CodeGraph Hits 31.5k Stars With a Local Index for Cheaper Coding Agents
CodeGraph v0.9.7 tries to cut the repository-reading cost of Claude Code, Codex, Cursor, and other coding agents with a local code graph.
- What happened:
CodeGraphreleased v0.9.7 on May 28, 2026.- GitHub API metadata showed roughly 31,545 stars and 1,846 forks around the release.
- Why it matters: the project targets the cost of letting Claude Code, Codex, Cursor, and similar agents rediscover a repository through repeated file reads.
- Numbers to check: the README claims average reductions of 35% cost, 57% tokens, and 71% tool calls across seven repositories.
- Those are project-published measurements, not independent benchmark results, so workload and agent behavior still matter.
- Watch: CodeGraph pays off when the agent actually uses the MCP tools as its first path into the codebase.
- The README notes that sub-agents can still create overhead if they keep reading files directly instead of querying the graph.
CodeGraph has become a useful signal in the coding-agent debate because it moves attention from model scores to repository exploration cost. The colbymchenry/codegraph repository describes itself as semantic code intelligence for Claude Code, Cursor, Codex, OpenCode, Hermes Agent, Gemini, Antigravity, and Kiro. Its May 28, 2026 v0.9.7 release connected Go gRPC stubs to concrete implementations, demoted generated files in search results, improved dynamic-dispatch tracing, expanded interface-to-implementation links, and fixed stale index rows for deleted files. GitHub API metadata around the release showed roughly 31,545 stars, 1,846 forks, and an MIT license.
The product story is not just another open-source coding tool launch. When Claude Code or Codex answers an architecture question in a large repository, the model first has to locate the right files, symbols, routes, and call paths. That discovery step can mean repeated grep, find, file reads, and sub-agent exploration. To a human developer this may feel like normal browsing. In an agent run, it becomes tokens, tool calls, wall-clock time, and model spend. CodeGraph proposes to replace part of that repeated discovery loop with a prebuilt local code knowledge graph.
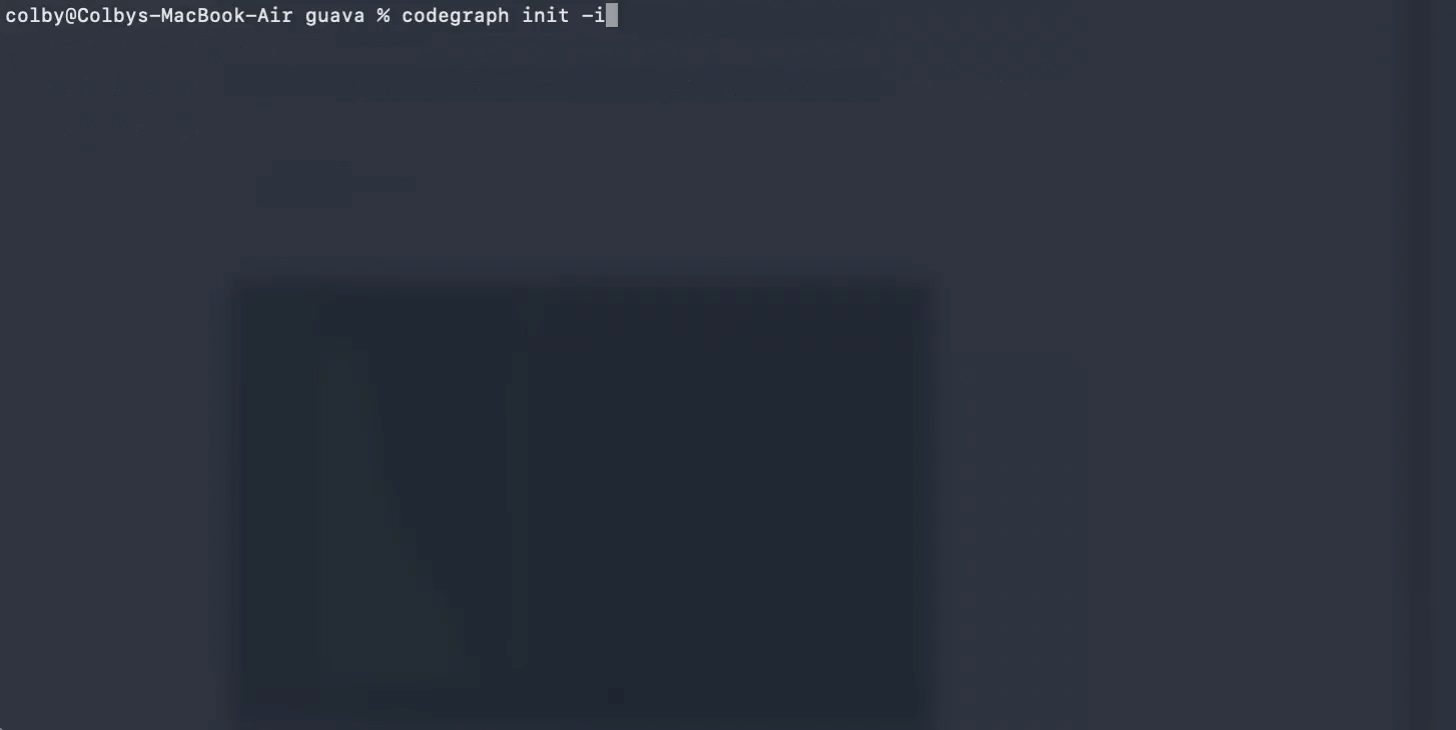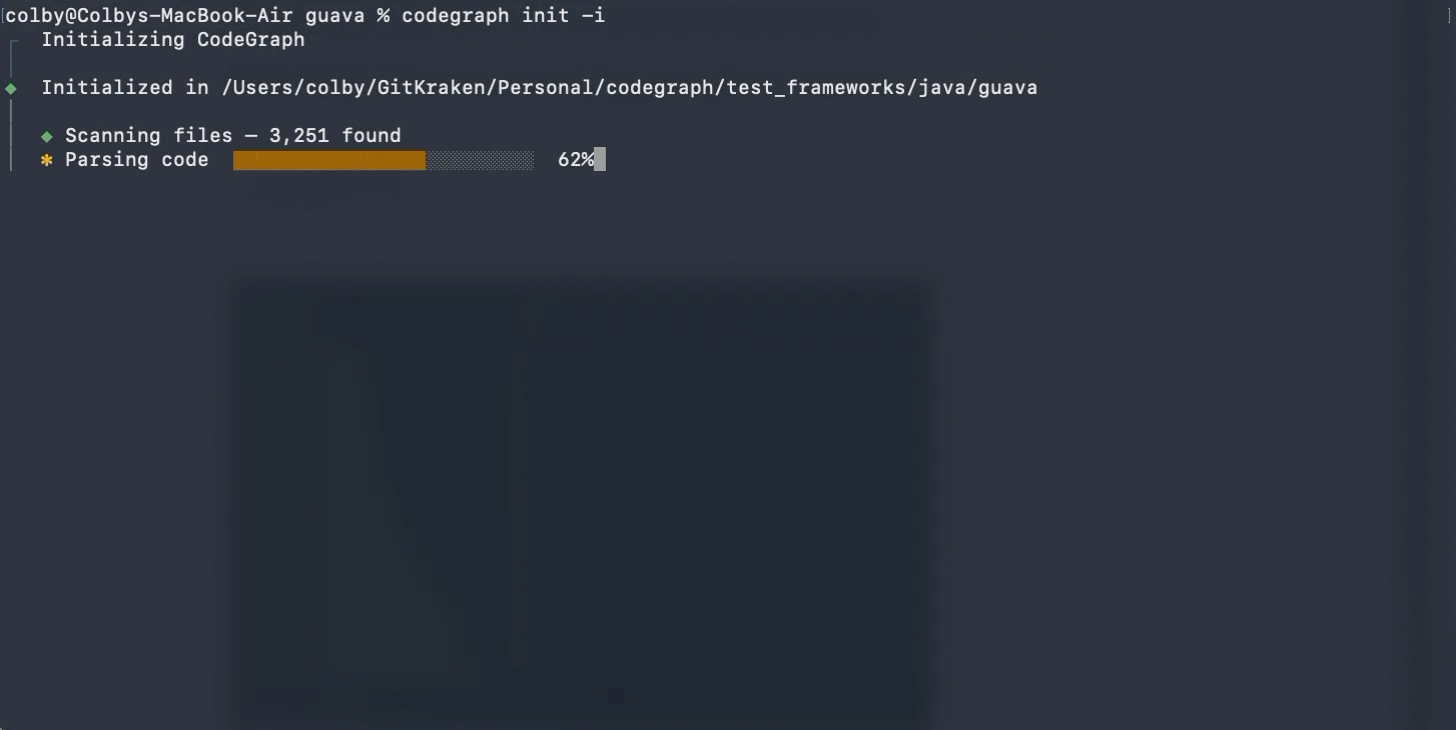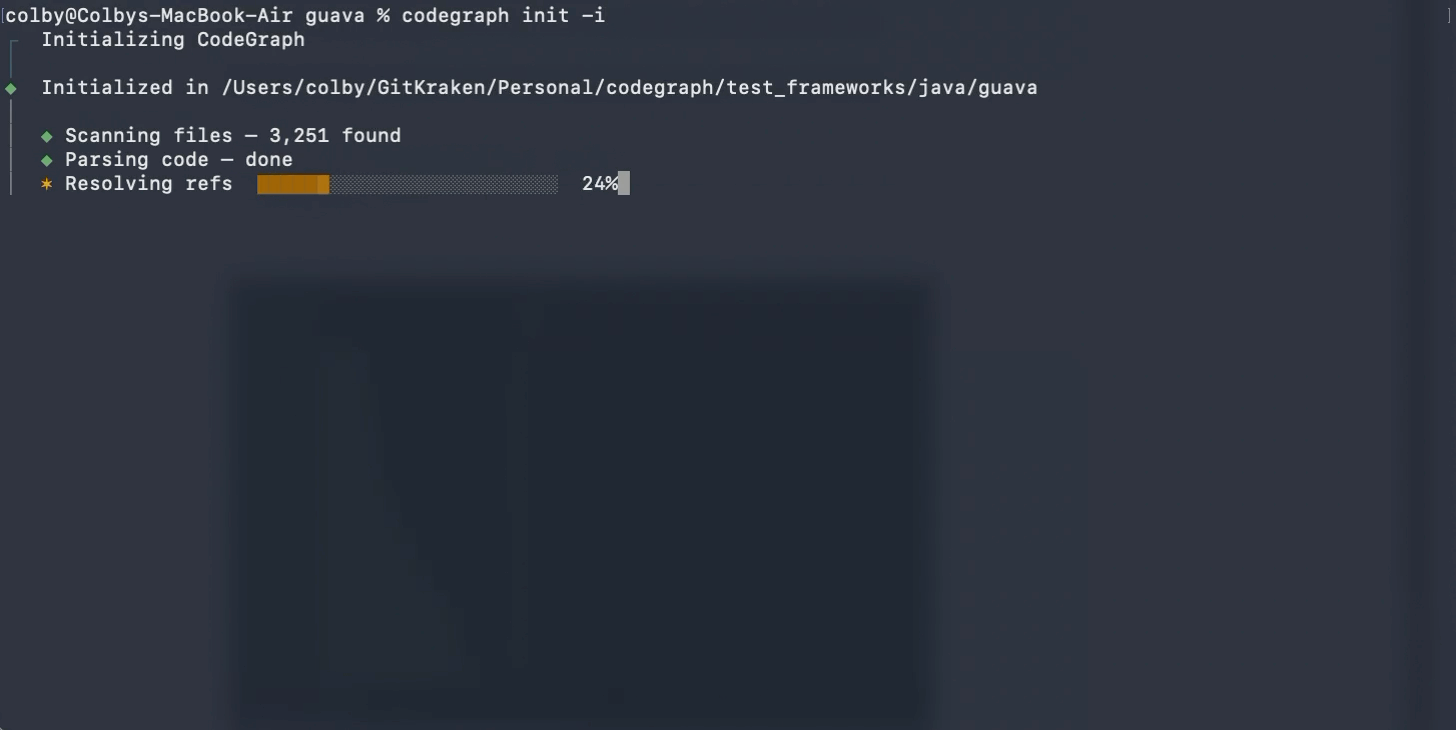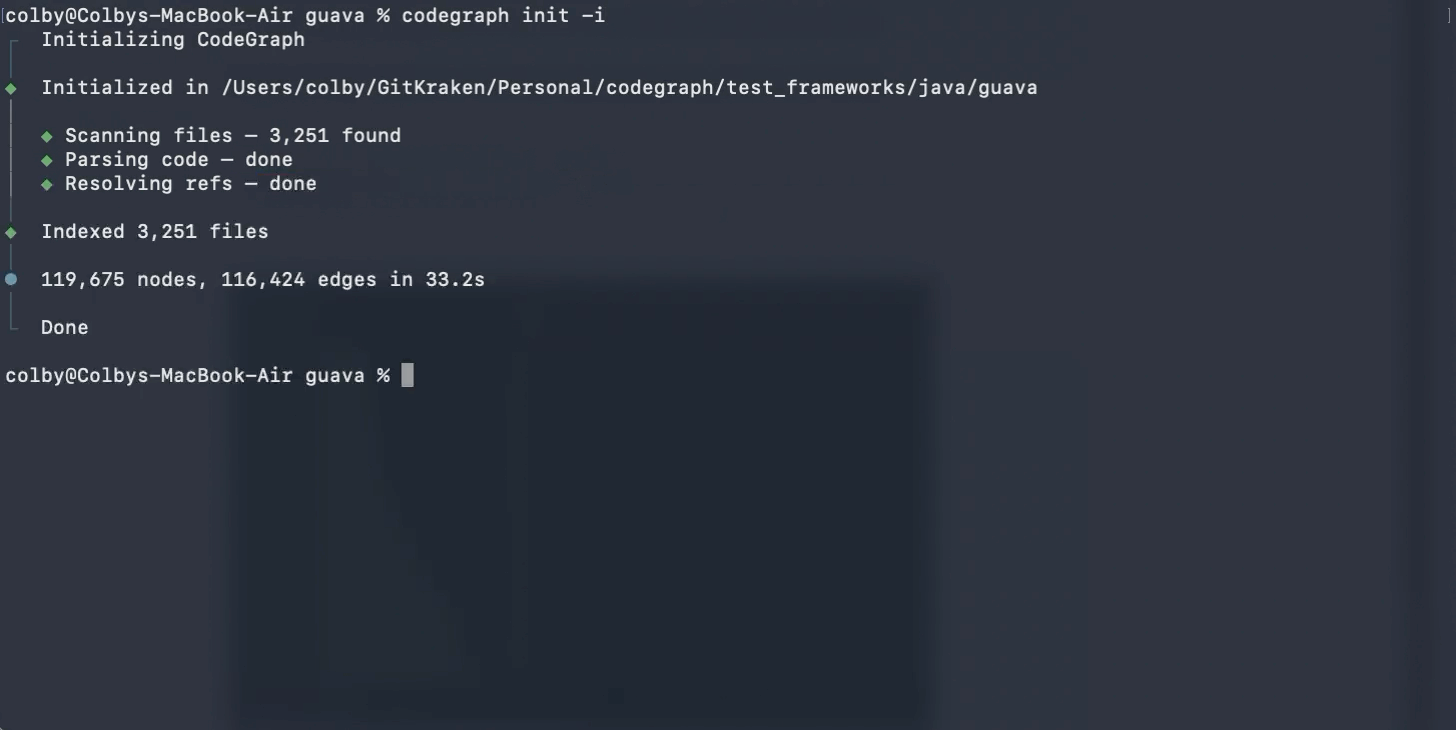
The README frames the core mechanism plainly: CodeGraph builds a pre-indexed knowledge graph, then lets an agent ask about symbol relationships, call graphs, and code structure instead of scanning files from scratch. Installation is exposed through a curl script, npx @colbymchenry/codegraph, or npm i -g @colbymchenry/codegraph. A project index starts with codegraph init -i. After that, an MCP server exposes tools such as codegraph_context, codegraph_trace, codegraph_explore, codegraph_search, and codegraph_impact.
The most interesting changes in v0.9.7 are about keeping agents away from misleading code. For Go projects, gRPC interface stubs now link to hand-written implementations instead of leaving the agent staring at generated shells. Generated files, protobuf output, mocks, and build artifacts are pushed lower in search, trace, and explore results. In large multi-module repositories, when multiple endpoints share a symbol name, CodeGraph now prefers endpoints in the same directory. These are index-quality changes rather than model-quality changes, but for coding agents the two are tightly coupled: better location data means fewer wrong edits and fewer expensive review passes.
Interface-to-implementation linking also widened in this release. The release notes say CodeGraph can find concrete implementations for interface methods in C#, TypeScript, JavaScript, Swift, and Scala, extending a path that had been stronger in Java and Kotlin. That matters because agents often produce plausible but wrong answers after reading only an interface declaration. String search can answer "where does this name appear?" A code graph is meant to answer "where does this call actually go?" That distinction becomes more valuable when the repository uses dependency injection, framework routing, generated clients, or cross-language bridges.
The project-published benchmark numbers are large enough to explain the attention. CodeGraph says it tested seven real-world open-source codebases, seven languages, and one architecture question per repository. The setup ran Claude Opus 4.7 headlessly, compared a CodeGraph MCP arm against an empty MCP config arm under --strict-mcp-config, ran each arm four times, and reported medians. The README says the v0.9.4 benchmark was revalidated on May 24, 2026. The average results: 35% lower cost, 57% fewer tokens, 46% less time, and 71% fewer tool calls.
The repository-level results are more useful than the averages. For a VS Code question, CodeGraph reports token use falling from 2.8 million to 601,000 and tool calls falling from 55 to 8. For Excalidraw, it reports 3.5 million tokens dropping to 344,000 and 79 tool calls dropping to 3. For Tokio, the reported cost falls from $2.41 to $0.42. The same table shows weaker cases: OkHttp stays at $0.47, and a smaller repository such as Gin leaves less room for savings. The obvious reading is that CodeGraph's benefit grows when the repository is large and the question requires broad exploration.
The caveats should stay attached to those numbers. First, the benchmark is published by the project itself; the research note did not find an independent reproduction yet. Second, each repository is represented by one architecture question, while daily agent work includes bug fixes, refactors, test failures, security patches, and review preparation. Third, CodeGraph helps most when the agent chooses CodeGraph tools directly. The README itself says sub-agents can create overhead if they continue reading files directly. The accurate claim is not "indexes always make agents cheaper." It is "a graph-first exploration path can be cheaper when the workload otherwise forces repeated repository scans."
| Exploration path | Default agent behavior | CodeGraph approach |
|---|---|---|
| Starting point | file names, strings, globs, grep | symbols, callers, callees, routes, impact graph |
| Cost item | repeated file reads and sub-agent tool calls | local indexing and MCP queries |
| Strong fit | small repositories and direct string search | large repositories, architecture questions, impact analysis |
| Failure mode | finding relevant files late or reading too much | stale indexes, heuristic edges, unused tools |
CodeGraph's local-only positioning is also part of the story. The README says repository data does not leave the machine, no API key is required, and the index is stored in SQLite. For enterprise security teams, a local MCP server is different from sending a code search index to an external SaaS service. Local does not remove the need for review. Teams still need to inspect install scripts, agent permissions, MCP server config, generated instruction files, and .codegraph/ index retention. But for organizations that cannot move repository context into a cloud RAG system, a local graph is easier to justify.
The supported surface area is broad. The README lists more than 20 languages, including TypeScript, JavaScript, Python, Go, Rust, Java, C#, PHP, Ruby, C, C++, Objective-C, Swift, Kotlin, Dart, Lua, Luau, Svelte, Liquid, and Pascal/Delphi. It also claims route recognition for Django, Flask, FastAPI, Express, NestJS, Laravel, Drupal, Rails, Spring, Gin, Axum, ASP.NET, Vapor, React Router, and SvelteKit. On iOS and React Native projects, it describes Swift and Objective-C bridging, React Native legacy bridge support, TurboModules, Fabric view components, and Expo Modules. The quality will not be identical across every stack, but the ambition is clear: let an agent enter a repository with a structural map instead of starting from raw text search.
Community response is uneven. GeekNews listed the project as a code knowledge graph for AI coding agents and summarized the reported cost and token reductions for Claude Code, Codex, and Cursor. Hacker News had a May 24, 2026 submission titled Supercharge Claude Code, Cursor, Codex with Semantic Code Intelligence, but it only reached 1 point and 2 comments in the research snapshot. GitHub stars moved much faster than public discussion. That pattern is common for developer infrastructure in an early wave: actual agent users and tool collectors may try it before a broader forum conversation forms.
CodeGraph's competitors are not a single product category. Cursor and Sourcegraph Cody already keep codebase context close to the developer experience. Continue, Zed, and JetBrains AI Assistant each have their own project-context strategy. In the MCP ecosystem, language-server-based tools, repository-specific RAG, and code navigation servers such as Serena-like setups can target similar questions. CodeGraph's distinction is that it is a local MCP index rather than an IDE-locked feature. That portability is valuable, but it adds setup work: the index must be initialized, the agent must be steered toward the tools, and teams have to watch freshness.
The operational questions for a development team are concrete. First, measure where agents actually spend money in the repository. Model response cost alone is not enough; logs should separate file discovery, test discovery, route tracing, dependency graph investigation, and sub-agent calls. Second, test how the index behaves when stale. CodeGraph describes file watching, debounce, pending sync banners, and connect-time catch-up, but CI checkouts and container sandboxes may not behave like a local workstation. Third, write instructions that stop agents from treating heuristic graph edges as guaranteed facts. A code graph can guide investigation; it should not become an unverified oracle.
The deleted-file stale-row fix in v0.9.7 points at the same operational issue. A code index is not a static document. The moment an agent edits the repository, the index starts aging. If an MCP response points to a file that has already moved or disappeared, the model can build a patch from old information. That is why freshness and provenance belong beside search speed in any coding-agent index. The product does not just need to find more links; it needs to tell the agent when the map may be behind the territory.
The broader event is that code reading has become its own infrastructure layer for coding agents. In 2025 and early 2026, much of the public conversation centered on which model scored higher on SWE-bench. Teams now have a more prosaic problem: how many times does the same model need to reread the repository before it makes a useful edit? Which tool calls burn the budget? Can PR analysis be reused across sessions? CodeGraph's 35% cost-reduction claim is an early attempt to answer those questions at the repository-navigation layer.
That does not make CodeGraph an automatic install for every team. The teams most likely to learn from it are those with large repositories, repeated architecture questions, agent-driven refactoring, code review preparation, or onboarding automation. Small repositories and autocomplete-heavy workflows may see little benefit. A serious evaluation should run the same prompt set with CodeGraph enabled and disabled, across the models and agents the team actually uses, then record cost, time, success rate, and wrong-file references. The README's numbers are a starting point. The team's own repository is the benchmark that matters.
CodeGraph v0.9.7 shifts the coding-agent discussion from model names toward the tool topology in front of the model. An agent has to find the code before it can change the code, and that search path now affects both product experience and the invoice. If a local graph can replace repeated grep and Read loops, an agent may reach the same answer with fewer tokens. If the index is stale or the agent ignores it, the graph becomes another layer to maintain. In 2026, a practical coding-agent stack needs to track models, repository indexes, MCP tools, freshness policy, and benchmark harnesses together.