Microsoft Foundry adds an ROI loop for production AI agents
Microsoft Foundry now ties agent traces, rubric evaluation, optimization, and ROI dashboards into one Agent DevOps loop.

- What happened: Microsoft expanded Foundry agent observability on June 3, 2026.
- The release adds any-framework tracing, multi-turn evaluation, rubric evaluation, trace replay, agent optimization, and ROI reporting around Foundry's GA tracing and evaluations.
- Operating unit: prompts, model calls, tool invocations, and sub-agent hops are collected as
OpenTelemetrytraces.- Microsoft names LangChain, LangGraph, the OpenAI SDK, Microsoft Agent Framework, and custom frameworks as targets.
- Developer impact: agent quality work moves from demo success rates toward trace replay, rubric scores, regression datasets, and cost efficiency.
- Watch: Agent optimizer and ROI for agents are still in private preview, and real ROI depends on each customer's task definitions and cost attribution model.
Microsoft published a Foundry Blog post on June 3, 2026, expanding its AI agent observability features after Build 2026. The post opens with the line that shipping an AI agent is the easy part. The more useful reading is that Microsoft is trying to define production agent operations around traces, evaluations, optimization, and ROI dashboards rather than around a successful demo. Foundry tracing and evaluations have reached general availability, while the Build update adds public previews that connect multiple frameworks and deployment locations into Foundry observability.
This release sits in a different layer from Microsoft's other Build 2026 agent announcements. Hosted agents describe a runtime. Work IQ APIs expose Microsoft 365 work context and action surfaces. MXC and MDASH cover execution isolation and security validation. The June 3 Foundry observability article focuses on what a production agent actually did, where quality degraded, and whether the run produced enough business value for its cost.
Microsoft is not describing a deterministic software failure model. A normal service usually follows a stable path for the same input and same code. An agent may search first on Monday, call a sub-agent first on Tuesday, and choose a different tool route after a model or prompt update. The Foundry Blog says drift can appear quietly after model updates, tool changes, and traffic pattern changes. That matters because error rate and latency alone do not tell an operations team whether an agent is still completing the user's workflow correctly.
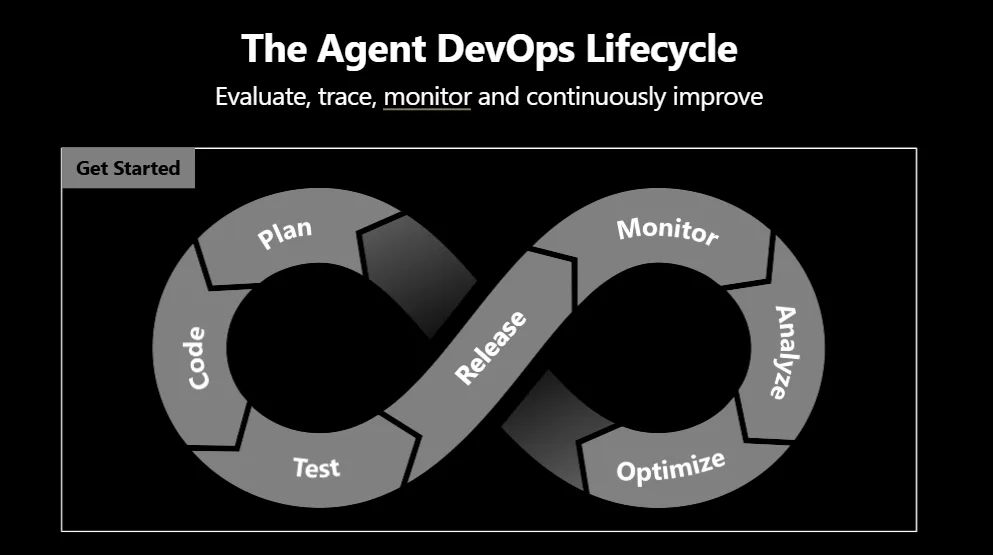
Foundry observability is organized around four verbs. Trace records prompts, model calls, tool invocations, and sub-agent hops as end-to-end telemetry. Evaluate scores quality, safety, and task completion for single-turn and multi-turn interactions. Monitor connects production issues to Azure Monitor alerts and dashboards. Optimize turns traces and evaluation results into candidate improvements. Those labels are not just product packaging. They map to the data types teams need to retain if they want to debug agent behavior after deployment.
The first Build 2026 public preview is interoperability. Foundry tracing and evaluations now extend to LangChain, LangGraph, the OpenAI SDK, Microsoft Agent Framework, and custom frameworks. The connection point is OpenTelemetry. For teams that already emit agent runs as OTel spans, the starting point is sending those spans toward Foundry. Microsoft uses the phrase "any agent, on any framework," but adoption will depend on whether each framework's span structure, tool metadata, and handoff details remain understandable inside the Foundry evaluation UI.
That question intersects with existing observability choices. Teams already using LangSmith, Braintrust, Arize Phoenix, or a custom OpenTelemetry collector need to decide whether Foundry becomes a new trace store, an enterprise plane tied to Azure Monitor, or a specialized UI for Foundry-hosted agents. Microsoft's advantage is the ability to connect Azure Monitor, Foundry Agent Service, Microsoft Agent Framework, and Agent 365. The tradeoff for multi-cloud organizations is a fresh review of trace export, data residency, and where evaluator model calls run.
The second group of features pulls evaluation closer to the development loop. The azd observability developer experience is in public preview for Azure Developer CLI. Microsoft says developers can enable observability while creating a hosted agent, then inspect the first execution trace and evaluation result from the terminal or VS Code. That placement matters. If debugging lives only in a separate dashboard, teams often keep editing prompts without looking at the failing trace. Microsoft is trying to make the trace part of the developer's first feedback cycle.
User simulation is also in public preview. Microsoft describes automatic generation of realistic test conversations and edge-case scenarios before real users reach the agent. That is most useful for customer support agents, compliance reviewers, and workflow agents where state carries across many turns. Handwritten conversations rarely cover enough failure modes, and model changes make regression testing hard to repeat. Simulation does not replace production traffic, but it can expand the pre-release regression suite.
Multi-turn evaluation targets a common blind spot. A single answer can look correct while the agent loses the user's goal by the fifth turn, changes tone halfway through the workflow, or misremembers an earlier tool result. Microsoft says multi-turn evaluation checks context carryover, reasoning consistency, and end-to-end task success. For scheduling, order changes, incident triage, and support workflows, the question is not only whether one response was right. The workflow has to end with the correct action.
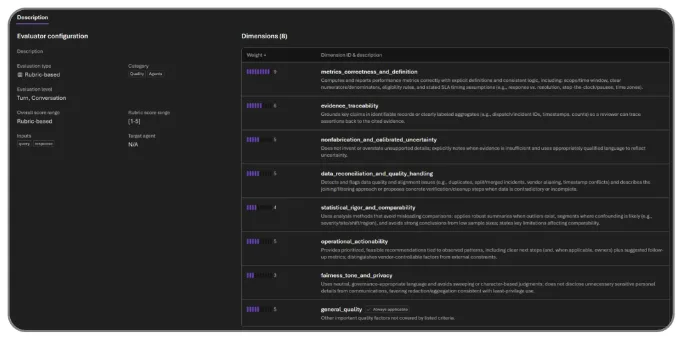
Rubric evaluator is the most product-shaped feature in the announcement. Microsoft says a vendor history agent, customer support agent, and compliance reviewer each need a different definition of "good." Rubric evaluator derives context-aware criteria from the intended behavior of the agent, then weights dimensions such as task success, tone, safety, cost, and latency. Foundry can then run those rubrics alongside its built-in safety and quality evaluators as a scorecard. In practice, the evaluation criteria become an artifact outside the prompt itself.
That addresses a recurring problem for teams using LLM-as-judge systems. Generic rubrics such as "accurate and helpful" can be attached to almost any agent, but the cost of failure differs by workflow. A vendor history agent giving the wrong contract date is not the same failure as a support agent using a stiff tone. A compliance reviewer should often stop when it lacks a source document rather than guess. Rubric evaluator will be useful only if generated rubrics are reviewed by humans and versioned with the same discipline as prompts and tests.
Intelligent trace sampling deals with evaluation cost. Running an evaluator over every production trace can become expensive. Evaluating none of them hides quality regressions. Microsoft says it selects signal-rich interactions for curated evaluation samples. The effectiveness depends on the sampling conditions. High-cost runs, sensitive tool calls, long conversations, low-confidence outputs, repeated retries, and known failure patterns need to be represented. Otherwise the dashboard may look clean while the risky traces are omitted.
Trace replay and visualization connect directly to incident review. Microsoft says teams can visually follow and replay prompts, decisions, tool calls, and model outputs. Instead of guessing the original user sentence or rerunning a rough simulation, developers can send the broken execution trace through candidate fixes. That is a large difference for coding agents and business workflow agents. If a system saves only the final model response, it loses the reason an email was sent, a file was modified, or a handoff happened. Tool inputs, tool outputs, intermediate state, and sub-agent handoffs need to remain inspectable.
Traces to dataset narrows the distance between production incidents and offline evaluation. Microsoft says production traces can become structured evaluation datasets. That is release engineering infrastructure: a real user failure can become part of the next regression dataset. It is also data governance work. Production traces may include user prompts, Microsoft 365 documents, source code, incident logs, support transcripts, tool outputs, and personal data. Turning traces into datasets requires masking, retention rules, deletion workflows, and access controls.
| Feature | Build 2026 status | Question to check |
|---|---|---|
| Tracing and evaluations | GA; any-framework expansion is public preview | Are existing OTel spans and tool metadata preserved inside Foundry? |
| Rubric evaluator | Public preview | Will domain experts review and version workflow-specific rubrics? |
| Trace replay | Public preview | Can failure traces become incident-review evidence and release gates? |
| ROI for agents | Private preview | Who defines task completion, time saved, and cost efficiency? |
Agent optimizer is in private preview. The Foundry Blog says it reads the agent's current prompts and skills, searches for configuration candidates that improve quality under stated scenarios and constraints, and provides diffs, lineage, audit trails, and rollback. A separate Microsoft Command Line post explains the loop in more detail. The optimizer treats instructions, models, skills, and tool definitions as a search space, then compares the baseline and candidates with an evaluator suite. Candidate changes are reviewed by a developer rather than deployed automatically from a score alone.
That makes prompt engineering look more like CI. Many teams currently edit an instruction, run a few examples, and wait to see whether production improves. For an optimizer to be useful, candidate generation is less important than comparison discipline. Baseline and candidate runs need the same dataset, same evaluator, and same cost constraints. Teams also need to see tradeoffs by dimension. "Better" is not an operating decision. "Routing accuracy improved, but latency and model spend increased" is closer to the decision an owner can make.
ROI for agents is also in private preview. Microsoft says Foundry will show task completion rates, time saved, and cost efficiency in the portal and through APIs, with version comparison, daily trends, and low-ROI trace drill-down. The announcement explicitly frames this as answering the question a CFO would ask. That reflects the current pressure on enterprise agent deployments. The 2025 and 2026 demo wave showed that many workflows are possible. Buyers now ask how often they succeed, how much they cost, and which workflow produced measurable value.
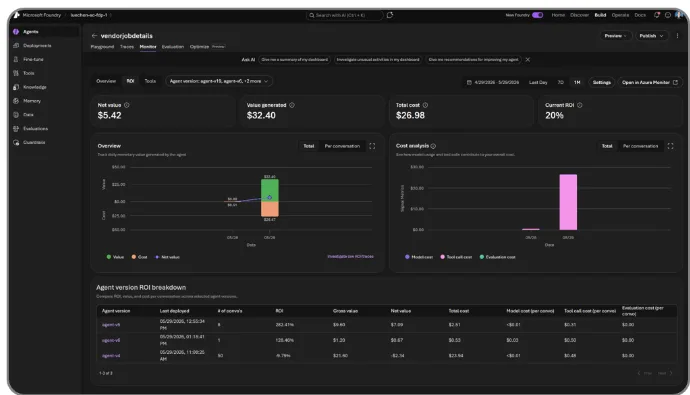
The difficult part of an ROI dashboard is not token cost. Token usage, model calls, tool calls, and latency are relatively easy to measure. Time saved requires a workflow-specific baseline. Task completion rate requires a human definition of success. Cost efficiency needs to include failed runs, retries, escalation mistakes, and review work. If an incident triage agent saves 20 minutes but creates one bad escalation, a simple time-saved chart overstates the value. Foundry's low-ROI trace drill-down exists because aggregate charts cannot answer that question by themselves.
This announcement also connects to Microsoft's broader agent governance stack. On June 2, the Foundry Blog introduced ASSERT and the Agent Control Specification as open evaluation and control components. Work IQ opens workplace data and action surfaces. Agent 365 handles inventory and governance. Foundry observability collects traces and evaluation results. ROI for agents asks whether those runs produced business value relative to cost. These are separate products, but Build 2026 arranges them as parts of an enterprise agent operating system.
The competitive field is already dense. LangSmith is strong inside LangChain and LangGraph tracing and evaluation. Braintrust emphasizes evaluation datasets, experiments, and prompt iteration. Arize Phoenix offers open-source observability and tracing. OpenAI Evals and Promptfoo are often used for specific regression and evaluation flows. Microsoft Foundry's differentiation is not one evaluator feature. It is the connection to Azure Monitor, Foundry Agent Service, Microsoft Agent Framework, Agent 365, and Microsoft 365 deployment paths. The constraint is that teams have to accept a more Azure-centered operating model.
For teams evaluating the announcement, the first question is not whether to adopt Foundry. If a production agent already exists, the first audit is what the current traces omit. Does the system store only model input and output, or does it include tool calls, tool results, sub-agent handoffs, user approvals, policy violations, and intermediate state on one timeline? Without those fields, any observability product will have weak failure analysis.
The second question is evaluation ownership. Even if Rubric evaluator generates a useful first draft, final criteria should involve product owners, security reviewers, domain experts, and support leaders. A support agent's tone, a legal agent's citations, a coding agent's test pass condition, and a finance agent's calculation tolerance cannot be owned by one generic AI platform team. If evaluation scores become release gates, rubric changes need review history just like code and prompt changes.
The third question is cost attribution. ROI for agents can show task completion and cost efficiency only if each agent run is tied to a user, team, customer, workflow, or business process. Instrumentation that stops at model cost produces a monthly usage number, not an operating decision. The useful question is which workflow produced low-ROI traces and which tool step created the failure cost. That data model has to be designed before the dashboard can be trusted.
The fourth question is data retention. Traces to dataset is attractive because it converts production failures into regression coverage. It also turns operational records into evaluation assets. Microsoft 365 documents, customer transcripts, source code, and incident logs can all appear inside a trace. Teams need masking, retention periods, access control, and deletion workflows before they promote production traces into reusable datasets.
Early community discussion around the specific Foundry ROI feature was limited when the Korean article was prepared. Hacker News and GeekNews did not show a large standalone thread on the ROI announcement. A Korean Build 2026 recap did call out Rubric Evaluator and Agent Optimizer as features that read production traces to generate evaluation criteria and improvement candidates. Broader developer discussion around agents remains focused on cost, quotas, quality swings, and missing governance. Microsoft's ROI dashboard does not make agents cheaper by itself, but it can show where the cost is leaking.
The practical conclusion is narrow. Production agent operations cannot stop at "did the answer look good?" Teams need to know which prompt and tool route was used, whether a multi-turn goal survived to the final action, which rubric dimension failed, whether the same trace breaks on a new version, and whether the run produced time savings or cost efficiency. Microsoft's new Foundry features try to combine those questions into one Agent DevOps loop.
Three metrics will decide how much this matters outside Microsoft's own stack. First, any-framework tracing has to preserve complex LangChain, LangGraph, and OpenAI SDK handoffs without flattening away the useful metadata. Second, Rubric evaluator has to produce criteria stable enough for domain expert review and release gates. Third, when ROI for agents leaves private preview, customers need enough control over task completion, time saved, and cost efficiency definitions. The operating bottleneck for production agents is moving from model choice toward trace quality, evaluation ownership, and cost attribution.