토큰 하나씩의 벽, Nemotron Diffusion이 흔든 서빙 병목
NVIDIA가 tri-mode diffusion LLM을 공개했습니다. AR, diffusion, self-speculation을 한 모델에서 전환하는 추론 실험입니다.

- 무슨 일: NVIDIA가
Nemotron-Labs-Diffusion모델군을 Hugging Face에 공개했습니다.- 같은 체크포인트에서 AR, diffusion, self-speculation 생성을 전환하는 tri-mode LLM입니다.
- 핵심 수치: 8B 기준 diffusion mode는
2.6x, self-speculation은 최대6.4xtokens per forward를 주장합니다. - 개발자 의미: 모델 품질 경쟁보다 서빙 지연시간과 GPU 사용률을 바꾸는 추론 방식 경쟁입니다.
- 주의점: SGLang 통합과 실제 inference provider 배포는 아직 진행 중입니다.
LLM을 쓰는 개발자는 대부분 같은 병목을 겪습니다. 모델이 똑똑해질수록 응답은 길어지고, 에이전트가 여러 단계를 거칠수록 "생각 중" 시간이 늘어납니다. 사용자는 토큰이 흘러나오는 것을 보지만, 서버 입장에서는 매 토큰마다 모델을 다시 통과하는 비용을 냅니다. NVIDIA가 2026년 5월 23일 Hugging Face에 공개한 Nemotron-Labs-Diffusion은 이 오래된 전제를 직접 건드립니다. 질문은 단순합니다. LLM은 반드시 한 토큰씩 왼쪽에서 오른쪽으로만 써야 할까요?
NVIDIA의 답은 "아니어야 한다"에 가깝습니다. Nemotron-Labs-Diffusion은 autoregressive 모델을 버리는 발표가 아닙니다. 오히려 기존 AR 디코딩을 유지하면서, 같은 모델에서 diffusion 방식의 병렬 생성과 self-speculation을 함께 쓰도록 설계한 모델군입니다. 그래서 이번 뉴스의 핵심은 또 하나의 8B, 14B 모델이 나왔다는 사실이 아닙니다. 핵심은 한 체크포인트가 세 가지 추론 모드를 갖는 운영 단위 로 제안됐다는 점입니다.

공개된 모델군은 3B, 8B, 14B 텍스트 모델과 8B 규모의 vision-language 모델을 포함합니다. 텍스트 모델은 NVIDIA Nemotron Open Model License로 공개됐고, VLM은 NVIDIA Source Code License가 적용됩니다. Hugging Face 모델 컬렉션에는 base와 instruction-tuned chat 변형이 함께 올라와 있습니다. NVIDIA는 학습 레시피도 Megatron-Bridge 저장소에 공개했습니다. 즉 "논문 아이디어"라기보다, 최소한 개발자가 내려받아 실험할 수 있는 공개 모델과 코드의 형태를 갖췄습니다.
왜 이게 중요한지는 기존 LLM 서빙 방식을 보면 분명해집니다. 일반적인 autoregressive LLM은 다음 토큰을 예측하고, 그 토큰을 컨텍스트에 붙인 뒤 다시 다음 토큰을 예측합니다. 이 방식은 안정적이고, 디코더 전용 트랜스포머의 생태계와 잘 맞습니다. 문제는 지연시간입니다. 하나의 긴 답변을 만들기 위해 모델은 순차적으로 움직이고, GPU는 계산보다 메모리에서 가중치를 읽는 데 많은 시간을 씁니다. 특히 batch size가 작거나 단일 사용자의 인터랙티브 응답이 중요한 상황에서는 이 병목이 더 도드라집니다. 코딩 에이전트, 문서 에이전트, 긴 추론 체인을 가진 챗봇이 모두 여기에 걸립니다.
Nemotron-Labs-Diffusion은 이 지점을 diffusion language model로 우회하려 합니다. 이미지 생성에서 익숙한 diffusion과 완전히 같은 사용자 경험은 아니지만, 개념은 비슷합니다. 먼저 여러 토큰을 블록 단위로 만들고, 이를 여러 refinement step으로 다듬습니다. 이 과정에서 모델은 토큰 하나를 확정하고 다음으로 넘어가는 대신, 후보 블록을 병렬로 draft하고 수정할 수 있습니다. NVIDIA 발표는 이 방식이 현대 GPU의 계산 구조를 더 잘 활용하고, 필요하면 refinement step 수를 줄여 inference budget을 조절할 수 있다고 설명합니다.
더 흥미로운 부분은 self-speculation입니다. 기존 speculative decoding은 보통 작은 draft model과 큰 verifier model을 조합합니다. 작은 모델이 빠르게 토큰 후보를 만들고, 큰 모델이 이를 검증합니다. 하지만 두 모델을 따로 운영하면 배포 복잡도가 늘고, 캐시와 메모리 관리도 어려워집니다. Nemotron-Labs-Diffusion의 self-speculation은 같은 모델이 diffusion으로 후보를 draft하고, autoregressive 방식으로 검증합니다. NVIDIA의 표현을 빌리면 diffusion-style drafting의 속도 가능성과 AR verification의 신뢰성을 한 모델 안에서 결합하는 구조입니다.
| 모드 | 동작 방식 | 운영 의미 |
|---|---|---|
| Autoregressive | 왼쪽에서 오른쪽으로 한 토큰씩 생성합니다. | 기존 LLM 서빙과 호환되는 기준선입니다. |
| Diffusion | 블록 단위 토큰을 병렬로 만들고 반복적으로 정제합니다. | 낮은 동시성이나 긴 출력에서 GPU 활용률을 끌어올릴 수 있습니다. |
| Self-speculation | 같은 모델이 diffusion draft와 AR verification을 수행합니다. | 별도 draft model 없이 속도와 검증 경로를 함께 노립니다. |
NVIDIA가 내세운 성능 수치도 이 방향을 뒷받침합니다. 발표에 따르면 Nemotron-Labs-Diffusion 8B는 평균 정확도에서 Qwen3 8B보다 1.2%p 높고, tokens per forward 기준으로 diffusion mode는 AR 모델보다 2.6배 높습니다. self-speculation은 linear 설정에서 6배, quadratic 설정에서 6.4배까지 올라간다고 설명합니다. 이 수치는 "초당 토큰" 자체가 아니라 hardware-agnostic한 디코딩 효율 지표라는 점을 구분해야 합니다. 그래도 개발자에게 중요한 메시지는 명확합니다. 모델이 같은 품질권에 머문다면, 다음 경쟁은 파라미터 수보다 토큰을 얼마나 덜 순차적으로 만들 수 있는가 로 옮겨갑니다.
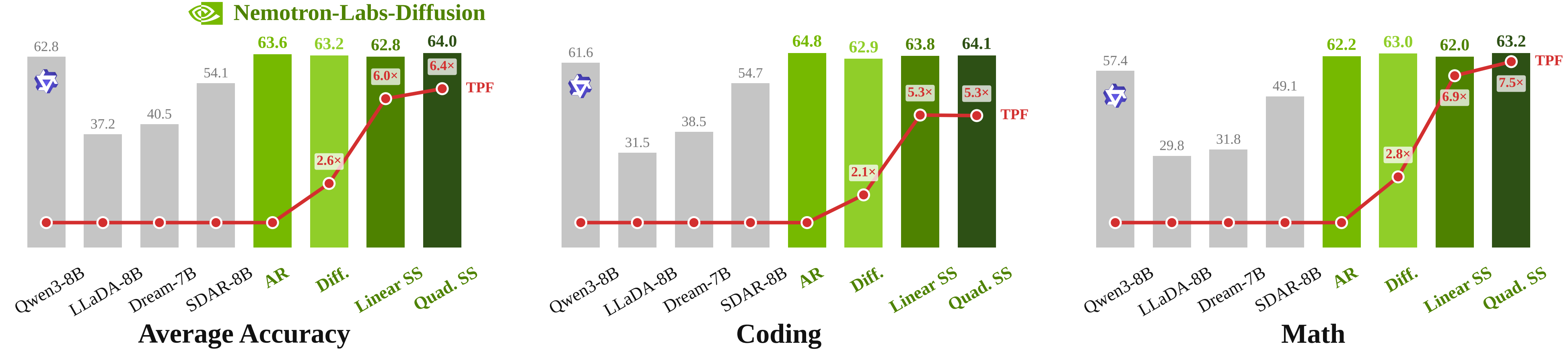
모델 카드의 수치는 더 공격적입니다. 14B 모델 카드는 8B 모델 기준 DGX Spark에서 concurrency 1일 때 112 tok/s를 기록해 AR의 41.8 tok/s보다 2.7배 빠르다고 설명합니다. GB200에서는 850 tok/s로 AR 253 tok/s와 Eagle3 360 tok/s를 앞선다고 제시합니다. custom CUDA kernel을 쓰면 1015 tok/s, 약 4배까지 올라간다는 주장도 있습니다. 물론 이런 수치는 특정 하드웨어, precision, decoding 설정, 벤치마크 조건에 묶여 있습니다. 그대로 제품 SLA로 가져오면 안 됩니다. 하지만 단일 사용자 지연시간이 중요한 에이전트 서비스에서는 충분히 주목할 만한 숫자입니다.
이번 발표가 에이전트 인프라와 연결되는 이유도 여기에 있습니다. 에이전트는 일반 챗봇보다 디코딩 병목에 더 민감합니다. 사용자가 한 번 묻고 끝나는 대신, planner가 계획을 쓰고, tool call을 만들고, 관찰 결과를 읽고, 다시 다음 액션을 작성합니다. 각 단계의 출력은 짧아 보여도 전체 루프에서는 수많은 토큰이 순차적으로 생성됩니다. 모델 호출 횟수와 토큰 대기시간이 곱해지면, 사용자에게는 "에이전트가 멈춘 것 같은" 체감으로 나타납니다. diffusion draft와 self-speculation이 실제로 안정적으로 동작한다면, 에이전트의 병목은 모델 선택뿐 아니라 decoding policy 선택의 문제가 됩니다.
다만 여기서 과장하면 안 됩니다. diffusion language model은 아직 주류 LLM 배포 경로가 아닙니다. NVIDIA도 SGLang 통합이 진행 중이라고 설명합니다. 발표 시점의 메시지는 "지금 모든 inference provider에서 버튼 하나로 켜라"가 아니라 "SGLang 같은 런타임이 이 모드를 받아들이기 시작했다"에 가깝습니다. 또한 diffusion mode가 모든 작업에 유리한 것도 아닙니다. 수학 증명, 긴 코드 수정, strict format 출력처럼 중간 토큰의 순서와 검증이 중요한 작업에서는 AR 검증 경로가 여전히 기준선입니다. self-speculation이 흥미로운 이유도 바로 이 때문입니다. 완전히 다른 생성 방식을 강요하는 대신, draft는 병렬로 하고 검증은 익숙한 causal 방식으로 붙입니다.
학습 경로도 실용성을 겨냥합니다. NVIDIA 발표는 Efficient-DLM 연구 흐름을 언급하며, pretrained AR 모델을 계속 학습하고 attention mechanism을 block-wise 방식으로 바꿔 diffusion capabilities를 더하는 접근을 설명합니다. Nemotron-Labs-Diffusion은 joint AR and diffusion objective로 훈련됐고, 1.3T tokens의 Nemotron pretraining datasets와 45B tokens의 post-training datasets를 사용했다고 발표했습니다. 기존 모델 지식을 버리고 diffusion LM을 처음부터 새로 만드는 것이 아니라, AR 모델의 학습된 능력을 보존하면서 parallel drafting 능력을 얹는 전략입니다.
커뮤니티 반응은 아직 초기입니다. Hugging Face 컬렉션의 upvote와 다운로드 수는 빠르게 움직이고 있지만, 대형 모델 출시 때처럼 폭발적인 논쟁이 붙은 단계는 아닙니다. Reddit의 r/LovingOpenSourceAI 글에서는 parallel token generation이 코드 scaffolding, agent planning, latency-sensitive workload에 의미가 있을 수 있다는 반응이 나왔습니다. 동시에 "빠른 chunk 생성이 좋더라도 단계적 추론에서 coherence가 유지되는지 봐야 한다"는 회의적인 지적도 있었습니다. 이 균형이 중요합니다. diffusion LLM은 마법 같은 품질 향상 발표가 아니라, 지연시간과 비용을 줄이기 위한 서빙 구조 실험입니다.
경쟁 구도도 모델 연구와 런타임 연구가 섞여 있습니다. Qwen3, LLaDA, Dream, SDAR 같은 비교 대상은 모델 품질과 diffusion/AR 설계의 기준선입니다. Eagle3 같은 speculative decoding 계열은 self-speculation의 직접적인 비교 대상입니다. SGLang, vLLM, TensorRT-LLM, TGI 같은 런타임은 이 방식을 실제 서비스로 가져갈 수 있는지 결정합니다. Hugging Face와 MLX 커뮤니티의 변환 모델은 로컬 실험의 속도를 좌우합니다. 결국 이번 발표는 "NVIDIA 모델이 Qwen을 이겼다"보다 "LLM 서빙 스택이 생성 모드를 설정값으로 다루기 시작했다"는 쪽이 더 큰 사건입니다.
개발팀이 지금 당장 할 일은 명확합니다. 첫째, Nemotron-Labs-Diffusion을 프로덕션 모델 후보로 보기보다 latency experiment 후보로 봐야 합니다. 둘째, 품질 지표를 전체 평균 하나로 보지 말고 자신의 워크로드로 나눠야 합니다. 코드 생성, 요약, 짧은 채팅, 긴 에이전트 계획, structured output은 서로 다른 실패 양상을 가집니다. 셋째, tokens/sec만 보지 말고 end-to-end task latency를 봐야 합니다. 에이전트에서는 한 번의 빠른 응답보다 tool loop 전체가 더 중요합니다. 넷째, 배포 런타임의 안정성을 확인해야 합니다. SGLang 지원이 merge되고, provider나 내부 serving stack이 동일한 attention pattern 전환과 KV cache 공유를 안정적으로 제공해야 실제 비용 절감이 됩니다.
특히 내부 플랫폼 팀이라면 이번 발표를 "모델 교체"가 아니라 "라우팅 정책" 문제로 다루는 편이 현실적입니다. 같은 서비스 안에서도 응답 유형은 다릅니다. 사용자의 짧은 질문에 대한 빠른 초안, 코드 보완처럼 중간 수정이 잦은 작업, 긴 reasoning을 요구하는 분석, JSON schema를 반드시 지켜야 하는 자동화 호출은 서로 다른 decoding policy를 요구합니다. AR mode는 가장 보수적인 fallback으로 남기고, diffusion mode는 빠른 draft와 편집성 출력에, self-speculation은 품질을 크게 포기하기 어려운 interactive generation에 붙여 보는 식의 실험이 가능합니다. 이것이 실제로 가능해지려면 모델 API가 단순한 model 선택을 넘어 generation mode, block length, confidence threshold, verification setting 같은 운영 파라미터를 노출해야 합니다. LLM 플랫폼의 추상화가 한 단계 낮은 inference layer까지 내려가는 셈입니다.
비용 관점에서도 의미가 있습니다. 지금까지 많은 팀은 지연시간 문제를 더 작은 모델로 라우팅하거나, speculative decoding용 draft model을 따로 붙이거나, 더 비싼 GPU를 쓰는 방식으로 풀었습니다. 이 방식들은 각각 단점이 있습니다. 작은 모델은 품질 경계가 흔들리고, 별도 draft model은 배포와 모니터링 대상을 늘리며, 하드웨어 증설은 원가를 직접 올립니다. Nemotron-Labs-Diffusion의 주장은 같은 모델 안에서 세 모드를 오가며 이 절충을 조절할 수 있다는 것입니다. 물론 이것이 모든 비용 문제를 없애지는 않습니다. diffusion refinement step이 늘어나면 계산량은 다시 커지고, verification이 실패하면 기대한 속도 이득이 줄어듭니다. 그럼에도 "빠른 모델과 정확한 모델을 따로 들고 가야 한다"는 운영 전제를 약하게 만드는 점은 중요합니다.
보안과 검증도 빠뜨리기 어렵습니다. 에이전트가 tool call을 만들거나 코드를 수정할 때는 빠른 생성만큼 재현성과 감사 가능성이 중요합니다. self-speculation은 draft와 verification의 경계를 한 모델 안에 둡니다. 이 구조는 운영을 단순하게 만들 수 있지만, 디버깅 관점에서는 어떤 후보가 왜 reject됐는지, confidence threshold가 어떤 출력 품질에 영향을 줬는지 추적해야 합니다. 앞으로의 agent observability는 프롬프트, 응답, tool call뿐 아니라 decoding mode와 accepted token path까지 기록해야 할 수 있습니다. 빠른 디코딩이 표준 기능이 되면, "무슨 모델을 썼는가"만으로는 장애 원인을 설명하기 어려워집니다.
이번 발표의 숨은 의미는 "더 큰 모델"이 아니라 "더 다른 디코더"입니다. 지난 2년간 LLM 경쟁은 주로 파라미터, 데이터, context length, reasoning benchmark로 설명됐습니다. 그러나 에이전트와 실시간 앱이 늘어날수록 병목은 모델 지능만이 아닙니다. 같은 GPU에서 더 많은 유효 토큰을, 더 낮은 지연시간으로, 품질 손실 없이 뽑아내는 운영 기술이 중요해집니다. Nemotron-Labs-Diffusion은 그 경쟁이 모델 아키텍처와 inference runtime 사이에서 벌어질 것임을 보여줍니다.
그래서 이 뉴스는 "NVIDIA가 새 LLM을 공개했다"로 끝나지 않습니다. 토큰 하나씩 생성한다는 당연한 전제가 흔들리기 시작했습니다. 아직 실험적이고, 실제 서비스에서는 검증할 것이 많습니다. 하지만 에이전트가 느리다고 느껴지는 순간마다, 우리는 더 큰 모델만 찾을 수는 없습니다. 다음 병목은 디코딩 방식, 런타임, 캐시, verification policy의 조합에서 풀릴 가능성이 큽니다. Nemotron-Labs-Diffusion은 그 방향을 꽤 선명하게 보여준 발표입니다.