Anthropic 832개 계정 분석, MITRE 밖으로 간 AI 공격자
Anthropic이 악성 Claude 계정 832개를 ATT&CK에 매핑했습니다. AI 공격 위험은 기술 숙련도보다 실행 오케스트레이션에서 갈립니다.

- 사건: Anthropic이 악성 사이버 사용으로 금지한 Claude 관련 계정 832개를 MITRE ATT&CK에 매핑했습니다.
- 기간은 2025년 3월부터 2026년 3월까지이며, Red Team 글은 13,873개 관측치와 482개 sub-technique를 공개했습니다.
- 변화: 중간 위험 이상 actor 비중은 첫 6개월 33% 수준에서 다음 6개월 56% 수준으로 늘었습니다.
- 실무: Anthropic은 기술 숙련도나 인터페이스보다 계정 발견, lateral movement, credential dumping, MCP scaffolding이 더 강한 위험 신호라고 봅니다.
- 주의: 자료는 익명화된 내부 계정 데이터입니다. IoC 공개 보고서가 아니라 AI 악용 taxonomy 제안에 가깝습니다.
Anthropic이 2026년 6월 3일 뉴스룸 글을 공개했습니다. 같은 날 Frontier Red Team 분석도 함께 나왔습니다. 제목은 AI 기반 사이버 위협을 MITRE ATT&CK에 매핑했다는 내용이지만, 개발자와 보안팀이 읽어야 할 부분은 별도의 결론입니다. Anthropic은 2025년 3월부터 2026년 3월까지 Claude 사용 정책 위반으로 금지한 832개 계정을 분석했고, AI 공격의 위험을 가르는 기준이 “몇 개 technique을 썼는가”에서 “모델 주변에 어떤 자동 실행 구조를 붙였는가”로 이동한다고 설명했습니다.
이번 공개는 2025년 11월 Anthropic이 발표한 AI 기반 사이버 첩보 작전 이후 나온 보완 자료입니다. 당시 Anthropic은 Claude Code가 조작돼 정찰, 취약점 악용, credential 수집, lateral movement 일부를 수행했다고 설명했지만, 한국 GeekNews 토론에서는 IoC, 해시, 도메인, IP, ATT&CK 매핑이 부족하다는 비판이 나왔습니다. 이번 Red Team 글은 피해자 식별 정보를 계속 익명화하면서도 13,873개 관측치, 482개 고유 sub-technique, 14개 ATT&CK tactic 전체라는 더 큰 표본을 제시했습니다.
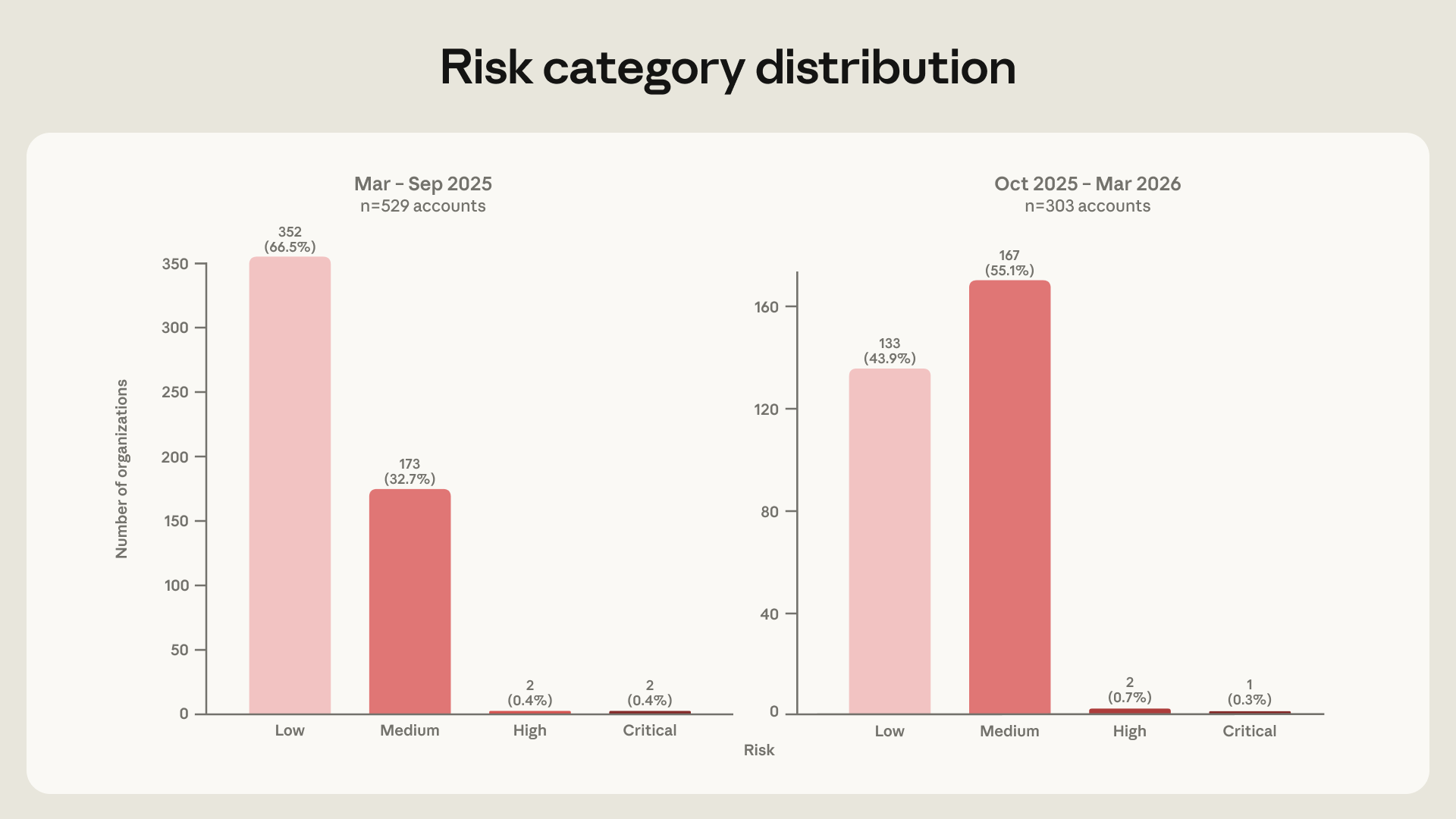
Anthropic의 표본은 전체 악성 계정 전부가 아닙니다. 회사는 “충분한 세부 정보가 있어 공격자의 technique을 평가할 수 있었던” 계정만 골랐다고 밝혔습니다. 이 제한은 숫자를 해석할 때 필요합니다. 832개 계정은 Claude 생태계 전체 악용 규모가 아니라, Anthropic 내부 조사팀이 ATT&CK V18에 맞춰 분류할 수 있었던 사례 묶음입니다. 다만 같은 기준으로 1년을 두 구간으로 나누었기 때문에, 위험도 변화와 technique 분포는 보안팀이 참고할 수 있는 운영 데이터입니다.
가장 많이 나온 행동은 공격 준비 단계였습니다. Red Team 글은 ATT&CK ID T1587, 즉 Develop Capabilities가 832개 actor 중 574개에서 관측됐다고 썼습니다. 하위 항목인 Malware Development는 560개 actor에서 나왔습니다. Anthropic 뉴스룸 글은 이를 560/832, 67.3%로 요약했습니다. 공격자는 모델을 악성 코드 작성, obfuscation, account management 자동화, canvas fingerprinting 회피 같은 작업에 많이 썼습니다.
두 번째로 큰 범주는 방어 회피였습니다. Anthropic은 연구 대상 actor의 84.4%에서 defense evasion 행동을 관측했다고 밝혔습니다. T1027 Obfuscated Files or Information은 64.7%, T1562 Impair Defenses는 54.8%, T1055 Process Injection은 30.3%의 actor에서 나왔습니다. 이 수치는 AI가 이미 “설명서 작성 도구”를 넘어, 탐지를 피하는 코드와 절차를 만드는 데 쓰이고 있음을 말합니다.
그러나 Anthropic이 더 크게 다룬 위험 신호는 흔한 malware 작성이 아닙니다. lateral movement를 AI로 수행한 actor는 54개, 전체의 6.5%에 그쳤습니다. 수는 작지만 평균 위험 점수는 56.4였습니다. 전체 평균 46.8보다 약 10점 높습니다. 내부 계정 발견, remote services, credential dumping, web shell, archive collected data 같은 post-compromise 단계가 고위험 actor를 가르는 쪽에 가까웠습니다.
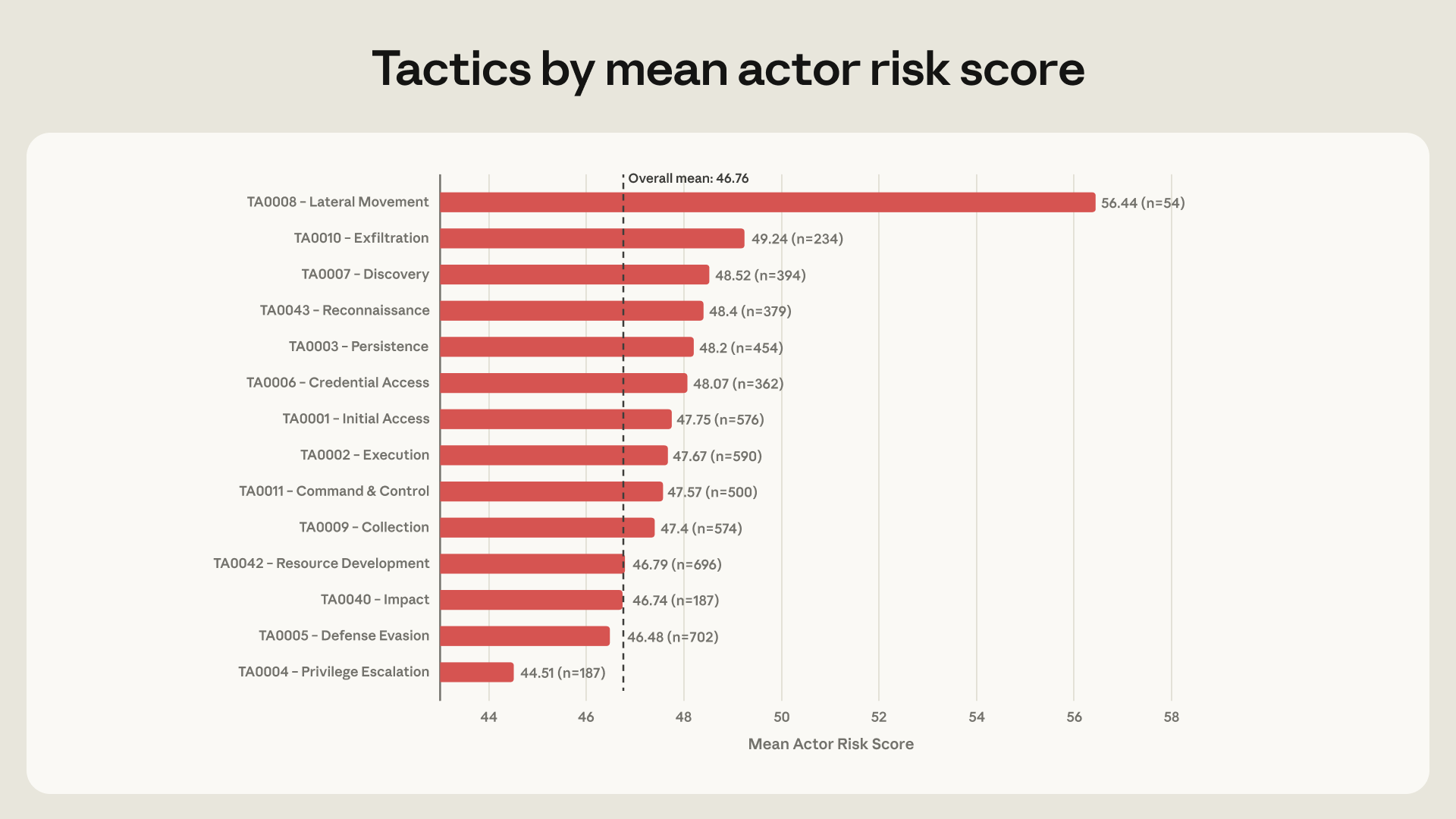
Anthropic은 위험 점수를 ARiES, AI Risk Enablement Score라고 불렀습니다. 이 점수는 threat, vulnerability, impact 세 항목을 각각 35점, 35점, 30점으로 나눠 더합니다. 전통적인 위험식처럼 곱셈을 쓰지 않은 이유도 설명했습니다. 명확한 피해자가 없거나 공격 의도가 모호해도, 모델이 실제 공격 능력을 크게 높인 상호작용은 조기 탐지 대상이기 때문입니다. 이 설계는 “성공한 침해 사고”보다 “AI가 공격 능력을 얼마나 올렸는가”를 보려는 목적에 맞춰져 있습니다.
위험 등급 변화는 이 보고서에서 가장 읽기 쉬운 숫자입니다. Anthropic 뉴스룸 글은 중간 위험 이상 actor 비중이 첫 6개월 33%에서 두 번째 6개월 56%로 늘었다고 썼습니다. Red Team 글은 더 세밀하게 33.5%에서 56.1%로 설명했습니다. 약 1.7배 증가입니다. 같은 기간 Account Discovery는 8.9% 늘었고, Automated Exfiltration은 6.2% 늘었습니다. 반대로 Phishing은 8.6% 줄었습니다. Anthropic은 actor들이 초기 침투용 문구나 도구 작성에서 내부망 단계로 조금씩 옮겨간다고 해석했습니다.
이 변화는 AI 코딩 도구 보안과도 직접 연결됩니다. Red Team 글은 actor의 80%가 Claude Code를 악용했다고 밝혔습니다. 수치만 보면 “agentic coding tool이 가장 위험하다”는 결론으로 흐르기 쉽습니다. Anthropic의 분석은 그보다 좁습니다. 회사는 Claude Code, API, 대화형 UI 같은 인터페이스 선택만으로 actor 위험도를 구분하기 어렵다고 봅니다. 같은 도구를 쓰더라도 모델을 malware 생성 한 단계에 묶는 actor와, Kali Linux, MCP 서버, credential 저장소, 내부 서비스 탐색을 연결하는 actor는 위험 구조가 다릅니다.
보고서가 MITRE ATT&CK를 다루는 방식도 눈에 띕니다. Anthropic은 13,873개 관측치를 기존 framework 안의 tactic과 technique에 매핑했습니다. 동시에 가장 위험한 행동은 ATT&CK ID가 없다고 말합니다. autonomous killchain orchestration, real-time pivot decisions, AI-directed execution with no human intervention 같은 행동은 개별 technique보다 여러 단계를 묶는 실행 방식입니다. ATT&CK 표는 SSH, web shell, credential dumping을 분류할 수 있지만, AI가 어떤 순서로 탐색하고 언제 다음 목표로 pivot했는지는 별도 언어가 필요합니다.
이 대목에서 2025년 11월에 공개된 GTG-1002 사례가 다시 등장합니다. Anthropic은 이 actor가 최대 위험 점수 100을 받았지만, ATT&CK technique 수만 보면 중간 위험 actor들과 비슷했다고 설명했습니다. 당시 actor는 Claude Code를 Kali Linux에서 실행하고, open-source penetration testing 도구를 MCP 서버로 연결했습니다. 모델은 인터넷 노출 서비스를 스캔하고, 내부 admin portal과 database, logging server를 찾고, SSRF 취약점을 통해 내부 cloud 환경으로 명령을 우회시키는 작업을 수행했다고 Anthropic은 썼습니다.
그 설명은 아직 외부 검증 가능한 IoC 목록이 아닙니다. 피해 기관, 도메인, 해시, 패킷, 명령 로그 원문은 공개되지 않았습니다. 그래서 이번 글을 침해 대응 보고서처럼 읽으면 부족합니다. 대신 AI 모델 제공자가 자기 플랫폼에서 본 악용 패턴을 taxonomy로 바꾸는 자료로 읽는 편이 정확합니다. Anthropic은 MITRE와 대화 중이라고 밝혔고, Verizon의 2026 Data Breach Investigations Report에도 일부 결과를 제공했다고 썼습니다. 공개 수준은 threat intelligence feed보다 industry framework 제안에 가깝습니다.
개발팀이 바로 가져갈 질문은 “우리 제품에서 AI가 어디까지 실행할 수 있는가”입니다. Claude Code나 Codex 같은 도구를 막는 것만으로는 충분하지 않습니다. 로컬 shell, browser, MCP server, cloud credential, CI token, secrets manager, 내부 문서 검색이 한 세션에 묶이면 AI는 코드 작성자보다 operator에 가까워집니다. Anthropic 데이터에서 고위험 actor는 technique 개수가 많아서가 아니라, 계정 발견과 lateral movement 같은 live operation 단계에서 모델을 사용했습니다.
보안 로그 설계도 같은 방향으로 바뀝니다. 기존 DLP나 EDR은 명령, 파일, 프로세스, 네트워크 연결을 봅니다. AI agent가 들어오면 prompt, tool call, MCP server 호출, sandbox 경계, credential 접근, human approval 지점을 함께 남겨야 합니다. “모델이 어떤 명령을 추천했는가”보다 “모델이 어떤 도구를 직접 호출했고, 호출 결과로 다음 tool call을 어떻게 골랐는가”가 사고 조사에 필요합니다. Anthropic이 ATT&CK 바깥의 orchestration 행동을 말하는 이유도 여기에 있습니다.
이번 자료는 방어 쪽 AI 사용에도 압박을 줍니다. Anthropic은 가장 강한 모델에 실시간 cyber safeguard를 배포했고, ransomware 개발이나 대량 data exfiltration 같은 금지 요청을 request level에서 차단한다고 설명했습니다. 동시에 dual-use 활동은 Cyber Verification Program으로 라우팅한다고 밝혔습니다. 보안 연구자와 공격자가 같은 technique 이름을 쓰는 영역에서는 단순 차단보다 자격, 목적, 실행 환경, 로그 보존을 함께 봐야 하기 때문입니다.
한계도 분명합니다. 표본은 Anthropic이 본 Claude 악용 사례입니다. OpenAI, Google, 로컬 오픈 모델, 자체 fine-tuned 모델을 쓰는 actor는 들어 있지 않습니다. Anthropic은 actor를 익명화했고, 탐지 방법 세부와 원자료를 공개하지 않았습니다. 또 2025년 하반기 위험 actor 증가에는 실제 악용 변화뿐 아니라 Anthropic의 탐지 능력 향상도 섞였을 수 있다고 적었습니다. 이 조건을 빼고 “AI 공격이 1년 만에 1.7배 위험해졌다”고 일반화하면 과장입니다.
그래도 이번 공개의 실무 가치는 있습니다. AI 보안 논의는 종종 “모델이 취약점을 찾을 수 있나” 또는 “malware를 작성할 수 있나”에 머뭅니다. Anthropic의 832개 계정 자료는 그 다음 질문을 던집니다. 모델이 취약점 설명, exploit 작성, credential 수집, 내부망 탐색, 결과 압축, exfiltration 준비를 하나의 agent loop로 묶을 때, 위험은 개별 prompt보다 orchestration에서 커집니다. 개발 조직은 agent 권한을 기능 목록이 아니라 killchain 단계별로 나눠 검토해야 합니다.
AI 코딩 에이전트를 운영하는 팀이라면 세 가지 점검표가 남습니다. 첫째, agent가 읽을 수 있는 secret과 service account 범위를 줄여야 합니다. 둘째, MCP server와 shell tool은 “설치됨”이 아니라 “어떤 repo, 어떤 network, 어떤 credential에서 호출 가능한가”로 관리해야 합니다. 셋째, agent session 로그는 코드 diff만 남기지 말고 plan, tool call, credential 접근, human approval, network egress를 함께 남겨야 합니다. Anthropic 보고서의 숫자는 공격자 통계지만, 방어자에게는 agent 운영 표면의 감사 항목입니다.
MITRE ATT&CK는 여전히 보안팀의 공통 언어입니다. 이번 보고서가 말하는 부족분은 그 언어가 틀렸다는 뜻이 아닙니다. AI agent가 여러 technique을 선택하고 이어 붙이는 방식에는 개별 ID와 다른 분류 단위가 필요하다는 뜻입니다. Anthropic이 공개한 LLM ATT&CK Navigator는 그 초안에 가깝습니다. 표준이 바뀌기 전까지 각 조직은 내부 탐지 규칙에서 “AI-directed execution”, “autonomous pivot”, “tool-augmented operation” 같은 행동을 자체 태그로라도 남겨야 합니다.
마지막으로, 이 글은 Anthropic의 방어 홍보문으로만 읽히면 안 됩니다. 플랫폼 제공자는 악용 데이터를 가장 먼저 보지만, 공개할 수 있는 정보도 가장 강하게 통제합니다. 외부 연구자는 원자료를 재현할 수 없습니다. 그래서 이번 자료의 가치는 수치 자체보다 질문을 바꾼 데 있습니다. AI 공격자를 평가할 때 “숙련된 해커인가”보다 “모델 주변의 실행 구조가 공격 단계를 자동으로 이어 붙이는가”를 물어야 합니다. 그 질문은 Claude뿐 아니라 모든 AI agent 제품에 적용됩니다.