QVAC TurboQuant 통합, 로컬 AI의 8GB KV 캐시 병목
Tether QVAC SDK 0.12.0이 Google TurboQuant를 구현해 긴 컨텍스트 로컬 AI의 KV 캐시 메모리 병목을 줄입니다.

- 무슨 일: Tether가
QVAC SDK 0.12.0에 Google Research의 TurboQuant 구현을 넣는다고 2026년 6월 1일 발표했습니다.- 발표는 262,000 tokens 규모에서 4B 모델의 KV cache가 약 8GB를 차지할 수 있다는 수치로 local long-context 병목을 설명합니다.
- 개발자 영향: QVAC은 JavaScript SDK, OpenAI-compatible API, P2P delegated inference를 묶어 cloud-only 설계를 피하려는 local AI stack입니다.
- 주의점: Google의 6배/8배 연구 수치와 Tether의 5배 SDK 주장은 구분해야 하며, QVAC Fabric README는 이 릴리스의 TurboQuant kernel이 CUDA와 Metal에는 없다고 적습니다.
Tether AI Research Group이 2026년 6월 1일 QVAC SDK 0.12.0에 TurboQuant 구현을 넣는다고 발표했습니다. 대상은 모델 전체가 아니라 긴 대화와 큰 문서 처리에서 커지는 KV cache입니다. Tether 발표는 4B 모델 기준으로 약 262,000 tokens에서 KV cache만 약 8GB를 차지할 수 있다고 설명합니다. 몇 시간 분량의 대화나 수백 쪽 텍스트 규모이며, 네 세션이면 모델 weight를 빼고 cache만 약 32GB까지 올라갈 수 있다는 계산입니다.
이 숫자가 글의 출발점입니다. 로컬 AI를 말할 때 보통 "7B 모델을 어느 노트북에서 돌릴 수 있나"를 먼저 묻지만, 긴 컨텍스트에서는 모델을 한 번 메모리에 올린 뒤에도 매 token마다 이전 key/value embedding을 보관해야 합니다. 문서 전체, 코드 저장소, 긴 상담 기록을 한 번에 다루려면 cache가 계속 자랍니다. Tether가 QVAC에 TurboQuant를 넣는다고 말한 이유도 "모델을 작게 만든다"보다 "session memory를 줄인다"에 가깝습니다.
TurboQuant 자체는 Tether가 만든 연구가 아닙니다. Google Research는 2026년 3월 24일 TurboQuant를 공개했고, 논문은 ICLR 2026 conference paper로 올라와 있습니다. 논문 제목은 "TurboQuant: Online Vector Quantization with Near-Optimal Distortion Rate"입니다. 저자는 Google Research의 Amir Zandieh와 Vahab Mirrokni, New York University의 Majid Daliri, Google DeepMind의 Majid Hadian입니다.
Google Research 설명에서 TurboQuant는 high-dimensional vector를 줄이는 online vector quantization 알고리즘입니다. LLM에서는 KV cache, 검색에서는 vector index가 직접 적용 대상입니다. Google은 Gemma, Mistral, Llama 3.1-8B-Instruct를 포함한 open-source model과 LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, L-Eval 같은 long-context benchmark를 사용했다고 밝혔습니다.
논문은 TurboQuant가 두 단계로 작동한다고 설명합니다. 첫 단계는 PolarQuant 방식으로 vector를 random rotation한 뒤 좌표를 scalar quantizer에 넣어 main signal을 압축합니다. 두 번째 단계는 남은 residual error에 1-bit Quantized Johnson-Lindenstrauss, 즉 QJL transform을 적용해 inner product estimator의 bias를 줄입니다. Transformer attention은 query와 key 사이의 inner product에 민감하므로, 단순히 값의 크기만 줄이는 압축보다 attention score의 왜곡을 줄이는 설계가 필요합니다.
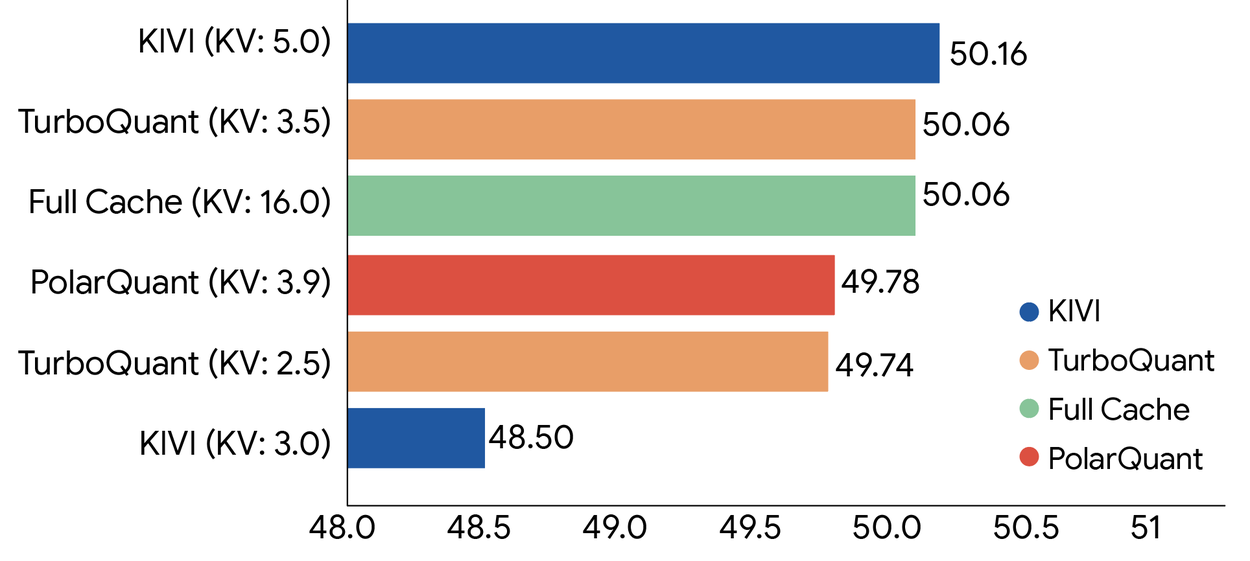
Google Research가 공개한 숫자는 공격적입니다. 블로그는 TurboQuant가 KV cache를 3-bit까지 양자화할 수 있다고 설명합니다. training이나 fine-tuning 없이 Gemma와 Mistral에서 원래 모델보다 빠른 runtime을 보였다는 설명도 붙었습니다. Needle In A Haystack에서는 key-value memory를 최소 6배 줄이면서 downstream result가 완전했다고 적었습니다. H100 GPU 기준으로 4-bit TurboQuant가 32-bit unquantized keys 대비 attention logits 계산에서 최대 8배 성능 향상을 보였다는 chart도 함께 공개했습니다.
Tether 발표의 수치는 Google 블로그와 다르게 읽어야 합니다. Tether는 QVAC implementation에서 KV cache를 최대 5배 압축하면서 uncompressed model에 가까운 output quality를 유지한다고 설명합니다. Google Research는 연구 환경에서 최소 6배 KV memory reduction과 최대 8배 attention-logit speedup을 제시했습니다. 두 문장을 합쳐 "QVAC이 모든 환경에서 8배 빨라진다"고 쓰면 틀립니다. QVAC이 발표한 제품 claim은 "최대 5배 KV cache compression"입니다.
QVAC이 흥미로운 이유는 이 발표가 논문 소개가 아니라 SDK 배포 경로를 말하기 때문입니다. QVAC SDK page는 npm install @qvac/sdk로 시작하는 JavaScript SDK를 보여줍니다. SDK는 Node.js, Bare, Bun, Expo 같은 JavaScript runtime을 지원한다고 설명합니다. LLM completion뿐 아니라 speech-to-text, text-to-speech, translation, OCR, image understanding, RAG를 한 entrypoint에서 다룰 수 있다고 적습니다.
QVAC GitHub README도 제품 방향을 분명히 합니다. QVAC은 local-first, peer-to-peer AI application을 만들기 위한 open-source cross-platform ecosystem입니다. 로컬에서 model을 load하고 inference를 수행하며, 필요하면 peer에게 inference를 delegated할 수 있습니다. HTTP server는 OpenAI-compatible API를 노출하므로, OpenAI REST API 형식을 쓰는 앱이 local QVAC server를 바라보도록 바꿀 수 있다는 설명도 들어 있습니다.
| 항목 | Google Research TurboQuant | Tether QVAC 구현 |
|---|---|---|
| 공개 시점 | 2026년 3월 24일 연구 블로그, ICLR 2026 paper | 2026년 6월 1일 QVAC SDK 0.12.0 announcement |
| 주요 claim | KV memory 최소 6배 절감, H100 attention logits 최대 8배 speedup | KV cache 최대 5배 압축, local/edge workload에 적용 |
| 대상 병목 | KV cache, vector search, inner product distortion | 긴 문서, codebase, 대화 session, mobile/edge memory limit |
| 구현 조건 | research algorithm과 benchmark 중심 | QVAC Fabric README 기준 CPU와 Vulkan path, CUDA/Metal TurboQuant kernel 없음 |
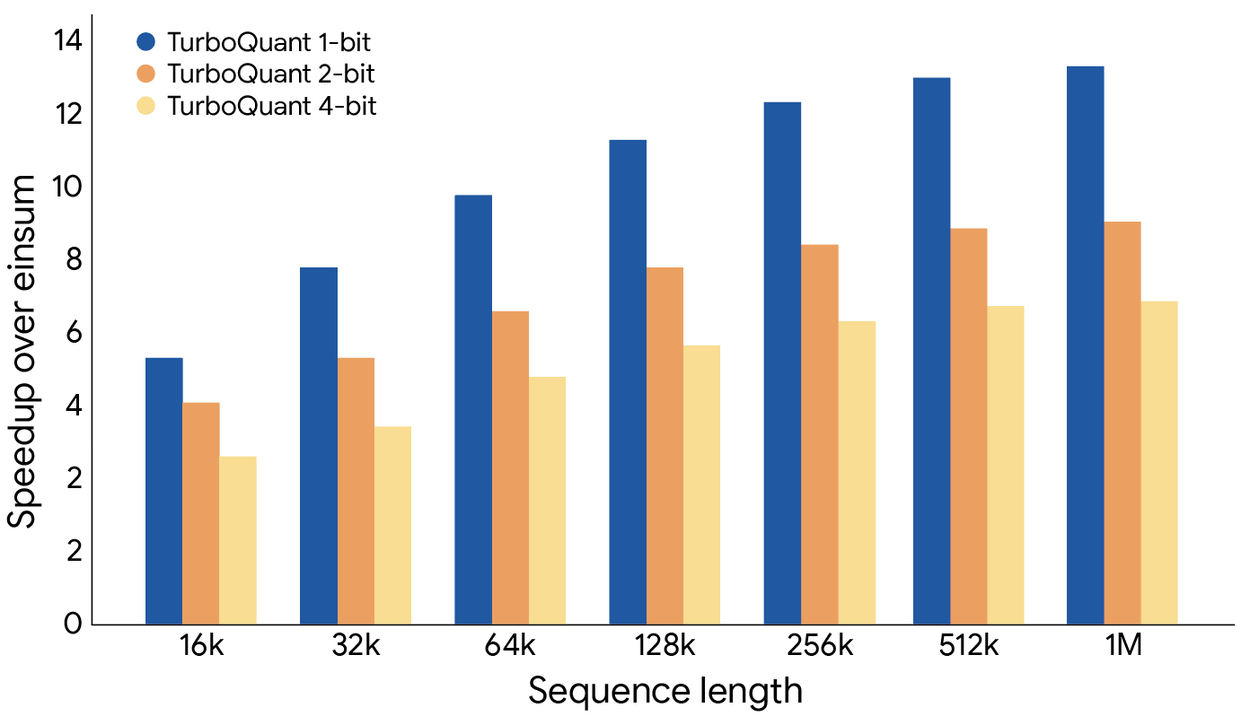
실제 구현 경로는 qvac-fabric-llm.cpp입니다. 이 저장소는 llama.cpp fork이며, README는 "desktop and mobile platforms"용 AI inference and training engine이라고 설명합니다. TurboQuant 항목에는 TBQ3_0, TBQ4_0, PQ3_0, PQ4_0 형식이 적혀 있고, smaller attention head dimension을 위한 64-wide variants도 있습니다. backend support에는 CPU quantization/dequantization과 Vulkan inference kernels가 포함됩니다.
README의 제한도 기사에서 빠뜨리면 안 됩니다. QVAC Fabric은 이 릴리스에서 CUDA와 Metal에 TurboQuant kernel이 없다고 적습니다. macOS와 iOS 자체는 Metal backend로 지원되지만, TurboQuant kernel 지원 범위와 동일하다는 뜻은 아닙니다. NVIDIA CUDA 서버나 Apple Silicon 노트북에서 바로 같은 speedup을 기대하는 개발자는 backend별 구현 상태를 확인해야 합니다.
Tether가 제시한 제품 사례는 로컬 assistant입니다. 발표는 legal document, financial filing, research report, book, code repository, 몇 시간 분량의 conversation을 예로 듭니다. 사용자는 파일을 cloud provider로 보내지 않고 laptop assistant에게 백 페이지 legal document 분석을 시킬 수 있습니다. 학생은 study session 전체를 on-device tutor에 남길 수 있고, 개발자는 codebase 일부를 더 길게 넣는 local coding assistant를 만들 수 있다는 설명입니다.
그 설명은 privacy marketing처럼 들릴 수 있지만, 개발자 입장에서는 deployment constraint입니다. 의료, 법무, 금융, 공공기관에서 "모델 API로 보내면 안 되는 파일"은 제품 요구사항입니다. 지금까지는 air-gapped 환경에서 작은 모델과 짧은 context window를 조합하거나, private cloud endpoint를 따로 만들어야 했습니다. QVAC은 여기에 JavaScript SDK, local server, OpenAI-compatible API, P2P delegated inference를 한 stack으로 제시합니다.
다만 P2P는 모든 문제의 답이 아닙니다. QVAC docs는 peer-to-peer가 optional이라고 설명합니다. 더 강한 기기가 네트워크 안에서 inference를 대신할 수 있고 model download도 peer를 통해 할 수 있다는 장점이 있지만, 기업 환경에서는 device identity, network policy, audit log, data residency를 따로 설계해야 합니다. TurboQuant가 cache를 줄여도 권한 모델과 데이터 이동 경로를 자동으로 해결하지 않습니다.
로컬 AI stack의 경쟁 상대도 단순히 cloud API가 아닙니다. llama.cpp, Ollama, LM Studio, Jan, Open WebUI는 이미 개발자 PC에서 model을 돌리는 경험을 만들었습니다. QVAC의 차별점은 JavaScript SDK와 P2P, OpenAI-compatible API, 여러 AI capability를 하나의 package ecosystem으로 묶는 방향입니다. Tether가 TurboQuant를 발표한 것은 "새 local chat app"보다 "runtime memory profile을 SDK 기능으로 낮춘다"는 쪽에 가깝습니다.
TurboQuant는 RAG와 vector database에도 영향을 줍니다. 논문은 vector database와 nearest neighbor search를 별도 적용 대상으로 다룹니다. Google Research는 TurboQuant가 GloVe dataset에서 baseline product quantization 계열보다 높은 1@k recall ratio를 보였다고 설명합니다. dataset-specific tuning이나 큰 codebook 없이 index building process를 빠르게 할 수 있다는 설명도 붙었습니다. 로컬 RAG 앱에서 embedding index까지 메모리를 줄일 수 있다면, 작은 서버와 데스크톱 배포의 설계 폭이 넓어집니다.
여기서도 과장은 피해야 합니다. TurboQuant가 줄이는 것은 주로 KV cache와 vector representation의 memory footprint입니다. 모델 weight 자체가 사라지지 않습니다. 70B급 모델을 휴대폰에서 자유롭게 실행하게 해주는 발표도 아닙니다. Tether가 예시로 든 4B 모델과 262,000 tokens cache 계산은 "긴 context에서 cache가 별도 병목이 된다"는 근거이지, 모든 local model size 문제를 끝냈다는 증거가 아닙니다.
커뮤니티 반응은 이 선을 기준으로 갈립니다. Reddit의 OpenAI, LocalLLaMA, MachineLearning 관련 thread에서는 6배 memory reduction과 8배 speedup 숫자가 빠르게 공유됐습니다. 긍정적 반응은 current hardware에서 long-context inference budget을 늘릴 수 있는 software-side efficiency jump로 읽습니다. 회의적 반응은 KV cache가 전체 메모리의 한 조각이라는 점을 지적합니다. paper result와 production implementation 사이에 backend kernel, quality eval, latency trade-off가 남아 있다는 지적도 같이 나옵니다.
개발자가 당장 확인할 부분은 세 가지입니다. 첫째, 대상 workload가 정말 KV cache bound인지 측정해야 합니다. 짧은 prompt와 낮은 concurrency에서는 weight memory나 compute latency가 더 클 수 있습니다. 둘째, 사용하는 hardware backend가 QVAC Fabric의 TurboQuant path를 실제로 타는지 확인해야 합니다. 셋째, 압축 후 quality를 own task로 평가해야 합니다. 법률 문서, 코드 검색, 의료 요약처럼 failure cost가 높은 작업은 LongBench 평균으로 충분하지 않습니다.
Tether 발표가 local AI 업계에서 의미 있는 지점은 연구 결과가 SDK release note로 내려왔다는 점입니다. Google이 3월에 논문과 benchmark를 냈고, Tether는 6월에 QVAC SDK와 Fabric 구현으로 개발자가 붙일 수 있는 형태를 제시했습니다. 이 간격이 짧을수록 로컬 AI runtime 경쟁은 모델 목록보다 memory path, backend kernel, API compatibility, evaluation report를 더 자주 비교하게 됩니다.
앞으로 볼 기준은 QVAC 0.12.0 이후의 실제 benchmark입니다. Tether 발표와 GitHub README는 Qwen3.5-4B Q8_0 기준 perplexity delta, RULER score, LongBench average 같은 숫자를 일부 제공합니다. 다음 단계에서는 독립 개발자가 같은 model, 같은 context length, 같은 hardware에서 f16/f16, pq4_0, tbq4_0를 비교한 결과가 필요합니다. CUDA와 Metal path가 보강되는지도 봐야 합니다. mobile Vulkan에서 memory saving과 token generation이 어떤 trade-off를 보이는지도 별도 확인 대상입니다.
로컬 AI의 병목은 "cloud냐 device냐"라는 구호보다 작게 쪼개집니다. model weight, KV cache, vector index, backend kernel, file privacy, network policy가 각각 다른 병목입니다. QVAC TurboQuant 통합은 그중 KV cache와 long-context memory에 꽂힌 업데이트입니다. 긴 문서와 코드베이스를 로컬에서 더 오래 붙잡고 싶은 개발자에게는 확인할 가치가 있지만, 선택 기준은 발표 문구가 아니라 own hardware에서의 cache size, latency, quality delta입니다.