Agent-EvalKit 공개, 에이전트 환각을 추적하는 6단계 평가
AWS Agent-EvalKit은 최종 답변이 아니라 도구 호출, trace, faithfulness, CI 품질 게이트로 에이전트 평가를 재구성합니다.
- 무슨 일: AWS가 2026년 6월 11일
Agent-EvalKit을 공개하고, 에이전트 평가를 6단계 CLI 워크플로로 묶었습니다.- 설치는
uv tool install evalkit --from git+https://github.com/awslabs/Agent-EvalKit.git명령으로 시작합니다.
- 설치는
- 차이: 최종 답변 채점 대신 계획, 테스트 데이터, trace, 실행, 평가 코드, 리포트를 한 평가 디렉터리에 남깁니다.
- 실무 영향: Claude Code, Kiro CLI, Kilo Code 같은 assistant가 평가 엔진으로 들어오면서 에이전트 테스트가 개발 루프 안으로 이동합니다.
- AWS 예시는
Faithfulness32.3%처럼 답변 품질과 사실 충실도가 갈라지는 지점을 보여줍니다.
- AWS 예시는
AWS가 2026년 6월 11일 Amazon Machine Learning Blog에서 새 에이전트 평가 도구를 소개했습니다. 발표 대상은 Agent-EvalKit입니다. 이름은 평가 도구처럼 보이지만, 이 발표가 다루는 문제는 더 좁고 실무적입니다. 에이전트가 웹 검색, 데이터베이스, 파일 시스템, 사내 API를 오가며 답을 만들 때 최종 문장만 읽어서는 어떤 도구가 실패했는지, 어떤 검증 단계를 건너뛰었는지, 빈 결과를 사실처럼 포장했는지 알기 어렵습니다.
AWS 글은 이 실패 모드를 여행 조사 에이전트 예시로 설명합니다. 에이전트가 웹 검색 도구에서 빈 결과를 받았는데도 통화와 기온 데이터를 실제 조회 결과처럼 답변한 trace가 등장합니다. 겉으로는 그럴듯한 여행 조언이지만, 실행 경로를 보면 근거가 없는 데이터가 들어갔습니다. Agent-EvalKit의 출발점은 이 차이입니다. "답이 자연스러운가"가 아니라 "답이 어떤 실행 증거에서 왔는가"를 평가 대상으로 올립니다.
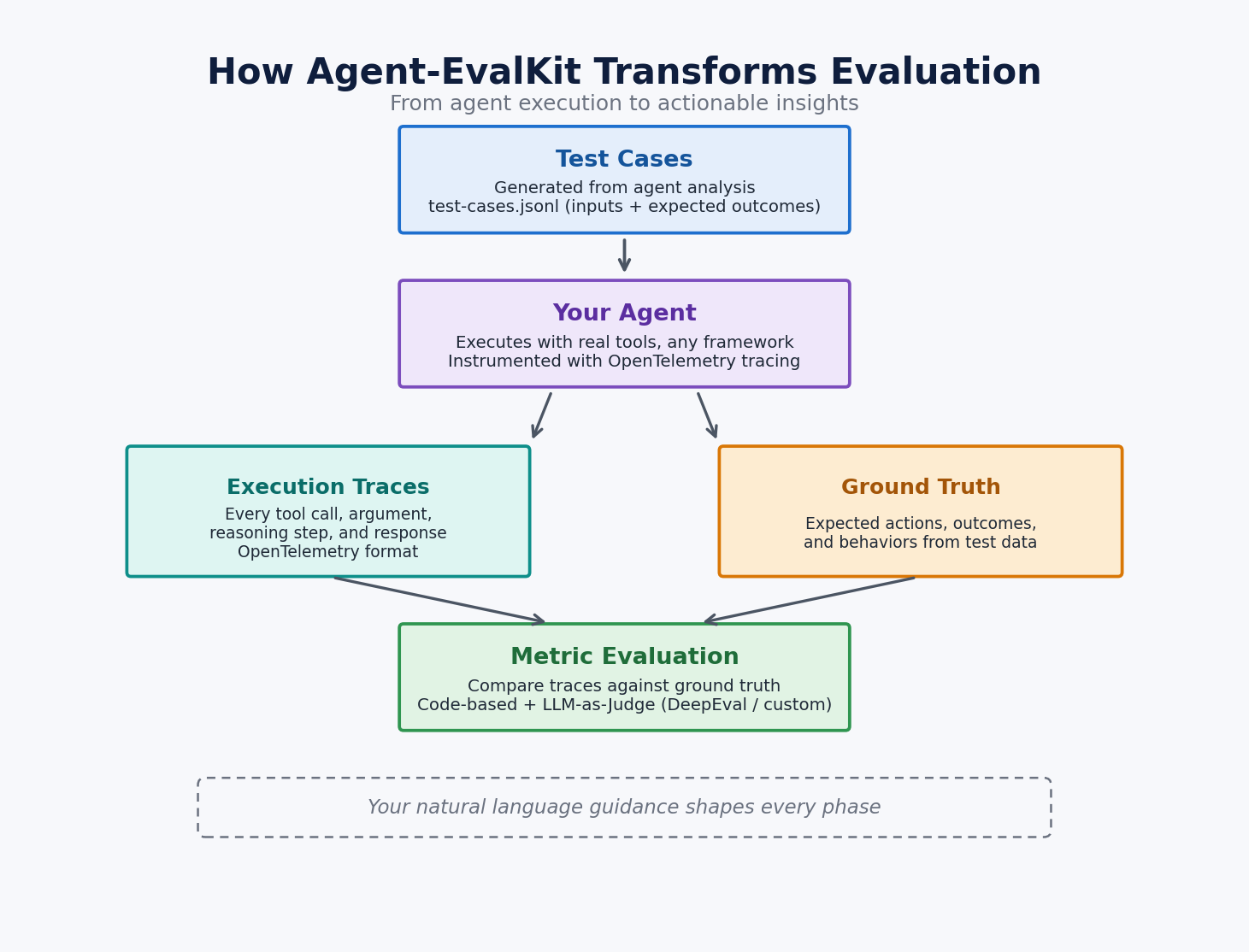
GitHub 저장소의 README는 Agent-EvalKit을 "AI assistant가 에이전트 평가 프로세스를 자동화하는 도구"로 정의합니다. 저장소는 awslabs/Agent-EvalKit 아래 공개되어 있고, GitHub API 기준 Apache-2.0 라이선스입니다. 요구 환경은 Linux 또는 macOS, Python 3.11 이상, uv, Git입니다. AWS 글과 README가 공통으로 적은 지원 assistant는 Claude Code, Kiro CLI, Kilo Code입니다.
설치 경로는 단순합니다. 별도 SaaS 대시보드부터 여는 방식이 아니라, 로컬 개발 환경에서 uv로 CLI를 설치하고 평가 프로젝트를 만듭니다.
uv tool install evalkit --from git+https://github.com/awslabs/Agent-EvalKit.git
evalkit init my-agent-evaluation
cd my-agent-evaluation
cp -r /path/to/your/agent-folder .
claude
이 구조에서 눈에 띄는 지점은 평가 엔진의 위치입니다. Agent-EvalKit은 독립된 평가 플랫폼이 모든 것을 처리한다고 말하지 않습니다. 이미 코드를 읽고 수정하는 AI assistant를 평가 작업에 끌어들입니다. Claude Code를 예로 들면, 개발자는 평가 프로젝트 안에서 assistant를 실행한 뒤 /evalkit.quick 또는 개별 명령을 호출합니다. assistant는 에이전트 코드와 요구사항을 읽고, 테스트 케이스를 만들고, trace를 붙이고, 평가 코드를 작성합니다.
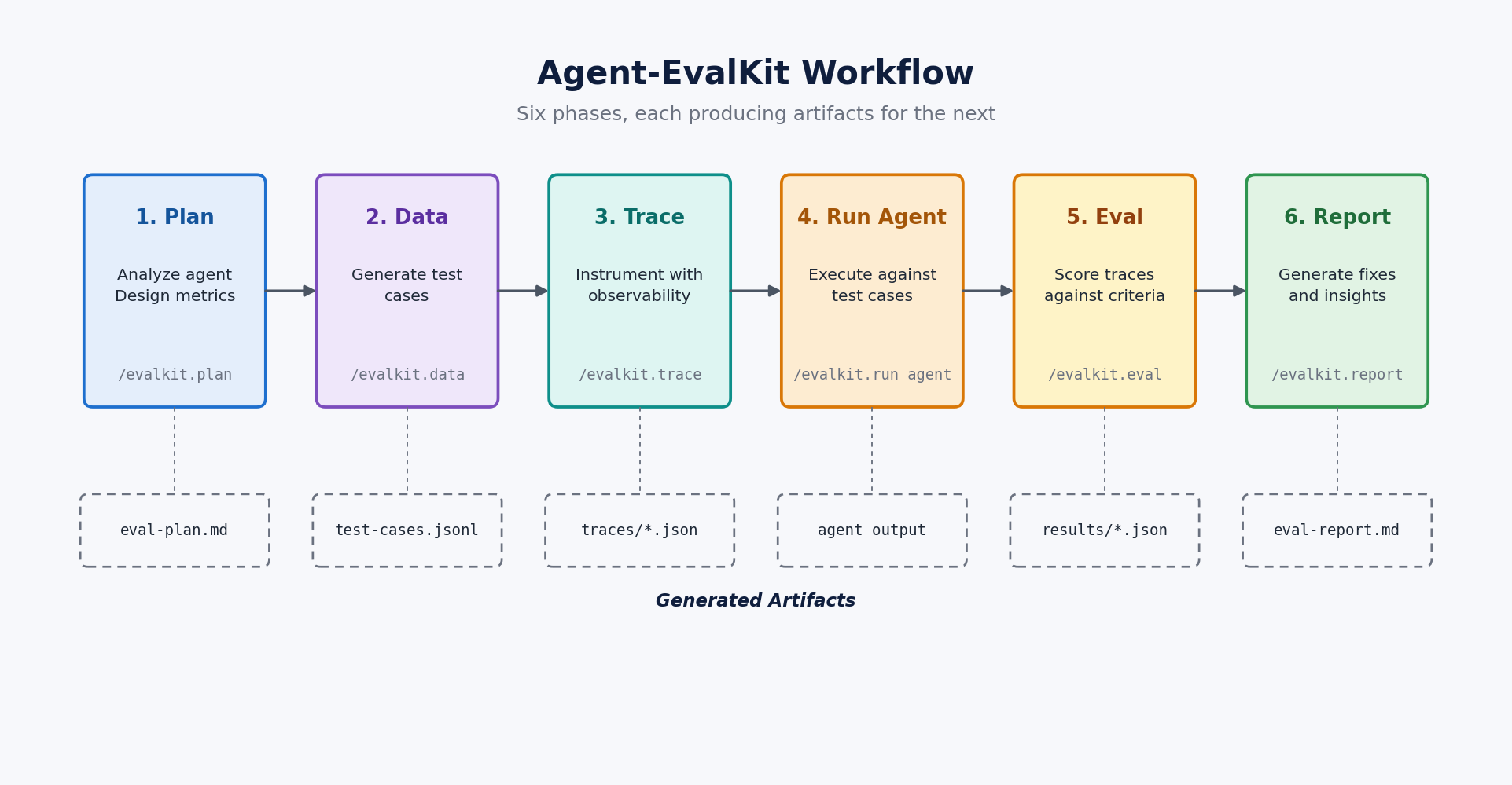
6단계 명령은 평가 과정을 파일과 산출물 단위로 쪼갭니다. /evalkit.plan은 에이전트와 사용자 요구사항을 분석해 평가 전략을 세웁니다. /evalkit.data는 테스트 케이스를 생성합니다. /evalkit.trace는 에이전트에 추적 계측을 추가합니다. /evalkit.run_agent는 에이전트를 실행하고 trace를 모읍니다. /evalkit.eval은 그 trace 위에서 평가 코드를 작성하고 실행합니다. /evalkit.report는 점수와 개선 권고를 리포트로 묶습니다.
AWS 글의 여행 조사 에이전트 예시는 이 6단계를 Strands Agents SDK와 Amazon Bedrock 위에서 보여줍니다. 예시 점수는 Response Quality 83.9%, Tool Parameter Accuracy 64.5%, Faithfulness 32.3%였습니다. 이 수치 조합은 에이전트 평가에서 자주 놓치는 부분을 드러냅니다. 답변 형식과 사용성은 높게 보일 수 있지만, 도구 파라미터 정확도와 근거 충실도는 같은 속도로 올라가지 않습니다.
Agent-EvalKit이 개발자에게 주는 첫 번째 메시지는 "최종 답변 스냅샷 테스트만으로는 부족하다"입니다. 기존 애플리케이션 테스트는 입력과 출력이 비교적 안정적인 함수나 API에 잘 맞습니다. 에이전트는 다릅니다. 같은 사용자 요청에서도 검색 결과, 도구 오류, 권한 상태, 모델 추론 경로가 달라질 수 있습니다. 출력 문자열 하나가 테스트를 통과해도, 내부에서는 검색 실패를 숨기거나 불필요한 도구 호출로 비용을 키울 수 있습니다.
두 번째 메시지는 "평가 대상이 에이전트 코드만이 아니다"입니다. AWS 글의 best practices는 도메인 지식으로 평가 지시를 구체화하고, 생성된 테스트 케이스를 사람이 검토하며, 중요한 변경마다 재평가하라고 권합니다. 이는 LLM-as-judge를 맹신하라는 뜻이 아닙니다. 오히려 자동 평가 프롬프트와 사람의 기준이 어긋나는지 주기적으로 비교하라는 조항이 들어 있습니다. 자동화가 들어오지만, 평가 기준의 소유자는 여전히 팀입니다.
세 번째 메시지는 trace의 운영 가치입니다. AWS는 AgentCore Observability와 AgentCore Evaluation을 함께 언급합니다. 사전 배포 평가만으로는 실제 트래픽에서 생기는 새 실패 모드를 알 수 없으므로, 운영 trace를 품질 지표로 다시 돌리라는 방향입니다. 이는 에이전트를 모델 API 호출 하나로 보지 않고, 배포 후 계속 관측해야 하는 소프트웨어 시스템으로 취급하는 태도에 가깝습니다.
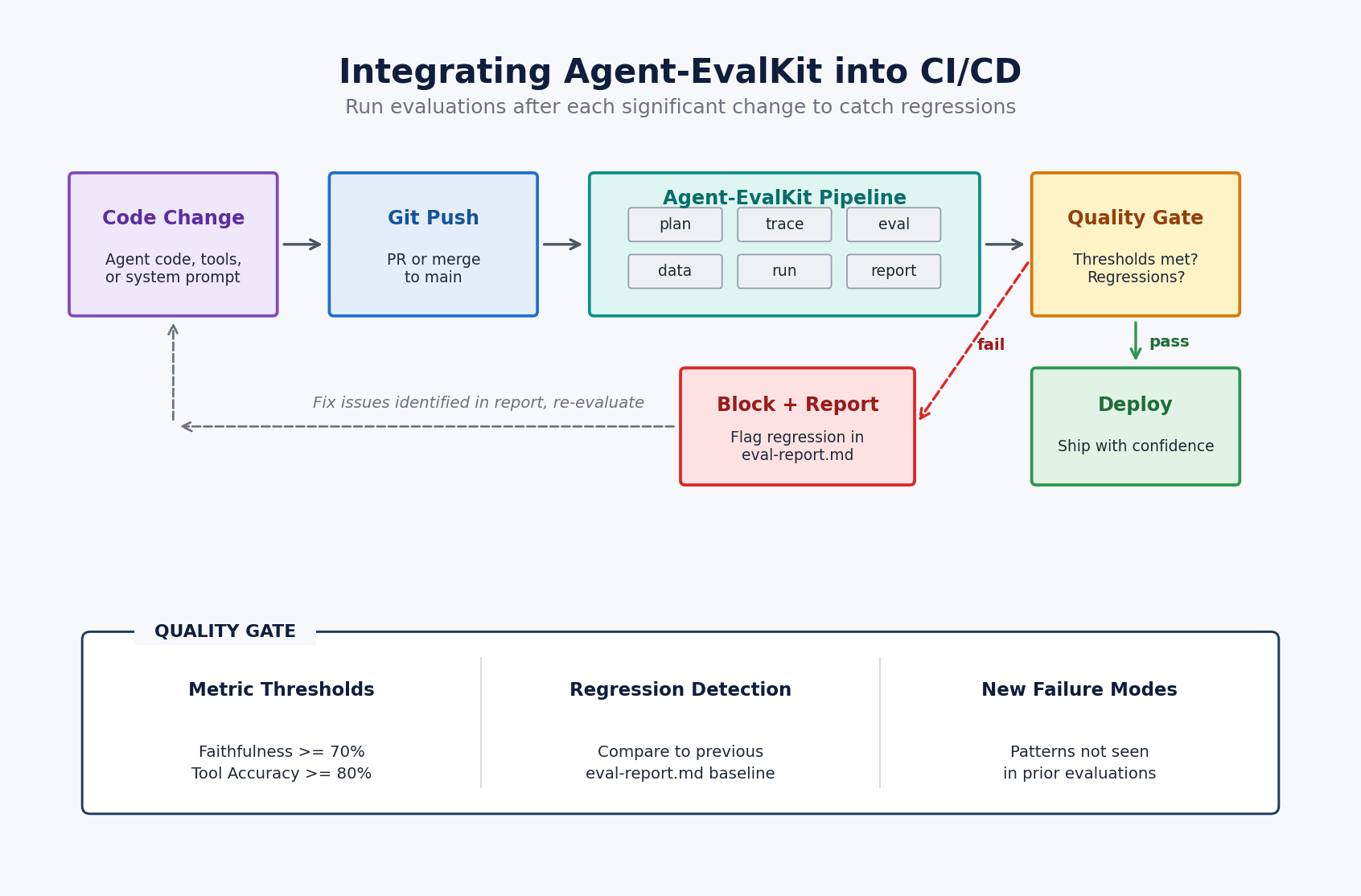
CI/CD 다이어그램은 이 발표의 실무적 목적을 더 직접적으로 보여줍니다. 코드 변경이 평가 실행을 트리거하고, 품질 게이트가 metric threshold와 regression을 확인합니다. 실패하면 평가 리포트가 개발자에게 돌아갑니다. 이 구조에서는 에이전트가 만든 변경도 일반 코드 변경처럼 품질 게이트를 통과해야 합니다. 차이는 단순 lint나 unit test뿐 아니라 도구 사용 정확도, trace 기반 faithfulness, 회귀 지표가 함께 들어온다는 점입니다.
최근 에이전트 제품 경쟁은 실행 위치와 권한 통제에 집중해 왔습니다. Google Colab CLI는 로컬 terminal agent가 원격 GPU/TPU 런타임을 빌릴 수 있게 만들었습니다. Arcade.dev 투자는 모델 밖 action layer와 권한 제어에 자본이 몰린 사례였습니다. GitHub Copilot 코드 리뷰 통제 확대는 PR 에이전트가 언제 실행되고 어느 범위까지 접근하는지 묻는 흐름입니다. Agent-EvalKit은 같은 선 위에서 "실행해도 되는가" 다음 질문인 "실행 결과를 어떻게 증명하는가"를 겨냥합니다.
보조 반응으로 확인한 Buttondown 글도 비슷한 지점을 짚었습니다. 이 글은 GitHub의 bot-created pull request 승인 흐름과 AWS Agent-EvalKit을 함께 묶어, 자동화가 CI에 들어올 때 중요한 문제는 좋은 diff 생성보다 실행 권한과 평가 증거라고 해석했습니다. 이 반응은 대규모 커뮤니티 합의라기보다 한 개발자 뉴스레터의 분석입니다. 다만 에이전트가 코드 작성 도구에서 배포 파이프라인의 참여자로 이동한다는 관찰은 AWS 글의 CI/CD 그림과 잘 맞습니다.
개발팀이 바로 적용할 수 있는 체크포인트는 세 가지입니다. 첫째, 에이전트 평가 기준을 최종 답변 품질, tool parameter accuracy, faithfulness처럼 분리해야 합니다. 둘째, 실패한 trace를 리포트에 남겨 한 줄 권고가 아니라 특정 도구 호출과 특정 코드 경로로 되돌아갈 수 있어야 합니다. 셋째, 평가 데이터셋을 매번 새로 만드는 대신 이전 테스트 케이스와 계측을 재사용해 회귀를 확인해야 합니다.
Agent-EvalKit의 한계도 분명합니다. README는 "빠르게 평가 파이프라인을 생성하고 필요에 맞게 다듬는 도구"라고 설명합니다. 생성된 테스트 코드와 평가 기준을 그대로 제품 보증으로 받아들이면 안 됩니다. AWS 글 역시 생성된 테스트 케이스 검토, 도메인 지식 입력, human annotator와의 비교를 요구합니다. 에이전트 평가를 자동화해도 품질 정의와 위험 허용선은 팀이 직접 정해야 합니다.
또 하나의 제약은 지원 assistant 범위입니다. 현재 문서에 적힌 assistant는 Claude Code, Kiro CLI, Kilo Code입니다. GitHub Copilot, Cursor, OpenAI Codex CLI 같은 도구를 쓰는 팀은 공식 지원 여부와 실제 명령 호환성을 따로 확인해야 합니다. 저장소는 오픈소스지만, AWS 예시의 실행 환경은 Amazon Bedrock과 Strands Agents SDK를 중심으로 구성되어 있습니다. 다른 런타임에 붙일 때는 trace 포맷, 도구 호출 기록, 모델 접근 권한을 맞추는 작업이 남습니다.
그래도 이 발표는 에이전트 평가의 기준점을 유용하게 바꿉니다. "에이전트가 답을 잘 썼는가"에서 "에이전트가 어떤 경로로 답을 만들었고, 그 경로가 다시 실행 가능한가"로 질문을 옮깁니다. AI 개발팀에게는 이 차이가 큽니다. 모델을 교체하거나 prompt를 고치거나 tool schema를 바꾸는 일이 잦을수록, 변경 전후의 실행 경로를 비교할 수 있어야 합니다. Agent-EvalKit은 그 비교를 개발 환경 안에 놓으려는 AWS의 제안입니다.
앞으로 볼 지점은 세 가지입니다. Agent-EvalKit이 실제 팀의 CI에서 얼마나 가벼운 비용으로 반복 실행되는지, LLM-as-judge 점수가 사람 평가와 얼마나 안정적으로 맞는지, 그리고 Claude Code 밖의 주류 코딩 agent들이 같은 6단계 평가 모델을 지원할지입니다. 에이전트가 점점 더 많은 권한을 갖는다면, 평가 도구의 경쟁력은 화려한 데모보다 실패 trace를 얼마나 구체적으로 남기고 회귀를 얼마나 빨리 잡는지에서 갈릴 가능성이 높습니다.