Microsoft Ships a 5B Coding Model Into Copilot Defaults
MAI-Code-1-Flash is rolling into GitHub Copilot for VS Code, putting Microsoft’s own 5B coding model inside Copilot’s model picker and Auto routing path.

- What happened: Microsoft AI introduced MAI-Code-1-Flash and GitHub started rolling it into Copilot for VS Code.
- The rollout starts with Copilot Free, Pro, Pro+, and Max individual users, including the model picker and Auto picker paths.
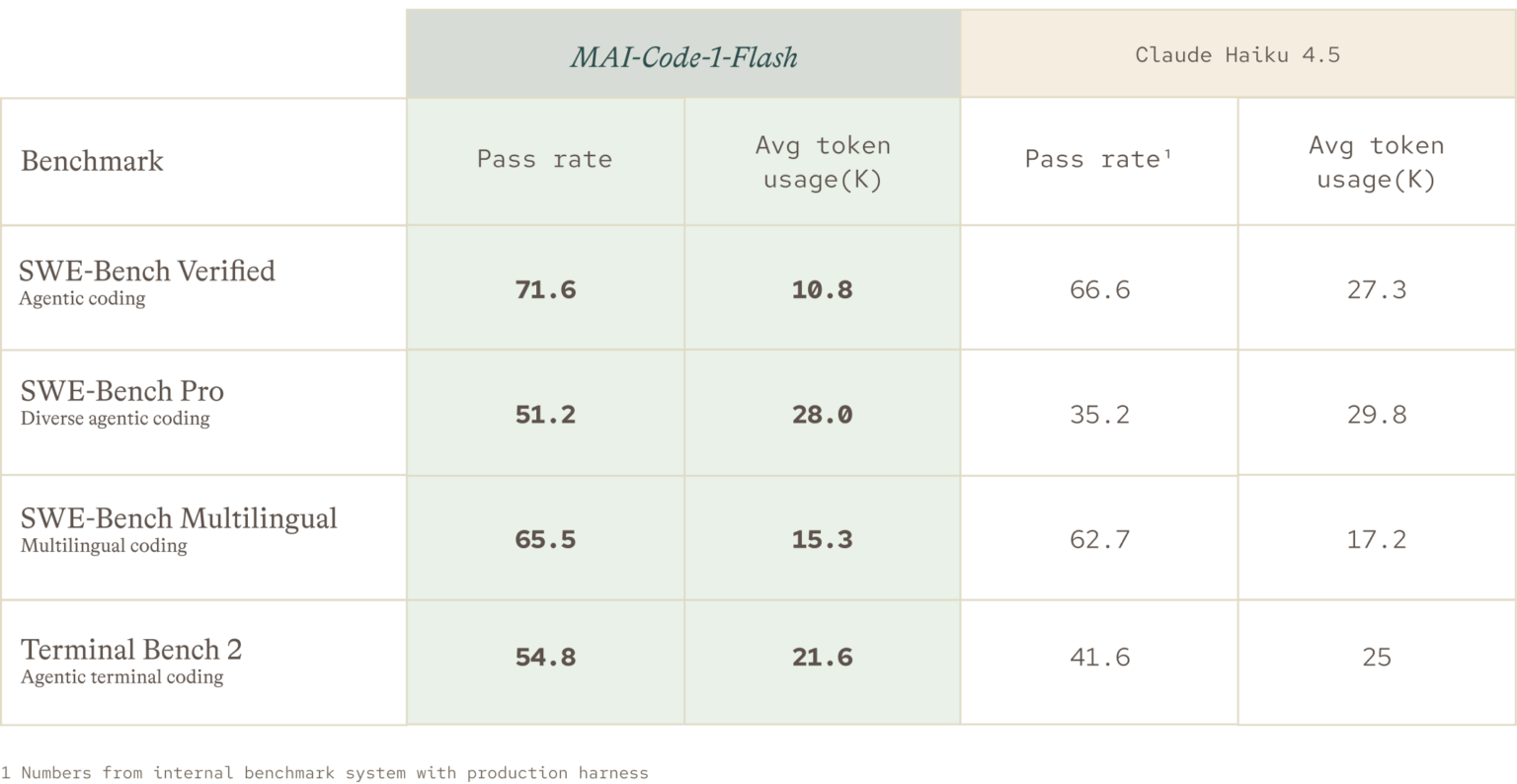
- Numbers: Microsoft claims a 5B active-parameter coding model, 51.2% on SWE-Bench Pro, and up to 60% fewer tokens than Claude Haiku 4.5 on SWE-Bench Verified.
- Why it matters: Copilot is becoming a routing layer for Microsoft-built coding models, not only a client for OpenAI, Anthropic, and Google models.
- Watch: The benchmark numbers come from Microsoft’s production harness, so teams still need repository-level checks for latency, cost, and patch quality.
Microsoft has started putting its own coding model inside GitHub Copilot. Microsoft AI announced MAI-Code-1-Flash on June 2, 2026, and GitHub said the same day that the model is rolling out to Copilot in VS Code. The first wave covers Copilot Free, Pro, Pro+, and Max individual users, with availability expanding gradually over several weeks.
This is more than another model option in a dropdown. MAI-Code-1-Flash is entering the normal Copilot product path. A user can select it directly in the VS Code model picker, and Copilot's Auto picker can route some requests to it without the user choosing the model name. Copilot is therefore moving from a surface that mainly exposes third-party frontier models into a product that can default everyday coding work to a Microsoft-built model.
The first number Microsoft wants readers to notice is size: 5B active parameters. Mustafa Suleyman's broader MAI model family announcement calls MAI-Code-1-Flash an inference-efficient agentic coding model. The same announcement places it alongside six other MAI models for image generation, speech, transcription, reasoning, and coding, and says the models are built for the Microsoft stack.
In GitHub Copilot, that 5B figure is less a brag about scale than an operating choice. Many Copilot interactions are short: explain an error, add a unit test, refactor a small function, repair a TypeScript type, or summarize a failing terminal log. Those tasks do not always need a large reasoning model. When a developer is waiting in the editor, first-token latency, response length, and routing cost shape the product experience as much as peak benchmark score.
Microsoft's main comparison is Claude Haiku 4.5. The MAI-Code-1-Flash post says Microsoft evaluated the model against Claude Haiku 4.5 on SWE-Bench Verified, SWE-Bench Pro, SWE-Bench Multilingual, and Terminal Bench 2 using the same production harness. On SWE-Bench Pro, Microsoft reports 51.2% for MAI-Code-1-Flash and 35.2% for Claude Haiku 4.5. On SWE-Bench Verified, it says MAI-Code-1-Flash solved difficult issues with up to 60% fewer tokens.
Token efficiency deserves its own line in coding-agent evaluation. Two models can pass the same issue while producing very different reasoning traces, patches, tool calls, and explanations. In a product like Copilot, extra tokens show up as latency, quota pressure, and cost. When Copilot reads files, interprets test output, retries patches, or explains an error in chat, "value per token" becomes a practical metric rather than a pricing footnote.
The benchmark caveat is equally important. Microsoft emphasizes that the comparison used the same production harness. That gives the test a product-relevant angle, because Copilot's actual environment includes repository context, tool use, prompt construction, and patch application. It also makes independent reproduction harder. A reader should treat the result as evidence that Microsoft believes the model performs well inside Copilot-like workflows, not as a universal claim that it beats Claude Haiku 4.5 in every coding setup.
Community discussion landed on that point quickly. A Hacker News thread for MAI-Code-1-Flash reached hundreds of points and comments by June 3. Some developers asked whether SWE-Bench Pro examples could overlap with training data. Others focused on the economics of small specialized models. A recurring request was simpler: if the model is called Flash, developers want tokens-per-second, latency distribution, and actual Copilot billing behavior alongside pass rate.
That reaction is fair because coding benchmarks are sensitive to the harness. Results can change based on whether the model can run tests, how many attempts it gets, what tools are available, how repository context is packed, and how failed patches are scored. SWE-Bench-style evaluations are still useful, but Copilot is a product pipeline. The model, retriever, editor integration, terminal access, instruction hierarchy, billing policy, and retry loop all affect the final developer experience.
The more revealing part of MAI-Code-1-Flash is the training target. Microsoft says the model is designed and trained around the GitHub Copilot production harness. The announcement names repository question answering, refactoring, telemetry-grounded tasks, and core software-engineering tasks. That is a different optimization loop from building a general chatbot and later attaching it to an IDE. Microsoft is using Copilot's workload distribution as the shape of the model.
This gives Microsoft a different starting point from Cursor, Claude Code, and OpenAI Codex. Claude Code and Codex bind the model and agent surface under the same product brand, with users moving through a CLI, app, browser, or sandboxed task. GitHub Copilot already has VS Code, Visual Studio, JetBrains IDEs, GitHub, Codespaces, Actions, issues, pull requests, and code review surfaces. Microsoft does not need to win by creating a separate coding app first. It can swap models behind the Copilot interface and let Auto picker decide when a cheaper model is enough.
GitHub's changelog supports that reading. It describes MAI-Code-1-Flash as the first in a new wave of purpose-built coding models from Microsoft. That wording frames this release as the start of a Copilot-specific model line, not a one-off research announcement. The inclusion of Free and Pro users matters too. Fast and inexpensive models change the default experience for more people than premium reasoning models that users select only for hard tasks.
The larger MAI announcement also contains a supply-chain message. Microsoft repeats that the new models were built with clean and appropriately licensed data, without distillation, and for Microsoft's own stack. Enterprise buyers increasingly ask about data provenance, licensing exposure, retention, vendor dependence, fallback paths, and procurement terms alongside raw benchmark score. A Microsoft-owned coding model inside Copilot gives GitHub more room to manage availability, cost, and routing without depending entirely on external model suppliers.
For developers, the immediate change is narrow. If the rollout has reached an account, MAI Code 1 Flash can appear in the VS Code Copilot model picker. Users who leave Copilot on Auto may have some requests routed to it. If it handles short edits, explanations, test additions, and small refactors quickly enough, many users will not care which model answered. For large design changes, multi-package migrations, or long debugging sessions, larger reasoning models may remain the better choice.
Teams evaluating Copilot should ask three operational questions. First, can administrators observe which requests Auto picker sends to MAI-Code-1-Flash? Second, does the smaller model produce safe patches inside private repositories with the team's coding standards, dependency patterns, and test culture? Third, what is the real cost difference once token-based billing, request frequency, and automatic routing are combined? Microsoft's Build 2026 MAI keynote transcript says MAI-Code-1-Flash is cheaper than Claude Haiku 4.5 in Copilot's token-based billing, but team-level spend depends on how often Copilot chooses it.
The Korean developer community noticed the release quickly as well. GeekNews listed MAI-Code-1-Flash on June 3, describing the model as available to GitHub Copilot individual users in VS Code and emphasizing adaptive thinking and token efficiency. For developers already switching between Copilot, Claude Code, Cursor, and Codex, the news is not simply another model launch. It shows model selection disappearing into product defaults.
The phrase to avoid is "Microsoft has ended its OpenAI dependence." Microsoft and OpenAI remain tied through Azure, model access, enterprise contracts, and product integrations. Copilot also still exposes other model choices. The accurate claim is narrower: Microsoft has placed its own coding model into a high-frequency Copilot path where it can handle everyday coding tasks when the router decides the smaller model is sufficient.
Four metrics will determine whether this is a meaningful product shift. The first is how often Copilot Auto picker selects MAI-Code-1-Flash. The second is when and how enterprise Copilot tenants receive the same model. The third is whether GitHub exposes model-level latency, token, and success telemetry to administrators. The fourth is what size, price, and benchmark profile Microsoft chooses for the next purpose-built coding model.
MAI-Code-1-Flash will not lead the frontier-model leaderboard conversation. Its importance comes from placement. A model that answers frequent Copilot requests can influence the economics and feel of AI coding more than a larger model that is reserved for exceptional cases. Microsoft is beginning to make "small, fast, owned by the platform, escalates only when needed" a default Copilot strategy. If the rollout works, the change will show up less in benchmark charts than in the model a developer never had to choose.