Datadog says rate limits caused 60% of LLM call errors
Datadog State of AI Engineering 2026 shows how production LLM apps fail on quotas, routing, prompt cache, and context growth, not only model quality.

- What happened: Datadog published State of AI Engineering 2026 with production telemetry from LLM applications.
- In February 2026, 5% of LLM call spans reported an error, and 60% of those errors were rate-limit violations.
- Why it matters: Agent reliability now depends on
quota, fallback policy, prompt caching, and context budgets, not just model accuracy. - Watch: Datadog says more than 70% of organizations use at least three models, while prompt caching appears in only 28% of eligible model-call spans.
- Multi-model routing helps with capacity, but it also changes data handling, safety behavior, cost control, and incident response.
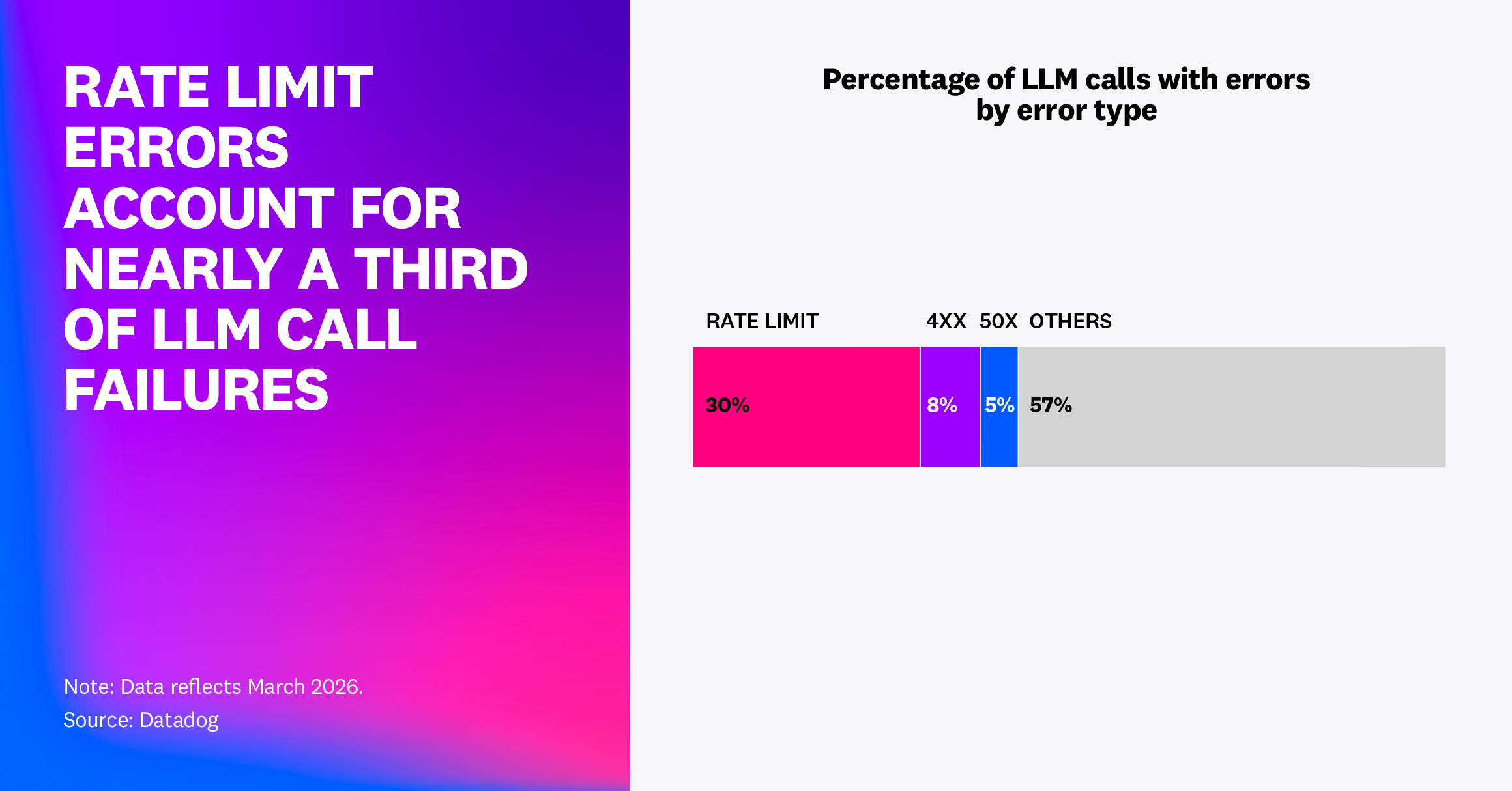
Datadog's State of AI Engineering 2026 is not another model leaderboard. It is a production telemetry report. The company announced the report on April 21, 2026, and says the analysis is based on customer metrics and metadata collected through Datadog LLM Observability. The most direct reliability number is uncomfortable for agent builders: in February 2026, 5% of LLM call spans reported an error, and 60% of those errors were rate-limit violations.
That number moves the reliability conversation away from model intelligence alone. A wrong answer can often be framed as an eval, retrieval, or prompt-engineering problem. A rate limit is a capacity, retry, queueing, fallback, and budget-allocation problem. When an agent calls several tools, asks the model to plan again after a failed step, or loops through a reflection pass, quota exhaustion can surface to the user as a stalled workflow rather than a clean "try again later" error.
 .
.
Datadog also reports that in March 2026, the overall LLM span error rate was 2%, and rate-limit errors made up almost one third of those failures, close to 8.4 million errors. A 2% span-level average can look manageable in isolation. Agent products make it harder to reason from that average because one user request may contain many model calls and service calls. A single failed span can become the visible failure of the whole task.
The second signal in the report is multi-model adoption. Datadog says OpenAI still held the largest provider share in March 2026 at 63%. At the same time, Google Gemini and Anthropic Claude increased their shares by 20 and 23 percentage points respectively from the same point in 2025. More than 70% of organizations in the report use three or more models. Production AI has moved from "which model did we choose?" to operating a provider portfolio.
That makes a model router less like a convenience feature and more like a reliability control plane. If one provider returns a rate-limit response, the product has to decide whether to wait, retry with backoff, route to another provider, downgrade to a smaller model, serve a cached answer, or enter a reduced workflow. Datadog cites OpenRouter as an example of this shift, noting that within less than two months after January 2025 it processed 3.5 times as many requests as its downstream provider. The routing layer is starting to abstract capacity, not just expose a model picker.
The tradeoff is that multi-model fallback does not preserve behavior automatically. Tokenization, tool-call schemas, safety policies, latency, structured-output reliability, and caching rules differ by provider. "Send it to the backup model" can change the answer, the allowed action, the cost, and the privacy boundary. Production teams need routing policy that names retry counts, degraded modes, write permissions, output validation, cost caps, and user-visible failure states.
Datadog's third signal is context growth. The report says the average request-token count for the median customer more than doubled over one year. For the 90th percentile power user, request tokens increased fourfold. Datadog also says 69% of input tokens in customer traces came from system prompts. In many AI apps, the dominant cost and latency drivers are not the user's latest question. They are policies, tool descriptions, domain instructions, retrieval context, and hidden scaffolding.
That is especially relevant for agents. An agent's system prompt often includes tool rules, permission boundaries, output schemas, failure handling, company policy, and domain terminology. Conversation history and retrieved documents are added on top. Even if a frontier model can handle the context window, longer context still affects latency, price, cache behavior, and trace readability. Large windows do not remove the need for context budgeting.
Prompt caching is one place where the gap is visible. Datadog says only 28% of LLM call spans for models that support prompt caching contained cached-read input tokens. In other words, most eligible calls did not appear to receive the caching benefit. Prompt caching depends on stable prefixes and provider-specific rules. If each request dynamically reassembles system instructions, tool schemas, personalization, and retrieval context, the application can pay the cost of a long context while missing the cache that would make it cheaper.
The immediate engineering task is to treat prompts as versioned artifacts rather than anonymous strings in application code. A team should know which part of the prompt is static, which part is a dynamic slot, which tool schema is attached, which retrieval budget is allowed, and how a prompt release changed token count and cache hit rate. Some policy text can move out of the model context and into middleware, permission checks, or tool-level guards. The report's 69% system-prompt figure is a warning that hidden context can become the main product dependency.
Datadog also tracks agent framework adoption. The share of organizations using an agent framework was just above 9% in early 2025 and almost 18% in early 2026. The number of services using such frameworks more than doubled. That includes the broader category of orchestration layers such as LangChain, LangGraph, Pydantic AI, Vercel AI SDK, and similar systems. The framework is no longer only a notebook-era experiment. It is becoming a production boundary with its own traces, retries, tool calls, and release risks.
The agentic workloads in the report are still more conservative than the hype might imply. Datadog says 59% of agentic application requests performed only one service call, while 18% performed three or more. That does not mean those products are not agents. A single-step agent can still interpret intent, choose a tool, check permissions, generate structured output, and explain a result. But the data suggests many production teams are opening autonomy carefully instead of sending every request through long, multi-step loops.
That matters for architecture. If most requests are single-step, the first reliability target should be that path: latency, cost, error budget, fallback behavior, and trace coverage. Multi-step flows should have stricter caps because they consume rate limits faster. A user request that runs plan, retrieve, tool call, verify, and summarize uses capacity differently from one chat completion. An unlimited retry loop can turn one user action into many failed spans and a quota incident.
Rate limits therefore belong in the agent runtime, not only in provider error handling. Backoff, circuit breakers, queue priority, partial completion, request cancellation, and per-tool budgets should be part of the execution design. The runtime should also distinguish between read-only and write-capable tool paths. If a fallback model is allowed to summarize a document, that does not mean it should be allowed to execute a purchase, modify a database record, or send an email.
Observability has to go beyond storing prompt logs. Datadog's report slices spans by provider, model, error type, token volume, framework, and service-call shape. AI teams need similar dimensions in their own dashboards. Which tool path creates the most rate-limit errors? Which fallback model lowers resolution quality? Which prompt release increased system-token share? Which provider outage triggered retry storms? Which cache rule stopped working after a schema change?
Security and compliance teams should treat this as a control-plane problem, not a performance footnote. Provider fallback can send the same user data to a different model company. Long system prompts can contain internal operating procedures. Agent frameworks can combine several service calls behind a single conversational request. Audit logs therefore need both request-level and tool-level records. The routing policy should make clear which data classes may cross which provider boundaries.
The community reaction described in the research notes points in the same direction. Discussions in AI quality and SRE forums treated rate limits as an agent failure mode, not merely a vendor-side inconvenience. Some developers compared multi-provider routing to load balancing. Others warned that fallback can blur quality, privacy, and security policies. That split is healthy. A router can improve resilience, but only if teams can explain what changes when traffic moves.
Datadog's position as an observability vendor is also a constraint on how to read the report. The strength is that the numbers come from production telemetry rather than survey sentiment or benchmark examples. The limitation is that the sample is shaped by Datadog customers and workloads using Datadog LLM Observability. The figures should not be read as an absolute average for every AI application. They are better read as a strong signal about where production AI systems are already bending under operational pressure.
For teams planning the next quarter of AI work, the report turns into a practical checklist. First, identify the top causes of LLM span failure, not just request-level failure. Second, define the degraded path when the primary provider returns a rate-limit error. Third, measure how much of the input token budget is system prompt, tool schema, retrieval context, and conversation history. Fourth, track prompt-cache usage for models that support it. Fifth, make agent framework traces visible alongside ordinary service traces.
The larger event is that AI has become a production service. Once that happens, the model is a dependency, the prompt is configuration, the token is a cost unit, the router is part of the reliability layer, and the rate limit is an outage source. Agent products make this more visible because they multiply calls behind one user-facing task. Datadog's 2026 report is a useful reminder that the next reliability win may not come from a smarter model. It may come from making failure predictable, bounded, and observable.