DiffusionGemma 공개, 256토큰 병렬 생성의 속도 조건
Google이 DiffusionGemma를 공개했습니다. 256토큰 canvas, vLLM 지원, 18GB VRAM 조건이 로컬 추론 병목을 어떻게 바꾸는지 봅니다.

- 무슨 일: Google이 2026년 6월 10일 DiffusionGemma를 Apache 2.0 open model로 공개했습니다.
- Gemma 4 기반 26B MoE 모델이며 추론 때는 3.8B parameters만 활성화합니다.
- 작동 방식: 한 token씩 쓰지 않고
256-token canvas를 병렬로 고칩니다. - 속도 조건: H100 1000+ tokens/s, RTX 5090 700+ tokens/s가 기준입니다.
- 이 이점은 low-to-medium batch, dedicated GPU, local interactive workflow에서 가장 큽니다.
- 주의점: Google은 최고 품질 output에는 여전히 standard Gemma 4를 추천합니다.
Google이 2026년 6월 10일 DiffusionGemma를 공개했습니다. 발표문은 이 모델을 "text diffusion을 탐색하는 experimental open model"이라고 부릅니다. 라이선스는 Apache 2.0이고, 모델은 Gemma 4 backbone 위에 만들어진 26B Mixture of Experts입니다. 추론 때 활성화되는 parameter는 3.8B입니다. 숫자보다 더 중요한 변화는 decoding 방식입니다. DiffusionGemma는 일반 LLM처럼 token을 왼쪽에서 오른쪽으로 하나씩 쓰지 않습니다. 256-token canvas를 잡고 여러 위치를 동시에 고치면서 문장을 완성합니다.
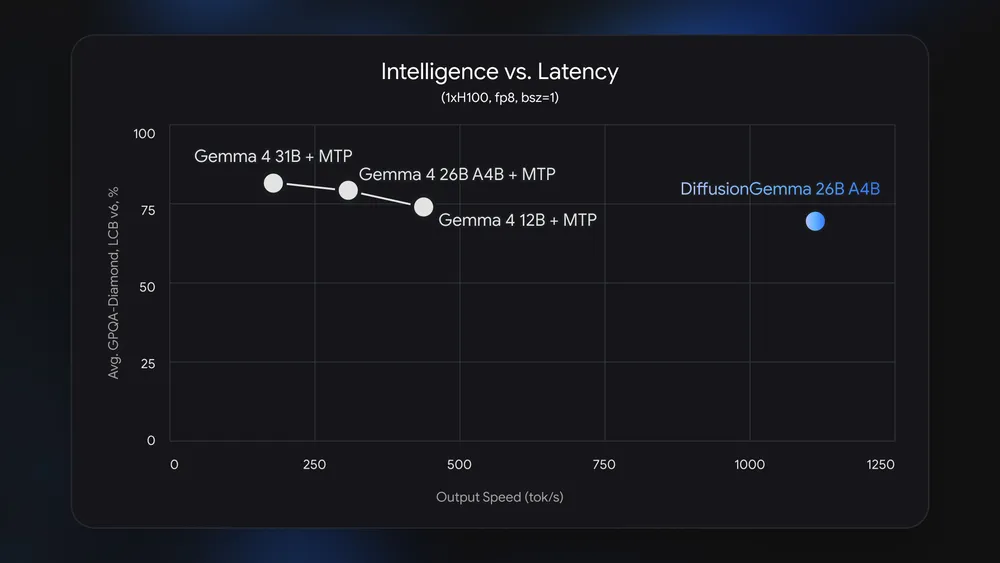
이번 발표는 모델 이름보다 serving 병목에 관한 뉴스입니다. Google은 DiffusionGemma가 dedicated GPU에서 최대 4배 빠른 token output을 낸다고 설명했습니다. 수치는 NVIDIA H100에서 1000+ tokens/s, GeForce RTX 5090에서 700+ tokens/s입니다. 같은 글은 quantized deployment가 18GB VRAM 안에 들어간다고 적었습니다. 로컬 개발자가 RTX 4090/5090 같은 dedicated GPU에서 inline editing, code infilling, 짧은 interactive agent response를 만들 때 의미가 있습니다. memory bandwidth에 막히는 autoregressive generation 대신 compute를 더 많이 쓰는 경로를 시험할 수 있기 때문입니다.
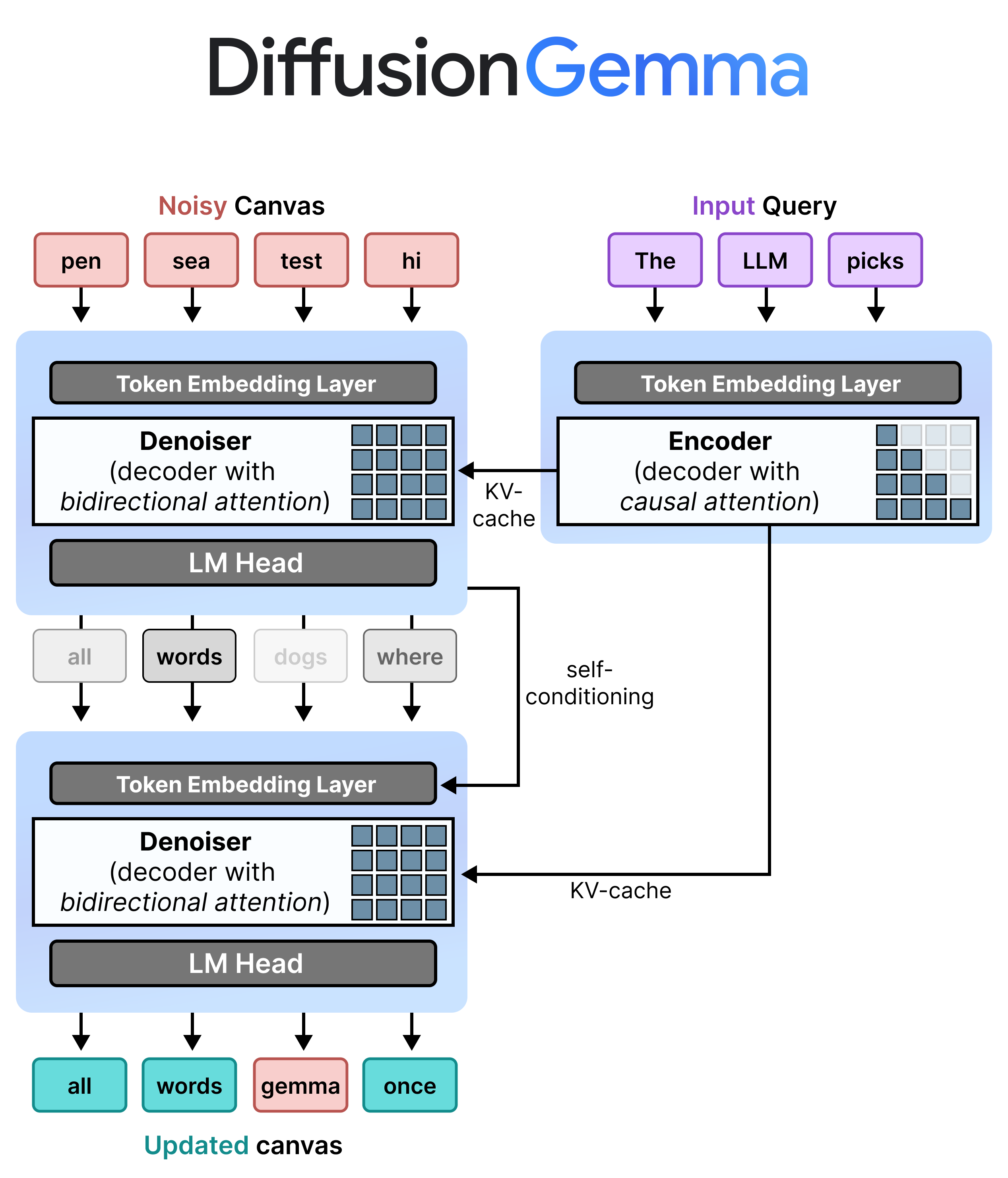
DiffusionGemma의 핵심은 "빠른 모델"이라는 말만으로는 설명되지 않습니다. 기존 autoregressive model은 다음 token을 예측하고, 그 token을 다시 context에 넣고, 다음 token을 예측합니다. cloud serving에서는 수천 request를 batch로 묶어 GPU를 채울 수 있습니다. 그러나 로컬에서 한 명이 쓰는 경우 GPU가 다음 token을 기다리는 시간이 많아집니다. Google은 이 문제를 memory-bandwidth bottleneck으로 설명합니다. DiffusionGemma는 256-token block 전체를 작업 단위로 만들어 tensor core에 더 큰 병렬 workload를 줍니다.
Google Developers Blog의 개발자 가이드는 과정을 더 구체적으로 설명합니다. 처음에는 random placeholder token으로 canvas를 채웁니다. 모델은 denoising pass를 돌며 각 위치의 candidate token을 예측합니다. 확신도가 높은 token은 고정되고, 확신이 낮은 위치는 다시 random token으로 바뀌어 다음 step에서 재평가됩니다. 충분히 수렴하면 256-token block을 commit하고, 그 결과를 KV cache에 넣은 뒤 다음 block을 시작합니다.
이 방식은 완전히 비순차적인 생성이 아닙니다. block 안에서는 bidirectional attention을 써서 canvas의 모든 위치가 서로를 볼 수 있습니다. block 사이에서는 이전 block을 조건으로 다음 block을 만드는 left-to-right 구조가 남습니다. 그래서 Google은 이를 block autoregressive denoising으로 설명합니다. 256-token 안에서는 확산 모델처럼 동시에 고치고, 256-token을 넘는 긴 출력에서는 이미 확정한 block을 기반으로 다음 canvas를 엽니다. 기존 LLM serving stack을 모두 버리지 않으면서 diffusion의 병렬성을 가져오려는 절충입니다.
 .
.
vLLM 팀과 Google DeepMind 팀이 같은 날 공개한 구현 글은 이 절충이 왜 중요한지 보여줍니다. vLLM은 DiffusionGemma를 native support하는 첫 diffusion LLM이라고 소개했습니다. dLLM은 standard autoregressive serving path에 잘 맞지 않습니다. bidirectional attention, iterative refinement, block-based generation, custom sampling state가 필요하기 때문입니다. vLLM은 ModelState abstraction으로 request마다 별도 상태를 들고 갑니다. 그 상태에는 canvas, denoising phase, commit phase, self-conditioning probability가 포함됩니다.
serving 쪽에서 가장 까다로운 부분은 attention mode가 request마다 달라진다는 점입니다. prefill과 commit은 causal attention을 씁니다. denoising canvas는 bidirectional attention을 씁니다. 한 batch 안에는 prompt를 읽는 request, canvas를 고치는 request, block을 commit하는 request가 섞일 수 있습니다. vLLM 글은 이를 위해 dynamic per-sequence causal attention을 구현했습니다. Triton Attention과 FlashAttention 4 backend에서는 request별 causality tensor를 쓰도록 바꿨습니다.
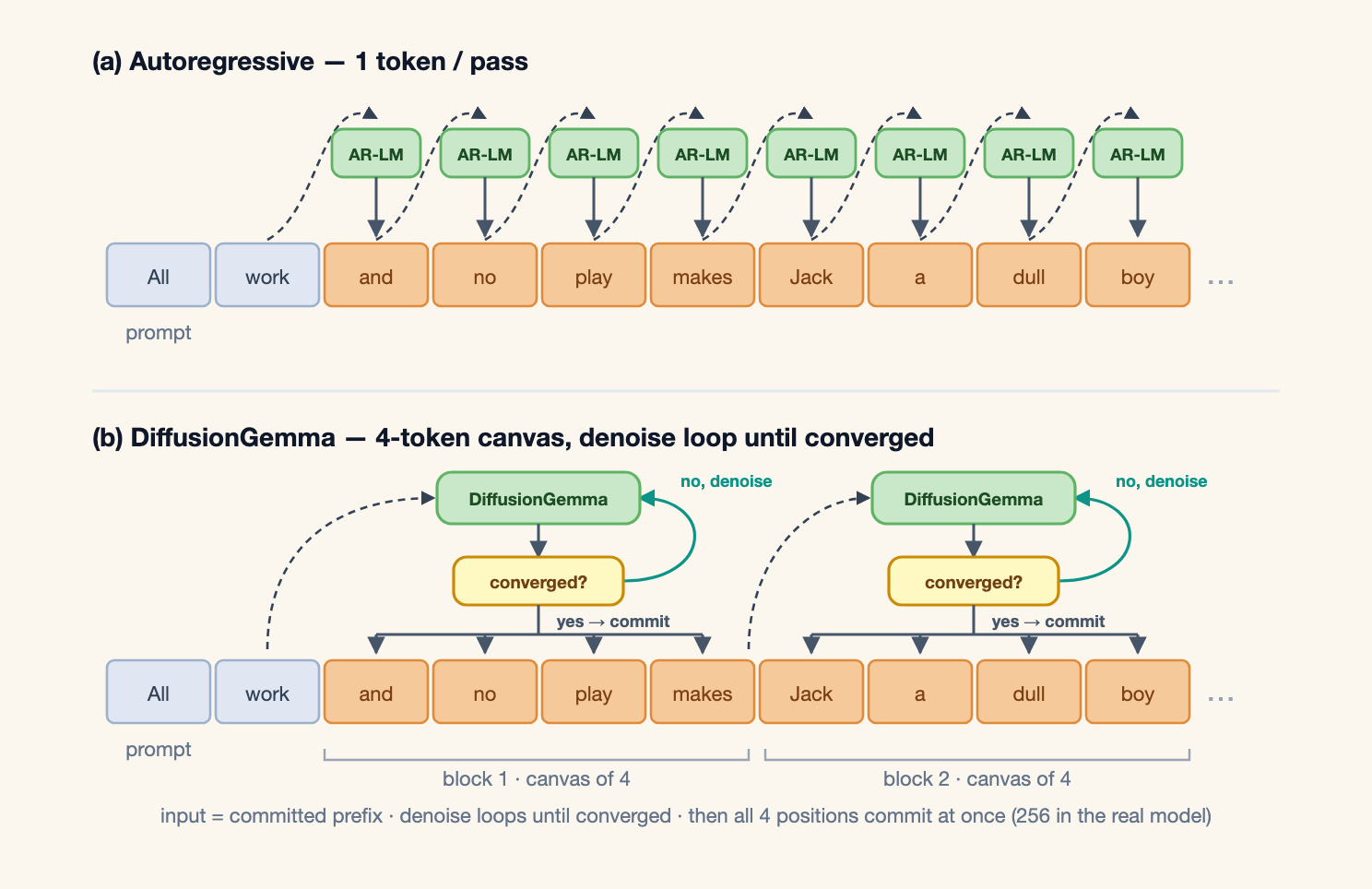
이 구현은 speculative decoding path와도 연결됩니다. vLLM은 DiffusionGemma의 canvas를 "매 step마다 큰 draft token set을 만들고, 이를 받아들이거나 버리는 과정"으로 해석했습니다. 그래서 mature한 speculative decoding accounting을 재사용하고, scheduler와 model runner의 큰 변경을 줄였습니다. denoise step에서는 num_sampled = 0으로 보고해 KV cache position을 움직이지 않고, commit step에서 clean argmax canvas 256 tokens를 emit합니다. diffusion model을 serving framework에 넣는 첫 실전 blueprint에 가깝습니다.
성능 수치도 vLLM 글이 더 공격적입니다. vLLM 팀은 FP8 DiffusionGemma가 H200에서 1,288 generation tokens/s를 기록했다고 밝혔습니다. 이는 standard autoregressive baseline의 약 6배, multi-token prediction baseline의 약 3배입니다. H100에서는 1,008 tokens/s로 standard autoregressive baseline의 약 5배, MTP baseline의 약 2.6배라고 설명했습니다. 이 수치는 batch size 1의 interactive setting에서 나온 결과입니다. 고QPS cloud serving에서 이미 큰 batch로 GPU를 채우는 상황과 같은 의미로 읽으면 안 됩니다.
Google도 이 한계를 숨기지 않았습니다. 발표문은 DiffusionGemma의 speedup이 local and low-concurrency inference에 맞춰져 있다고 적었습니다. high-QPS cloud serving에서는 autoregressive model이 batch를 통해 compute를 충분히 포화할 수 있습니다. 이 경우 diffusion의 이점은 줄고 serving cost가 높아질 수 있습니다. 또 Apple Silicon Mac 같은 unified-memory architecture는 inference가 memory bandwidth bound인 경우가 많습니다. 그래서 Gemma 4 같은 autoregressive model 대비 같은 acceleration을 보지 못할 수 있다고 주석을 달았습니다.
품질 trade-off도 명시돼 있습니다. Google은 DiffusionGemma가 speed와 parallel layout generation을 우선하며, overall output quality는 standard Gemma 4보다 낮다고 설명했습니다. maximum quality가 필요한 application에는 standard Gemma 4를 배포하라고 권했습니다. 따라서 DiffusionGemma를 "Gemma 4의 상위 모델"로 보면 틀립니다. 더 정확한 분류는 "interactive latency가 더 중요한 특정 workflow를 위한 open experimental architecture"입니다.
개발자가 봐야 할 실무 사용처는 세 가지입니다. 첫째, code infilling입니다. 함수 중간, Markdown table, JSON block, HTML/CSS snippet처럼 앞뒤 문맥을 동시에 봐야 하는 작업이 여기에 들어갑니다. 이런 작업은 left-to-right generation보다 bidirectional denoising이 유리할 수 있습니다. 둘째, inline editing입니다. 사용자가 이미 쓴 문단을 조금씩 고치는 UI에서는 256-token canvas가 앞뒤 제약을 한 번에 고려할 수 있습니다. 셋째, constrained text structure입니다. Google 개발자 가이드는 Sudoku fine-tuning 예시를 들었습니다. 행과 열, 3x3 grid 제약이 얽힌 문제에서 bidirectional context propagation이 왜 맞는지 설명하기 위해서입니다.
Sudoku 예시는 장난처럼 보이지만, 모델의 성격을 잘 드러냅니다. Google은 base DiffusionGemma가 Sudoku를 풀도록 훈련되지 않았을 때 성공률이 거의 0%였다고 밝혔습니다. Hackable Diffusion 기반의 단순 SFT recipe를 적용하자 correctness는 80%까지 올라갔습니다. 동시에 inference step count도 줄었습니다. 여기서 얻을 수 있는 실무 힌트는 구체적입니다. diffusion LLM은 범용 chat model보다 특정 형식의 빠른 refinement task에 fine-tune할 때 더 설득력이 생깁니다.
NVIDIA도 같은 날 최적화 글을 냈습니다. NVIDIA는 DiffusionGemma가 text를 병렬 생성하며 RTX PRO platform, DGX Spark systems, GeForce RTX GPUs에 맞춰 최적화됐다고 설명했습니다. Google 발표문도 NVIDIA와 함께 consumer setup인 RTX 4090/5090부터 Hopper, Blackwell, DGX Spark, DGX Station까지 hardware stack을 맞췄다고 적었습니다. open model 발표이지만 실제 메시지는 "로컬 AI PC와 desk-side AI workstation에서 어떤 decoding path가 맞는가"에 가깝습니다.
배포 경로는 넓게 열려 있습니다. Google은 Hugging Face weight, vLLM, Hugging Face Transformers, SGLang, MLX, Google Cloud Model Garden, NVIDIA NIM을 언급했습니다. 공식 support for llama.cpp는 "arriving soon"이라고만 밝혔습니다. 오늘 바로 실험하려는 팀이라면 vLLM의 OpenAI-compatible local server가 가장 문서화된 경로입니다. 개발자 가이드의 예시는 vllm serve google/diffusiongemma-26B-A4B-it에 --diffusion-config '{"canvas_length": 256}'와 entropy-bound sampler 설정을 붙입니다.
커뮤니티 반응은 속도 숫자보다 조건에 집중했습니다. GeekNews에는 "DiffusionGemma: 4배 빠른 텍스트 생성"으로 올라왔습니다. r/LocalLLaMA 토론에서는 "Gemini Flash도 이미 수천 tokens/s를 말하지 않았느냐"는 질문이 나왔습니다. "이 속도는 어떤 hardware와 batch 조건에서 나온 것이냐", "Unsloth나 GGUF로 로컬에서 바로 돌릴 수 있느냐"는 반응도 이어졌습니다. 이 반응은 건강합니다. DiffusionGemma의 가치가 headline throughput이 아니라 workload shape와 deployment condition에 달려 있기 때문입니다.
이번 공개가 MTP나 speculative decoding을 바로 대체한다고 보기도 어렵습니다. MTP는 작은 draft나 여러 token prediction으로 autoregressive path를 가속합니다. DiffusionGemma는 256-token canvas 전체를 iterative denoising 대상으로 삼습니다. vLLM benchmark에서 diffusion은 MTP baseline보다도 빠른 수치를 보였습니다. 다만 이 비교는 batch size 1과 FP8/H100/H200 조건에 묶여 있습니다. production router는 작업을 나누는 편이 현실적입니다. 짧은 interactive completion은 DiffusionGemma, 품질이 중요한 reasoning은 Gemma 4 또는 frontier model, 긴 대량 batch는 기존 AR serving으로 보내는 식입니다.
AI coding tool 관점에서는 prompt architecture도 달라집니다. 기존 completion은 "다음 token"을 잘 만들도록 context를 앞에 쌓습니다. DiffusionGemma가 강해지는 작업은 빈칸이 중간에 있거나, 앞뒤 constraint가 동시에 중요한 작업입니다. editor extension이 selection 주변 code, type error, test failure, desired patch shape를 canvas에 넣는 방식은 실험해볼 만합니다. 이렇게 하면 여러 후보를 빠르게 refinement할 수 있습니다. 반대로 긴 chain-of-thought가 필요한 planning, repository-wide reasoning, multi-file refactor 판단은 품질과 tool-use 안정성이 더 중요합니다. 이런 작업은 DiffusionGemma만으로 해결될 가능성이 낮습니다.
운영팀이 확인해야 할 지표는 네 가지입니다. 첫째, latency가 token throughput이 아니라 first useful edit time으로 줄어드는지입니다. 1000 tokens/s라도 denoising step과 commit 구조가 UI 체감 시간을 줄이지 못하면 의미가 작습니다. 둘째, quality regression입니다. standard Gemma 4 대비 factuality, instruction following, code correctness가 어느 정도 떨어지는지 task별로 봐야 합니다. 셋째, hardware utilization입니다. Google이 말한 이점은 dedicated GPU의 spare compute를 쓰는 데서 나오므로, Apple Silicon이나 CPU offload 환경에서는 다시 측정해야 합니다. 넷째, cost per accepted edit입니다. 빠르게 많이 생성해도 사용자가 버리는 후보가 늘면 비용 절감이 아닙니다.
DiffusionGemma의 뉴스 가치는 "텍스트 확산이 드디어 모든 LLM을 대체한다"가 아닙니다. 더 좁고 실용적인 변화입니다. Google과 vLLM이 discrete diffusion language model을 open weights, Apache 2.0, vLLM native serving, NVIDIA optimization, Hugging Face distribution으로 한 번에 묶었습니다. 연구 아이디어가 로컬 developer workflow에서 바로 시험 가능한 artifact가 됐습니다. 실패하더라도 의미가 있습니다. AI inference 경쟁이 더 큰 context와 더 강한 reasoning만이 아니라, decoding path와 hardware utilization까지 내려왔다는 증거이기 때문입니다.
앞으로 볼 지표는 세 가지입니다. 첫째, llama.cpp와 consumer GPU quantization이 얼마나 안정적으로 따라오는지입니다. 둘째, inline editing과 code infilling benchmark에서 AR model 대비 실제 acceptance rate가 나오는지입니다. 셋째, vLLM의 ModelState abstraction이 다음 dLLM이나 hybrid model을 얼마나 쉽게 받는지입니다. DiffusionGemma가 production default가 되지 않더라도, 256-token 병렬 생성은 로컬 AI 도구가 latency를 다루는 새 실험 기준이 됐습니다.