Decepticon 1.1.3 공개, 레드팀 에이전트의 안전장치 시험
Decepticon 1.1.3은 자동 해킹 데모보다 RoE, 샌드박스, 지식 그래프, 릴리스 검증이 더 중요한 레드팀 에이전트 사례입니다.

- 무슨 일: PurpleAILAB의 오픈소스
Decepticon이 2026년 5월 27일v1.1.3을 공개했습니다.- 최신 릴리스는 Windows 설치, Podman/nerdctl 감지, Ghidra backend, 76개 skill playbook, runtime fix를 포함합니다.
- 의미: 레드팀 에이전트 경쟁의 기준이 모델 답변이 아니라 RoE, sandbox, graph, release integrity로 이동합니다.
- 주의점: 실제 공격 도구와 C2를 다루므로 승인된 환경, 로그, 범위 통제, 법적 책임을 먼저 봐야 합니다.
- README의 disclaimer도 명시적 서면 승인 없는 시스템이나 네트워크에서 사용하지 말라고 적습니다.
PurpleAILAB의 오픈소스 프로젝트 Decepticon이 2026년 5월 27일 v1.1.3을 공개했습니다. GitHub release API 기준 최신 릴리스의 published_at은 2026-05-27T08:43:51Z입니다. 저장소는 조사 시점에 약 4.1k stars와 809 forks를 표시했고, README는 Decepticon을 "Autonomous Red Team Agent"로 소개합니다. 이 뉴스가 AI 개발자에게 흥미로운 이유는 "AI가 해킹한다"는 문구보다, 위험한 실행 권한을 가진 에이전트가 어떤 운영 장치를 갖춰야 하는지를 보여주기 때문입니다.
Decepticon의 README는 자신을 "nmap을 실행하고 보고서를 쓰는 또 하나의 AI 해커"가 아니라고 설명합니다. 프로젝트가 내세우는 차이는 공격 체인 그 자체보다 engagement package입니다. 에이전트는 패킷을 내보내기 전에 RoE, ConOps, Deconfliction Plan, OPPLAN과 MITRE ATT&CK mapping을 만든다고 되어 있습니다. 이 구조는 자동화된 보안 도구를 "스캐너"가 아니라 "규칙과 목표를 가진 작업자"로 취급합니다.
이번 v1.1.3은 단순 패치 릴리스처럼 보이지만, changelog의 내용은 제품 표면을 넓히는 방향입니다. Windows PowerShell 설치 경로가 추가됐고, Go launcher는 OS, architecture, distro, Docker readiness system check를 onboard 단계에 넣었습니다. Docker만 전제하던 실행 환경에는 Podman과 nerdctl 자동 감지가 들어갔습니다. 리버스엔지니어링 쪽에는 Ghidra 12.1 headless backend와 optional MCP bridge sidecar가 추가됐습니다.
릴리스에서 더 큰 면적은 skill과 runtime입니다. Changelog는 76개 신규 skill playbook을 추가했다고 적습니다. 범위는 Active Directory, Cloud, Smart Contract, Web Exploit, LLM Red Team, Mobile, Reverser, Supply Chain, Modern API, ICS-OT, C2까지 넓습니다. 동시에 Soundwave interview loop, Codex/ChatGPT OAuth handler, streaming event, sandbox zombie process가 수정됐습니다. LiteLLM truncated tool use, CVE lookup timeout, web dashboard, CLI TUI 문제도 같은 릴리스에 들어갔습니다. 공격 표면을 넓힌 만큼 운영 오류를 줄이는 작업도 같은 릴리스에 묶인 셈입니다.

Architecture 문서에서 가장 먼저 봐야 할 부분은 네트워크 분리입니다. Decepticon은 management infrastructure와 operational infrastructure를 decepticon-net과 sandbox-net이라는 두 Docker network로 나눕니다. LiteLLM, PostgreSQL, LangGraph, web dashboard는 management 쪽에 있고, Kali sandbox, C2 server, victim targets는 operational 쪽에 있습니다. 문서는 sandbox가 LiteLLM, PostgreSQL, LangGraph API, web dashboard로 라우팅되지 않는다고 설명합니다.
이 분리는 레드팀 에이전트에서 필수에 가깝습니다. 공격 도구가 실행되는 sandbox가 LLM gateway나 provider credential을 직접 볼 수 있으면, 타깃 시스템에서 얻은 입력이나 compromised process가 관리 계층으로 피벗할 수 있습니다. Decepticon은 LangGraph가 sandbox를 TCP가 아니라 Docker socket을 통해 조작하고, Neo4j만 양쪽 network에 걸쳐 finding을 주고받는 공유 지점으로 둔다고 설명합니다. Neo4j는 agent credential을 전달하는 서비스가 아니라 attack graph를 위한 knowledge store로 제한됩니다.
Agent 설계도 긴 작업을 의식합니다. Docs는 16개 specialist agent가 kill chain phase별로 구성된다고 설명합니다. Orchestrator인 Decepticon은 OPPLAN을 읽고 recon, exploit, postexploit, analyst, reverser, contract auditor, cloud hunter, ad operator 같은 specialist에게 objective를 위임합니다. Vulnresearch는 scanner, detector, verifier, patcher, exploiter의 five-stage pipeline을 갖습니다. Soundwave는 engagement planner로 RoE, Threat Profile, CONOPS, Deconfliction, Contact, Data Handling, Abort, Cleanup 문서를 만드는 역할입니다.
여기서 눈에 띄는 설계는 fresh context model입니다. 각 specialist agent는 objective마다 clean context window로 시작하고, finding은 대화 메모리 대신 disk와 knowledge graph에 남깁니다. 장기 작업을 한 대화창에 계속 밀어 넣으면 토큰 비용, 오래된 추론, 맥락 오염이 동시에 생깁니다. Decepticon은 이를 sub-agent와 graph persistence로 나눠 처리합니다. 최근 코딩 에이전트 제품이 "작업마다 새 세션, 결과는 diff와 로그로 보존"하는 쪽으로 가는 것과 같은 이유입니다.
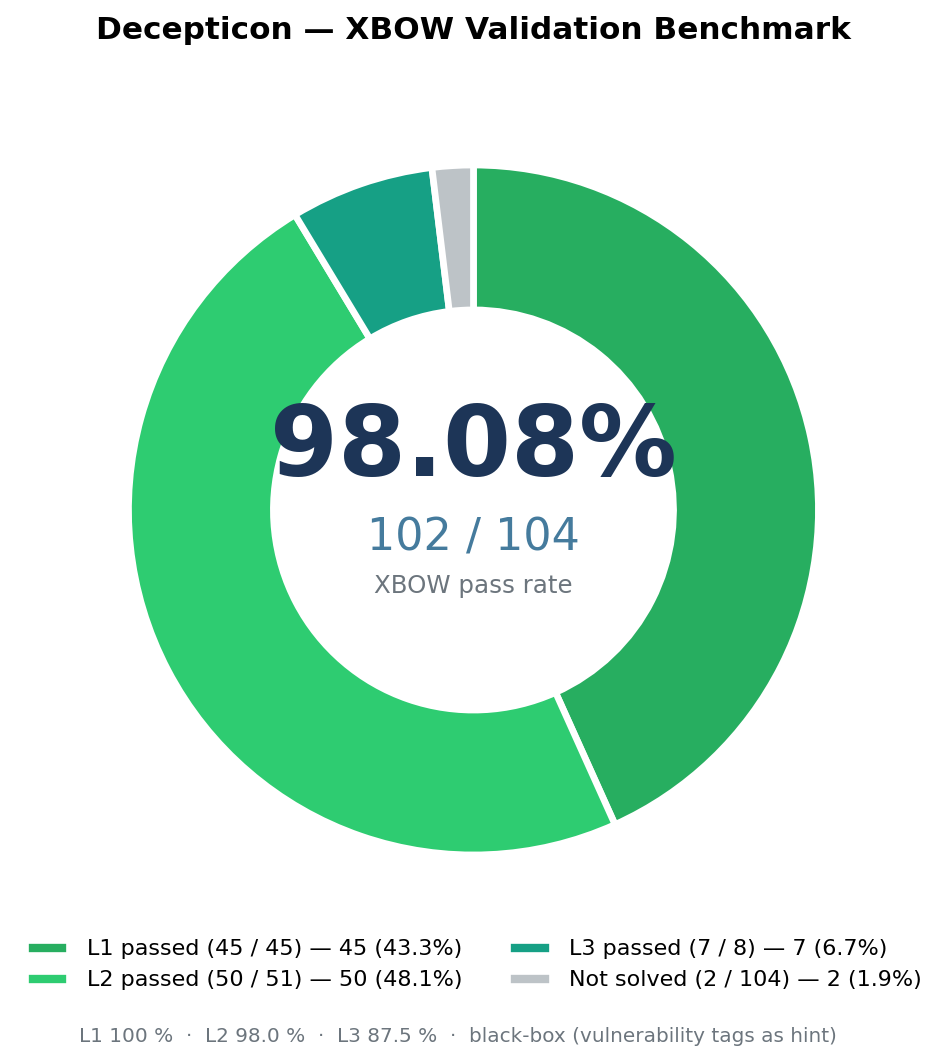
README의 benchmark claim은 강하게 보입니다. Decepticon은 XBOW validation-benchmarks에서 Easy 45/45, Medium 50/51, Hard 7/8, 전체 102/104로 98.08% pass rate를 주장합니다. 이 수치는 레드팀 에이전트가 단순 데모가 아니라 반복 평가를 받는 제품처럼 포장되고 있음을 보여줍니다. 다만 benchmark는 실제 기업 네트워크, 법적 범위, 운영 로그, 복구 책임, 방어팀 협업까지 재현하지 않습니다. 따라서 숫자는 성능 주장으로 읽되, 구매나 도입 판단의 전체 근거로 삼기에는 부족합니다.
v1.1.3에서 Windows 지원이 들어간 점도 가볍지 않습니다. 레드팀 도구는 오랫동안 Linux나 Kali 중심으로 배포되는 경우가 많았습니다. Decepticon은 macOS, Linux, Windows, WSL2를 README에서 지원 대상으로 적고, 이번 릴리스는 native Windows installer와 windows_amd64, windows_arm64 artifacts를 포함합니다. 이는 보안 연구자만이 아니라 플랫폼팀, 컨설팅팀, 내부 red team이 각자 다른 로컬 환경에서 같은 agent runtime을 띄우는 그림을 겨냥합니다.
Podman과 nerdctl 지원은 enterprise 환경을 의식한 변화입니다. 일부 조직은 Docker Desktop 라이선스, root daemon, 보안 정책 때문에 Docker 대신 Podman이나 containerd 계열 도구를 씁니다. Changelog는 launcher가 docker, podman, nerdctl 순서로 reachable runtime을 감지하고 DECEPTICON_CONTAINER_RUNTIME override를 제공한다고 적습니다. AI 에이전트가 실제 보안팀 도구가 되려면 모델 호출보다 먼저 조직의 container runtime 정책을 통과해야 합니다.
Ghidra backend와 reversing sidecar는 Decepticon의 범위가 웹 스캐닝을 넘어 binary analysis로 넓어진다는 신호입니다. Changelog는 ghidra_analyze, ghidra_decompile, ghidra_xrefs, ghidra_status 도구를 언급합니다. 기본 sandbox image가 무거워지지 않도록 INSTALL_REVERSING=false 뒤에 두고, reversing compose profile에서 sidecar를 opt-in하는 방식입니다. 이 설계는 공격 기능을 무작정 기본값에 넣지 않고, 비용과 위험이 큰 기능을 profile로 분리한다는 점에서 의미가 있습니다.
Model strategy도 단일 모델 데모와 다릅니다. README는 Anthropic, OpenAI, Google Gemini, MiniMax, DeepSeek, xAI, Mistral, OpenRouter, Nvidia NIM, Ollama local을 tier-mapped provider로 나열합니다. Subscription OAuth에는 Claude Max/Pro/Team, ChatGPT Pro/Plus/Team, Gemini Advanced, Copilot Pro, SuperGrok, Perplexity Pro가 들어갑니다. Profile은 eco, max, test로 나뉘고, orchestrator나 exploiter에는 높은 tier를 쓰고 recon에는 낮은 tier를 쓰는 식의 비용 조절을 설명합니다.
이 부분은 레드팀 에이전트의 경제성을 가르는 지점입니다. 취약점 분석, exploit chain 구성, 보고서 작성은 모두 토큰을 많이 씁니다. 모든 agent를 frontier model에 고정하면 비용과 rate limit이 먼저 터집니다. 반대로 너무 약한 모델을 쓰면 잘못된 공격 가설, 오탐, 실패한 검증이 늘어납니다. Decepticon의 tier와 fallback은 "어떤 모델이 가장 똑똑한가"보다 "어떤 objective에 어떤 모델 비용을 배정할 것인가"라는 운영 질문을 앞으로 밀어냅니다.
Release process도 볼 만합니다. RELEASE.md는 PyPI Trusted Publishing, GoReleaser artifacts, GHCR multi-arch images, Cosign keyless signing, CycloneDX SBOM, :latest promotion 조건을 설명합니다. 최신 release API에도 여러 CycloneDX JSON asset과 OS별 launcher binary가 보입니다. offensive security tool이 AI 에이전트로 포장될수록 공급망 신뢰가 더 중요해집니다. 사용자는 agent가 무엇을 공격할 수 있는지만이 아니라, agent runtime 자체가 어디서 빌드됐고 어떤 image와 binary가 배포됐는지도 확인해야 합니다.
커뮤니티 반응은 아직 대형 모델 발표 수준은 아닙니다. GeekNews 첫 화면에는 2026년 5월 28일 KST 기준 "Decepticon - 레드팀을 위한 자율 해킹 에이전트"가 올라왔고 약 10시간 전 게시물로 15 points가 보였습니다. 소개문은 nmap 실행 후 보고서를 출력하는 데모와 다르게 전문 레드팀 운영을 수행한다고 요약했습니다. 같은 시점 Hacker News 첫 화면에서는 YouTube AI 라벨링, Anthropic과 OpenAI의 product-market fit 논쟁, AI 대화 피로 같은 항목이 강했고 Decepticon은 확인되지 않았습니다.
보안팀 입장에서 실무 질문은 분명합니다. 첫째, Decepticon 같은 에이전트가 작성한 RoE와 OPPLAN을 사람이 어떤 단계에서 승인할 것인가입니다. 둘째, sandbox에서 나온 finding과 command log를 감사 가능한 증거로 보존할 수 있는가입니다. 셋째, C2와 exploitation 기능을 실제 고객 환경에서 켤 때 legal authorization, target scope, abort condition을 어떻게 강제할 것인가입니다. 넷째, model provider로 외부 API를 쓸 때 target metadata와 finding이 어떤 경로로 이동하는지 확인해야 합니다.
개발자에게도 이 사례는 남의 이야기가 아닙니다. 코딩 에이전트가 test runner와 package manager를 다루는 것과 레드팀 에이전트가 Kali sandbox와 C2를 다루는 것은 권한의 종류만 다를 뿐, 제품 설계 질문은 비슷합니다. 실행은 어디서 일어나는가. 장기 기억은 어디에 남는가. 실패하면 누가 중단시키는가. 결과가 잘못됐을 때 어떤 log로 되돌아보는가. Decepticon은 이 질문을 security domain의 더 날카로운 환경에서 보여줍니다.
오남용 위험은 기사에서 빼면 안 됩니다. README의 disclaimer는 명시적 서면 승인 없는 시스템이나 네트워크에서 사용하지 말라고 적습니다. 이 문장은 법적 면책 문구이지만, 실제 제품 요구사항으로도 읽어야 합니다. 자율 레드팀 도구는 데모 영상보다 approval workflow, target registry, network egress policy, credential isolation, report redaction, emergency stop이 먼저 설계돼야 합니다. 공격 도구의 성능이 올라갈수록 통제 장치의 품질이 제품의 핵심 기능이 됩니다.
Decepticon 1.1.3이 당장 모든 조직에 필요한 도구라는 뜻은 아닙니다. 오히려 많은 팀에는 너무 이른 도구일 수 있습니다. 하지만 이번 릴리스는 AI 보안 에이전트가 어디로 가는지 보여줍니다. 모델 호출을 감싼 CLI가 아니라, engagement 문서, specialist agent, sandbox, graph, runtime profile, release signing, SBOM까지 묶인 운영 패키지입니다. 레드팀 에이전트의 경쟁력은 더 위험한 명령을 실행하는 능력보다, 위험한 명령을 언제, 어디서, 누구의 승인 아래 실행하지 않을지 증명하는 능력에서 갈릴 가능성이 높습니다.