Lyft AI Assist cuts support-agent development from six months to two weeks
Lyft showed how LangGraph and LangSmith turned customer-support agents into a self-serve platform with routing, state, evals, and prompt CI.

- What happened: Lyft described a customer-support agent platform built on
LangGraphandLangSmith.- The company says new configurable-agent development fell from roughly six months for the first driver agent to about two weeks.
- Architecture: A meta agent classifies rider and driver requests, then routes work to specialist subagents.
- Operations: Lyft attaches LLM-as-a-judge evaluation to 100% of production agents and pages engineers when error rate exceeds 5% or p95 latency exceeds 10 seconds for 15 minutes.
- The production story is not a builder UI alone; it is routing, state, tracing, rollout gates, and prompt governance.
- Watch: The remaining bottleneck is prompt quality, eval reliability, and disciplined rollout ownership rather than model access.
LangChain published a guest post from Lyft's SCX Data Science and MLE team on May 27, 2026. The post describes a multi-agent customer-support platform built with LangGraph and LangSmith. Lyft says the platform reduced the time needed to build a new configurable agent from roughly six months for the first driver agent to about two weeks, and that AI Resolution Rate increased by 16% after several self-serve agents launched. The useful part for builders is not only the number. It is the operating system behind the sentence "non-engineers can create agents."
Lyft AI Assist handles support work for riders and drivers, including account access, damage claims, charge reviews, and earnings disputes. The LangChain post says the system processes millions of rider and driver interactions. Lyft's earlier approach started in 2023: domain experts defined workflow behavior, then machine-learning engineers and software engineers translated that behavior into tool configuration and prompts. By 2026, new user segments, issue types, and autonomous-vehicle support needs made that loop too slow.
The question Lyft asked was about authority, not only model quality. Can the operations team, voice-of-customer leads, and product managers who understand support issues create agents directly? That question now sits at the center of enterprise agent platforms. OpenAI, Google, Anthropic, Microsoft, Salesforce, and ServiceNow all talk about agent builders. In production support, however, a prompt editor is not enough. The platform needs a router, state, safety checks, traces, evals, rollout rules, and a clear path for rollback.
The router comes before the agent
Lyft's architecture centers on a meta agent. The LangChain post says the system follows LangGraph's router multi-agent architecture: the meta agent acts as a stateful router, classifies each incoming request, then dispatches it with Command(goto=...) to the correct specialized subagent. Each subagent is its own StateGraph and is registered as a subgraph node under the meta agent.
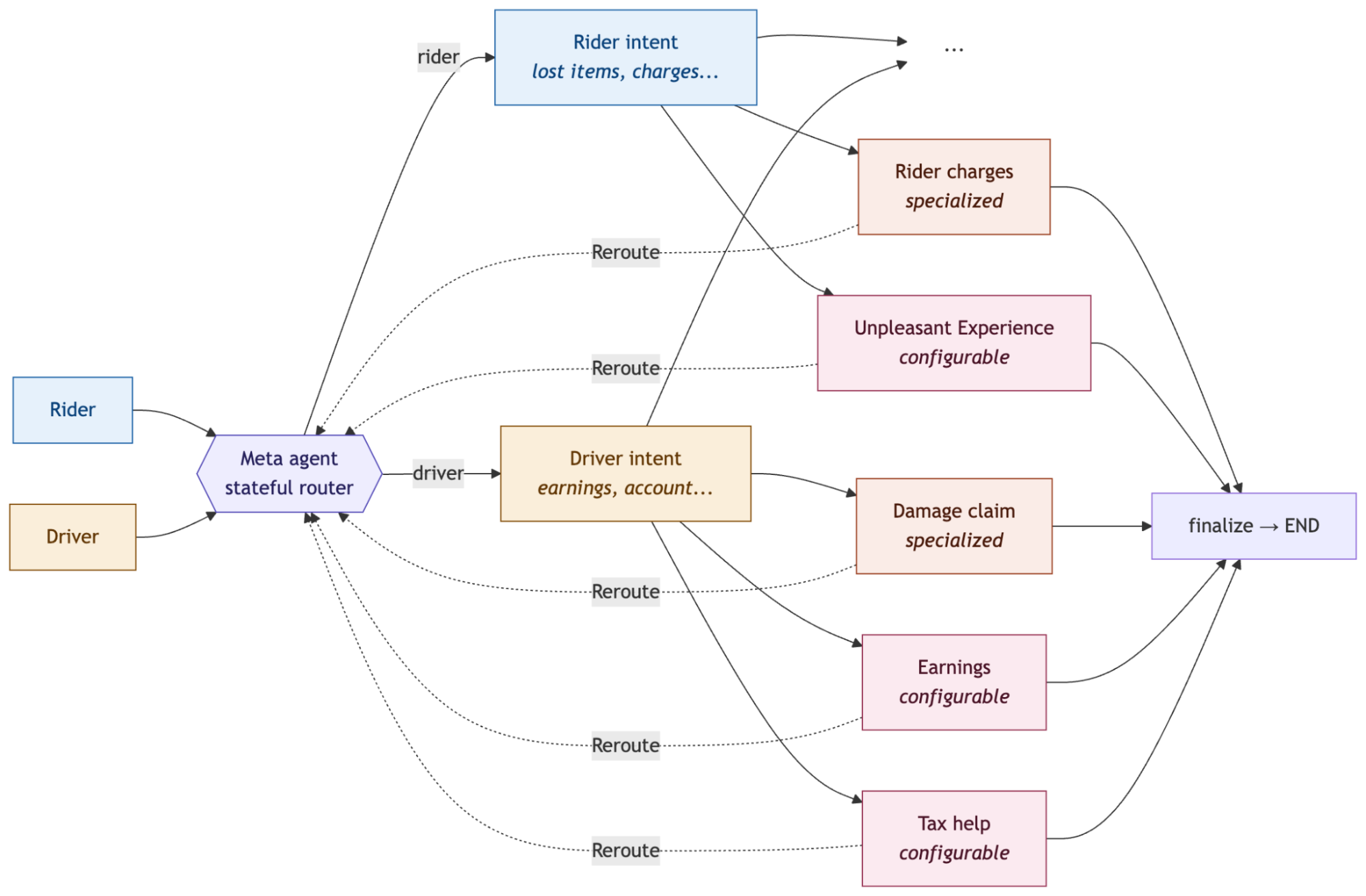
Lyft runs separate router instances for rider and driver support. When a rider contacts support, the meta agent first sends the request to a rider_intent subagent that classifies categories such as lost items, charge disputes, and trip issues. Driver requests go through a driver_intent subagent for areas such as earnings, account access, and damage claims. If the conversation needs a more specialized agent, the intent agent returns control to the parent meta agent with Command(goto=..., graph=Command.PARENT), and the meta agent routes the conversation again.
This matters because self-serve agent creation does not mean "add one more prompt." A new agent becomes a subgraph under the meta graph and runs inside explicit routing and handoff rules. Real support conversations often shift topics, hit policy boundaries, or move toward high-stakes actions. Without a router, an agent is left to improvise inside its own prompt.
Lyft also standardizes the shape of each subagent. The first shared property is safety. Malicious-intent detection and safety-issue detection run on every turn through LangGraph's Command(goto=[...]) fan-out before the system proceeds to LLM reasoning. The second property is modularity. New agents are added by defining a new subgraph and registering it with the meta agent.
Self-serve agents are loaded from JSON and prompts
Lyft separates agents into two broad groups. Specialized agents are built directly by MLEs for high-risk workflows. A damage-claim agent can involve image processing, fraud detection, multi-step classification, and automation calls, so Lyft does not push that entire workflow into a low-code layer. Configurable agents are the self-serve layer. Their JSON configuration lives in an internal config service, and their prompts are loaded from LangSmith Prompt Hub.
The split is practical. If every agent is delegated to domain experts, the risk profile rises quickly. If every agent requires MLE implementation, the system cannot move fast enough. Lyft's design moves agent creation to the right owner based on risk. A product manager can create a driver tax-question agent by writing prompt and JSON configuration while the platform handles graph construction, tool binding, safety gates, and state management. Image fraud or payment-dispute workflows stay with hand-built specialists.
In this model, a prompt is not decorative prose. Lyft later says prompt quality became a larger bottleneck than infrastructure. A domain expert may understand an issue type deeply but still fail to convert that knowledge into instructions a model can follow consistently. "Respond empathetically" is not a support policy. A production prompt has to specify tool-unavailable states, topic changes, out-of-scope requests, escalation conditions, and terminal actions.
Support agents need replayable state
Multi-turn support conversations are a poor fit for stateless chat completion. Users challenge earlier answers, add new evidence, and introduce another issue inside the same conversation. Lyft built a custom DynamoDBSaver that implements LangGraph's BaseCheckpointSaver interface. Each checkpoint stores full graph state, execution metadata, and a reference to the parent checkpoint.
That design directly supports debugging and replay. If a driver reports that a response was confusing, the team can inspect the trace and checkpoint path to see whether the problem came from intent classification, a tool call, or the final LLM response. LangChain's post says the team can pull the exact trace, review node inputs and outputs, inspect tool calls and final responses, and fix some issues within hours.
Agent-platform discussions often compress this category into the word "memory." Lyft's implementation is more specific. The important artifact is not only what the assistant remembered about a user; it is the graph state, execution metadata, parent checkpoint, and replayable path through the conversation. In customer support, where disputes and policy constraints matter, knowing which node called the next node and why is often more useful than a generic long-term memory feature.
LangSmith becomes a rollout gate
Lyft runs LANGSMITH_TRACING=true across development, staging, and production. Traces include graph execution, LLM input, tool calls, token usage, and latency. Lyft also attaches custom metadata such as user type, agent name, intent, and conversation ID so teams can filter and debug production behavior. That instrumentation is what keeps self-serve from becoming blind delegation by the central platform team.
Evaluation is tied to rollout. Before an agent reaches 100% traffic, Lyft starts with a 5-10% production rollout. The team samples real conversation traces into an evaluation dataset, extends a shared LangSmith Prompt Hub judge prompt with agent-specific metrics, and runs LLM-as-a-judge evaluation. Lyft says every production agent has an automated LLM-as-a-judge pipeline.
The monitoring dashboard tracks run volume, error rate, p50 and p95 latency, token usage, tool-call success rate, and LLM-as-a-judge score. Lyft also disclosed PagerDuty thresholds: if error rate is above 5% or p95 latency is above 10 seconds for 15 minutes, an on-call engineer is paged. Those numbers are useful reference points because they put agent quality, latency, and tool health in the same production support surface.
Prompts become product specifications
Lyft's most practical lesson is prompt discipline. The team initially expected the hardest problems to be platform infrastructure: tool binding, graph edge cases, and state management. The actual bottleneck was prompt quality. Domain experts knew the issue types, but early prompts sometimes described the happy path while omitting topic changes, tool failures, and boundary cases.
Lyft created a structured prompt-writing framework. Required components include identity, primary objective, scope, phased workflow, and content guidelines. The primary objective must use concrete verbs rather than vague help language. Scope must define both in-scope and out-of-scope cases, including the routing action for out-of-scope requests.
The phased workflow requires entry conditions, branching, and terminal actions. Content guidelines use specific do and don't rules plus example phrasing. The checklist treats prompts as reviewable product specs with questions such as whether every phase has an exit condition.
That framing is important. A code comment is read and passed over. A product specification has inputs, boundaries, failure modes, exit conditions, and acceptance criteria. In a self-serve agent platform, a prompt written by a PM or operations lead sits between engineering artifact and policy artifact. It needs versioning, review, linting, and CI.

Lyft is also building a Git-backed prompt linting pipeline. After a domain expert finishes a prompt in the builder UI, a pull request opens in the configuration repository. CI runs in two layers. Fast static rules catch malformed template variables, duplicate intent slugs, and spelling errors. LLM-powered rules look for prompt-injection vulnerability, contradictory instructions, and structural dead ends. Violations block the merge, and authors receive inline feedback in the UI so they can revise without MLE help.
The workflow resembles recent coding-agent delivery. Codex, Copilot cloud agent, and other coding agents create pull requests, and CI validates the changes. In Lyft's case, the artifact is prompt and configuration rather than application code. The broader point is that prompt governance is moving into software delivery pipelines rather than sitting only in legal or policy documents.
The numbers need operating context
Lyft's results are strong. Configurable-agent development fell from roughly six months to about two weeks. One hundred percent of production agents have automated LLM-as-a-judge evaluation. Hallucination and contradiction rates fell 20% after LangSmith evaluation metrics were used to configure guardrails. AI Resolution Rate rose 16% after several self-serve agents launched.
Those numbers should not be read as "buy an agent builder and the work is done." Lyft already has an MLE team, an internal config service, DynamoDB checkpointing, PagerDuty operations, LangSmith dashboards, evaluation datasets, and a prompt-review process. Self-serve does not remove infrastructure. It moves repeated ownership closer to domain experts while the platform team owns guardrails, tracing, and release mechanics.
LLM-as-a-judge also carries assumptions. Lyft samples production traces, runs evaluators, and adds agent-specific metrics. A judge model is still a model. Prompt injection, policy ambiguity, subtle customer harm, and regional compliance issues cannot be assumed away. Lyft's roadmap includes pairwise evaluation and human reviewers because automated judging is useful but not complete.
Competition shifts toward operational primitives
The competitive comparison is not just LangGraph versus another framework. Customer-support agent products include Sierra Agent OS, Intercom Fin, Zendesk AI, and Salesforce Agentforce. Runtime and framework options include OpenAI Agents SDK, Google ADK, CrewAI, AutoGen, and internal Temporal-based runners. Observability choices overlap across LangSmith, Langfuse, Arize Phoenix, Honeycomb Agent Timeline, and Datadog LLM Observability.
Lyft's case shows the tradeoff of building production support agents on an open framework. The advantage is control: routing, checkpointing, prompt lifecycle, rollout metrics, and policy boundaries can be shaped around Lyft's support workflows. The cost is that a real platform team has to exist. Self-serve is not self-running. The more domain experts create agents, the stronger the central system needs to be around linting, evals, traces, permissions, and rollback.
The question often missing from agent-platform marketing is who edits the agent. If only MLEs can edit it, the workflow is safer but slow. If operations teams can edit it immediately, the workflow is faster but risky. Lyft places graph runtime, prompt templates, config pull requests, evaluation CI, monitoring dashboards, and alerts between those two extremes. Without those pieces, a two-week deployment target can turn into a demo that never earns production trust.
Simulation and continuous scoring come next
Lyft's next work includes completing prompt linting, adding mocking and simulation infrastructure, building pairwise evaluation, expanding Freenow Europe and autonomous-vehicle support, and continuously scoring all production traces. That roadmap points to where agent operations are heading.
Before opening 5-10% of real customer traffic, teams need synthetic conversations and mocked tool responses that reproduce failure modes. A prompt revision can then be compared through A/B tests and human review instead of being judged only after live deployment.
Simulation is especially important for support agents. Refunds, safety issues, account access, and earnings disputes create low-frequency edge cases with high operational risk. Production trace sampling may not surface rare failures quickly enough. Mocked tool responses and synthetic conversations can inject tool timeouts, contradictory user input, policy boundaries, and abuse attempts before customers encounter them.
Continuous scoring has its own cost and reliability questions. Evaluating every production trace with a judge model increases token spend, introduces judge drift, and can create false-positive alerts. Sampled evaluation, however, can detect degradation late. Lyft's mention of automatic prompt-degradation alerts treats the agent as a product that continues to change after release, not as a workflow frozen at launch.
Builder takeaways
The first checkpoint from Lyft's post is routing. A meta router plus specialist subagents makes intent changes and handoffs explicit in a way a single all-purpose support agent usually cannot. The second is checkpointing. Multi-turn support needs replayable state and node-level inspection for incident analysis. The third is prompt CI. As more prompt authors enter the system, instruction quality needs review checklists and lint rules.
The fourth checkpoint is rollout. Agent launches should look more like feature flags: 5-10% traffic, real trace sampling, evaluation datasets, judge metrics, monitoring dashboards, and alert thresholds. The fifth is role design. Domain experts write prompts and configurations. The platform team owns graph and guardrail infrastructure. On-call engineers watch latency and error rates. Without that division, "non-engineers can create agents" can become "nobody knows who is responsible for the agent."
Lyft AI Assist offers more useful detail than the usual agent-platform slogan. The six-month-to-two-week reduction is the headline. The operational lesson is that prompts become product specifications, traces become the system of record, and evals become release gates. For teams putting customer-support agents into production, the self-serve platform is not the builder UI. It is the combined system of graph, state, safety, eval, CI, and alerts.