Perplexity Search as Code 공개, 에이전트 검색을 Python으로 실행
Perplexity가 Search as Code를 공개했습니다. Agent API와 Computer에서 반복 검색 호출을 Python sandbox pipeline으로 바꾸는 설계입니다.

- 무슨 일: Perplexity가 2026년 6월 1일 Search as Code를 Agent API와 Computer의 새 검색 아키텍처로 공개했습니다.
- 모델이 검색 primitive를
Python코드로 조합하고, secure sandbox에서 retrieval, ranking, fan-out, filtering을 실행합니다.
- 모델이 검색 primitive를
- 의미: 에이전트 검색을 직렬 function call이나 MCP 호출이 아니라 실행 가능한 retrieval program으로 다루겠다는 선언입니다.
- 수치: Perplexity는 CVE case study에서 token 사용량을 288.7K에서 42.9K로 줄였고, WANDR에서 다음 시스템 대비 2.5배 점수를 냈다고 밝혔습니다.
- 주의점: WANDR benchmark는 아직 공개 예정이고, sandbox와 tool call 비용은 모델 token 비용과 별도로 계산해야 합니다.
Perplexity Research가 2026년 6월 1일 Search as Code를 공개했습니다. Perplexity는 이를 SaC라고 줄여 부르며, Agent API와 Perplexity Computer에 적용되는 새 reference search architecture라고 설명합니다. 기존 AI 검색은 모델이 query를 만들고 검색 시스템이 고정 pipeline을 실행한 뒤 resultset을 돌려주는 방식이었습니다. SaC는 이 경계를 낮춥니다. 모델이 검색 스택의 primitive를 Python 코드로 조합하고, Perplexity의 secure sandbox 안에서 검색 pipeline을 실행합니다.
이 발표는 검색 품질 개선 글처럼 보이지만, 개발자에게는 에이전트 runtime 설계 변경에 가깝습니다. Perplexity는 Computer 안의 단일 작업이 몇 분 안에 수백 또는 수천 번의 retrieval operation을 호출하는 사례를 봤다고 적었습니다. 사람이 쓰는 검색창은 그런 fan-out을 필요로 하지 않습니다. 그러나 보안 advisory 수백 개를 대조하거나, 특정 시장의 공급업체 목록을 넓게 조사하거나, 코드베이스와 웹 문서를 동시에 훑는 에이전트는 반복 query, 병렬 fetch, deduplication, filtering, ranking을 한 번의 긴 작업 안에서 수행합니다.
SaC의 출발점은 "검색 결과를 더 잘 요약한다"가 아닙니다. Perplexity는 검색을 에이전트가 직접 프로그래밍할 수 있는 I/O 계층으로 바꿔야 한다고 봅니다. 모델은 어떤 증거가 필요한지 판단하고, deterministic runtime은 batching, parallelism, filtering, aggregation을 처리합니다. 검색 인프라는 모델이 세계 정보에 접근하는 handle을 제공합니다. 이 세 요소를 한 흐름으로 묶는 방식이 SaC의 제품 메시지입니다.
 .
.
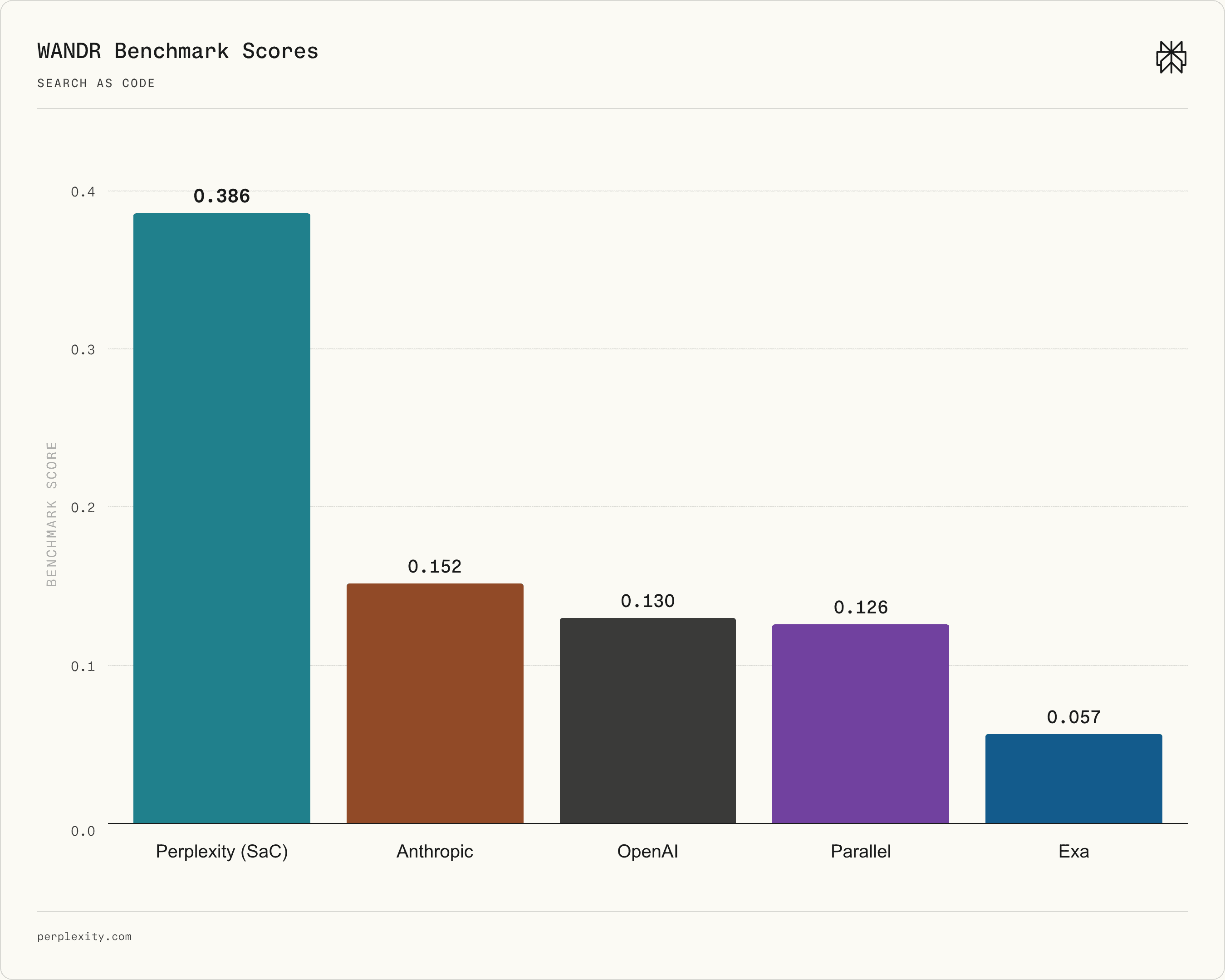
공식 Figure 5는 Perplexity가 새로 개발 중인 WANDR benchmark에서 SaC가 다른 agent-based system보다 높은 점수를 냈다는 주장을 보여줍니다. 이 그림은 Perplexity 자체 평가 자료입니다.
고정 검색 API에서 검색 프로그램으로
Perplexity 글은 기존 검색 인터페이스의 실패 양상을 세 가지로 나눕니다. 첫째, context가 거칠어집니다. 모델이 아주 좁은 사실 하나만 필요할 때도 고정 search endpoint는 recall을 우선한 넓은 결과를 넣을 수 있습니다. 둘째, 모델이 갖고 있는 domain knowledge를 검색 전략에 반영하기 어렵습니다. 특정 source를 우선하거나 lexical signal과 semantic signal을 섞는 판단이 query parameter로 표현되지 않으면 실행할 수 없습니다. 셋째, fan-out과 deduplication이 필요한 workflow가 반복 model turn으로 밀려 latency와 context pollution을 키웁니다.
SaC는 검색 작업을 model-visible tool call의 연속으로 두지 않습니다. 모델이 Python 코드를 작성하고, 그 코드가 Agentic Search SDK를 호출합니다. Perplexity는 이 SDK가 기존 search API를 library로 감싼 물건이 아니라, 검색 스택을 retrieval, ranking, filtering, fanout, rendering 같은 modular primitive로 재설계한 결과라고 설명합니다. high-level end-to-end search pipeline도 SDK 안에 남지만, agent는 task에 따라 낮은 수준 primitive를 직접 조합할 수 있습니다.
Perplexity가 첫 runtime으로 고른 언어는 Python입니다. 글에 따르면 Rust, TypeScript, Bash도 검토했지만 내부 테스트에서 Python이 가장 자연스러운 선택으로 나왔습니다. 이 선택은 개발자에게 낯설지 않습니다. 대규모 검색 결과를 다룰 때 Python은 list comprehension, async batching, regex, JSON parsing, dataframe류 처리, lightweight scoring logic을 빠르게 표현합니다. 에이전트가 생성하는 코드도 복잡한 shell pipeline보다 Python 함수로 관리하기 쉽습니다.
| 항목 | 직렬 tool call 검색 | Search as Code |
|---|---|---|
| 제어 단위 | 모델이 검색 API를 한 번씩 호출 | 모델이 검색 pipeline 코드를 생성 |
| 중간 상태 | 결과가 token context로 들어가기 쉬움 | sandbox 파일과 변수, serialized state로 관리 |
| 병렬 처리 | 반복 turn과 tool call scheduling에 의존 | Python 코드에서 fan-out, batch, dedupe 실행 |
| 실패 지점 | query와 최종 결과 사이가 불투명해짐 | 검색 전략, 필터, 검증 schema를 코드로 남김 |
이 비교에서 SaC가 모든 검색 문제의 정답이라는 뜻은 아닙니다. 단일 질문에 최신 문서 몇 개를 붙이는 챗봇이라면 기존 search API가 더 단순합니다. SaC의 강점은 query가 많고, 조건이 바뀌고, 중간 후보를 걸러야 하고, 최종 답변 전에 별도 검증을 해야 하는 작업입니다. Perplexity가 예시로 든 CVE vendor advisory task가 그런 유형입니다.
CVE 사례에서 token을 85.1% 줄였다는 주장
Perplexity의 case study는 2023년부터 2025년까지 high-severity CVE 200개 이상을 찾는 작업입니다. 각 record는 vendor advisory, affected product, fix version, CVE와 fix version의 연결 근거를 확인해야 합니다. Perplexity는 SaC가 이 task에서 100% accuracy를 기록했고, 같은 Perplexity 검색 인프라를 쓰는 non-SaC baseline 대비 token 사용량을 288.7K에서 42.9K로 줄였다고 밝혔습니다. 감소율은 85.1%입니다. 비교 대상 non-Perplexity systems는 25% 미만 점수였다고도 적었습니다.
이 숫자의 원인은 검색 결과가 적어서가 아닙니다. SaC 예시 코드는 Mozilla, Jenkins, Chrome, Android 같은 vendor별 advisory URL pattern을 직접 만들고, 연도와 월을 펼쳐 query list를 구성합니다. 그 다음 sdk.search.web_many로 병렬 검색을 수행하고, vendor-owned advisory가 아닌 결과를 구조적으로 제외합니다. 모델 context에는 모든 seed hit가 들어가지 않습니다. 코드가 후보를 좁히고, 다음 단계에 필요한 상태만 남깁니다.
두 번째 단계는 sparse vendor-year를 찾고 query를 보강합니다. 코드가 현재 coverage를 요약하고, LLM에게 부족한 vendor-year를 채울 exact-phrase query를 제안하게 합니다. 그런 뒤 proposed query가 official scope와 CVE year 조건을 만족하는지 검증한 후 다시 검색합니다. 여기서 LLM은 reasoning을 맡지만, 실행과 검증은 코드가 맡습니다. 모델이 검색 결과를 하나씩 읽고 다음 tool call을 고민하는 방식과 다릅니다.
마지막 단계는 CVE와 fix version의 연결을 schema로 확인합니다. Perplexity 예시는 sdk.llm.extract_many에 "vendor advisory가 high 또는 critical CVE를 specific fixed version, build, patch, security level과 연결한 경우만 남기라"는 instruction을 넣습니다. schema에는 cve, vendor, product, fix_version, severity, source_url, evidence, version_bound_to_cve, confidence가 있습니다. 이 구조는 보안 리서치 자동화에서 중요한 차이를 만듭니다. 단순히 CVE 번호가 있는 페이지를 찾는 것이 아니라, vendor-authored text 안에서 fix version과 CVE의 관계를 검증합니다.
benchmark 수치는 강하지만 출처를 분리해야 합니다
Perplexity는 SaC를 다섯 benchmark에서 평가했다고 밝혔습니다. 기존 benchmark는 DeepSearchQA, BrowseComp, Humanity's Last Exam, WideSearch이고, 새 benchmark로 WANDR를 추가했습니다. WANDR는 Perplexity Computer의 knowledge-intensive professional task에서 영감을 받은 wide research benchmark이며, Perplexity는 몇 주 안에 공개하겠다고 적었습니다. 이 점은 독자가 따로 표시해 두어야 합니다. DSQA, BrowseComp, HLE, WideSearch는 외부 논문과 연결되지만 WANDR는 아직 독립 재현 자료가 없습니다.
공식 표에 따르면 SaC는 DSQA 0.871, BrowseComp 0.805, HLE 0.612, WideSearch 0.651, WANDR 0.386을 기록했습니다. 같은 표에서 OpenAI는 HLE 0.614로 SaC보다 근소하게 높고, 다른 네 항목에서는 SaC보다 낮습니다. Anthropic은 DSQA 0.815, WideSearch 0.590으로 일부 항목에서 강하지만 BrowseComp와 WANDR에서는 낮게 나옵니다. Exa와 Parallel도 포함됐습니다. Perplexity는 "best-of-N"이 아니라 individual run으로 underlying architecture를 비교했다고 설명합니다.
WANDR에서는 Perplexity Agent API가 다음으로 높은 시스템 대비 2.5배 점수를 냈다는 그림을 제시했습니다. 이 수치는 눈에 띄지만, 바로 시장 우위로 번역하면 안 됩니다. WANDR 자체가 공개 전이고, task selection과 grading protocol을 외부에서 확인할 수 없기 때문입니다. 다만 wide research task가 검색, compute, model reasoning orchestration을 동시에 요구한다는 문제 설정은 실무와 맞습니다. enterprise agent가 단일 document Q&A보다 vendor 비교, 규정 조사, incident timeline 구성, migration 영향 분석을 자주 맡기 때문입니다.
 .
.
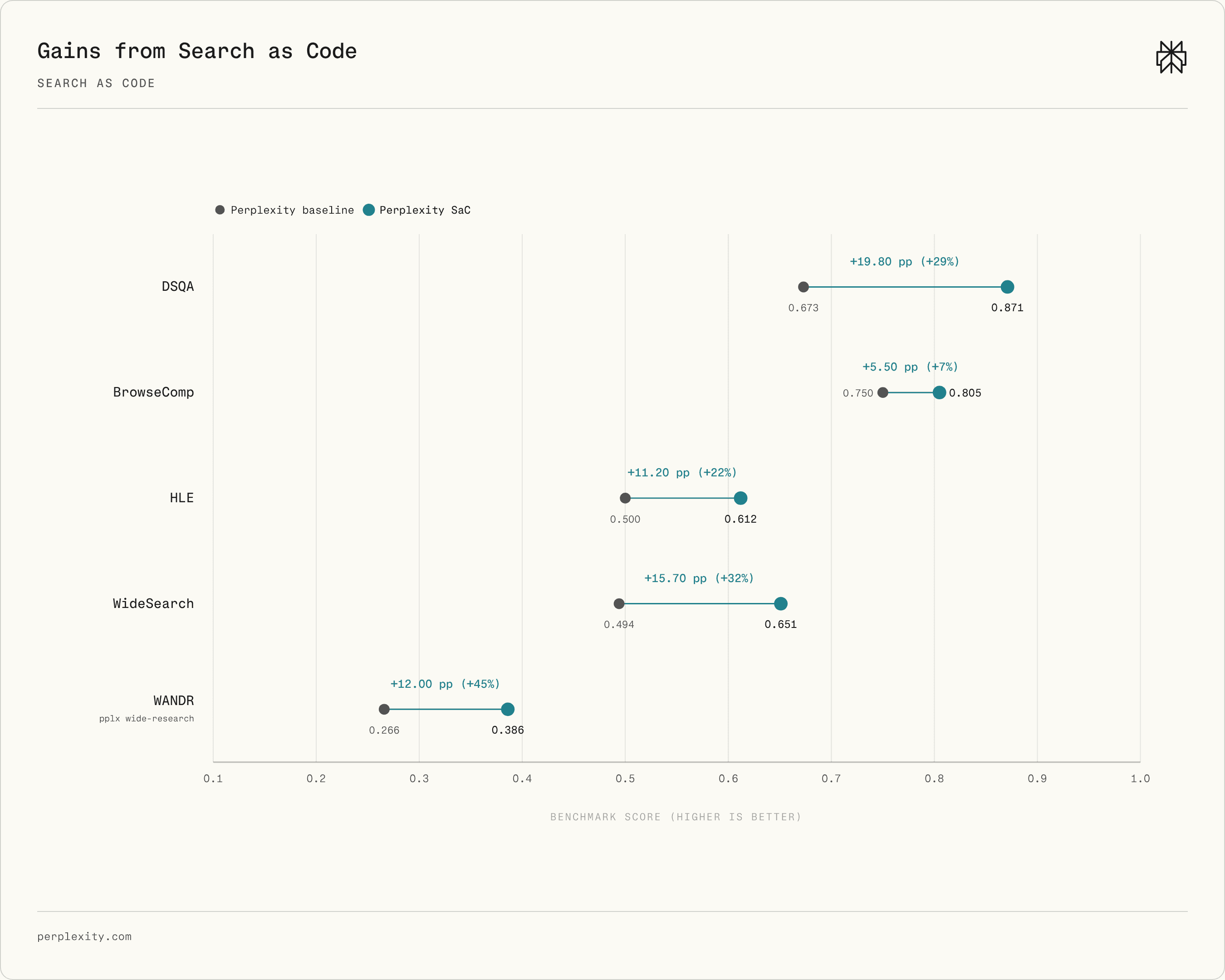
공식 Figure 6은 같은 Perplexity 검색 인프라에서 SaC와 non-SaC baseline을 비교한 delta입니다. Perplexity는 DSQA에서 +19.77 pp, WANDR에서 +12.00 pp와 45% relative gain을 제시했습니다.
sandbox 상태 관리는 REPL보다 파일을 골랐습니다
SaC의 내부 설계에서 개발자가 볼 만한 부분은 sandbox state입니다. Perplexity는 agent가 한 turn에서 문서를 가져오고, 다음 turn에서 일부 문서를 검사하고, 그 다음 turn에서 추가 pipeline을 만드는 상황을 언급합니다. 이때 중간 상태를 token space로 넘기면 context가 커지고 noise가 들어갑니다. SaC는 sandbox 안에서 중간 상태를 관리해야 합니다.
Perplexity는 두 접근을 비교했습니다. 하나는 persistent filesystem과 explicit serialization/deserialization입니다. 모델이 중간 상태를 파일로 저장하고, 다음 turn에서 명시적으로 읽습니다. 다른 하나는 REPL 방식입니다. runtime 자체가 살아 있어 이전 turn에서 만든 변수를 다음 turn에서 그대로 참조할 수 있습니다. REPL은 token 효율이 좋지만, 긴 Jupyter notebook처럼 namespace가 지저분해지면 무엇이 남아 있는지 추적하기 어렵습니다.
Perplexity는 일반 사용에서는 두 방식이 비슷했지만, 긴 trajectory에서는 filesystem-based serde가 더 reliable했다고 적었습니다. 그래서 SaC는 explicit state transfer를 채택합니다. 이 선택은 agent observability 관점에서 보수적인 설계입니다. 파일로 남긴 상태는 검색 전략, 후보 목록, 검증 결과를 audit하기 쉽습니다. 반대로 REPL 변수만 남기면 나중에 어떤 intermediate result가 최종 답변에 영향을 줬는지 추적하기 어렵습니다.
Perplexity sandbox 문서는 Agent API request 안에서 모델이 isolated container에서 코드를 실행할 수 있다고 설명합니다. sandbox tool은 preview이고 runtime availability, quotas, pricing이 바뀔 수 있습니다. 문서의 use case에는 web search, numeric calculations, data cleaning, parsing, code execution, structured artifact generation, intermediate files가 필요한 multi-step workflow가 들어갑니다. SaC는 이 sandbox를 검색 pipeline 실행의 중심으로 가져옵니다.
비용은 token만 보면 안 됩니다
SaC는 token 절감 가능성을 내세우지만, 실제 비용 계산은 model token, sandbox session, tool invocation을 함께 봐야 합니다. Perplexity pricing 문서는 Agent API가 third-party model을 direct provider rates with no markup으로 제공한다고 설명합니다. model token 비용은 provider와 모델별로 다릅니다. tool 비용은 별도입니다.
문서 기준 Agent API의 web_search는 invocation당 0.005달러, fetch_url은 0.0005달러, people_search와 finance_search는 각각 0.005달러입니다. sandbox는 session당 0.03달러입니다. sandbox session은 single isolated container lifecycle이고, 최대 20분 active use를 billing window로 삼습니다. 문서는 이것이 runtime cap이 아니라 billing window라고 명시합니다. sandbox 안에서 SDK search query를 호출하면 같은 web_search와 동일하게 request당 0.005달러가 붙습니다.
이 비용 구조는 SaC 도입 판단을 복잡하게 만듭니다. 반복 tool call이 model context를 크게 만들고 reasoning token을 많이 쓰는 작업에서는 SaC가 싸질 수 있습니다. CVE case study처럼 token을 85.1% 줄인다면 sandbox와 search invocation 비용을 더해도 전체 비용이 줄 가능성이 있습니다. 그러나 단순 검색 몇 번으로 충분한 작업에서는 sandbox session 0.03달러와 여러 SDK search query가 오히려 부담이 될 수 있습니다. 개발팀은 task class별로 cost trace를 분리해야 합니다.
MCP를 버린다는 말은 아닙니다
Perplexity 글은 function calling과 MCP 시대의 한계를 직접 언급합니다. 검색 operation마다 LLM inference roundtrip이 필요하면 개발자는 한 번의 호출에서 최대한 많은 결과를 받으려 하고, 결국 end-to-end search pipeline을 그대로 쓰게 된다는 설명입니다. SaC는 이 serial I/O를 줄이려는 설계입니다. 그렇다고 MCP나 function calling이 사라진다는 뜻은 아닙니다.
MCP와 function calling은 외부 system boundary를 정의하는 데 여전히 유용합니다. CRM, ticketing system, code hosting, calendar, database처럼 권한과 audit가 필요한 tool은 명시적 tool interface가 필요합니다. SaC가 바꾸려는 지점은 검색 스택 내부의 세부 제어입니다. 검색 query를 한 번 던지는 interface만 열어 두는 대신, agent가 검색 primitive를 조합해 task-specific retrieval pipeline을 만들 수 있게 합니다.
개발자는 이 구분을 architecture review에 넣어야 합니다. SaaS API를 호출하는 tool은 permission, rate limit, data policy를 기준으로 설계합니다. 검색 primitive를 조합하는 SaC류 runtime은 intermediate state, code execution safety, result verification, cost accounting을 기준으로 봅니다. 둘을 섞어 "모든 tool을 코드로 실행한다"로 읽으면 보안 경계가 흐려집니다. Perplexity도 secure sandbox를 별도 layer로 둔 이유가 여기에 있습니다.
Agent API 제품 전략도 같이 보입니다
Agent API 문서는 이 API를 multi-provider, interoperable API specification으로 설명합니다. OpenAI, Anthropic, Google, xAI 등 여러 provider 모델을 하나의 API에서 쓰고, integrated real-time web search, tool configuration, reasoning control, token budgets를 제공한다는 설명입니다. endpoint는 POST https://api.perplexity.ai/v1/agent이고, OpenAI SDK 호환을 위해 POST /v1/responses alias도 받습니다.
SaC는 이 Agent API 포지션을 강화합니다. Perplexity가 단순히 "우리 검색 API를 LLM에 붙이라"고 말하는 것이 아니라, multi-provider model이 Perplexity 검색 스택을 낮은 수준 primitive로 조작할 수 있게 합니다. 연구 글의 benchmark에서도 Perplexity SaC는 GPT 5.5 high reasoning을 underlying model로 사용했습니다. 모델 제공자가 Perplexity가 아니어도, 검색 runtime과 sandbox, SDK가 Perplexity 쪽이면 agentic search 품질을 차별화할 수 있다는 전략입니다.
이 전략은 Exa, Tavily, Brave Search API 같은 AI-facing search provider와도 경쟁합니다. 동시에 OpenAI Responses API의 web_search와 code_interpreter, Anthropic Managed Agents의 tool runtime, Parallel Tasks, Exa Agent 같은 agent runtime과도 겹칩니다. Perplexity가 내세우는 차이는 "검색 결과를 제공한다"가 아니라 "검색 스택 자체를 agent가 code로 orchestrate한다"입니다. 이 차이가 실제 고객 task에서 얼마나 재현되는지는 공개 benchmark와 third-party evaluation이 더 필요합니다.
도입 전 점검할 항목
SaC와 비슷한 구조를 제품에 넣으려는 팀은 먼저 task class를 나눠야 합니다. 단일 답변형 query, 몇 개 source를 확인하는 research, 수백 query를 펼치는 wide search, code나 CVE처럼 strict verification이 필요한 investigation은 비용과 위험이 다릅니다. 모든 검색을 sandbox code로 보내면 단순 task에서 latency와 비용을 키울 수 있습니다. 반대로 wide research를 serial tool call로 밀어붙이면 context compaction과 중복 fetch가 커집니다.
두 번째는 intermediate state audit입니다. SaC는 파일 기반 serialization을 택했습니다. 내부 제품에서도 agent가 어떤 query pattern을 만들었고, 어떤 URL을 버렸고, 어떤 evidence를 최종 답변에 썼는지 남겨야 합니다. 특히 보안, 금융, 법무, 의료, enterprise procurement task에서는 "검색했다"보다 "왜 이 source를 신뢰했고 왜 다른 source를 제외했는가"가 중요합니다. 코드로 검색 pipeline을 만들면 이 근거를 남길 수 있지만, logging과 review UI가 없으면 사람이 확인하기 어렵습니다.
세 번째는 sandbox policy입니다. 검색 pipeline code는 deterministic operation을 실행하지만, 그래도 code execution입니다. 네트워크 접근 범위, 파일 보존 기간, secret 접근 차단, package import 제한, timeout, retry, billing guardrail을 정해야 합니다. Perplexity 문서는 sandbox errors가 sandbox_results item으로 돌아오고 timeout, runtime error, quota/limit case를 구분한다고 설명합니다. production agent에서는 이 error를 최종 답변으로 숨기지 말고, retry와 human review 조건으로 연결해야 합니다.
네 번째는 benchmark 해석입니다. Perplexity의 수치는 SaC가 유망하다는 신호지만, WANDR 공개 전에는 재현 검증이 어렵습니다. DSQA, BrowseComp, HLE, WideSearch 같은 외부 benchmark도 실제 회사 corpus와 다릅니다. 팀별로 customer ticket, internal docs, code search, vendor advisory, policy memo 같은 자체 eval set을 만들어야 합니다. SaC류 architecture는 "모델이 똑똑하다"보다 "검색 과정이 task에 맞게 조립되고 검증되는가"를 평가해야 합니다.
검색은 에이전트의 실행 전 판단 근거가 됩니다
Perplexity Search as Code 발표의 실무 가치는 검색을 보조 기능에서 실행 전 판단 근거로 끌어올린 데 있습니다. 에이전트가 결정을 내리기 전에 어떤 증거를 가져왔는지, 그 증거를 어떤 순서로 비교했는지, 어떤 intermediate result를 버렸는지가 품질을 좌우합니다. 사람이 검색 결과 10개를 훑는 제품과, agent가 몇 분 동안 수천 retrieval operation을 실행하는 제품은 같은 검색 API로 다루기 어렵습니다.
개발자에게 이번 발표는 두 가지 질문을 남깁니다. 첫째, 우리 에이전트의 검색 실패는 query 품질 문제인가, search pipeline 제어 문제인가. 둘째, 반복 tool call에서 쓰는 token과 latency를 code execution과 explicit state management로 줄일 수 있는가. Perplexity의 답은 SaC입니다. 모델이 검색 primitive를 Python으로 조합하고, sandbox가 deterministic compute를 맡고, SDK가 검색 스택의 낮은 수준 handle을 제공하는 구조입니다.
다만 지금 단계에서 SaC는 Perplexity가 제시한 architecture와 자체 benchmark 결과입니다. WANDR 공개, 외부 재현, 실제 pricing trace, sandbox preview 안정성은 남은 확인 항목입니다. 그럼에도 Agent API와 Computer를 쓰는 팀, 또는 deep research agent를 만들고 있는 팀이라면 이번 발표를 단순한 검색 기능 업데이트로 넘기기 어렵습니다. 에이전트 검색은 더 이상 "검색 API를 한 번 호출한다"가 아니라, 실행 가능한 검색 프로그램을 어떻게 설계하고 검증할 것인가의 문제로 이동하고 있습니다.