Takane 28포인트 개선, 자기개선 에이전트의 안전한 좁은 길
Fujitsu 자기진화 멀티 AI 에이전트는 업무 특화 LLM과 설계서 검색을 운영 중 계속 고치는 검증 루프를 보여줍니다.

- 무슨 일: Fujitsu가 self-evolving multi-AI agent 기술을 발표했습니다.
- 업무 수행 결과, 사람 피드백, 제도 개정, 사양 변경을 에이전트 개선 루프에 넣고 검증된 개선안만 반영하는 구조입니다.
- 핵심 숫자: 업무 특화 LLM
Takane을 제조·의료·금융·공공 도메인에 맞춰 평균 정확도28포인트개선했다고 밝혔습니다. - 의미: 에이전트 경쟁이 실행 자동화에서 운영 중 검증된 자기개선으로 이동하고 있습니다.
- 주의점: 공식 수치는 Fujitsu 평가 조건의 claim이며, 실제 채택은 감사 로그, rollback, 데이터 경계, 규제 검증을 함께 통과해야 합니다.
Fujitsu가 2026년 5월 25일 self-evolving multi-AI agent technology를 발표했습니다. 발표의 표면 문장은 익숙합니다. 여러 AI 에이전트가 팀처럼 일하고, 업무 수행 결과와 사람 피드백을 바탕으로 스스로 개선한다는 이야기입니다. 그러나 이번 발표에서 볼 부분은 "자기진화"라는 큰 단어보다, Fujitsu가 이 루프를 어디에 붙였는지입니다. 대상은 범용 챗봇이 아니라 업무 특화 LLM Takane, 대규모 병원 전자의무기록 시스템, 지방자치단체 업무 솔루션의 설계 사양서 검색입니다.
Fujitsu의 claim은 숫자로도 제시됐습니다. 회사는 제조, 의료, 금융, 공공 행정 등 여러 도메인에서 Takane을 자동 강화하고 운영 중 계속 개선한 결과, 특화 전 대비 평균 정확도가 28포인트 개선됐다고 밝혔습니다. 의료 예시에서는 의무기록과 검사 결과 같은 비정형 데이터에서 진단명, 진행 단계, 치료 방침을 특정 업무 형식에 맞춰 구조화해 추출하는 작업을 들었습니다. 이 수치는 독립 벤치마크가 아니라 Fujitsu의 공식 평가 결과입니다. 그래도 "업무 LLM을 사람이 한 번 튜닝하고 끝낸다"가 아니라, 운영 결과를 다음 개선 데이터로 되돌리는 구조를 전면에 세웠다는 점은 AI 제품팀이 볼 만합니다.
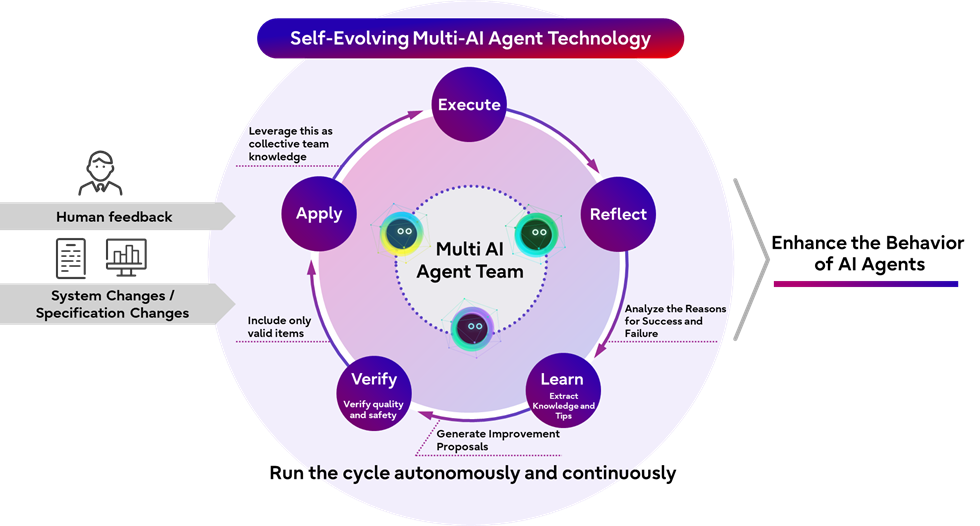
출처: Fujitsu 2026년 5월 25일 공식 발표.
Fujitsu가 정의한 자기진화 멀티 AI 에이전트는 여러 에이전트가 작업을 나누어 수행하고, 수행 결과, 사람 피드백, 정책 개정, 사양 변경 같은 환경 변화를 바탕으로 후속 행동을 지속적으로 안전하게 개선하는 기술입니다. 발표문은 기존 AI 에이전트가 주어진 지시를 처리하는 능력은 높지만, 실패 이유를 독립적으로 분석해 다음 운영 규칙에 안전하게 넣는 데 어려움이 있었다고 설명합니다. 그래서 전문가가 계속 조정하던 prompt, 검색 방법, 평가 기준, 운영 규칙을 에이전트가 일부 넘겨받는 것이 이번 발표의 중심입니다.
자기개선의 대상은 프롬프트가 아니라 운영 규칙입니다
일반적인 에이전트 제품에서 self-improvement는 종종 느슨한 표현으로 쓰입니다. 대화 기록을 기억한다, 실패한 tool call을 재시도한다, 사용자가 싫어한 답을 다음에 피한다는 정도도 자기개선처럼 포장됩니다. Fujitsu 발표의 차이는 개선 대상이 조금 더 구체적이라는 데 있습니다. 회사는 데이터 선택, 학습 조건 조정, 평가, 개선 제안 생성, 검증, 반영을 업무 특화 LLM 구축 과정에 넣었습니다. 각 에이전트가 개선안을 만들고, 효과가 검증된 것만 반영해 모델 성능을 계속 올리는 구조입니다.
이 구조에서 중요한 단어는 "검증된 것만"입니다. 자기개선 루프는 잘못 설계하면 실패를 학습하는 장치가 됩니다. 모델이 그럴듯한 이유를 만들고, 근거 없는 개선안을 채택하고, 다음 세대의 prompt나 데이터셋이 더 오염되는 경로가 생깁니다. Fujitsu는 발표문에서 "generated improvement proposals"를 단순 저장하지 않고, 업무 실행 결과와 평가 결과를 통해 효과적인 것만 반영한다고 설명했습니다. 이 차이가 없다면 self-evolving agent는 운영 자동화가 아니라 자동화된 drift가 됩니다.
관련 연구 맥락도 같은 방향을 가리킵니다. Fujitsu 발표의 related links에는 2026년 5월 21일 arXiv에 제출된 EVE-Agent 논문이 포함되어 있습니다. 원제는 Evidence-Verifiable Self-Evolving Agents입니다. 이 논문은 self-evolving search agent가 스스로 질문과 답을 만들며 학습할 때, 답뿐 아니라 검증 가능한 근거 span을 함께 가져야 한다고 주장합니다. 논문의 핵심 문장은 "self-evolving agents should not train on examples they cannot justify"입니다. Fujitsu의 제품 발표와 논문이 완전히 같은 시스템을 설명한다고 단정할 수는 없습니다. 다만 둘 다 자기개선 루프의 신뢰 조건을 "근거와 검증"으로 잡고 있습니다.
Takane의 28포인트는 어떤 루프에서 나왔나
Fujitsu는 이번 기술을 업무 특화 LLM 자동 강화에 적용했습니다. Takane은 Fujitsu와 Cohere가 공동 개발한 LLM로, Fujitsu는 이를 자사 AI 플랫폼과 산업별 업무 시스템에 연결해 왔습니다. 이번 발표에서 멀티 AI 에이전트는 데이터 선택, 학습 조건 조정, 평가, 개선 제안 생성을 반복합니다. 사람이 매번 도메인 데이터를 고르고, prompt를 바꾸고, 평가 기준을 손보던 과정을 에이전트 팀이 수행하는 형태입니다.
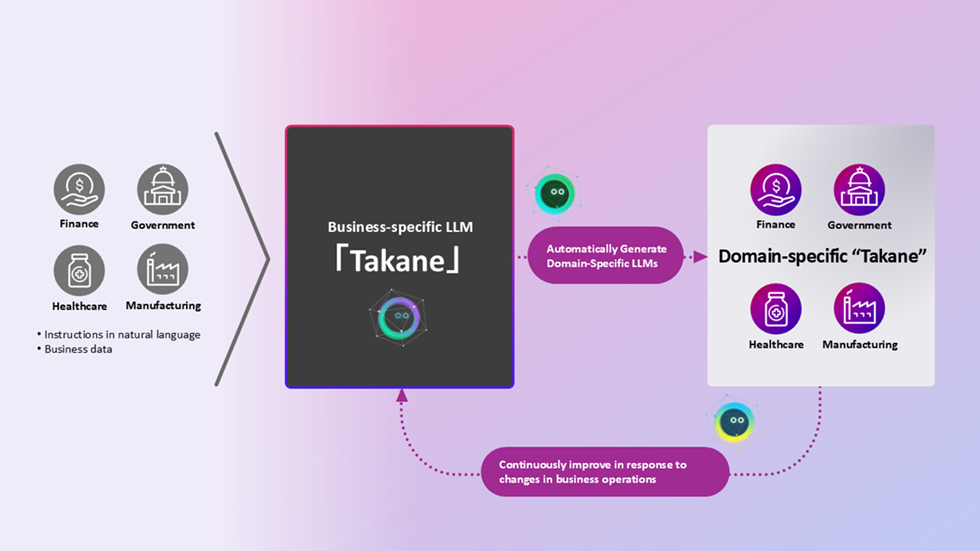
이 루프의 실무 의미는 모델 튜닝 비용입니다. 기업용 LLM의 병목은 base model 호출이 아니라, 현장 규칙과 예외를 모델이 다루게 만드는 과정에 있습니다. 의료 청구, 지방자치단체 행정, 금융 심사, 제조 품질 관리에는 문서와 규칙이 많고, 규칙은 정기적으로 바뀝니다. 모델을 한 번 특화해도 법령, 사내 정책, 서식, 시스템 사양이 바뀌면 답변 기준도 달라집니다. Fujitsu가 노린 지점은 이 지속 조정 비용입니다.
28포인트 개선이라는 숫자는 강하지만, 그대로 일반화하면 안 됩니다. 발표문은 여러 도메인에서 평균 정확도가 개선됐다고 말하지만, 어떤 benchmark set, task distribution, baseline, scoring 방식인지는 제한적으로만 공개돼 있습니다. 따라서 이 숫자는 "Fujitsu가 특정 업무 특화 평가에서 큰 개선을 봤다"는 근거로 읽어야 합니다. 공개 리더보드의 frontier model 비교처럼 읽으면 과장됩니다. 대신 제품 관점에서는 충분히 의미가 있습니다. 엔터프라이즈 AI의 구매자는 종종 모델 이름보다 자사 업무 task에서의 정확도 변화와 운영 비용을 봅니다.
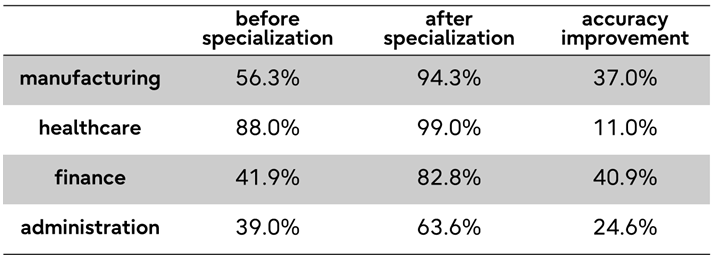
의료 예시는 이 차이를 잘 보여줍니다. Fujitsu는 의무기록과 검사 결과 같은 비정형 데이터에서 진단명, 진행 단계, 치료 방침을 일관된 형식으로 추출하는 사용 사례를 들었습니다. 여기서 모델이 해야 할 일은 일반 의학 지식을 말하는 것이 아닙니다. 특정 병원 업무, 문서 양식, 추출 기준, 누락 허용 범위, 감사 가능한 출력 형식에 맞춰야 합니다. 사람이 계속 바꾸던 기준을 에이전트가 실행 결과와 피드백에서 다시 학습한다면, LLM 운영은 prompt engineering에서 업무 품질 관리에 가까워집니다.
설계서 검색은 레거시 시스템의 현실적인 병목입니다
Fujitsu가 제시한 두 번째 적용처는 대규모 업무 시스템의 설계 사양서 검색입니다. 회사는 중대형 병원 전자의무기록 시스템과 지방자치단체 업무 솔루션에 이 기술을 적용했다고 밝혔습니다. 법 개정이나 정책 변경이 생기면 어떤 기능, 화면, 계산 로직, 데이터 항목이 영향을 받는지 찾아야 합니다. 기존에는 규정, 업무 프로세스, 시스템 구조를 모두 아는 숙련자가 관련 문서를 뒤져 영향 범위를 판단했습니다.
이 작업은 코딩 에이전트 벤치마크보다 덜 화려하지만, 기업 IT에서는 더 흔한 병목입니다. 오래된 업무 시스템은 문서가 여러 형식으로 흩어져 있고, 설계서와 실제 구현이 완전히 일치하지 않을 수 있으며, 같은 규칙이 화면 설명서, DB 정의서, 배치 설계서, 테스트 문서에 중복됩니다. 단순 검색은 keyword가 맞지 않으면 놓칩니다. 반대로 범위를 넓히면 검토할 문서가 너무 많아집니다.
Fujitsu 발표에서 눈에 띄는 부분은 에이전트가 숙련자의 검색 습관을 학습했다는 설명입니다. 예를 들어 과거 검색 결과, 실패 사례, 사람의 수정 내용을 바탕으로 검색 범위 확장과 문서 추출 전략을 개선합니다. 발표문은 에이전트가 "관련 주변 문서를 확인한다"거나 "같은 업무 도메인에 속하면 겉보기에는 관련 없어 보이는 문서도 배제하지 않는다"는 탐색 기법을 적용했다고 설명했습니다. 이것은 모델이 정답을 바로 생성하는 문제가 아니라, 검색의 recall과 precision을 운영 중 조정하는 문제입니다.
이 지점은 AI 코딩 에이전트와도 연결됩니다. Fujitsu는 2026년 2월 AI-Driven Software Development Platform을 발표했습니다. 이 플랫폼은 요구 정의부터 설계, 구현, 통합 테스트까지 자동화하겠다는 제품입니다. 당시 회사는 의료·정부 업무 소프트웨어 67종의 수정에 이 플랫폼을 적용하겠다고 했고, 2024 의료수가 개정 관련 PoC에서 약 3인월 작업을 4시간으로 줄였다고 주장했습니다. 5월 발표의 자기진화 기술은 이 개발 자동화 플랫폼에서 영향 분석과 설계서 검색의 품질을 계속 올리는 하부 루프로 읽을 수 있습니다.
자기진화 에이전트의 안전선은 어디에 있어야 하나
자기개선 에이전트가 기업 업무에 들어가면 위험의 모양이 달라집니다. 일반 agent는 한 번의 작업에서 실수할 수 있습니다. 자기개선 agent는 그 실수를 다음 운영 규칙으로 가져갈 수 있습니다. 잘못된 검색 범위, 편향된 평가 기준, 불완전한 업무 규칙, 오래된 법령 해석이 개선안으로 채택되면 다음 작업의 실패 확률이 올라갑니다. 그래서 이 분야에서 "자동 반영"은 항상 audit, approval, rollback과 같이 논의돼야 합니다.
Fujitsu 발표는 "safe self-evolution"을 제목에 가까운 위치에 놓았지만, 외부 독자가 확인할 수 있는 운영 통제 세부사항은 많지 않습니다. 어떤 개선안이 자동 반영되고 어떤 개선안이 사람 승인을 거치는지, 실패한 개선안을 어떻게 rollback하는지, 업무별 evaluation set이 어떻게 갱신되는지, 고객 환경에 배포된 에이전트가 어떤 로그를 남기는지는 발표문만으로 충분히 알 수 없습니다. 이 빈칸은 제품이 실제 고객 환경에 들어갈 때 가장 먼저 확인돼야 합니다.
개발팀이 참고할 질문은 명확합니다. 첫째, 에이전트가 만든 개선안은 code diff처럼 리뷰 가능한가. 둘째, prompt, retriever, evaluation rule, tool policy 중 무엇이 바뀌었는지 버전으로 남는가. 셋째, 운영 중 정확도가 올라간 것처럼 보일 때 특정 하위 업무에서 recall이 떨어지지 않았는가. 넷째, 규제 문서나 의료 기록처럼 민감한 데이터가 개선 데이터로 들어갈 때 고객 환경 밖으로 나가지 않는가. 다섯째, 잘못된 개선안이 반영된 뒤 몇 번의 작업에 영향을 줬는지 추적할 수 있는가.
| 검증 지점 | Fujitsu 발표의 단서 | 도입팀 질문 |
|---|---|---|
| 개선안 채택 | 효과가 검증된 제안만 반영 | 검증 기준과 승인 주체가 문서화되는가 |
| 업무 데이터 | 고객 환경 배포와 개별 규칙 적응 | 학습·평가 데이터가 환경 밖으로 이동하는가 |
| 검색 전략 | 실패 사례와 사람 수정을 반영 | recall 개선이 noise 증가로 이어지지 않는가 |
| 운영 복구 | 안전한 지속 개선을 강조 | 버전, rollback, 영향 범위 추적이 가능한가 |
이 표는 Fujitsu만의 문제가 아닙니다. Anthropic, OpenAI, Google, Microsoft, IBM, AWS가 모두 기업용 에이전트와 업무 자동화를 팔고 있습니다. 실행 권한이 늘어나면 다음 경쟁 기준은 모델 점수보다 운영 통제입니다. 누가 더 좋은 답을 생성하는가도 중요하지만, 누가 개선 루프를 증거와 로그, 승인, 복구 절차 안에 넣는지가 더 오래 남는 차별점이 됩니다.
on-premises와 edge가 붙는 이유
Fujitsu는 향후 계획에서 이 기술을 proprietary AI platform과 Fujitsu Kozuchi AI platform의 핵심 기술로 통합하겠다고 밝혔습니다. 또 Carnegie Mellon University의 Graham Neubig, Tim Dettmers와의 공동 연구를 언급했습니다. 여기에 Fujitsu의 generative AI reconstruction technology를 결합해 메모리와 전력 사용을 줄인 self-evolving multi-AI agent system을 개발하겠다고 했습니다. 목표 환경은 cloud뿐 아니라 highly confidential on-premises와 edge입니다.
이 계획은 Fujitsu의 고객층과 맞습니다. 병원, 공공기관, 금융사, 제조사는 데이터와 시스템을 모두 public cloud에 올리기 어렵습니다. 업무 기록, 환자 정보, 설계 자산, 규제 문서는 외부 전송 제한이 걸릴 수 있습니다. 자기개선 에이전트가 업무 실패와 사람 수정을 학습하려면 더 민감한 로그를 다룹니다. 그래서 on-premises와 edge에서 돌아가는 경량화된 multi-agent system은 단순 배포 옵션이 아니라 영업 조건입니다.
여기서도 tradeoff가 있습니다. 고객 환경 내부에서 지속 학습하면 데이터 주권과 기밀성에는 유리합니다. 반면 중앙 플랫폼에서 모델과 평가 도구를 빠르게 갱신하기 어렵고, 고객별 환경 차이가 커질수록 운영 지원 비용이 늘어납니다. 자기개선 루프가 고객마다 다르게 진화하면, 벤더는 어떤 버전이 어떤 규칙으로 움직이는지 추적해야 합니다. Fujitsu가 OneFujitsu initiative와 global standard process를 함께 언급한 것도 이 문제와 닿아 있습니다. 표준화된 업무 프로세스가 있어야 에이전트 개선 루프도 비교 가능해집니다.
개발자에게 남는 실무 신호
이번 발표는 일반 개발자가 당장 쓸 수 있는 SDK 출시 소식은 아닙니다. 그래도 AI 제품을 만드는 팀에게는 몇 가지 신호가 있습니다. 첫째, 에이전트의 가치가 작업 수행에서 작업 품질 개선으로 확장되고 있습니다. 둘째, enterprise AI에서 좋은 RAG나 tool calling만으로는 부족하고, 검색 전략과 평가 기준 자체를 운영 중 업데이트하는 체계가 필요합니다. 셋째, 자기개선 기능은 반드시 evidence, evaluation, human correction, versioning과 묶여야 합니다.
특히 AI coding agent와 내부 업무 자동화 제품을 만드는 팀은 "에이전트가 실패한 뒤 무엇이 남는가"를 설계해야 합니다. 실패 로그가 단순 에러 메시지로 끝나면 다음 작업은 나아지지 않습니다. 반대로 실패 로그가 검증 없이 prompt나 정책에 들어가면 drift가 생깁니다. Fujitsu식 접근에서 배울 점은 실패를 학습 신호로 보되, 반영 전 검증 단계를 제품 구조에 넣는다는 점입니다. 이 원칙은 병원 설계서 검색뿐 아니라 코드 리뷰, 보안 triage, 고객 지원, 재무 분석 에이전트에도 적용됩니다.
커뮤니티 반응은 아직 크지 않습니다. Hacker News와 주요 Reddit AI 커뮤니티에서 이번 발표 자체에 대한 깊은 토론은 확인되지 않았고, 검색 결과는 일본·중국권 뉴스 요약이나 Fujitsu 공식 자료 재게재가 대부분이었습니다. 이는 Fujitsu 발표가 OpenAI나 Anthropic의 모델 업데이트처럼 즉시 개발자 담론을 흔들지는 않았다는 뜻입니다. 하지만 조용한 발표가 의미 없다는 뜻은 아닙니다. 일본 대형 SI와 공공·의료 업무 시스템에서 나온 AI 자동화 사례는, 에이전트가 실제 레거시 시스템에 들어갈 때 어떤 문제가 먼저 나타나는지 보여주는 자료가 됩니다.
Fujitsu의 자기진화 에이전트가 성공하려면 28포인트라는 숫자 다음의 질문에 답해야 합니다. 어떤 업무에서, 어떤 데이터와 평가 기준으로, 얼마나 오래 개선 효과가 유지됐는가. 잘못된 개선안은 어떻게 걸러졌는가. 고객 환경마다 달라지는 규칙을 어떻게 버전 관리하는가. 사람이 마지막으로 승인해야 하는 경계는 어디인가. 이 질문에 답할 수 있을 때 self-evolving agent는 마케팅 문구가 아니라 운영 가능한 AI 시스템이 됩니다.
지금 AI 에이전트 시장은 더 많은 도구 호출, 더 긴 작업 시간, 더 넓은 권한으로 움직이고 있습니다. Fujitsu 발표는 그 다음 질문을 던집니다. 에이전트가 스스로 배운다면, 무엇을 근거로 배웠는지 누가 확인할 것인가. Takane의 28포인트 개선은 그 질문을 피하지 않고 정면에 세운 사례입니다. 자기개선 에이전트의 안전한 좁은 길은 더 많은 자동화가 아니라, 개선안이 업무 근거와 평가를 통과한 뒤에만 운영 규칙이 되는 구조에서 시작합니다.