? |
| MCP | 에이전트가 도구와 데이터를 호출합니다. | 찾은 서버의 도구를 어떤 규약으로 실행하나? |
| A2A | 에이전트가 다른 에이전트에 작업을 위임합니다. | 전문 에이전트와 어떤 메시지 형식으로 협업하나? |
| OpenAPI | 기존 HTTP API를 구조화해 호출합니다. | 일반 백엔드 기능을 어떤 엔드포인트로 부르나? |
여기서 ARD를 "MCP 대체재"로 읽으면 핵심을 놓칩니다. Google 발표는 ARD가 신뢰 메타데이터를 넘긴 뒤 물러난다고 설명합니다. 에이전트는 선택한 기능과 직접 연결하고, 그 기능의 네이티브 프로토콜이나 API로 상호작용합니다. ARD가 하는 일은 연결 전 단계입니다. 어떤 기능이 있고, 누가 게시했으며, 어떤 방식으로 검증하고, 어느 URL로 가야 하는지를 알려줍니다.
명세 쪽을 보면 아직 초안이라는 사실도 중요합니다. ARD Specification은 v0.9, 상태는 Proposal, 날짜는 2026년 5월 28일로 표시됩니다. 문서는 LLM이 외부 기능에 의존할수록 MCP 도구, A2A 에이전트, 스킬, 호출 가능한 서비스를 통틀어 agentic resources라고 부르겠다고 정의합니다. 또한 이 버전은 ai-catalog 데이터 모델과 맞추고, 발견 인터페이스에는 표준 웹 프로토콜인 REST를 쓰는 방향으로 정리됐다고 설명합니다.
신뢰 모델은 발표에서 가장 민감한 부분입니다. Google은 게시자가 자기 도메인 아래에 카탈로그를 호스팅하기 때문에 도메인 소유권이 신원과 신뢰의 암호학적 기반이 된다고 말합니다. 카탈로그 항목에는 복잡한 보안·컴플라이언스 데이터를 가볍게 분리하기 위한 trustManifest가 붙을 수 있습니다. Google Cloud 쪽 설명은 Gemini Enterprise Agent Platform의 Agent Registry가 글로벌 네임스페이스 URN, 에이전트형 이그레스 정책, 도구와 명세 고정, Agent Identity 기반 trust manifest 검증을 맡을 수 있다고 적었습니다.
이 대목은 플랫폼팀에게 바로 닿습니다. 에이전트가 검색으로 새 도구를 찾는 순간, 발견은 곧 권한 요청이 됩니다. 사내 에이전트가 "세일즈포스에서 지난달 리드 전환율을 가져오라"는 요청을 받았을 때, 레지스트리는 Salesforce MCP 서버 후보를 보여줄 수 있습니다. 하지만 후보가 진짜 회사 승인 서버인지, 어떤 테넌트 권한을 쓰는지, 고객 데이터에 닿는지, 결과가 감사를 남기는지 확인하지 못하면 검색은 생산성 기능이 아니라 데이터 유출 경로가 됩니다.
Microsoft의 참여는 ARD가 Google 단독 제안이 아니라는 점을 보여줍니다. Microsoft Command Line 글도 협력사 목록을 공개했습니다. Cisco, Databricks, GitHub, GoDaddy, Google, Hugging Face가 들어갑니다. NVIDIA, Salesforce, ServiceNow, Snowflake도 같은 목록에 있습니다. 같은 글은 GitHub가 ARD 기반 Agent Finder를 출시한다고 설명합니다. Agent Finder는 GitHub Copilot이 특정 작업에 맞는 MCP 서버, 스킬, 도구, 에이전트를 실행 시점에 찾고, 불필요한 리소스로 컨텍스트 창을 부풀리지 않도록 필요한 때만 주입하는 기능으로 소개됐습니다.
![]()
Hugging Face는 참고 구현을 더 구체적으로 제시했습니다. Discover Tool은 Hugging Face Hub의 기존 의미 검색을 Spaces, Agent Skills, MCP 서버에 연결하고, 결과를 ARD 카탈로그 항목으로 변환합니다. 응답 미디어 타입도 세 가지로 나뉩니다. 기본은 application/ai-skill이고, MCP 서버는 application/mcp-server+json, 원시 Space 메타데이터는 application/vnd.huggingface.space+json입니다. 또한 실행 단계가 RUNNING인 Spaces만 결과에 포함한다는 필터도 공개했습니다. 이것은 ARD가 추상 명세에 머물지 않고 실제 공개 허브의 검색과 연결될 수 있음을 보여주는 예입니다.
개발자 입장에서 가장 큰 변화는 설정 파일의 성격입니다. 지금은 에이전트용 설정이 허용된 도구 목록에 가깝습니다. MCP 서버를 추가하고, 스킬 파일을 복사하고, API 키를 넣고, 새 기능을 배포할 때마다 클라이언트를 다시 설정합니다. ARD가 작동하면 설정은 "어디를 검색할지", "어떤 레지스트리를 신뢰할지", "어떤 게시자와 미디어 타입을 허용할지"를 정하는 정책 파일에 가까워집니다. 도구 목록 자체는 레지스트리와 카탈로그에서 최신 상태로 유지됩니다.
이 변화는 컨텍스트 비용에도 연결됩니다. 에이전트가 모든 도구 설명을 한 번에 읽지 않아도 되면, 긴 작업에서 모델 컨텍스트를 업무 정보와 코드, 로그, 사용자 지시에 더 많이 쓸 수 있습니다. 하지만 검색 결과를 잘못 고르면 비용 절감은 곧 실패율 증가로 돌아옵니다. 레지스트리의 순위 품질, 도구 설명의 구체성, 대표 질의의 정확도, 게시자 평판, 사내 허용 목록이 실제 성능을 좌우합니다. 검색 계층이 좋아야 모델이 좋은 도구를 고릅니다.
커뮤니티 반응은 차분한 편입니다. Hacker News 토론은 6월 19일 확인 시 65점과 댓글 15개 수준이었습니다. 한 사용자는 사내에서 위키와 실행 스크립트를 결합해 비슷한 문제를 풀고 있다고 설명했습니다. 다른 사용자는 MCP Resources와 겹치는 부분이 있고, 차이는 검색 가능한 레지스트리와 MCP/A2A 같은 다중 프로토콜 소비에 있는 것 같다고 봤습니다. 더 회의적인 댓글은 이것이 새 약어를 붙인 검색이며, UDDI 같은 과거 웹서비스 발견 시도를 떠올리게 한다고 지적했습니다.
그 회의론은 가볍지 않습니다. 검색 결과에 가치가 생기면 검색 결과를 조작하려는 동기도 생깁니다. 에이전트 도구 검색에서 상위 노출은 단순 트래픽이 아니라 권한 획득과 실행 기회를 뜻합니다. 악성 MCP 서버, 모호한 스킬, 과장된 도구 설명, 비슷한 이름의 사칭 카탈로그가 등장할 수 있습니다. Google이 trust manifest, 도메인 기반 게시, Agent Identity를 강조한 이유도 여기 있습니다. 발견 계층은 편의 기능이 아니라 보안 계층입니다.
기업 도입에서는 공개 웹 크롤링보다 내부 레지스트리가 먼저일 가능성이 큽니다. 금융사나 의료기관이 아무 공개 카탈로그나 에이전트에게 열어주기는 어렵습니다. 대신 승인된 사내 MCP 서버, 데이터셋 조회 도구, 문서 검색 스킬, 장애 대응 에이전트를 내부 ARD 레지스트리에 등록하고, 일부 공개 레지스트리는 읽기 전용 후보로만 붙일 수 있습니다. 이때 중요한 정책은 검색 소스, 게시자 신원, 미디어 타입, 데이터 분류, 실행 전 승인 조건입니다.
ARD가 성공하려면 세 가지가 필요합니다. 첫째, 실제 구현입니다. GitHub Agent Finder와 Hugging Face Discover처럼 사용자가 체감할 수 있는 클라이언트가 늘어야 합니다. 둘째, 품질 신호입니다. 설명과 태그만으로는 유사 도구를 구분하기 어렵습니다. 실행 가능 상태, 최근 업데이트, 권한 범위, 감사 로그 지원, 실패율 같은 신호가 필요합니다. 셋째, 거버넌스입니다. 사내 레지스트리는 검색을 허용하기 전에 누가 게시했고, 어떤 데이터에 닿고, 어떤 로그를 남기며, 어떤 사용자가 실행할 수 있는지 확인해야 합니다.
이번 발표를 과장할 필요는 없습니다. ARD가 나온다고 해서 에이전트가 바로 전 세계 모든 도구를 안전하게 찾는 것은 아닙니다. 명세는 초안이고, 레지스트리 품질과 신뢰 검증은 구현마다 다를 수 있습니다. 공개 검색은 스팸과 사칭을 피해야 하고, 사내 검색은 권한과 감사 기준을 맞춰야 합니다. 그래도 개발자가 봐야 할 방향은 분명합니다. 에이전트 도입의 다음 설정 파일은 "내가 아는 도구 목록"이 아니라 "내 에이전트가 어떤 세계에서 무엇을 찾아도 되는가"를 적는 정책 문서가 될 가능성이 큽니다.
MCP가 에이전트와 도구의 호출 방식을 정리했고, A2A가 에이전트 간 위임 방식을 정리하려 했다면, ARD는 그 앞에서 검색과 검증을 정리하려 합니다. 좋은 에이전트는 모델만으로 만들어지지 않습니다. 어떤 도구가 있는지 찾고, 그 도구가 진짜인지 확인하고, 필요한 순간에만 컨텍스트에 넣고, 실행 뒤 감사할 수 있어야 합니다. Google ARD 발표는 에이전트 생태계가 호출 규약의 경쟁에서 발견과 신뢰의 경쟁으로 넘어가고 있다는 신호입니다.