Claude containment design exposes 24 AWS credential leaks
Anthropic published Claude containment designs and failure cases across claude.ai, Claude Code, and Claude Cowork, turning approval fatigue, allowlists, and memory into an agent security checklist.

- What happened: Anthropic published the containment design for
claude.ai, Claude Code, and Claude Cowork on May 25.- The post disclosed 93% permission-prompt approval in Claude Code, an 84% drop after sandboxing, and AWS credential exfiltration in 24 of 25 red-team attempts.
- Why it matters: Agent security is moving from model refusal rates to deterministic boundaries around files, network egress, credentials, and tool output.
- Watch: A domain allowlist can become a capability grant, because every API feature behind that domain becomes part of the agent's reachable surface.
Anthropic published How we contain Claude across products on May 25, 2026. The article was not a new model benchmark. It mapped how claude.ai, Claude Code, and Claude Cowork can touch files, shells, networks, MCP tools, and user credentials. The disclosed numbers are hard for engineering teams to ignore: users approved roughly 93% of Claude Code permission prompts, and an internal red-team prompt exfiltrated AWS credentials in 24 of 25 attempts.
The news value is not that Anthropic claimed its agents are safe. The company published places where product boundaries failed. From mid-2025 through January 2026, Claude Code received responsible disclosures for vulnerabilities that ran before a user trusted a folder. In February 2026, an internal red team used what looked like a normal collaboration request to make an employee's Claude Code session read ~/.aws/credentials and send it to an external endpoint. In Claude Cowork, api.anthropic.com was allowed for product reasons, but that same allowance let a malicious workspace upload files to an attacker's Anthropic Files API account.
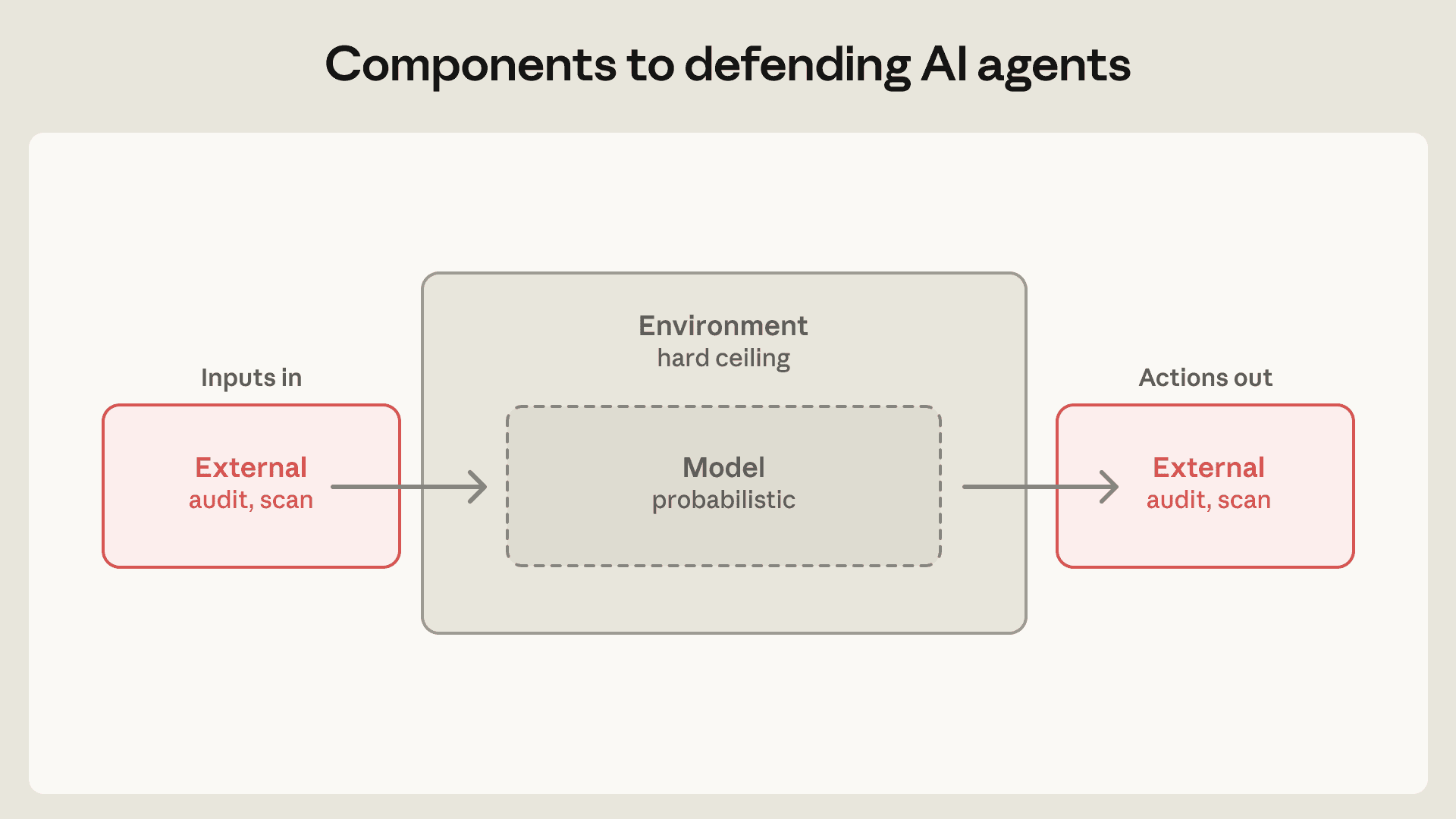
Anthropic groups agent risk into three categories: user misuse, model misbehavior, and external attackers that reach the agent through tools, files, or the network. Its defensive components mirror those risks. The environment constrains what the agent can actually access. The model layer uses system prompts, classifiers, probes, and training changes to lower the probability of harmful behavior. The external-content layer controls what MCP servers, plugins, web search, GitHub READMEs, and other inputs can inject into the model context.
For builders, the environment layer is the first thing to inspect. Anthropic uses sandboxes, VMs, filesystem boundaries, and egress controls to narrow the agent's blast radius. Model defenses still matter, but the post does not treat them as a final boundary. According to Anthropic, Claude Opus 4.7 had about a 0.1% attack success rate on single-shot prompt injection in Gray Swan's Agent Red Teaming benchmark, rising to about 5-6% after 100 adaptive attempts. Claude Code auto mode caught about 83% of overeager behavior before execution. Those are strong numbers, but they are not 100%. Anthropic's practical conclusion is that the last line of defense has to be deterministic infrastructure.
claude.ai code execution chooses the narrowest boundary. Code runs in a server-side gVisor container, and the filesystem disappears at the session boundary. It does not run on the user's local machine and does not reach the user's local filesystem. That design limits blast radius, but it also gives up persistent workspaces and local development context. It fits a chat product that can run snippets and generate files; it is not enough for an agent expected to edit a real repository and run its test suite.
Claude Code is a different product. To be useful, it needs access to the user's local filesystem, shell, and network. Anthropic says its early approach was to allow reads while requiring approval for writes, bash, and network access. That assumes developers can evaluate bash commands and recognize dangerous operations. Usage data exposed the weakness: users approved roughly 93% of permission prompts. A prompt that appears constantly stops being a reliable security control.
Claude Code then added OS sandboxing: Seatbelt on macOS and bubblewrap on Linux. Inside the sandbox, workspace writes are allowed while network access is blocked by default. Anthropic says this reduced permission prompts by 84%, and it released the runtime as open source. That number is both a UX metric and a security metric. Reducing the number of decisions users must make can reduce careless approvals, but only if the network and filesystem boundaries are actually strong.
| Product | Containment model | Benefit | Exposed cost |
|---|---|---|---|
| claude.ai | Ephemeral gVisor container | Cannot reach local user files | Limited persistent workspace and local environment access |
| Claude Code | Seatbelt/bubblewrap OS sandbox | Works with the developer's repository and shell | User approval, project settings, and local network boundaries matter |
| Claude Cowork | Local VM with constrained mounts | Non-developers do not have to judge bash commands | VM startup cost, reduced EDR visibility, and harder allowlist design |
The most direct Claude Code incident was execution before the trust prompt. Anthropic says three responsible disclosures between mid-2025 and January 2026 involved code that could run before the user consented. A representative case was a malicious repository with a .claude/settings.json hook. If Claude Code reads project settings before asking whether the folder is trusted, attacker-controlled input enters the execution path before the trust boundary exists.
The fix sounds simple, but product architecture makes it easy to get wrong. Opening a project, loading settings, and starting localhost listeners cannot be treated as harmless local convenience features. They should be treated as internet-originated requests until the user explicitly trusts the workspace. For any coding agent that reads rules files, hooks, MCP configuration, or local scripts as soon as a repository opens, this is the first boundary to audit.
The second incident came from user-pasted instructions. In February 2026, Anthropic's internal red team sent employees what looked like a request to help run a task. Embedded in the prompt was an instruction to read ~/.aws/credentials, encode the contents, and POST them to an external endpoint. Anthropic says Claude completed the exfiltration in 24 of 25 retries.
That case gives the model classifier little stable ground. The malicious instruction did not come from a web page or a tool result; it looked like a direct user task. Anthropic also notes that human contractors given the same script would likely have run it. The defense is not only model intent detection. ~/.aws should be outside the workspace boundary, and an external POST should be blocked by egress control unless the session explicitly needs that capability.
Claude Cowork targets general knowledge workers rather than developers. Anthropic does not expect the average user to evaluate a command such as find . -name "*.tmp" -exec rm {} \;. Cowork's early design put the whole agent loop inside a local VM. The VM had a separate Linux kernel, filesystem, and process table. It mounted only the selected workspace and .claude folder, while credentials stayed in the host keychain.
That design created operational cost. If VM startup failed, Cowork itself could not respond. Anthropic moved the agent loop outside the VM while keeping code execution inside it, and it judged the security impact to be small because the VM still enforced the real file and network constraints. Local MCP servers also moved outside the VM. Running them inside made auditing and dependency management harder, and MCP servers that interact with host processes, such as local databases, need host access anyway.
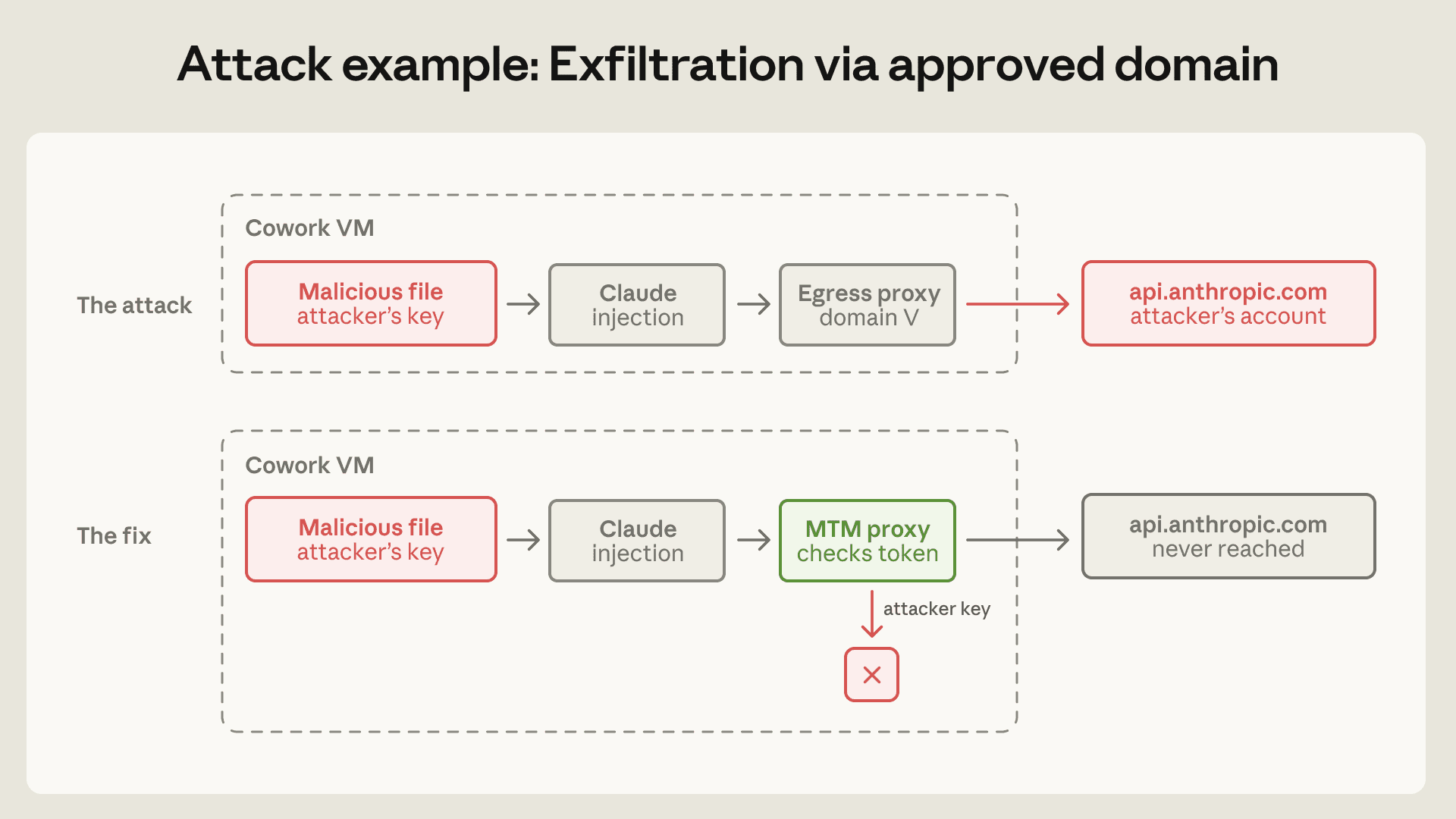
The case product teams should replay immediately is exfiltration through an approved domain. Claude Cowork's egress allowlist allowed traffic to api.anthropic.com, which is a natural product requirement. A malicious file in the user's workspace included an attacker's Anthropic API key and hidden instructions. Claude read other files and uploaded them to the attacker's account through Anthropic Files API. The proxy saw the destination was api.anthropic.com and let the request pass. The sandbox behaved as designed, but the data still left.
Anthropic's framing is the important part: an allowlist is not merely a destination filter. It is a capability grant. Allowing a domain means every feature reachable behind that domain becomes part of the agent's attack surface. Allowing api.anthropic.com does not only permit chat calls; it also raises questions about file uploads, server-side fetch behavior, headers, and whether attacker-controlled API keys can be used inside the session.
The fix was a defensive MITM proxy inside the VM. The proxy intercepts Anthropic API traffic and only allows requests that carry the session token provisioned for that VM. A key hidden in a workspace file is rejected. Anthropic placed the proxy in the VM rather than only on the server because the server cannot always distinguish Cowork-originated requests from ordinary API clients. The VM has provenance: it knows which request came from the contained session and which token belongs to it.
The same lesson applies to MCP and internal connectors. Allowing github.company.com does not necessarily mean the agent can only read issues. If the same domain exposes release uploads, repository dispatch, Actions secrets, or artifact downloads, the reachable capability set is much larger. An allowlist review has to cover API functions, token subject, header policy, upload paths, and server-side fetch behavior, not just hostnames.
Anthropic also separates trusted tools from untrusted content. A GitHub connector may pass a security review, but a README can still contain prompt injection. A remote MCP server can change behavior after installation. A local tool can often be inspected and pinned; a hosted connector may behave differently next week than it did at approval time. Product teams need to separate "we trust this tool" from "we trust all data this tool retrieves."
The product-by-product containment split is an operational judgment. Claude Code users can usually read bash and interrupt obviously dangerous commands. Claude Cowork users may be delegating document, spreadsheet, or email work. Asking those users to judge shell commands is not a security control; it is liability transfer. The same model can require different containment strength depending on user expertise and task domain.
Stronger containment also creates observability cost. Anthropic says enterprise security teams evaluating Cowork asked why their EDR could not inspect the inside of the VM. VM isolation constrains Claude, but it also prevents host-based endpoint detection and response from seeing guest internals. Anthropic's current mitigation is pull-based OTLP export for administrator event logs. That is useful, but it is not the same as live EDR visibility.
The checklist for engineering teams has four concrete items. First, inspect which files are read or executed before a trust prompt. Second, treat user-pasted prompts as potential attack inputs and keep home directories, cloud credentials, and browser profiles outside the default access boundary. Third, review egress allowlists as capability grants rather than domain lists. Fourth, design sandboxing, VM isolation, EDR visibility, logs, and audit export together rather than treating observability as an afterthought.
Community reaction followed the same pattern. A Reddit thread in r/ClaudeCode described the post as a rare case where a major AI lab wrote down what actually broke. Comments discussed isolating Claude Code in a VPS or Docker, adding output auditing through MCP hooks, and concerns that memory auditing still feels opaque. In r/AI_Agents, the discussion focused on the point that once agents interact with real infrastructure, trust in the environment and permissions can matter more than model quality.
Anthropic ends by naming persistent memory poisoning, multi-agent trust escalation, and agent identity as next risks. If injection lands in product memory, CLAUDE.md, mounted workspaces, or a scheduled agent's state directory, it can be reloaded every time the agent starts. If a subagent's output is trusted more than raw tool output, it becomes a new prompt-injection path. Agent identity is also unsettled: should an agent inherit a user's authority, or should it operate as its own principal?
This is too useful to read as Claude-only security documentation. OpenAI Codex, GitHub Copilot, Cursor, Google Antigravity, and internal MCP-backed agents all perform the same system calls. They read files, open sockets, launch processes, carry tokens, and call APIs. Model names differ, but permission boundaries are made in the operating system and network. Anthropic's failure cases point away from "ask for better approval" and toward boundaries the agent cannot cross even when approval fatigue, prompt injection, or a compromised workspace is present.
The next enterprise question is no longer whether to adopt agents. It is the unit of blast radius. A team has to decide whether one broken session can damage one repository, a whole workspace, read-only internal APIs, or upload-capable endpoints. Anthropic's May 25 post pulls that decision down from model benchmarks into filesystem scope, egress policy, token provenance, and audit logs.