Claude 코드 80% 병합, Anthropic R&D의 검토 병목
Anthropic은 Claude가 production codebase 병합 코드의 80% 이상을 작성한다고 밝혔습니다. 작성 자동화 뒤의 검토 병목을 봅니다.

- 무슨 일: Anthropic Institute가 2026년 6월 4일
When AI builds itself를 공개했습니다.- 2026년 5월 기준 production codebase에 병합된 코드 줄의 80% 이상이
Claude작성으로 attribution됐습니다.
- 2026년 5월 기준 production codebase에 병합된 코드 줄의 80% 이상이
- 숫자: 엔지니어별 코드 병합량은 2024년 대비 8배, open-ended Claude Code task 성공률은 2026년 5월 76%입니다.
- 개발자 영향: 병목은 코드 작성에서 review queue, test harness, incident prevention, experiment selection으로 이동합니다.
- 주의점: Anthropic도 줄 수와 직원 추정치가 생산성·품질을 과대평가할 수 있다고 footnote에서 제한했습니다.
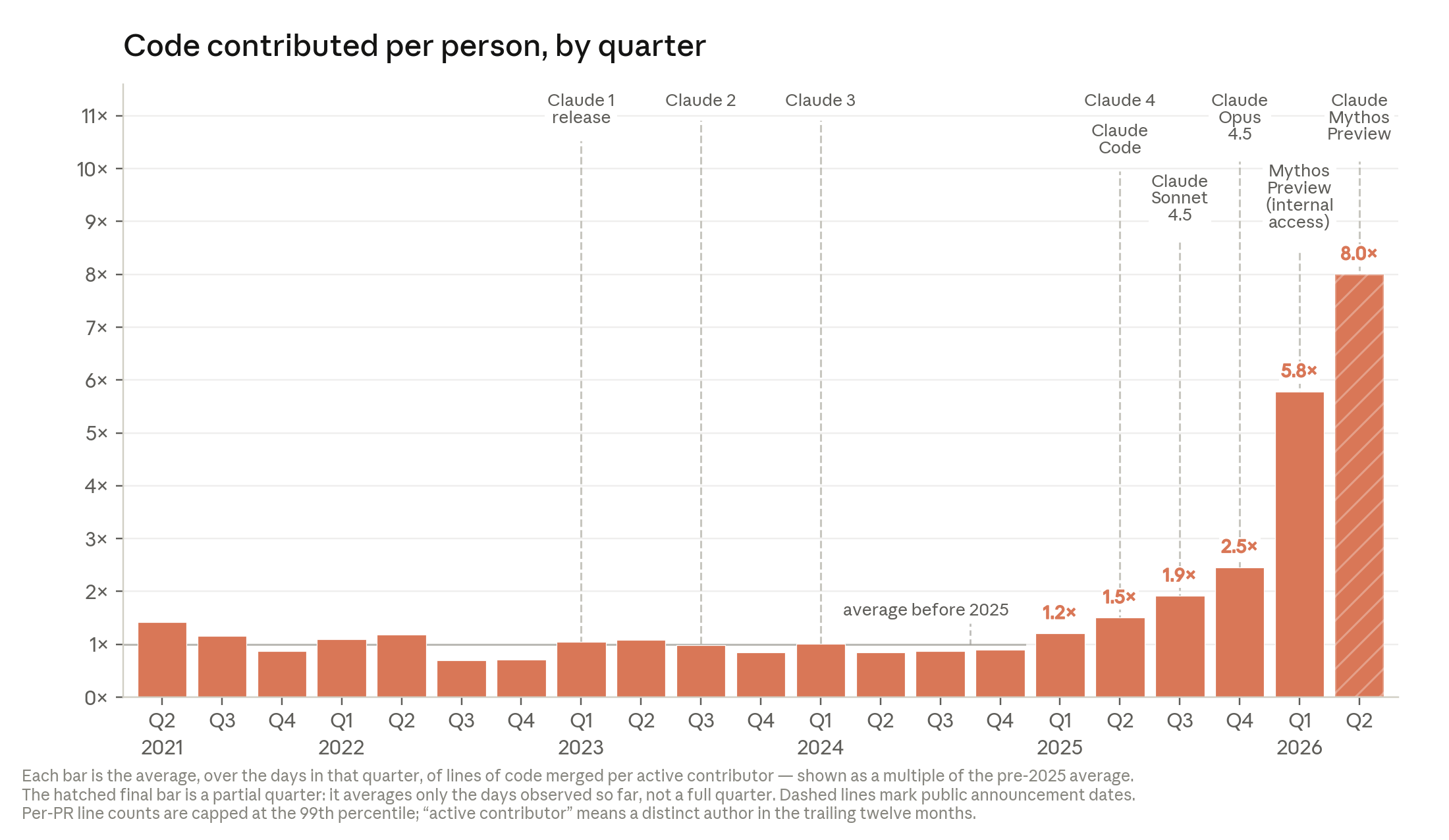
Anthropic Institute가 2026년 6월 4일 When AI builds itself를 공개했습니다. 글의 첫 숫자는 강합니다. 2026년 5월 기준 Anthropic production codebase에 병합된 코드 줄의 80% 이상이 Claude가 작성한 것으로 attribution됐습니다. Claude Code 연구 프리뷰가 2025년 2월 나오기 전에는 이 수치가 한 자릿수 초반이었습니다. 같은 글은 2026년 2분기 일반적인 Anthropic 엔지니어가 2024년보다 하루 8배 많은 코드를 병합한다고 설명합니다.
이 발표는 새 모델 출시나 가격 변경이 아닙니다. Anthropic Institute가 자사 내부 데이터를 공개하며 "AI가 AI 개발을 가속하고 있는가"를 논한 연구·정책 성격의 글입니다. Anthropic은 full recursive self-improvement가 아직 일어나지 않았고 피할 수 없는 결과도 아니라고 적었습니다. 다만 AI 시스템이 자기 후속 모델을 설계하고 개발하는 단계가 오면 보안, 모니터링, 행동 shaping이 더 어려워진다고 주장합니다. 개발자에게는 더 가까운 질문이 있습니다. 코드 작성이 8배 빨라지면, review와 검증은 같은 속도로 늘어났는가입니다.
Anthropic은 AI 개발을 engineering과 research로 나눠 설명합니다. Engineering은 코드 작성, infrastructure 구축, training oversight입니다. Research는 어떤 실험을 할지 고르고, 결과를 해석하고, 다음 아이디어를 정하는 일입니다. 회사의 결론은 둘 사이가 다릅니다. Claude는 underspecified engineering problem을 받아 해결 방법을 찾아가는 단계까지 왔지만, 어떤 목표가 가치 있는지 고르는 판단에서는 큰 격차가 남아 있습니다. 이 차이가 오늘의 coding agent와 완전한 recursive self-improvement 사이의 경계입니다.
코드 생산량 수치는 lines of code라는 약한 지표를 사용합니다. Anthropic도 footnote에서 8배 코드 병합량이 진짜 생산성 향상을 과장할 수 있다고 적었습니다. 팀원이 코드 줄 수로 보상받지 않는다는 설명도 붙였습니다. 그래도 변화의 방향은 분명합니다. Claude가 제안한 snippet을 사람이 editor에 복사하던 2023~2025년 단계와, Claude가 파일을 고치고 테스트를 돌리고 긴 작업을 넘겨받는 2025~2026년 단계는 병합량 그래프에서 다른 기울기로 나타납니다.
Anthropic이 공개한 두 번째 내부 수치는 직원 설문입니다. 2026년 3월 Anthropic research team 130명을 대상으로 한 poll에서 median respondent는 Mythos Preview가 없을 때보다 자기 output이 약 4배라고 추정했습니다. 회사는 이 수치 역시 낮춰 봐야 한다고 밝혔습니다. 응답자가 bias와 질문 정의를 충분히 고려하지 않았을 수 있고, METR의 최근 연구도 개발자가 AI 생산성 uplift를 과대평가할 수 있음을 지적했기 때문입니다. 그래도 code attribution, 병합량, 설문이 같은 방향을 가리킨다는 점은 Anthropic의 주장에 무게를 더합니다.
가장 눈에 띄는 사례는 2026년 4월 API error class 수정입니다. Anthropic은 Claude가 800개 이상의 fix를 shipping해 특정 API error class를 1000분의 1로 줄였다고 설명했습니다. 이를 감독한 엔지니어는 사람이 직접 했다면 4년이 걸렸을 것으로 추정했습니다. 이 사례는 "AI가 코드 몇 줄을 빠르게 쓴다"보다 narrow하지만 실무적입니다. 오래 미뤄진 cleanup, 낯선 context가 많은 bug class, 반복적인 재현·검증 작업은 agent에게 넘기기 좋은 영역으로 보입니다.
품질 지표에서는 Claude Code session success rate가 등장합니다. Anthropic은 Claude judge가 session이 사용자 task를 correction 없이 성공했는지 판단한다고 설명합니다. 가장 open-ended한 task에서 Claude의 성공률은 2026년 5월 76%에 도달했고, 6개월 동안 50 percentage points 올랐습니다. 예시로는 routine upgrade 후 training job 수만 개가 crash한 사건이 나옵니다. 엔지니어가 Claude에 텍스트 context와 cluster access를 주자 Claude가 환경 설정을 하나씩 테스트해 obscure debugging flag를 찾아냈고, 약 2시간 만에 보통 2~3일 걸릴 작업을 끝냈다는 설명입니다.
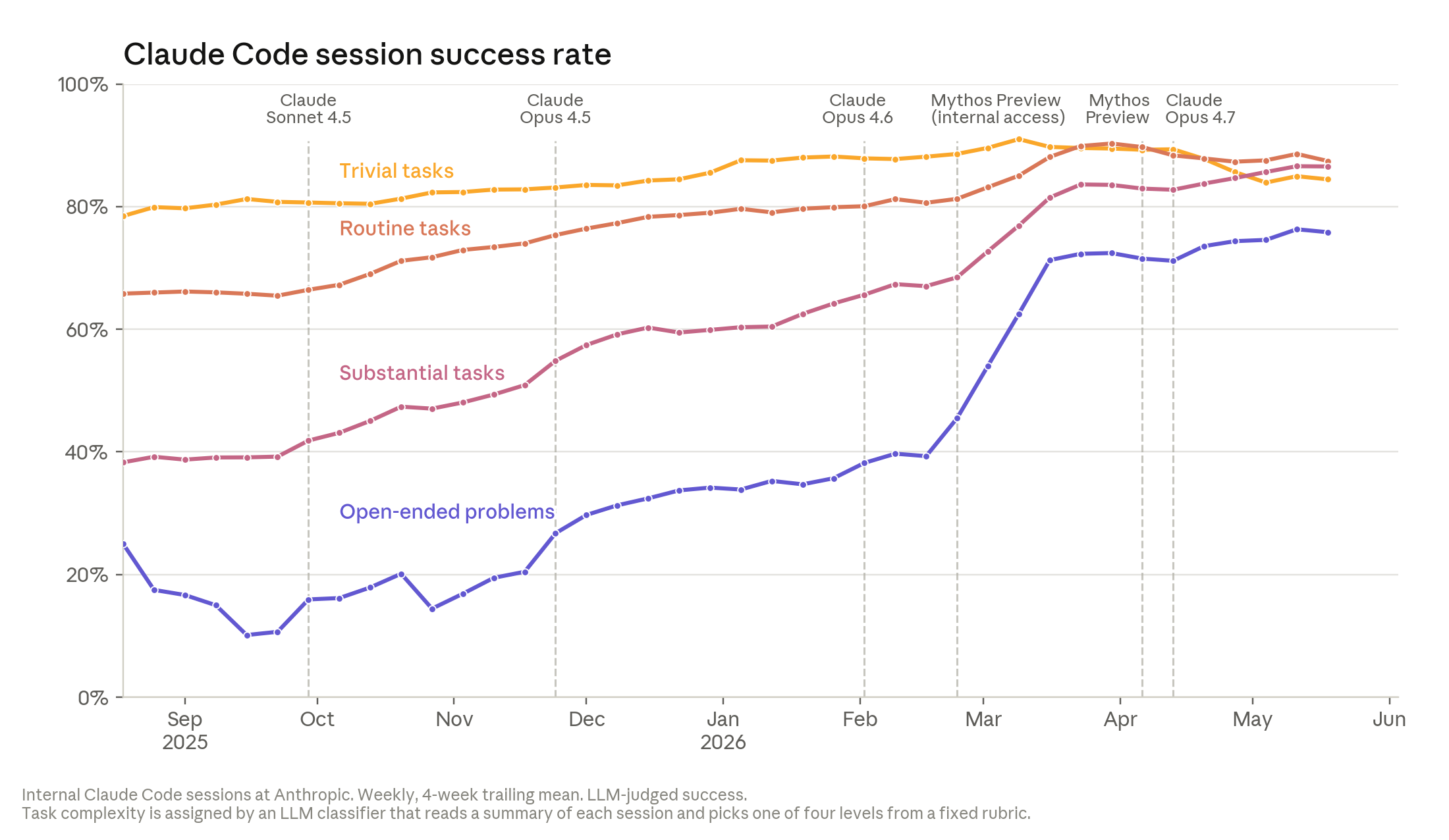
이 대목에서 검토 병목이 생깁니다. Anthropic은 Claude가 작성한 코드가 late 2025에는 인간 코드보다 다소 낮았지만 2026년 현재는 대체로 parity에 가깝고, 1년 안에 더 나아질 것으로 보는 직원이 많다고 적었습니다. 코드 작성 속도가 review 속도보다 빠르면 merge queue는 사람이 기다리는 곳이 아니라 사람이 Claude 출력을 판정하는 곳이 됩니다. Anthropic 내부에서는 proposed change를 automated Claude reviewer가 읽고 bug, security flaw, defect를 찾습니다. 회사는 retrospective analysis에서 이 reviewer가 과거 claude.ai incident bug의 약 3분의 1을 production 전에 잡았을 것이라고 밝혔습니다.
개발팀이 여기서 배울 지점은 "AI reviewer를 켜자"가 아닙니다. 작성 agent와 review agent가 같은 계열 모델일 때 독립성이 얼마나 되는지, reviewer가 잡은 결함을 사람이 어떻게 sampling하는지, incident postmortem이 test case로 환원되는지까지 설계해야 합니다. Anthropic 사례에서는 Claude가 만든 코드를 Claude가 다시 읽습니다. 같은 모델군의 blind spot이 공유될 수 있으므로 compiler, type system, integration test, fuzzing, policy check, human owner approval 같은 이질적인 신호가 같이 필요합니다.
Research 쪽 수치도 강합니다. Anthropic은 작은 AI 모델을 학습하는 코드를 더 빠르게 만들라는 fixed-goal optimization benchmark를 매 release마다 Claude에 줍니다. 2025년 5월 Claude Opus 4는 starting code 대비 약 3배 speedup을 냈고, 2026년 4월 Claude Mythos Preview는 약 52배 speedup을 냈습니다. Anthropic은 footnote에서 이 절대 배수를 real-world training speedup으로 읽지 말라고 제한했습니다. 시작 코드에 개선 여지가 얼마나 남았는지에 따라 배수가 달라지기 때문입니다. 비교에 쓸 부분은 같은 setup 안에서 1년 동안 3배에서 52배로 오른 변화입니다.
Open-ended research project에서는 더 공격적인 숫자가 나옵니다. 2026년 4월 Anthropic은 Claude-powered agents가 약한 모델이 강한 모델을 감독할 수 있는지 탐구하는 AI safety 문제를 end to end로 수행한 사례를 공개했습니다. 두 인간 연구자는 약 1주일 동안 weak-to-strong supervision gap의 23%를 회복했습니다. Agents는 800 cumulative hours와 약 1만8000달러 compute로 97%를 회복했습니다. 다만 Anthropic은 결과가 production-scale model로 clean transfer되지 않았고, 인간이 문제와 scoring rubric을 정했다고 설명했습니다. 방향 설정은 여전히 사람의 몫이었습니다.
이 구조를 소프트웨어 조직에 옮기면 병목은 네 군데로 나뉩니다. 첫째, review throughput입니다. 생성된 pull request가 많아질수록 사람의 diff reading, architecture approval, security sign-off가 밀립니다. 둘째, test harness입니다. Agent가 빠르게 고친 코드를 합치려면 unit test보다 실제 사용자 workflow, migration, permission, rollback까지 검증하는 자동화가 필요합니다. 셋째, attribution입니다. 어떤 줄이 어떤 agent session에서 나왔는지, 어떤 prompt와 tool permission을 썼는지 incident 때 추적할 수 있어야 합니다. 넷째, experiment selection입니다. 실행 비용이 human time에서 compute로 옮겨가면 "무엇을 돌리지 않을 것인가"가 팀 리더의 일이 됩니다.
Hacker News 반응은 빠르고 거칠었습니다. 2026년 6월 4일 16:20 UTC에 올라온 thread는 6월 5일 확인 시점에 469 points와 628 comments를 기록했습니다. 일부 댓글은 Anthropic의 IPO 가능성과 연결해 글의 동기를 의심했고, lines of code를 productivity 지표로 쓰는 점을 비판했습니다. 다른 댓글은 frontier model이 edge case를 찾아내는 경험을 들며 2025년보다 coding assistant가 확실히 좋아졌다고 썼습니다. 또 다른 축은 compute, energy, datacenter, code review, correctness가 recursive self-improvement를 막는 제약이라고 봤습니다.
이 반응은 과장이 아닙니다. Anthropic이 제시한 세 가지 미래 중 첫째는 trend가 S-curve로 꺾이는 경우입니다. 판단력, research taste, compute, energy, interconnect bandwidth 같은 공급망이 intelligence보다 강한 제약이 될 수 있습니다. 둘째는 AI lab이 compounding efficiency gain을 계속 보지만 humans가 연구 방향과 결과 판정을 맡는 경우입니다. 셋째가 AI systems themselves become capable of full recursive self-improvement입니다. Anthropic은 둘째가 현재 evidence에 가장 가깝다고 보지만, 셋째를 배제하지 않습니다.
개발자에게 실무적으로 가까운 것은 둘째 시나리오입니다. AI가 완전히 자기 후속 모델을 만드는 세계가 오지 않아도, agent가 bug fix, cleanup, benchmark optimization, incident investigation을 대량으로 처리하면 조직의 control plane은 바뀝니다. GitHub branch protection, CI budget, code owner rule, security review SLA, incident response ownership이 agent throughput을 따라가야 합니다. Code generation이 싸질수록 코드베이스는 커지고, diff는 많아지고, 검증은 느려질 수 있습니다.
Anthropic의 slowdown/pause 제안도 개발 조직의 언어로 바꿔 읽을 수 있습니다. 회사는 frontier AI 개발을 늦추거나 일시 중지할 선택지가 있으면 좋겠지만, 다른 lab이 몰래 앞서나가지 않았는지 검증하는 체계가 필요하다고 썼습니다. 소프트웨어 팀 내부에서도 작은 버전의 같은 문제가 생깁니다. 어느 agent에게 production credential을 줄지, 어떤 작업은 사람이 approve하기 전까지 실행하지 못하게 할지, 어떤 benchmark 상승을 실제 품질 향상으로 인정할지, 팀마다 검증 기준을 맞춰야 합니다.
이번 글의 가장 날카로운 부분은 recursive self-improvement라는 용어보다 review bottleneck입니다. Anthropic 내부의 작성 속도는 이미 사람이 직접 타이핑하는 단계를 넘어섰습니다. 남은 인간 역할은 goal selection, result judgement, code review, incident accountability입니다. Claude가 코드 80% 이상을 쓰는 조직에서 인간 개발자는 덜 쓰는 사람이 아니라 더 자주 판정하는 사람이 됩니다. 그 판정이 느리거나 부실하면, AI가 만든 코드는 생산성 지표가 아니라 future incident backlog가 됩니다.
따라서 AI coding agent를 쓰는 팀은 모델 이름보다 세 가지 로그를 먼저 봐야 합니다. 누가 어떤 목표를 줬는가. Agent가 어떤 파일, command, service, credential에 접근했는가. Merge 뒤 어떤 test와 reviewer가 결과를 승인했는가. Anthropic의 숫자는 매우 큰 조직의 내부 사례이지만, 작은 팀에도 같은 질문을 남깁니다. 코드 작성이 빨라진 다음 병목은 손가락이 아니라 검증 체계입니다.