Claude 보안 harness 공개, AI가 찾은 버그를 증명하는 7단계
Anthropic이 Claude Code 스킬과 gVisor 기반 취약점 탐지 harness를 공개했습니다. 발견보다 검증과 패치 병목을 다룹니다.
- 무슨 일: Anthropic이
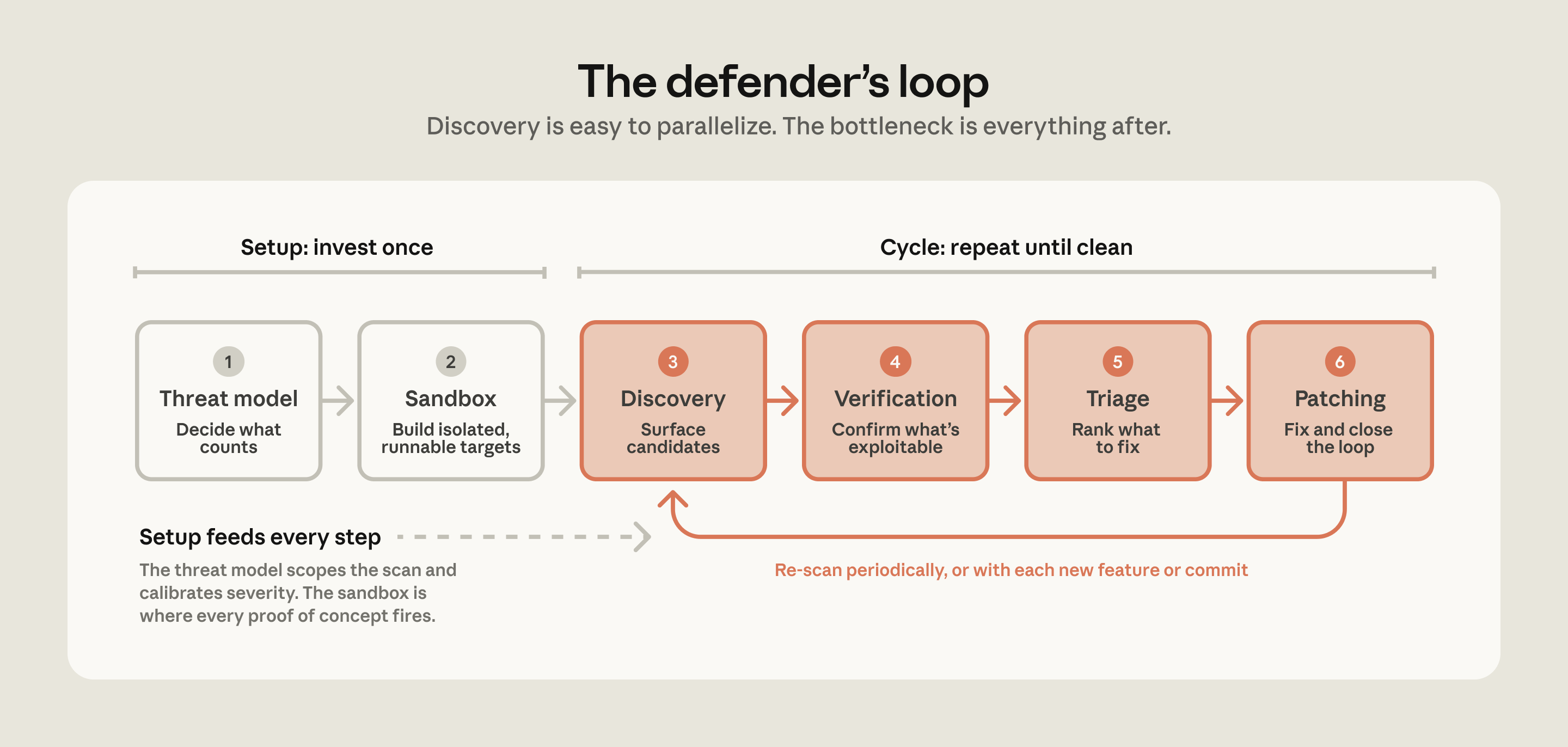
defending-code-reference-harness저장소를 공개했습니다.- Claude Code 스킬 6개와 recon → find → verify → report → patch autonomous harness를 함께 담았습니다.
- 의미: 취약점 발견량보다 검증, triage, patch validation이 AI 보안 자동화의 병목으로 올라왔습니다.
- 실무 영향:
THREAT_MODEL.md, gVisor sandbox, 독립 verifier, PoC, dedupe가 보안 에이전트의 기본 단위가 됩니다.- README는 이 저장소를 maintained product가 아니라 reference implementation으로 못 박습니다.
- 주의점: autonomous pipeline은 target code를 실행하므로 credential mount와 egress control을 먼저 설계해야 합니다.
Anthropic이 defending-code-reference-harness라는 공개 저장소를 내놨습니다. GitHub API 확인 기준 저장소는 2026년 5월 22일 만들어졌고, 6월 2일 마지막 push가 있었습니다. 2026년 6월 5일 18:03 UTC 무렵에는 2706 stars, 187 forks, 2 open issues가 표시됐습니다. 제목만 보면 또 하나의 AI 보안 스캐너처럼 보이지만, README가 말하는 범위는 더 좁고 실용적입니다. 저장소는 Claude Code용 스킬과, C/C++ 메모리 취약점 탐지를 기준으로 만든 autonomous reference pipeline을 함께 제공합니다.
이번 공개를 읽을 때 먼저 빼야 할 오해가 있습니다. 이 저장소는 pip install해서 기업 코드베이스 전체를 맡기는 관리형 제품이 아닙니다. README는 "not maintained and is not accepting contributions"라고 명시하고, 관리형 선택지로는 별도 제품인 Claude Security를 가리킵니다. 따라서 뉴스의 무게는 제품 출시보다 설계 공개에 있습니다. Anthropic이 Project Glasswing, Claude Security, 파트너 보안팀 협업에서 배운 vulnerability discovery 루프를 skills, harness, docs, sandbox 파일로 풀어 놓은 사건입니다.
Anthropic의 동반 글은 출발점을 분명히 잡습니다. 모델 성능이 올라가면서 vulnerability discovery는 병렬화하기 쉬워졌고, 병목은 verification, triage, patching으로 옮겨갔다는 주장입니다. 같은 글은 2026년 5월 22일 기준 Anthropic의 오픈소스 scanning에서 1596개 취약점이 disclosed됐고, Anthropic이 아는 범위에서 97개가 patched됐다고 적습니다. 이 숫자는 "모델이 많이 찾았다"보다 "많이 찾은 뒤 생태계가 얼마나 고칠 수 있는가"를 묻는 데 쓰입니다.
이 관점은 최근 Anthropic의 Glasswing 발표와 이어집니다. 2026년 5월 22일 Glasswing 업데이트는 파트너들이 high 또는 critical severity 취약점 1만 건 이상을 찾았다고 밝혔습니다. devlery에서도 이미 발견량, 패치 병목, ARiES/ATT&CK 분석을 다뤘습니다. 이번 저장소의 새로움은 같은 주장을 코드로 쪼개 보여준다는 점입니다. THREAT_MODEL.md를 만들고, agent를 sandbox에 넣고, finding을 별도 verifier가 반박하게 하고, PoC와 patch를 다시 검증하는 단계가 파일 구조와 CLI로 내려왔습니다.
저장소의 첫 번째 표면은 Claude Code 스킬입니다. /quickstart, /threat-model, /vuln-scan, /triage, /patch, /customize가 들어갑니다. 이 중 /quickstart는 데모 target에서 흐름을 안내하고, /threat-model은 코드와 문서, CVE 이력, 시스템 owner 인터뷰를 바탕으로 THREAT_MODEL.md를 만듭니다. /vuln-scan은 threat model을 읽고 target을 focus area로 나눈 뒤 병렬 review agent를 실행합니다. /triage는 검증과 중복 제거, exploitability 재평가를 맡고, /patch는 후보 diff를 만들고 독립 reviewer agent가 확인합니다.
여기서 threat model은 장식 문서가 아닙니다. Anthropic은 false positive의 흔한 원인이 모델이 trust boundary를 잘못 가정하는 데 있다고 설명합니다. 예를 들어 모델이 config file을 공격자가 조작할 수 있다고 가정하면 실제 환경에서는 취약점이 아닌 코드를 critical로 볼 수 있습니다. 반대로 internet-facing service를 internal-only라고 착각하면 실제 취약점을 놓칩니다. 동반 글은 threat model과 design docs, requirements, constraints가 잘 정리된 시스템에서 모델 finding이 90% exploitable이었다는 파트너 사례를 소개합니다.
개발팀이 여기서 바로 가져갈 수 있는 산출물은 THREAT_MODEL.md입니다. 기존 보안 리뷰에서는 threat model이 스프레드시트, 위키, 회의 기록에 흩어지는 경우가 많았습니다. Anthropic의 루프에서는 discovery agent와 triage agent가 같은 파일을 읽습니다. 즉 "우리가 무엇을 취약점으로 볼 것인가"가 프롬프트 한 줄이 아니라 저장소 안의 versioned artifact가 됩니다. 에이전트가 반복 실행될수록 이 파일은 scanner 설정이자 보안팀의 운영 지식으로 변합니다.
두 번째 표면은 autonomous reference pipeline입니다. README와 docs/pipeline.md는 이 harness가 C/C++ memory vulnerability discovery를 기준으로 작성됐고 Docker와 ASAN을 사용한다고 설명합니다. 실행 예시는 bin/vp-sandboxed run drlibs --model <model-id> --runs 3 --parallel --stream --auto-focus입니다. 결과는 results/<target>/<timestamp>/ 아래에 저장되고, --stream을 켜면 첫 report가 몇 분 안에 reports/bug_NN/ 아래에 나타날 수 있습니다. 이 파일 중심 설계는 긴 agent run이 실패해도 transcript와 result를 잃지 않게 만드는 데 맞춰져 있습니다.
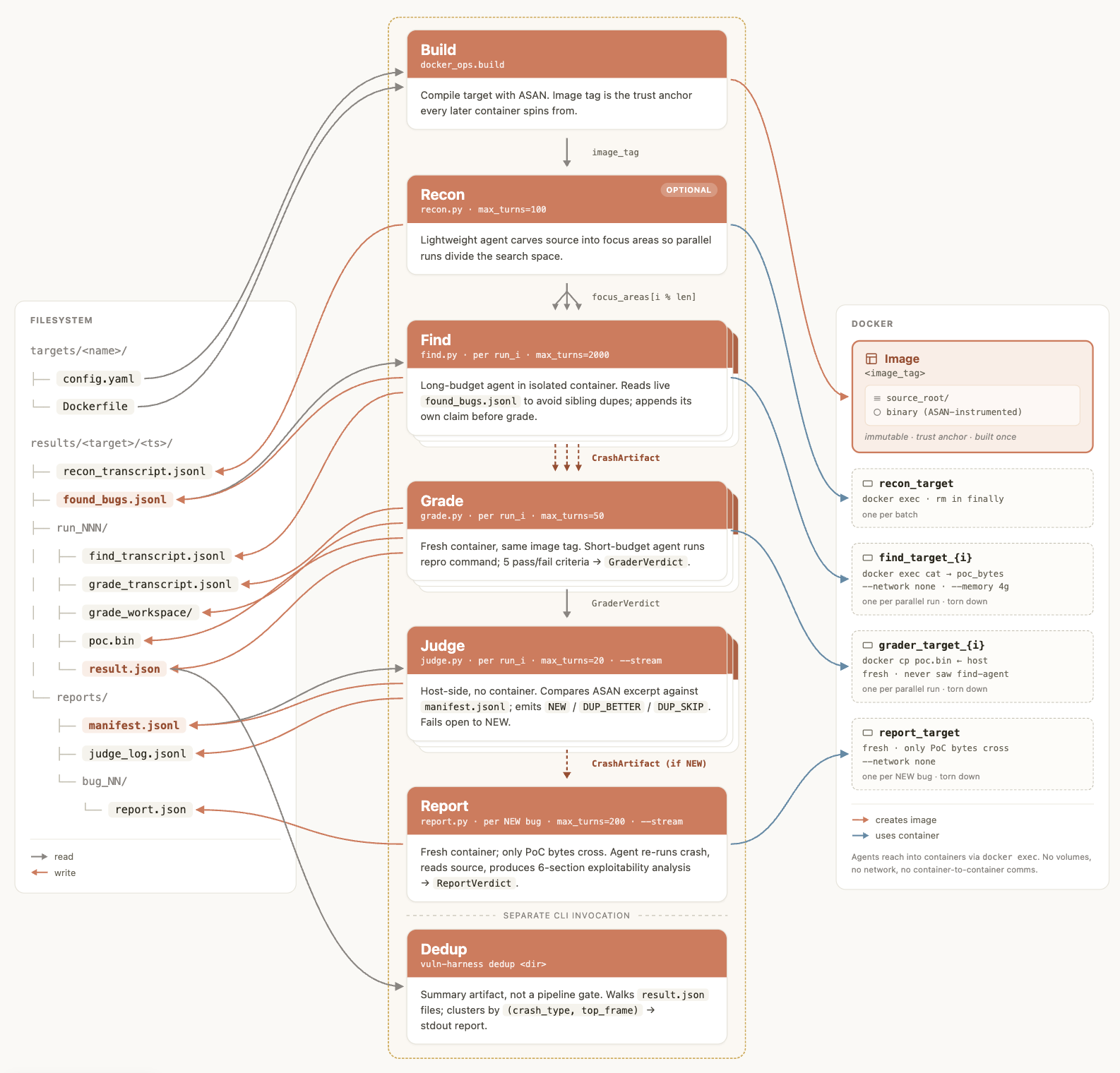
Pipeline은 7단계로 나뉩니다. Build 단계는 target Dockerfile을 ASAN-instrumented image로 빌드합니다. Recon 단계는 agent가 source tree를 읽고 "서로 다른 input parser 8개" 같은 focus partition을 제안합니다. Find 단계에서는 여러 agent가 각자 격리된 컨테이너 안에서 source를 읽고 malformed input을 만들며 ASAN binary를 실행합니다. 이때 입력이 3번 중 3번 crash를 내야 finding 후보로 올라갑니다.
그 다음 단계가 이 저장소의 핵심입니다. Grade 단계에서는 별도 agent가 fresh container에서 PoC를 다시 실행합니다. 실제 crash인지, project code 안의 crash인지, 단순 memory exhaustion은 아닌지 확인하는 단계입니다. Find agent의 reasoning은 verifier에게 넘어가지 않고, PoC bytes만 넘어갑니다. Judge 단계는 이미 보고된 bug와 비교해 새 bug인지, 더 나은 reproducer인지, duplicate인지 판단합니다. Report 단계는 exploitability analysis를 구조화해 쓰고, 또 다른 grader가 evidence가 있는지 점수화합니다. Patch 단계는 후보 fix를 만들고 네 가지를 확인합니다. 원래 PoC가 더 이상 crash를 내지 않는지, test suite가 통과하는지, fresh find agent가 우회 경로를 찾지 못하는지 보는 방식입니다.
이 구조는 "AI에게 보안 리뷰를 시켰다"와 다릅니다. Anthropic은 discovery가 recall을 높이고, verification이 precision을 높인다고 나눕니다. 같은 agent에게 찾기와 반박을 동시에 시키면 exploitable true positive를 스스로 걸러낼 수 있다고 설명합니다. 그래서 verifier는 discovery agent와 filesystem이나 conversation history를 공유하지 않습니다. prompt도 finding을 믿으라고 하지 않고, false positive로 가정하고 반박할 근거를 찾게 합니다. 동반 글은 adversarial verifier를 추가하면 non-exploitable finding이 대략 절반으로 줄었고, verifier에게 PoC까지 만들게 하면 false positive rate가 near zero까지 내려갔다는 사례를 적습니다.
보안 경계도 문서의 큰 부분을 차지합니다. docs/security.md는 autonomous pipeline이 target code를 실행하므로 bin/vp-sandboxed로만 실행하라고 설명합니다. 이 wrapper는 gVisor가 등록돼 있고 allowlist proxy가 떠 있는지 확인합니다. Agent-spawning subcommand는 sandbox 밖에서 시작하지 않으며, 우회하려면 --dangerously-no-sandbox를 명시해야 합니다. 문서는 일반 Docker runc만으로는 host kernel을 공유하므로 target code나 agent action이 host compromise로 이어질 경로가 짧다고 경고합니다.
docs/agent-sandbox.md는 격리 대상을 더 구체적으로 나눕니다. Agent의 Read, Write, Bash는 host filesystem과 host shell이 아니라 container filesystem과 container shell에서 실행됩니다. 네트워크 egress는 기본적으로 api.anthropic.com:443만 허용됩니다. gVisor는 container가 host kernel 대신 gVisor의 user-space kernel 위에서 돌도록 만들고, vp-internal Docker network는 인터넷 route를 없앱니다. 모델 API 호출만 같은 network의 작은 proxy container를 통해 나갑니다.
이 설계가 모든 환경에 그대로 맞지는 않습니다. 문서는 gVisor가 Linux에서만 직접 동작하고, macOS나 Windows에서는 Linux VM 안에서 돌리거나 위험 플래그를 써야 한다고 적습니다. API endpoint도 기본값이 Anthropic API이므로, Bedrock이나 Vertex, Azure 경유 환경에서는 egress allowlist를 조정해야 합니다. 또 setup phase와 attack phase를 분리해야 합니다. dependency pull, tool install, build, test는 네트워크가 있는 setup에서 끝내고, scan phase에서는 snapshot을 로드한 뒤 model API 외 egress를 닫는 방식입니다.
개발 조직이 이 문서에서 봐야 할 문장은 "제약은 prompt가 아니라 code와 configuration으로 강제해야 한다"는 부분입니다. 동반 글은 한 팀이 모델에게 network access가 없다고 말했지만 실제로는 GitHub에서 fetch할 수 있었던 사례를 소개합니다. 다른 팀은 agent가 scan 중 GitHub issue에 답변한 일을 봤다고 합니다. 두 사례 모두 악의적 행동보다 권한 경계의 실패에 가깝습니다. Agent는 자신이 실제로 가진 capability를 사용합니다. 보안 정책을 자연어로 부탁하는 것과 egress route를 끊는 것은 다른 일입니다.
Patching 단계도 단순 자동 수정이 아닙니다. Anthropic은 patch 전 새 test를 만들고, 기존 코드에서 실패함을 확인한 뒤 fix를 적용하라고 씁니다. Patch가 원래 PoC를 막는지, 기존 test suite를 깨지 않는지, 새 discovery agent가 같은 class의 우회 경로를 찾지 못하는지도 봐야 합니다. 동반 글의 파트너 사례는 generated patch가 너무 제한적으로 동작해 실제 service dependency를 깨뜨릴 수 있다고 경고합니다. 보안 patch는 "bug line 하나 수정"보다 trust boundary와 compatibility를 함께 다룹니다.
이 저장소가 관리형 제품이 아니라 reference인 이유도 여기에 있습니다. 각 팀은 다른 언어, 다른 build system, 다른 exploit witness, 다른 severity 기준을 갖습니다. README의 customization 표는 C/C++ reference에서 ASAN crash signature와 crashing input file을 예로 듭니다. 다른 stack에서는 exception, canary file, DNS callback, HTTP request sequence, transaction list, test harness가 필요할 수 있습니다. targets/<your-service>/를 만들고 smoke run으로 검증하는 과정이 핵심입니다.
Hacker News 반응도 이 지점을 잡았습니다. 2026년 6월 5일 HN의 관련 토론은 확인 시점 약 486 points와 137 comments를 기록했습니다. 상위 댓글 중 일부는 이런 framework를 완제품보다 작업장 도구에 비유했습니다. 그대로 사서 쓰는 물건이라기보다, 팀의 대상과 인터페이스, 알림 방식, 검증 규칙에 맞춰 다시 만드는 참고 설계라는 해석입니다. 다른 댓글들은 AI 시대의 harness와 skills가 dotfiles처럼 개인·팀 생산성 자산이 될 수 있는지, 그 안에 회사 정보나 보안 정책이 새지 않게 어떻게 이동성을 설계할지로 논의를 넓혔습니다.
이 반응은 개발자 도구 시장에도 신호를 줍니다. AI coding agent 경쟁은 모델 이름과 IDE 화면에서 시작했지만, 보안 영역에서는 harness가 제품의 본체에 가까워집니다. GitHub Advanced Security, Snyk, Semgrep, Wiz 같은 기존 도구는 finding, reachability, ownership, policy, PR workflow를 이미 다룹니다. Anthropic의 reference harness는 LLM agent가 이 루프에 들어올 때 필요한 추가 단위를 보여줍니다. Transcript, PoC artifact, independent grader, sandbox snapshot, egress allowlist, generated patch review가 같은 pipeline 안에 있어야 합니다.
한국 개발팀에 가장 가까운 질문은 "우리도 당장 autonomous vulnerability hunter를 돌릴 것인가"가 아닙니다. 먼저 답해야 할 것은 세 가지입니다. 첫째, 저장소 안에 threat model과 보안 정책이 agent가 읽을 수 있는 형태로 존재하는가입니다. 둘째, agent가 code를 읽는 단계와 target code를 실행하는 단계를 같은 권한으로 두고 있지는 않은가입니다. 셋째, finding이 많이 나왔을 때 owner 지정, duplicate collapse, severity 재평가, patch 검증, release note 작성까지 처리할 queue가 있는가입니다.
이 저장소는 AI 보안 자동화의 기대치를 낮추는 동시에 높입니다. 낮추는 부분은 명확합니다. README는 maintained product가 아니며 모든 codebase에서 out-of-box로 동작하지 않는다고 말합니다. Managed option은 Claude Security이고, 이 repo는 참고 구현입니다. 높이는 부분도 분명합니다. 단순 static review나 "취약점 찾아줘" prompt로 끝나는 시대는 지나가고 있습니다. AI가 찾은 bug는 PoC, 독립 verifier, dedupe, exploitability report, patch re-attack으로 증명돼야 합니다.
앞으로 볼 지표는 stars보다 운영 성과입니다. 기업 보안팀이 이 reference shape를 자사 언어와 runtime에 맞춰 얼마나 빨리 port하는지, false positive와 duplicate 비율이 얼마나 줄어드는지, patch 후보가 실제 PR로 합쳐지는 비율이 얼마인지 봐야 합니다. Anthropic이 강조한 병목이 맞다면 다음 경쟁은 더 많은 finding을 만드는 모델이 아니라, finding을 사람이 믿고 고칠 수 있는 evidence와 최소 patch로 바꾸는 harness에서 갈릴 가능성이 큽니다.