MiniMax M2.7 brings self-evolving training to low-cost agent models
MiniMax M2.7 uses a self-evolution loop around OpenClaw, activates only 10B of 230B parameters, and challenges premium coding models on price, benchmarks, and licensing.

- What happened: Shanghai-based MiniMax released
M2.7, a sparse MoE model trained with more than 100 autonomous self-optimization loops.- MiniMax says the process improved internal evaluation performance by 30%, with the model modifying scaffold code, evaluating results, and deciding whether to keep or roll back changes.
- Why builders noticed: M2.7 activates only 10B of its 230B parameters per token while claiming near-Opus coding performance at much lower token prices.
- Cost caveat: The headline pricing is weakened by long thinking traces, including reports of simple prompts generating more than
16,000thinking tokens. - Watch: The model is described as open source, but its modified MIT license requires MiniMax approval for commercial use.
- That puts M2.7 closer to a controlled open-weight release than to Apache-2.0 projects such as GLM-5.1.
An AI model revised parts of its own training workflow, ran more than 100 autonomous optimization loops, and lifted internal evaluation performance by 30%. That is the central claim around MiniMax M2.7, released on April 12 by the Shanghai AI startup MiniMax. The model uses a sparse mixture-of-experts architecture: 230B total parameters, but only 10B active parameters for each token. In SWE-Pro, it reached 56.22%, close to the roughly 57% reported for Claude Opus 4.6. MiniMax also prices it far below premium frontier APIs: $0.30 per million input tokens and $1.20 per million output tokens.
The headline is attractive, but the release is not a simple "cheap Opus" story. M2.7 can emit very long thinking traces, with community reports of more than 16,000 thinking tokens for simple prompts. Its 200K context window may also lose practical speed advantages when filled, because the model uses full attention. And although MiniMax uses open-source language around the release, the modified MIT license requires prior written permission for commercial use.
The more durable question is narrower and more technical: can model training itself become an agentic loop? M2.7 is interesting because MiniMax is not only claiming another benchmark win. It is claiming that the model participated in improving the system used to train and evaluate it.
Who MiniMax is
MiniMax was founded in Shanghai in 2021 by former SenseTime executive Yan Junjie. The company became one of China's most visible AI startups after a $600M round led by Alibaba in March 2024, which valued it at $2.5B. In January 2026, MiniMax completed a Hong Kong IPO; its shares reportedly rose more than 70% on the first trading day and pushed market capitalization past HK$90B, or about $11.5B. NVIDIA CEO Jensen Huang has also described the company as a "world-class" AI startup.
Its investor base reflects the Chinese technology stack around AI. Alibaba, Tencent, Hillhouse, HongShan, IDG Capital, and miHoYo are all part of the broader MiniMax story. The product portfolio is also broader than text models. MiniMax operates Hailuo AI for video generation and Music-01 for music generation, so M2.7 arrives from a company already building across text, video, audio, and multimodal tooling.
Until this release, MiniMax was quieter than DeepSeek, Zhipu GLM, and Alibaba Qwen in the open model conversation. Those companies turned open-weight LLM releases into global developer adoption channels. MiniMax spent more attention on multimodal products. M2.7 is its more direct entry into the frontier text and coding-model race.
Self-evolution means the model changed the training harness
The most important part of M2.7 is not the benchmark number. It is how MiniMax says the model got there.
Most LLM training pipelines are directional. Engineers collect data, preprocess it, train a model, evaluate the result, adjust the pipeline, and deploy a new checkpoint. The model being trained is mostly an artifact of the process. If the process needs improvement, humans change the data recipe, reward setup, evaluation harness, scaffold code, or deployment rules.
MiniMax says it built an autonomous agent harness called OpenClaw. An early version of M2.7 ran inside that harness as an agent and executed more than 100 optimization loops. The loop included analyzing failure trajectories, drafting a change plan, editing scaffold code, running evaluation, comparing results, and deciding whether to retain or roll back the change.
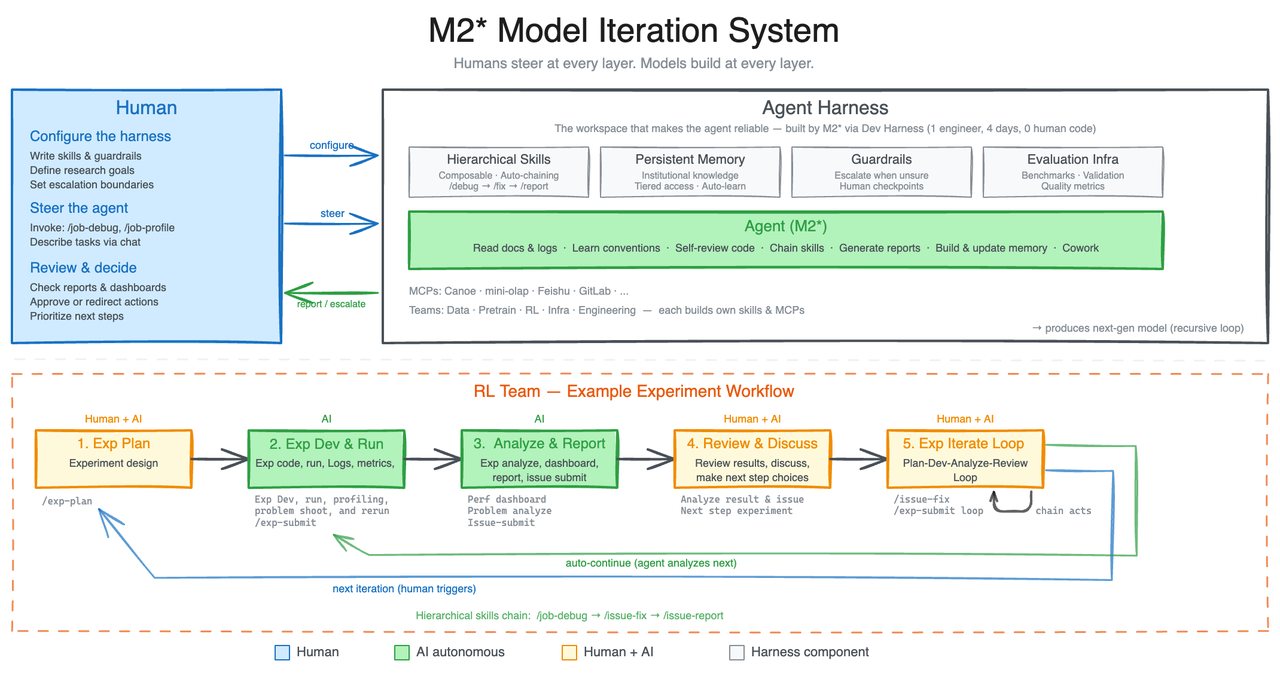
That is different from standard RLHF or RLAIF framing. In RLHF and RLAIF, the model receives preference or reward signals from humans or AI systems. The model is still the object being optimized. In MiniMax's self-evolution framing, the model becomes an active participant in the training infrastructure. It diagnoses failure, edits surrounding code, and helps shape the next attempt.
MiniMax says this loop improved internal evaluation performance by 30%. The company also says the model updated its own memory and built dozens of complex skills inside the harness to support reinforcement-learning experiments. In the Korean source article, the practical claim is that MiniMax's RL team now lets M2.7 handle 30% to 50% of routine work, including literature review, data-pipeline management, experiment launch, monitoring, log analysis, debugging, code changes, and merge requests.
The MLE-Bench Lite result gives the claim a concrete evaluation surface. On 22 machine-learning competitions using a single A30 GPU, M2.7 reportedly achieved a 66.6% average medal rate. That placed it behind Claude Opus 4.6 at 75.7% and GPT-5.4 at 71.2%, and tied with Gemini 3.1.
230B total parameters, 10B active parameters
M2.7's pricing depends on architecture as much as training method. The model has 230B total parameters, but only about 10B active parameters for a token. MiniMax uses a sparse mixture-of-experts architecture with 256 experts, eight of which are activated per token. The model also has 62 layers, a 3,072 hidden size, and a 200K context window.
| Item | MiniMax M2.7 | Claude Opus 4.6 | GPT-5 |
|---|---|---|---|
| Total parameters | 230B | Undisclosed | Undisclosed |
| Active parameters | 10B | Undisclosed | Undisclosed |
| Context window | 200K | 200K | 128K |
| Input price ($/M tokens) | $0.30 | $15.00 | $10.00 |
| Output price ($/M tokens) | $1.20 | $75.00 | $30.00 |
| Inference speed | ~100 TPS | ~33 TPS | ~40 TPS |
| Architecture | Sparse MoE | Dense | Undisclosed |
Among tier-1 performance claims in the source article, M2.7 is presented as the only model with just 10B active parameters.
That sparse activation is why the price comparison looks so aggressive. Against Claude Opus 4.6, the source article compares $0.30 input pricing with $15.00, and $1.20 output pricing with $75.00. That gives the headline numbers: 50 times cheaper for input and 62.5 times cheaper for output. MiniMax also claims about 100 tokens per second, roughly three times the Opus comparison point used in the Korean article.
The software-engineering benchmark table makes the price argument sharper.
| Benchmark | M2.7 | Claude Opus 4.6 | GPT-5.3 Codex |
|---|---|---|---|
| SWE-Pro | 56.22% | ~57% | 56.2% |
| SWE-bench Verified | 78% | 55% | - |
| Terminal Bench 2 | 57.0% | - | - |
M2.7 is within 0.78 percentage points of Opus on SWE-Pro in the source article's comparison. On SWE-bench Verified, the Korean article reports 78% for M2.7 and 55% for the Opus comparison. It also cites an ELO of 1495 on GDPval-AA, described as the highest among open-source models, and 97% on a 40-task Skill Adherence evaluation.
The real cost is not the headline cost
The price story needs a practical warning. M2.7 reportedly tends to generate far more output tokens than average models. Community reports cited in the Korean article describe simple prompts producing more than 16,000 thinking tokens. If a model emits four times as many output tokens for the same work, $1.20 per million output tokens behaves more like $4.80 in effective task cost.
That still leaves a large gap against the $75.00 per million output-token price used for the Opus comparison. But it makes "62.5 times cheaper" less useful as a production estimate. Kilo Code's independent framing, cited in the Korean article, was closer to "90% of Opus quality at 7% of the cost." That 7% number likely reflects a more realistic accounting that includes thinking-token overhead.
There is also a long-context caveat. M2.7 has a 200K context window, but the llama.cpp community noted that full attention can make long-context use slow. A large advertised context window is not the same thing as a cheap or fast fully populated context window. Teams evaluating M2.7 for repository-scale coding work should measure real prompts with real context lengths, not only the API price sheet.
MMX-CLI puts MiniMax into existing agent workflows
The release is not only a model checkpoint. MiniMax also released MMX-CLI, a multimodal command-line tool intended for agent environments. The important integration detail is that it can call MiniMax models natively from existing tools such as Claude Code, Cursor, and OpenClaw without requiring an MCP server.
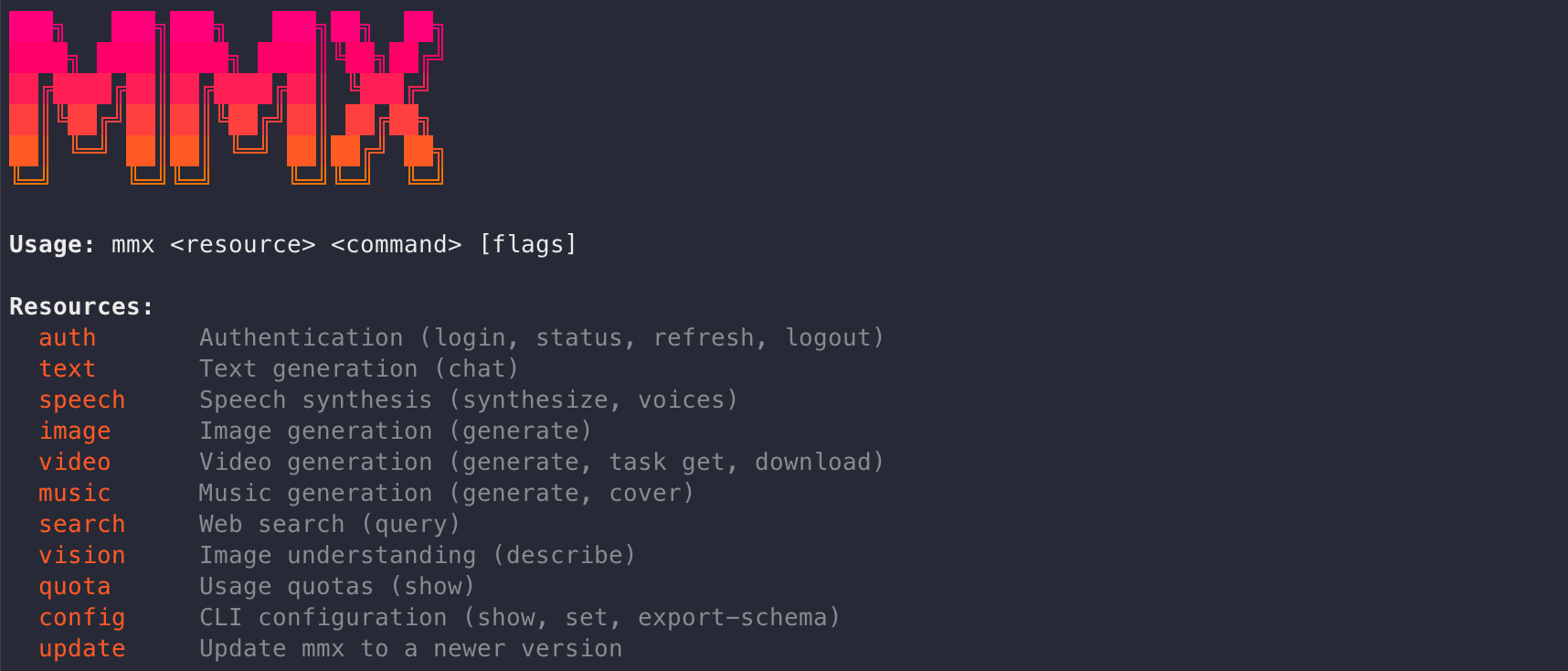
For a developer using an agentic coding environment, that changes the integration surface. Instead of wiring a separate API client or standing up an MCP server for image, video, audio, music, vision, search, or text generation, MMX-CLI exposes those modalities through a command-line interface. It is written in TypeScript, targets Node.js 18 and later, and supports seven generation modalities in the Korean article: text, image, video, speech, music, vision, and search.
The CLI design is also agent-oriented. Human-readable progress goes to stderr, while machine-parseable output goes to stdout. Different failure types return different exit codes. An --async flag supports asynchronous control. Those details matter because coding agents and automation runners need stable contracts more than polished terminal narration.
Ecosystem support appeared quickly after the M2.7 release. The Korean article lists Ollama, OpenRouter, Vercel, and NVIDIA NIM as early support paths. That gives the model several adoption routes at once: local inference, hosted APIs, application platforms, and enterprise deployment.
MiniMax also released Music 2.6 on the same day. Its cover feature extracts the melodic structure of an existing song and reinterprets it in another style or genre, such as turning folk into heavy metal or a classical symphony into cyberpunk electronic music. The article cites more than 99% BPM and key-control accuracy and a first-output time under 20 seconds. That launch is a reminder that MiniMax is not treating M2.7 as an isolated text release. It is trying to connect model, CLI, and multimodal products.
Community reaction: strong benchmarks, hard licensing questions
The community response has two clear sides.
The positive side is performance per dollar. Kilo Code's independent test reportedly found that M2.7 caught the same security bugs as Opus in a vulnerability-detection task. Users on r/LocalLLaMA praised its backend-coding behavior and its habit of reading code deeply before changing it.
The technical discussion also focused on the harness. One reaction summarized in the Korean article was that harness engineering is becoming the real differentiator. That is a useful lens for M2.7. The model is not only a weights-and-benchmarks story. MiniMax is claiming progress in the infrastructure that lets models improve training workflows.
The negative side starts with licensing. M2.7 uses a modified MIT license, but commercial use requires prior written approval from MiniMax. That is not the ordinary meaning most developers attach to open source. The source article cites Reddit criticism that MiniMax called the model open source while attaching a non-commercial-style constraint.
This concern is not specific to MiniMax. The Korean article compares it with Meta's move around Muse Spark and the Meta Spark License, where Meta's earlier open-source posture became more restrictive. A broader pattern is emerging: companies use "open" language to drive developer adoption while retaining commercial control.
| Model | License | Commercial use | Constraint | Practical openness |
|---|---|---|---|---|
| GLM-5.1 | Apache 2.0 | Free | None | Fully open |
| DeepSeek | MIT | Free | None | Fully open |
| MiniMax M2.7 | Modified MIT | Prior approval required | Written MiniMax approval | Conditional |
| Meta Llama 4 | Llama License | Conditional | Restriction above 700M MAU | Conditional |
| Meta Muse Spark | MSL | Strictly limited | Effectively proprietary | Not open source |
The word "open source" does not always imply the same commercial freedom across model releases.
The same week, Zhipu's GLM-5.1 offered a useful contrast in the source article. GLM-5.1 used Apache 2.0 and claimed first place on SWE-Bench Pro. For developers who need unambiguous commercial freedom, that license may matter more than a small benchmark delta.
The self-evolution claim should stay bounded
M2.7's self-evolution does not mean the deployed model improves itself continuously in production. The loop described in the source article happens during training and evaluation. Once the model is served, users are not getting a system that rewrites its own weights or training procedure in real time.
That boundary matters because "self-evolving AI" can easily sound like an autonomous runaway system or a marketing phrase. The practical version is more grounded: a model acts as an agent inside a controlled research harness, changes code and scaffold logic around experiments, evaluates outcomes, and helps researchers decide what to keep.
That still changes the model-development process. If this pattern generalizes, the scarce skill in model labs shifts from only scaling data, parameters, and compute toward building reliable agentic research environments. The competitive asset becomes the harness: memory, tools, evaluation discipline, rollback logic, experiment tracking, and the ability to let models safely improve parts of the pipeline without corrupting the science.
Meta's HyperAgents project, mentioned in the Korean article, points in a similar direction around agent self-improvement. MiniMax and Meta are not proving the same thesis in the same way, but both make the model-development loop more agentic. The question for 2026 is whether these systems produce repeatable research productivity or only strong demonstrations around carefully chosen tasks.
M2.7 is not a perfect model release. Its cost advantage depends on actual token behavior, not price-card math. Its long-context speed needs workload-specific testing. Its license creates enterprise friction for commercial use. But the self-evolution loop is a real signal: model competition is moving from "who trained the bigger model?" toward "who can build the better system for models to help train, test, and improve the next model?"
For teams evaluating agent models, M2.7 should be tested less like a general chatbot and more like a research-and-coding worker. Measure repository tasks, long-context prompts, thinking-token overhead, CLI integration, and license risk. The model's strongest claim is not that it is simply cheaper. It is that MiniMax is turning the training pipeline itself into an agent workspace.