Cohere Command A+ Puts a 218B Agent Model on Two H100s
Cohere Command A+ pushes the private agent model race with Apache 2.0 weights, a 218B MoE design, and a two-H100 W4A4 deployment path.

- What happened: Cohere released Command A+ as an Apache 2.0 open-source model for enterprise agent workloads.
- The official specs list
218B totalparameters,25B activeparameters, a128Kinput context, image input, reasoning, and tool use.
- The official specs list
- The headline number: Cohere presents a W4A4 quantized path that can run on two H100s or one B200.
- Why it matters: the agent race is moving from benchmark scores into private deployment cost, data control, and operational governance.
- Cohere also claims 16% better Korean tokenization efficiency, a practical cost signal for non-English enterprise AI.
Cohere released Command A+ on May 20, 2026. At a glance, it could look like another open model launch. The more important part is the deployment claim. Cohere describes Command A+ as a sparse Mixture-of-Experts model with 218B total parameters, but only 25B active parameters per token. With W4A4 quantization, the company says the model has a minimum deployment path on two NVIDIA H100s or one B200.
That pairing is the story. As agents begin touching internal documents, databases, workflow systems, cloud permissions, and customer information, buyers cannot choose only by asking which model is smartest. They also need to know where the model runs, where logs and prompts remain, how inference costs move, and whether the system can fit inside internal security and audit policy. Command A+ is Cohere's argument that the answer does not always have to be a frontier cloud API.
This does not mean Cohere suddenly displaces OpenAI, Anthropic, or Google. OpenAI is tying Codex and ChatGPT Enterprise into the software-workflow layer. Anthropic is pushing Claude and Claude Code deeper into agentic development. Google connects Gemini with Vertex AI and Workspace. Cohere's emphasis is different. The word it keeps returning to is "sovereign": enterprises and governments should be able to download a model, run it in their own environment, control the inference path, and connect it to their own workflows. Command A+ is therefore less a standalone model release than a snapshot of the sovereign AI infrastructure race.
What Command A+ Actually Is
Cohere's announcement and the Hugging Face model card describe an aggressive model package. The model name is command-a-plus-05-2026, and the license is Apache 2.0. Its architecture is sparse Mixture-of-Experts. It accepts text and image input, and its outputs can include text, reasoning, and tool use.
The context window is 128K input tokens, with a maximum generation length of 64K. Cohere lists support for 48 languages, including Korean. The company says the model is optimized for reasoning, agentic workflows, RAG, multilingual use, and multimodal document processing. The model card includes paths for vLLM, Transformers, SGLang, and Docker Model Runner.
The interesting phrase is not only "open-source model." It is "agentic workflows." Open models have grown around chat, RAG, coding, local inference, and cost control. Enterprise agents need additional pieces: reliable tool calls, long context, memory, file access, database access, permission boundaries, audit logs, and deployment governance. Command A+ is trying to connect those worlds. Developers can download it from Hugging Face, while Cohere also routes the enterprise story through North and Model Vault.
The Two-H100 Message
The most memorable number in the release is 2 x H100. Cohere says Command A+ is available in 16-bit BF16, 8-bit FP8, and 4-bit W4A4 quantized forms. The model card lists minimum GPU requirements as 4 x B200 or 8 x H100 for BF16, 2 x B200 or 4 x H100 for FP8, and 1 x B200 or 2 x H100 for W4A4. The recommended path is W4A4. Cohere says the benchmark quality differences across the quantization options are small, while W4A4 gives a smaller hardware footprint and better speed and latency.
For enterprise teams, that number is a direct signal. A 218B model sounds hard to deploy internally. A 25B-active MoE model with 4-bit weight and activation quantization sounds much closer to something a team can test on a high-end workstation or a compact server node. Two H100s are still not cheap. But the calculation changes from "frontier-scale model, impossible to own" to "should we keep calling a hosted frontier API, or operate inference inside our GPU pool?"
Cohere also makes speed claims. Under the same quantization and concurrency conditions, it says Command A+ improves output tokens per second by up to 63% over Command A Reasoning and lowers time to first token by up to 17%. W4A4 contributes an additional 47% speed increase and 13% latency reduction, according to the post. Cohere also points to speculative decoding designed for MoE systems, claiming another 1.5-1.6x speedup for both text and multimodal inputs.
Those claims still need independent reproduction. Cohere's footnotes describe specific measurement conditions: a single NVIDIA HGX B200 node, eight GPUs, vLLM tensor parallelism 8, LiveCodeBench, roughly a 3K prompt, and 8K maximum output. Teams should not translate those numbers straight into their own workloads. The direction is still important. Model companies are no longer only saying "the model is bigger." They are putting GPU topology, latency, and quantization into the center of the product message.
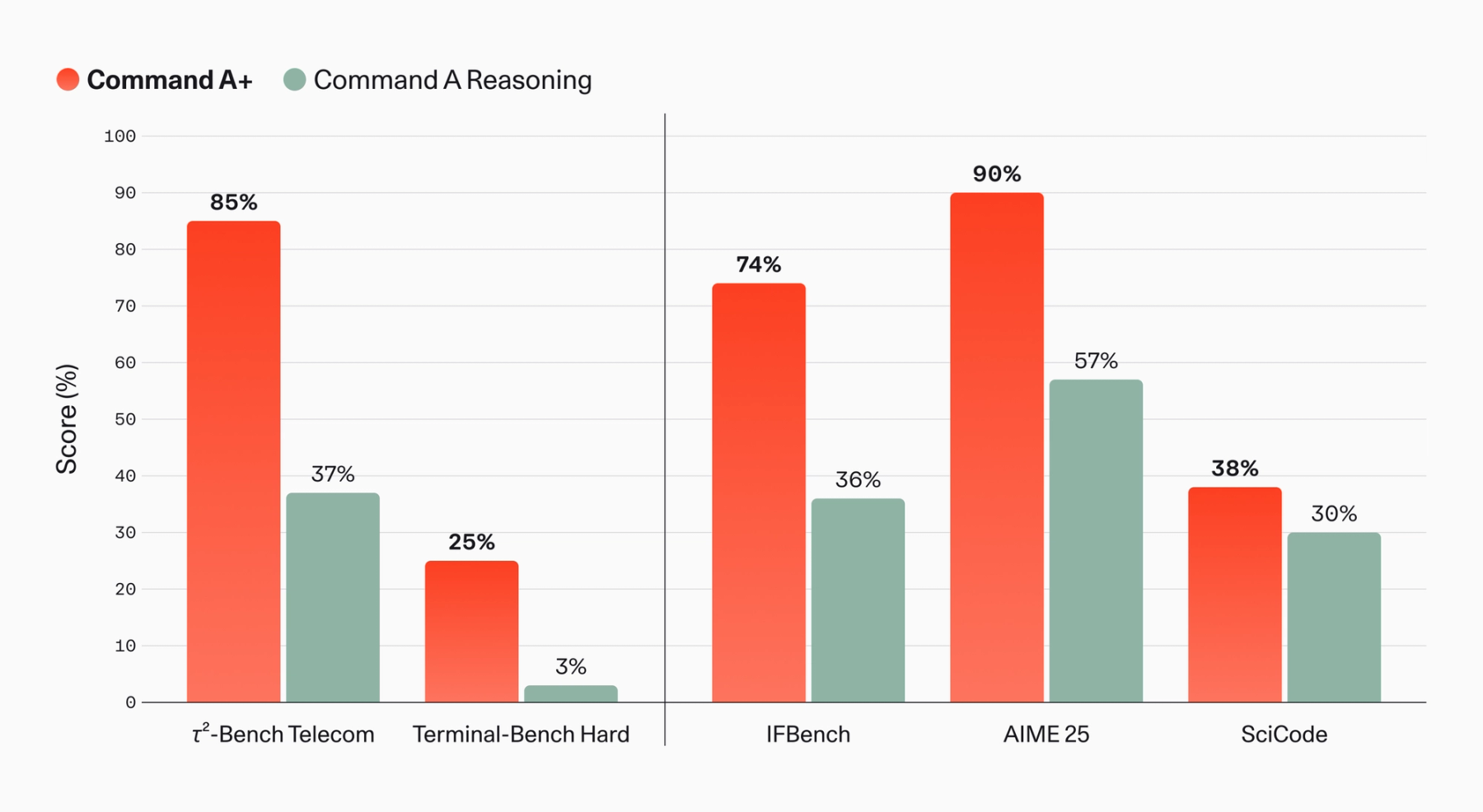
How Agent Benchmarks Are Changing
Command A+'s performance story is aimed less at generic chat and more at enterprise agent work. Cohere says 2-Bench Telecom improved from 37% to 85% versus Command A Reasoning, while Terminal-Bench Hard agentic coding performance rose from 3% to 25%. Inside North, Cohere reports a 20% gain in Agentic Question Answering accuracy, a 32% gain in spreadsheet analysis quality, and a memory score increase from 39% to 54%.
Those metrics are interesting because they better match the bottlenecks of agent products. In enterprise AI, answering a question is only the starting point. A useful agent may need to find relevant files in a document store, interpret spreadsheet data, refer to prior memory, call an API, query a database, and produce a result that can be audited. Cohere's emphasis on North evaluations suggests Command A+ is designed less as a detached chat model and more as an execution engine for workplace agents.
There is a caveat. Internal North evaluations are difficult for outside readers to verify, and LLM-as-a-judge setups are sensitive to benchmark design. The model card and blog include public benchmarks, but a buyer's real test is not the aggregate chart. It is whether the model works with that buyer's files, language, tools, security policy, and failure costs. Command A+'s open release helps here. Teams can download the weights and run their own evaluations through vLLM or Transformers instead of relying only on vendor claims.
Why 16% Korean Token Efficiency Matters
One easy-to-miss number in the announcement is tokenizer efficiency. Cohere says its latest tokenizer reduces the number of tokens needed to produce the same responses, including improvements for major non-European languages. It lists 20% for Arabic, 16% for Korean, and 18% for Japanese.
For Korean readers, this is not just a localization footnote. LLM costs usually move by input and output token. When a tokenizer splits Korean more inefficiently than English, the same business task can become slower and more expensive. If an organization's internal documents, contracts, support tickets, code comments, and knowledge bases are primarily Korean, tokenizer efficiency becomes a practical budget variable.
A 16% tokenizer improvement does not automatically mean a 16% total cost reduction. Prompt structure, retrieved-document length, tool-call output, reasoning tokens, and cache policy all matter. Still, tokenization is becoming a sharper competitive factor in non-English enterprise AI. There is a difference between saying a model "supports Korean" and saying it processes Korean more efficiently. Command A+ explicitly makes the second claim.
The Operational Weight Of Sovereign AI
"Sovereign AI" can sound political or promotional. Once agents enter enterprise systems, it becomes a concrete operations requirement. Finance, manufacturing, public-sector, healthcare, defense, and legal organizations may be unable to send sensitive data to an external cloud API, or may need strict terms before doing so. Model update cadence, log retention, access control, data residency, and incident investigation all become part of the model decision.
Command A+'s Apache 2.0 license and Hugging Face release are aligned with that requirement. Teams can bring the model into their own infrastructure and attach it to an internal inference gateway or vLLM cluster. Cohere also offers Model Vault as a managed inference environment. The shape is not only self-hosting versus SaaS. It is a spectrum between fully self-operated inference and managed private deployment.
This fits the broader AI infrastructure competition. NVIDIA is not only selling GPUs; it is emphasizing CPU orchestration, networking, compilers, and inference optimization. Cloud platforms are bundling managed agent runtimes, MCP servers, sandboxing, and observability. Model companies are splitting product lines between convenient APIs and deployment control. Command A+ sits on the side that opens weights, adds agent features, and lowers the hardware entry point.
What Developers Should Check
The first question for developers is the execution path. The Hugging Face model card includes examples for Transformers, vLLM serve, SGLang launch server, and Docker Model Runner. W4A4 requires vLLM 0.21.0 or later and Cohere's melody library. The tool-call parser and reasoning parser use Cohere Command4 settings. In practice, this may not be as simple as swapping a model name into an existing open-model serving stack.
The second question is tool-call format. The model card describes JSON schema tool descriptions, a flow where the model generates a plan and a tool call, and then the tool result is added back to the conversation history. Teams already running agent systems should compare this with OpenAI-compatible APIs, Anthropic tool use, and MCP-based tool layers. Model quality matters, but tool-call stability, citation spans, recovery from failed calls, and sandbox policy can matter more in production.
The third question is evaluation. Cohere's 2-Bench Telecom, Terminal-Bench Hard, MMMU, MathVista, and North results are not meaningless. But enterprise agent adoption should start from the cost of failure in the team's own environment. A team evaluating Command A+ should build a small benchmark set from real tasks: customer data questions, internal-document RAG, codebase analysis, spreadsheet analysis, multilingual translation, and long-form report drafting. It should then compare Command A+ with frontier API models and other open models under the same constraints.
Competition Moves From Scores To Control
Command A+ is not a sign that Cohere is opting out of frontier-model competition. It is a sign that Cohere is choosing a different axis. OpenAI and Anthropic are pairing strong models with integrated products for agentic coding and workplace automation. Cohere is making the case that enterprises need control over where the model runs and how it is governed. That difference affects sales motion, deployment architecture, security review, and cost model.
The role of open models is changing too. A few years ago, many teams viewed open models mainly as cheaper alternatives to closed APIs. In the agent era, they also become a governance mechanism. Owning the weights, controlling the inference path, keeping logs and permissions inside internal policy, and evaluating or tuning for a domain can all be part of the adoption decision. Command A+'s Apache 2.0 release strengthens that direction.
Open weights are not enough, though. Enterprises do not buy only a model. They buy an operating system around it: monitoring, rate limits, secrets handling, tool sandboxes, prompt-injection defenses, data governance, automated evaluation, and incident response. That is why Cohere talks about North and Model Vault alongside the open release. The strategy is to invite developer experimentation with open weights while connecting real enterprise deployments to managed or private platforms.
The Open Questions
The largest question is independent validation. Cohere's official numbers are strong, but agent models often reveal their real differences in operations rather than charts. How does the 128K context behave under long-running work? How stable are tool calls in complex multi-step workflows? How much does Korean document RAG actually improve? What error patterns does W4A4 quantization introduce in long reasoning traces? Those answers need community and enterprise evaluation.
The second question is ecosystem fit. OpenAI and Anthropic are moving quickly across coding tools, IDEs, CLIs, mobile approvals, enterprise policy, and security programs. Google connects Gemini with Vertex AI, Android, and Workspace. If Cohere's Command A+ argument is open weights plus deployment efficiency, the next battle is how easily developers can place the model inside real agent runtimes. vLLM and Transformers support are good starting points, but operational quality is a longer fight than SDK examples.
The question Command A+ raises is still clear. In the agent era, model choice does not end with calling the API that tops a benchmark. It includes where the model can run, what GPU budget it needs, whether non-English token costs are acceptable, and how tool use and memory are governed. Command A+ compresses that question into a sharp contrast: a 218B model with a two-H100 deployment path. The real news is not just another model. It is that the price tag for a private agent brain is becoming more concrete.