Google RAG 정확도 34% 향상, 답변 전 근거 부족 검사
Google Research가 Gemini Enterprise Agent Platform의 Agentic RAG를 공개했습니다. cross-corpus 검색과 충분한 근거 검사를 봅니다.

- 무슨 일: Google Research가 Gemini Enterprise Agent Platform의 Agentic RAG 기반 Cross-Corpus Retrieval을 공개했습니다.
- 2026년 6월 5일 발표이며, Google은 이 기능을 public preview로 제공한다고 밝혔습니다.
- 수치: FramesQA 실험에서 표준 RAG 대비 factuality dataset 정확도를 최대 34% 높였다고 설명했습니다.
- 메커니즘:
Sufficient Context Agent가 retrieved snippets, draft, missing pieces를 검사하고 부족하면 다시 검색합니다.- Cross-corpus 설정에서는 4개 corpus 중 검색 대상을 고르며 90.1% 정답률과 평균 3% 이내 latency 차이를 보고했습니다.
- 개발자 영향: enterprise RAG의 병목은 vector DB 선택보다 corpus routing, 권한, 평가, audit trail로 이동합니다.
Google Research는 2026년 6월 5일 Gemini Enterprise Agent Platform에 들어가는 Agentic RAG 기반 Cross-Corpus Retrieval을 공개했습니다. 발표의 첫 문장은 단순한 검색 성능 개선보다 좁습니다. Google Research와 Google Cloud가 만든 multi-agent workflow가 복잡한 기업 질문을 분해하고, 충분한 context를 찾을 때까지 반복 검색한 뒤 답변한다는 내용입니다.
RAG는 이미 낯선 단어가 아닙니다. 그러나 Google이 지목한 실패 지점은 실무에서 자주 보이는 유형입니다. 사용자가 "Project X에 쓰인 서버의 사양이 무엇인가"라고 물으면 첫 검색은 Project X 문서를 찾을 수 있습니다. 그 문서에 server ID만 있고 실제 CPU, memory, region 정보가 다른 asset database에 있으면 표준 RAG는 "찾지 못했다"거나 server ID만 답하기 쉽습니다. Google은 이런 multi-source, multi-hop query가 현재 enterprise workflow의 기본형에 가깝다고 봅니다.
이번 발표가 최근 Google agent 발표와 다른 점은 실행 도구가 아니라 검색 루프를 다룬다는 데 있습니다. 5월 Google I/O 이후 devlery는 Gemini Managed Agents API, Gemini Enterprise Agent Platform, Gemini File Search 같은 소식을 이미 다뤘습니다. 이번 글의 초점은 "에이전트가 무엇을 실행하느냐"보다 "에이전트가 답변 근거를 충분히 찾았는지 어떻게 판단하느냐"입니다. 기업 RAG에서 틀린 답은 모델이 약해서만 생기지 않습니다. 데이터가 여러 corpus에 흩어져 있고, 첫 검색 결과가 부분적이며, 검색이 실패했는지 아니면 아직 덜 찾았는지 구분하지 못할 때 생깁니다.
Google의 구조는 검색 엔진 하나가 아닙니다. Orchestrator 또는 Root Agent가 요청을 보고 단일 검색으로 끝낼지, 여러 하위 작업으로 나눌지 판단합니다. Planner Agent는 어떤 정보 경로를 확인해야 하는지 정합니다. Query Rewriter는 긴 자연어 질문을 검색 가능한 여러 query로 바꿉니다. Search Fanout 또는 RAG Agent는 refined query를 여러 retrieval source로 보냅니다. 마지막 LLM은 모인 context를 읽고 답변을 합성합니다. 여기까지만 보면 일반적인 multi-agent RAG와 크게 다르지 않습니다.
Google이 차별점으로 내세운 구성 요소는 Sufficient Context Agent입니다. 이 에이전트는 답변 직전에 세 가지를 봅니다. 첫째, RAG Agent가 실제로 가져온 text chunk입니다. 둘째, 모델이 만든 intermediate draft입니다. 셋째, 원래 질문과 비교했을 때 빠진 항목입니다. Google의 병원 예시에서 의사가 퇴원 약물, 식이 제한, 입원 중 알레르기 반응을 함께 물었는데 검색 결과에 약물과 식이만 있으면, 이 에이전트는 "알레르기 반응 근거가 없다"는 신호를 냅니다.
이 신호가 중요한 이유는 RAG 실패를 한 종류로 뭉개지 않기 때문입니다. 정보가 실제로 없는 경우도 있고, 검색 query가 나빠서 못 찾은 경우도 있습니다. Google의 예시에서는 "rash", "adverse events" 같은 더 구체적인 query로 다시 검색하게 됩니다. 표준 RAG라면 첫 retrieval 결과에 allergy가 없을 때 불완전한 답변을 만들거나 정보가 없다고 답할 수 있습니다. Agentic RAG는 부족한 항목을 feedback log로 남기고 Query Rewriter를 다시 호출합니다.
실험 수치도 발표의 중심입니다. Google은 FramesQA를 사용했습니다. FramesQA는 FRAMES 논문을 기반으로 한 multi-hop 질문 dataset입니다. Google이 든 예시는 2024년 6월 기준 가장 많이 본 TV season finale 상위 2개 중 어느 finale가 더 길었고 몇 분 차이가 났는지 묻는 질문입니다. 시스템은 먼저 M*A*S*H와 Cheers를 식별하고, 각 finale runtime을 찾고, 길이 차이를 계산해야 합니다. 한 번 검색으로는 viewership 문서만 찾고 runtime 정보를 놓칠 수 있습니다.
Google은 FramesQA 824개 query와 2,676개 PDF 문서를 사용했다고 밝혔습니다. Vanilla RAG 기준선은 Google RAG Engine입니다. Google 설명에 따르면 RAG Engine은 advanced retrieval engine, LLM parser, re-ranker를 포함합니다. 비교 대상은 single-corpus agentic RAG와 cross-corpus agentic RAG입니다. Cross-corpus 설정에는 FramesQA 문서 외에 distractor dataset 3개가 들어가며, Planner Agent는 4개 corpus 중 어디를 검색할지 골라야 합니다. 이 설정은 회사 안에서 finance, project management, clinical notes, support ticket 같은 데이터가 팀별로 나뉜 상황을 흉내 냅니다.
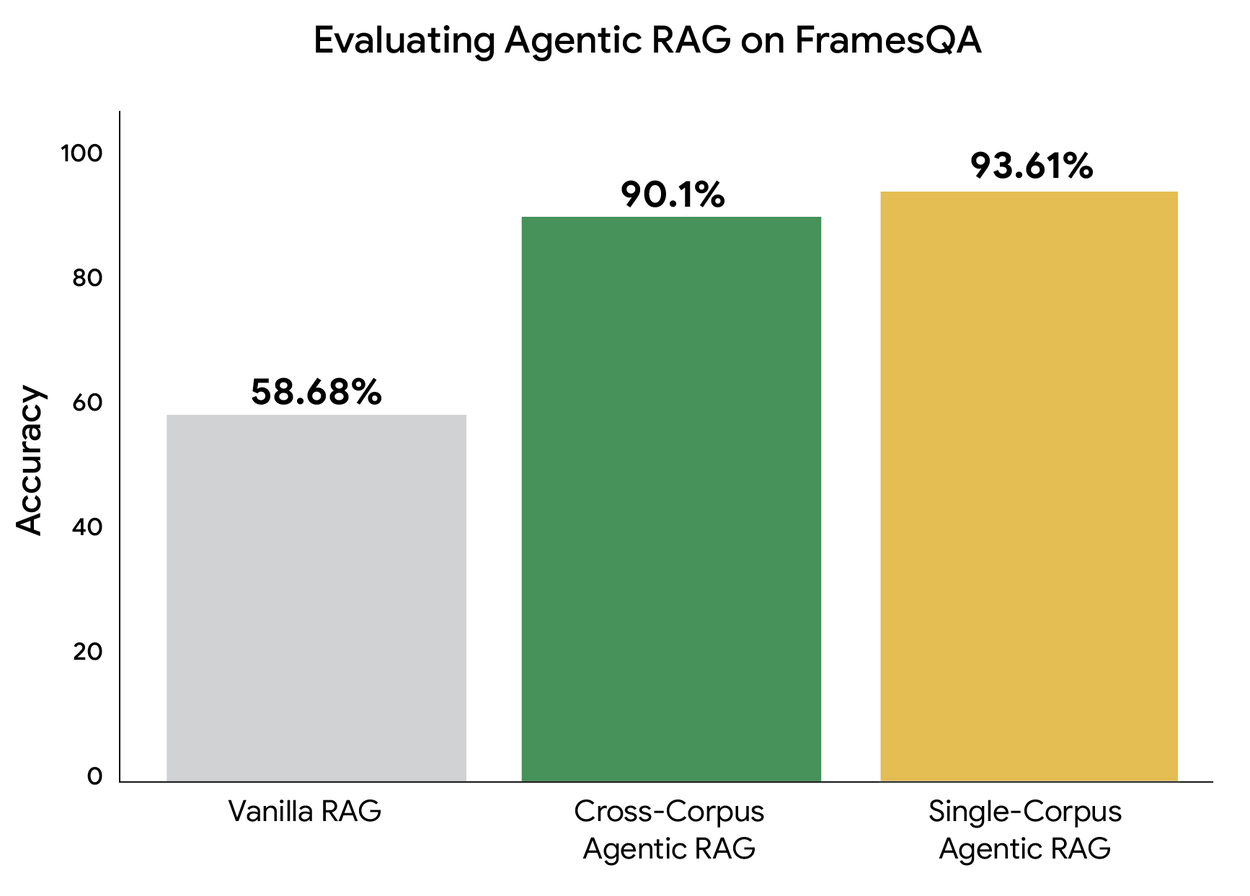
결과는 세 갈래로 읽어야 합니다. 첫째, Google은 표준 RAG 대비 factuality dataset accuracy가 최대 34% 높아졌다고 말했습니다. 둘째, cross-corpus 설정에서 4개 corpus 중 올바른 source를 route하면서 90.1%의 질문에 정확히 답했다고 설명했습니다. 셋째, single-corpus와 cross-corpus version의 latency는 평균 3% 이내 차이였다고 밝혔습니다. Google은 이 수치를 통해 corpus가 늘어도 route와 retrieval loop가 급격한 latency penalty 없이 작동할 수 있다고 주장합니다.
수치를 받아들일 때는 한계도 함께 봐야 합니다. 정확도는 LLM-as-a-judge가 system response와 ground truth answer를 비교하는 방식으로 계산됐습니다. 공개된 proprietary internal dataset 결과는 "더 나은 grounding과 reasoning accuracy"라는 표현에 머물고 세부 수치와 업무 도메인은 제한적으로만 공개됐습니다. 또한 FramesQA는 공개 benchmark이지만, 실제 기업 환경에는 ACL, stale document, 중복 문서, contradictory source, PII redaction, region별 data boundary가 들어갑니다. Cross-corpus routing이 4개 corpus에서 잘 됐다는 결과를 수백 개 connector가 붙은 사내 knowledge graph로 곧바로 확대하면 과장입니다.
그럼에도 이번 발표가 실무적으로 유효한 이유는 RAG 평가 기준을 retrieval hit rate 밖으로 밀어내기 때문입니다. 지금까지 많은 RAG 구현은 "top-k에 관련 chunk가 들어왔는가"를 중심으로 설계됐습니다. Agentic RAG에서는 질문의 하위 조건이 모두 충족됐는지, 누락된 조건을 찾기 위해 query를 다시 썼는지, 다른 corpus를 조회할 근거가 있었는지, 최종 답변 전에 부족 신호가 남았는지가 함께 봐야 할 지표가 됩니다. 검색 품질은 단일 step 점수가 아니라 loop의 종료 조건이 됩니다.
개발자에게 가장 직접적인 변화는 corpus 설계입니다. 표준 RAG에서는 하나의 vector store에 문서를 넣고 namespace나 metadata filter로 범위를 줄이는 방식이 흔합니다. Cross-Corpus Retrieval은 corpus 자체를 routing 대상으로 둡니다. finance database, HR policy, engineering design doc, CRM note가 별도 corpus라면 Planner Agent가 어느 corpus를 먼저 볼지 결정해야 합니다. 이때 corpus description이 부정확하면 좋은 embedding을 써도 검색은 빗나갑니다. 반대로 corpus description, permission mapping, freshness signal이 잘 관리되면 agent는 "어디를 더 찾아야 하는가"를 더 안정적으로 결정할 수 있습니다.
권한 문제도 피할 수 없습니다. Multi-source RAG는 한 사용자의 질문이 여러 데이터 경계를 넘나드는 구조입니다. 사용자가 Project X 문서를 볼 수 있어도 server inventory 전체를 볼 권한은 없을 수 있습니다. 의료 예시에서는 약물, 영양, clinical note가 서로 다른 접근 정책을 가질 수 있습니다. Google 발표는 RAG mechanism을 설명하지만, 실제 제품에서는 user identity, service account, corpus ACL, audit log가 같은 수준으로 중요합니다. 검색이 반복될수록 "처음 질문에 허용된 권한"이 뒤 검색에서도 그대로 강제되는지 확인해야 합니다.
이 지점에서 Gemini Enterprise Agent Platform이라는 포장도 의미가 있습니다. Google은 이 기능을 단독 research demo가 아니라 platform public preview로 발표했습니다. 기업 고객 입장에서는 Agentic RAG 자체보다 Gemini Enterprise 안에서 agent, corpus, connector, runtime, evaluation, governance가 어떻게 연결되는지가 구매 판단 기준이 됩니다. Reddit r/googlecloud의 5월 토론에서도 사용자는 custom agentic pipeline을 Gemini Enterprise에 올릴 때 ingestion endpoint와 query agent를 어떻게 붙일지 물었습니다. 답변자는 ingestion pipeline을 agent serving instance에 억지로 넣기보다 Cloud Run 또는 별도 backend로 분리하는 접근을 제안했습니다. 이 작은 토론은 enterprise RAG가 "검색 agent 하나"가 아니라 ingestion, serving, frontend, permission의 배치 문제라는 점을 보여줍니다.
경쟁 구도는 이미 복잡합니다. Microsoft는 Copilot Studio, Azure AI Search, Fabric, Purview, Entra를 묶어 업무 데이터와 권한을 잡으려 합니다. AWS는 Bedrock Knowledge Bases, OpenSearch Serverless, AgentCore 계열로 검색 backend와 agent runtime을 연결합니다. Mistral은 Search Toolkit과 RAG evaluation을 전면에 세웠고, Chroma는 Context-1 같은 retrieval-specialized model로 "RAG 이후 context 품질"을 겨냥했습니다. Google의 포지션은 Gemini Enterprise Agent Platform 안에서 model, RAG Engine, corpus routing, agent orchestration을 관리형으로 묶는 쪽입니다.
한국 AI 팀이 지금 확인할 질문은 네 가지입니다. 첫째, 사내 지식이 하나의 vector index로 충분한지, 아니면 업무 단위 corpus routing이 필요한지입니다. 둘째, 답변 실패를 "정보 없음"으로 기록할지, "검색이 부족함"으로 기록할지 구분하는 telemetry가 있는지입니다. 셋째, 평가 dataset이 single-hop FAQ에 머물러 있는지, 실제 업무처럼 두세 source를 건너야 하는 질문을 포함하는지입니다. 넷째, latency 예산입니다. Google은 cross-corpus와 single-corpus latency 차이를 평균 3% 이내라고 밝혔지만, 각 회사의 connector, network, document size, permission check는 다릅니다.
Sufficient Context Agent는 환각 방지의 만능 장치가 아닙니다. 이 에이전트도 모델 판단에 의존합니다. Retrieved snippet이 모순될 때 어떤 source를 우선할지, 최신 문서와 오래된 문서가 충돌할 때 freshness를 어떻게 반영할지, draft가 그럴듯하지만 근거가 약할 때 몇 번까지 다시 검색할지 같은 정책은 별도로 정해야 합니다. LLM-as-a-judge 평가 역시 운영에서는 사람이 검토한 golden set, regression test, domain-specific rubric와 함께 써야 합니다.
이번 발표의 실무 결론은 "RAG를 agentic하게 바꾸라"가 아닙니다. 더 구체적으로는 답변 전에 부족한 근거를 찾는 loop를 제품 요구사항으로 만들라는 쪽에 가깝습니다. 검색된 chunk, 중간 draft, missing piece, 재검색 query, 최종 citation이 trace로 남아야 운영자가 실패를 고칠 수 있습니다. RAG가 틀렸을 때 "모델이 환각했다"로 끝내면 다음 배포에서 같은 문제가 반복됩니다. 어느 corpus를 보지 않았는지, 어떤 query가 조건을 빠뜨렸는지, 충분한 근거 판단이 왜 통과됐는지까지 남아야 합니다.
Google의 6월 5일 발표는 enterprise AI agent 경쟁에서 retrieval layer가 다시 전면으로 올라왔다는 신호입니다. 모델이 길게 생각하고 도구를 호출해도, 업무 지식이 데이터 섬에 흩어져 있으면 답변은 빈칸을 남깁니다. Cross-Corpus Retrieval과 Sufficient Context Agent는 그 빈칸을 찾는 장치입니다. 개발팀이 가져갈 변화는 명확합니다. RAG 파이프라인을 "검색 후 생성"으로 설계하는 대신, "검색, 검증, 부족한 근거 추적, 재검색, 합성"의 상태 기계로 다뤄야 합니다.