Vera CPU enters production with 88 cores for agent bottlenecks
NVIDIA Vera CPU has entered full production. The launch puts tool calls, sandbox execution, and retrieval on the AI agent infrastructure bill.

- What happened: NVIDIA said at GTC Taipei on May 31, 2026 that its Vera CPU is in full production.
- Vera pairs 88 Olympus cores with up to
1.2TB/sLPDDR5X bandwidth and claims1.8xfaster task completion for agentic workloads.
- Vera pairs 88 Olympus cores with up to
- Why it matters: Tool calls, sandboxed code, search, scheduling, and data processing now sit directly on the AI agent latency path.
- Context: NVIDIA listed Anthropic, OpenAI, SpaceXAI, ByteDance, CoreWeave, Lambda, Nebius, Nscale, and OCI as adopters or evaluators.
- Watch: Public benchmarks focus on agentic sandbox tasks, while production chassis, cloud pricing, regions, and broader workloads still need validation.
NVIDIA said at GTC Taipei on May 31, 2026 that Vera, its new data-center CPU, has entered full production. The official newsroom calls Vera "the first CPU for AI agents" and says it can deliver 1.8x faster task completion than x86 CPUs for agentic AI, reinforcement learning, and data processing workloads. The news is not only that NVIDIA is moving deeper into CPUs. It is that repeated agent execution has become part of the sales case for data-center CPUs.
Vera was first introduced at GTC San Jose in March 2026. At that launch, NVIDIA said the CPU would be 50% faster than traditional rack-scale CPUs while offering twice the efficiency. The May announcement adds supply timing, system partners, and customer names. NVIDIA says Vera will be used in standalone Vera servers, the Vera Rubin system, and the Vera BlueField-4 STX storage platform. Partner systems and cloud partner availability are scheduled to begin in fall 2026.
The adoption list is broad, but the wording matters. NVIDIA names Anthropic, OpenAI, SpaceXAI, ByteDance, CoreWeave, Lambda, Nebius, Nscale, Oracle Cloud Infrastructure, and NYSE as customers or evaluation parties. Dell Technologies, HPE, Lenovo, and Supermicro are listed as major OEMs for standalone CPU server configurations. ASUS, Compal, Foxconn, GIGABYTE, Pegatron, QCT, Wistron, and Wiwynn appear on the manufacturing side. The release mixes language such as "planning to adopt," "exploring," and "evaluating," so it should not be read as proof that every named company already runs Vera in production fleets.

NVIDIA's argument is not limited to model inference. Its technical blog shows a loop where the GPU generates a tool call and the CPU runs a command such as gcc -o hello hello.c ; ./hello, then returns the result to the GPU for the next step. In that flow, the CPU is not just a host processor that prepares prompts or feeds accelerators. It is part of the agent loop that executes tool calls, sandboxed code, data retrieval, data processing, scheduling, and orchestration.
Teams that operate agents will recognize the pattern. A coding agent does not stop after producing a patch. It runs tests, executes lint, reads failing logs, searches files, follows dependency graphs, and edits again. A research agent loops through browser search, PDF parsing, table extraction, database queries, and summarization. An enterprise agent chains approval, policy checks, CRM updates, ticket creation, and document generation. Even if each model call finishes quickly on GPUs, surrounding execution can hold back request latency and concurrency.
Vera's specifications target that surrounding execution layer. NVIDIA says the CPU uses 88 custom Olympus cores, Spatial Multithreading, and an LPDDR5X memory subsystem with up to 1.2TB/s of memory bandwidth. The technical blog says Olympus targets up to 50% higher IPC than NVIDIA Grace. It also lists a neural branch predictor, 10-wide decode unit, deep out-of-order engine, and graph prefetcher for branch-heavy code. Agent runtimes frequently touch Python, JavaScript, graph traversal, database queries, and code compilation, all of which can stress branch prediction and memory access.
Memory power is another repeated part of the pitch. NVIDIA's Vera technical blog says the LPDDR5X subsystem can deliver up to 1.2TB/s of bandwidth with less than 30W of memory power, compared with more than 100W for a common DDR5 configuration. The same post claims Vera can sustain more than 90% of peak memory bandwidth. If an AI factory runs thousands of sandboxes and tool calls at once, memory bandwidth and power budget can matter as much as the raw number of CPU cores.
The 1.8x performance claim is framed around agentic sandboxes. Figure 4 in NVIDIA's technical blog says Vera delivers more than 1.8x the agentic sandbox performance of x86 architecture across workloads including code compilation, code analysis, and Python. The newsroom also cites Phoronix results for code compilation, Python, Java, and database processing. Those are not conventional "AI benchmarks." They are CPU tasks that agents call while doing real work.
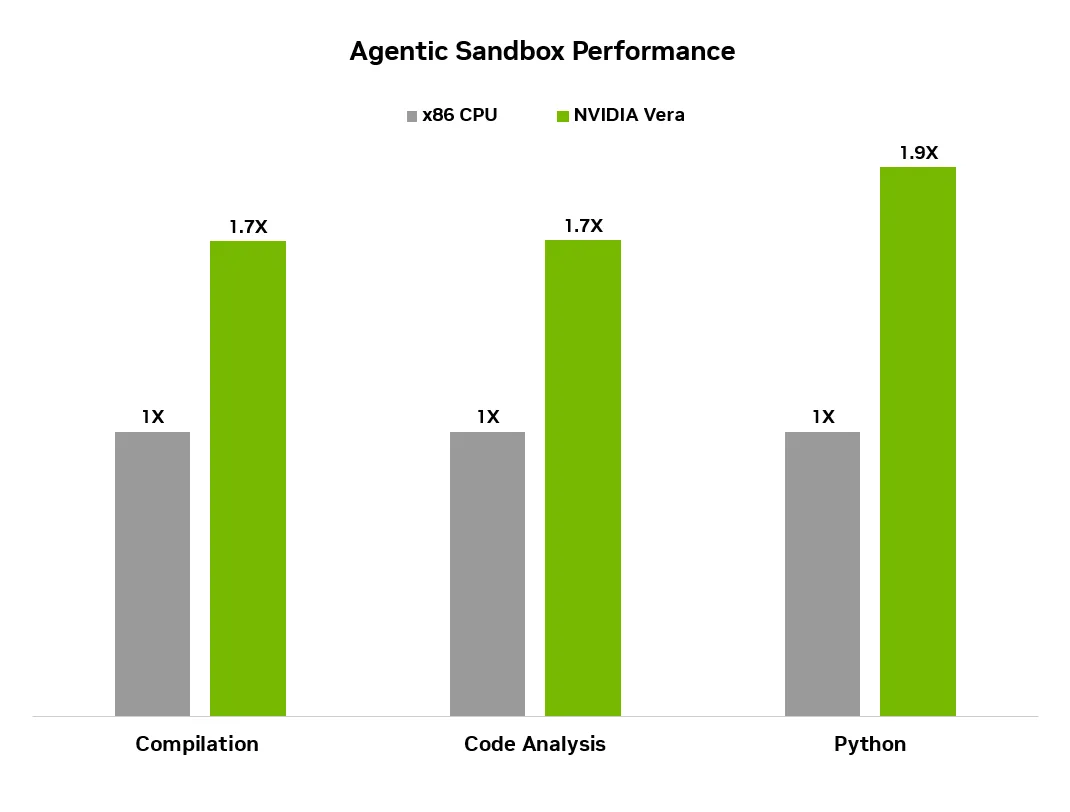
The Phoronix results add credibility, but they also narrow the interpretation. NVIDIA's blog says Phoronix tested a single-socket Vera CPU with a 450W TDP and less than 30W memory power profile. The workloads included code compilation, file compression, video transcoding, Python, Java, and database management. Phoronix reported a 1.6x geometric-mean performance improvement over Grace and a 10% geometric-mean lead over AMD's EPYC 9575F 5.0GHz high-frequency processor.
Outside coverage put caveats around the test scope. Tom's Hardware noted that the first benchmarks were run at NVIDIA's Santa Clara facility and focused on workloads selected around NVIDIA's target. PC Gamer used similar caution around the NVIDIA-sanctioned nature of the testing. Phoronix itself said production enclosed server chassis behavior, including power and frequency, will matter more later in 2026. Vera's results should therefore not be stretched into a blanket claim that it wins every general server workload.
For developers, the more practical question is where an agent waits. If a model call takes two seconds and the test suite takes 45 seconds, upgrading the GPU may not improve the user's completed-task latency. If retrieval queries and document parsing dominate, storage, database behavior, and memory bandwidth will shape perceived speed. In a multi-step agent, CPU execution sits between model calls over and over. NVIDIA's diagram matters because it treats CPU execution as a repeated part of reasoning, not as background plumbing.
The same structure applies to reinforcement learning. RL post-training can involve repeated calls to code generators, math tools, simulators, browsers, game environments, and validators. The GPU may generate the policy step, but the environment step, judge, and test execution often run on CPUs. NVIDIA says Vera can create more completed evaluations and more training-window data. The longer an agent reasons and the more it verifies, the more time CPU-side execution can take away from accelerator utilization.
Vera BlueField-4 STX points in the same direction. In a separate newsroom post, NVIDIA described Vera BlueField-4 STX as protecting agents, context memory, and file-based data access with silicon-level security while integrating storage acceleration and networking. Agents constantly touch files and tools, so compute is not the only runtime concern. Permissions, storage, network policy, and security checks also become part of the latency path. Vera's appearance inside BlueField-4 STX suggests NVIDIA sees agentic workloads as a CPU, DPU, storage, and security package.
The NYSE example gives Vera a broader infrastructure angle than AI labs alone. NVIDIA's release quotes NYSE Group president Lynn Martin saying NYSE processes more than 1.1 trillion messages per day and plans to use Redpanda, HPE, and Vera CPU systems to scale capacity and further optimize latency. That statement is not just about an "AI agent" label. It places Vera in streaming data, database, analytics, and latency-sensitive infrastructure as well as model-serving support.
Anthropic and Oracle's comments sit closer to the agent workload story. Anthropic head of compute James Bradbury described Vera as a promising part of the ecosystem for addressing agentic workloads. OCI executive Mahesh Thiagarajan said OCI is scaling infrastructure for training, inference, and agentic AI demand, and described Vera as supporting high-throughput reasoning and data processing workloads. Those comments point less to model leaderboard competition and more to infrastructure scheduling, throughput, and cost curves.
OpenAI and SpaceXAI appeared first through a delivery story rather than detailed public quotes. NVIDIA wrote on May 18 that Ian Buck personally delivered the first Vera CPU systems to Anthropic, OpenAI Mission Bay, SpaceXAI Palo Alto, and Oracle Cloud Infrastructure. The post says the OpenAI visit included opening the server lid to show the internals, while SpaceXAI asked about cores, memory layout, and cooling. That is symbolically useful, but it does not establish production scale or the exact workload profile for those labs.
Reading this announcement only as "NVIDIA beat Intel and AMD" misses part of the product logic. EPYC and Xeon are still the obvious competitors, but NVIDIA is trying to sell against a different metric. The company wants buyers to evaluate AI factories by tokens per dollar, output per watt, and task completion time, not only by conventional cores per dollar. Under that metric, the CPU is not a GPU accessory. It is the environment that runs before and after the GPU produces the next token.
Software teams can treat the Vera announcement as an observability checklist before treating it as a hardware roadmap. Agent latency should be split into model-call time, tool execution time, retrieval time, sandbox startup time, test-runner time, and policy approval time. CPU utilization, memory bandwidth, storage wait, and network wait should be separated for each step. Whether a CPU like Vera lowers cost will show up less in "GPU token time per request" and more in how many CPU steps, seconds, and watts are spent before a task is actually complete.
Cloud buyers also need to ask lock-in questions. NVIDIA says Vera can be sold as a standalone CPU server, as the host CPU for the Vera Rubin platform, and inside the BlueField-4 STX storage processor. A full-stack NVIDIA AI factory can offer CPU-GPU coherent bandwidth, storage security, networking, and rack power as one design. But if a workload runs well enough on existing x86 fleets, or if a cloud provider's custom Arm CPU is cheaper, the claimed 1.8x agentic sandbox performance may not translate directly into a lower bill.
Fall availability remains a concrete checkpoint. NVIDIA's official timeline says partner systems and cloud partner availability start in fall 2026. Public cloud instance lists, prices, SLAs, regions, and software stacks still require separate announcements. Production chassis thermals, frequency behavior, and memory configurations will also affect interpretation. Real enterprise agent workloads are noisy: policy engines, logging, secret brokers, network proxies, and human approval systems all add latency beyond synthetic benchmark loops.
Vera is news because the comparison unit for AI infrastructure is changing. Since 2023, LLM competition has often been explained through parameters, context windows, token prices, and GPU availability. As coding agents and research agents grew through 2025 and 2026, the cost of "what happens after the model generates" became harder to ignore. NVIDIA is packaging that execution layer as a new CPU demand curve, and the May 31 announcement ties the story to manufacturing partners and named customers.
Developers can start with a simple measurement pass. Separate model steps and CPU steps in agent traces. Group requests with many tool calls. For coding agents, record compile, test, static analysis, package install, and file-search time as distinct metrics. For data agents, split parsing, SQL, embedding lookup, reranking, and format conversion. When comparing hardware or cloud SKUs, look beyond GPU throughput and add completed tasks per dollar, completed evaluations per hour, and failed sandbox restart rate.
Vera is not a universal answer that every team can buy today. NVIDIA's public performance numbers are aimed at agentic workloads, and production pricing and availability will need verification after fall 2026. The question it raises can be applied earlier. When AI agents become execution systems rather than answer generators, bottlenecks move outside GPU kernels. The time spent opening files, running code, querying databases, and passing validators has to be counted before an agent's real speed and cost are visible.