Vera CPU 양산, AI 에이전트 병목을 겨냥한 88코어
NVIDIA Vera CPU가 full production에 들어갔습니다. 도구 호출, 샌드박스 실행, 검색이 만든 에이전트 CPU 병목을 봅니다.

- 무슨 일: NVIDIA가 2026년 5월 31일 GTC Taipei에서 Vera CPU full production과 가을 partner availability를 발표했습니다.
- Vera는 88개 Olympus core, 최대
1.2TB/sLPDDR5X bandwidth, agentic workload1.8xtask completion 주장을 앞세웁니다.
- Vera는 88개 Olympus core, 최대
- 의미: 에이전트가 도구 호출, 코드 실행, 검색, 오케스트레이션을 반복하면서 CPU가 GPU 옆의 latency 경로로 올라왔습니다.
- NVIDIA는 Anthropic, OpenAI, SpaceXAI, ByteDance, CoreWeave, Lambda, Nebius, Nscale, OCI를 채택 또는 평가 주체로 적었습니다.
- 주의점: 공개 benchmark는 agentic sandbox 중심이며, production chassis와 일반 서버 workload 검증은 아직 더 필요합니다.
NVIDIA가 2026년 5월 31일 GTC Taipei에서 Vera CPU가 full production에 들어갔다고 발표했습니다. 공식 newsroom은 Vera를 "AI agents를 위한 첫 CPU"라고 부르고, x86 CPU 대비 1.8배 빠른 task completion으로 agentic AI, reinforcement learning, data processing workload를 처리한다고 설명했습니다. 이 발표에서 새로 봐야 할 지점은 CPU 시장 진출 자체보다, AI 에이전트의 반복 실행이 데이터센터 CPU의 판매 논리로 바뀌었다는 점입니다.
Vera는 2026년 3월 GTC San Jose에서 처음 공개됐습니다. 당시 NVIDIA는 Vera CPU가 traditional rack-scale CPU보다 50% 빠르고 twice efficiency를 낸다고 설명했습니다. 5월 발표는 제품 스펙을 다시 소개하는 수준을 넘어 공급 단계와 고객 이름을 붙였습니다. NVIDIA는 Vera가 standalone Vera server, Vera Rubin system, Vera BlueField-4 STX storage platform의 CPU로 쓰이며, partner system과 cloud partner를 통한 availability가 2026년 가을부터 시작된다고 밝혔습니다.
채택 명단도 넓습니다. NVIDIA 발표문은 Anthropic, OpenAI, SpaceXAI, ByteDance, CoreWeave, Lambda, Nebius, Nscale, Oracle Cloud Infrastructure, NYSE를 고객 또는 평가 주체로 적었습니다. Dell Technologies, HPE, Lenovo, Supermicro는 standalone CPU server configuration을 제공할 major OEM으로 등장합니다. ASUS, Compal, Foxconn, GIGABYTE, Pegatron, QCT, Wistron, Wiwynn 같은 대만 system builder도 manufacturing ecosystem에 들어갑니다. 다만 발표 문구는 "planning to adopt", "exploring", "evaluating"을 섞어 씁니다. 이미 모든 회사가 production fleet에 넣었다는 뜻으로 읽으면 과합니다.

NVIDIA가 제시한 문제는 모델 inference만으로는 설명되지 않습니다. Technical blog는 GPU가 다음 tool call을 생성하고, CPU가 gcc -o hello hello.c ; ./hello 같은 명령을 실행한 뒤 결과를 다시 GPU에 넘기는 예를 듭니다. 이 구조에서 CPU는 prompt 전처리나 GPU feed를 맡는 host processor가 아닙니다. 도구 호출, sandboxed code execution, data retrieval, data processing, scheduling, orchestration을 실행하는 agent loop의 일부입니다.
에이전트 제품을 운영해 본 팀이라면 이 설명이 낯설지 않습니다. 코드 에이전트는 patch를 만들고 끝나지 않습니다. test runner를 실행하고, lint를 돌리고, failing log를 읽고, 파일을 검색하고, dependency graph를 따라가고, 다시 수정합니다. research agent는 browser search, PDF parsing, table extraction, database query, summarization을 반복합니다. enterprise agent는 approval, policy check, CRM update, ticket write, document generation을 엮습니다. 각 단계의 모델 호출은 GPU에서 빠르게 끝나도, 주변 실행이 CPU에서 길어지면 전체 request latency와 concurrency가 막힙니다.
Vera의 스펙은 이 "주변 실행"을 겨냥합니다. NVIDIA는 Vera가 88개 custom Olympus core를 쓰고, Spatial Multithreading과 LPDDR5X memory subsystem을 통해 최대 1.2TB/s memory bandwidth를 제공한다고 설명합니다. Technical blog는 Olympus core가 NVIDIA Grace 대비 최대 50% 높은 IPC를 목표로 한다고 적었습니다. branch-heavy code를 위해 neural branch predictor, 10-wide decode unit, deep out-of-order engine, graph prefetcher도 넣었습니다. AI agent runtime은 Python, JavaScript, graph traversal, database query, code compilation처럼 분기와 메모리 접근이 많은 경로를 자주 지나갑니다.
메모리 전력도 NVIDIA가 반복해서 강조하는 항목입니다. Vera technical blog는 LPDDR5X subsystem이 일반 DDR5 configuration의 100W 이상보다 낮은 30W 미만 memory power로 최대 1.2TB/s bandwidth를 제공한다고 설명합니다. 같은 글은 Vera가 peak memory bandwidth의 90% 이상을 sustained한다고 주장합니다. agentic AI factory가 수천 개 sandbox와 tool call을 동시에 실행한다면, CPU core 수만 늘리는 설계보다 메모리 대역폭과 power budget이 중요해집니다.
NVIDIA의 1.8배 성능 주장은 agentic sandbox를 전면에 세웁니다. Technical blog의 Figure 4는 code compilation, code analysis, Python을 포함한 여러 workload에서 Vera가 x86 architecture 대비 1.8배 이상 높은 agentic sandbox performance를 낸다고 설명합니다. Newsroom도 Phoronix를 인용해 code compilation, Python, Java, database processing 같은 workload에서 Vera가 fastest overall performance를 보였다고 적었습니다. 이 네 가지는 "AI benchmark"라기보다 에이전트가 실제 작업 중 호출하는 CPU 작업입니다.
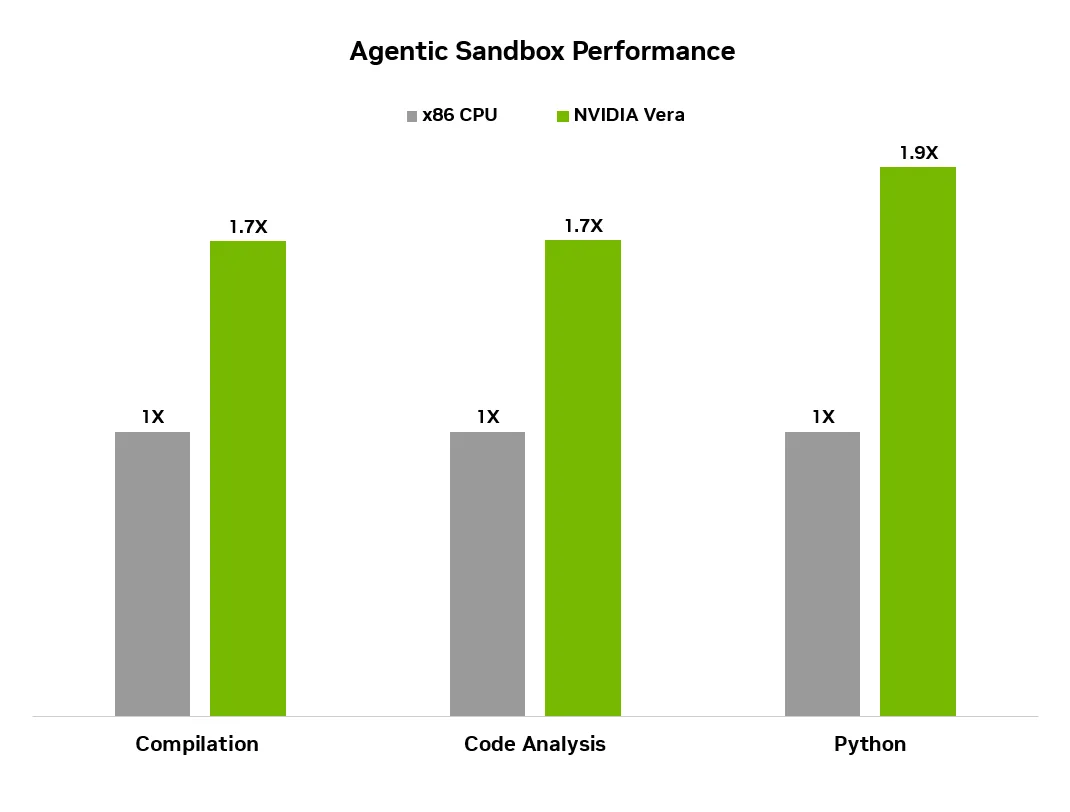
Phoronix benchmark는 이번 발표의 신뢰도를 높이는 동시에 한계를 남깁니다. NVIDIA blog는 Phoronix가 single-socket Vera CPU를 테스트했다고 소개했습니다. 조건은 450W TDP와 30W 미만 memory power profile이었습니다. workload는 code compilation, file compression, video transcoding, Python, Java, database management였습니다. Phoronix는 Vera가 Grace 대비 geometric mean 1.6배 성능 향상을 냈고, AMD EPYC 9575F 5.0GHz high frequency processor 대비 geometric mean 10% 우위를 보였다고 평가했습니다.
하지만 외부 보도와 커뮤니티 토론은 benchmark scope를 따로 표시했습니다. Tom's Hardware는 첫 benchmark가 NVIDIA Santa Clara에서 진행됐고, 테스트 범위가 NVIDIA가 겨냥한 workload 중심이었다고 짚었습니다. PC Gamer도 "NVIDIA-sanctioned tests"라는 표현으로 같은 제한을 지적했습니다. Phoronix 자체도 production enclosed server chassis에서 power와 frequency를 보는 것이 2026년 후반에는 더 중요해질 수 있다고 설명했습니다. 따라서 Vera의 성능을 일반 서버 전체 workload 승리로 확대하는 제목은 아직 이릅니다.
개발자에게 더 직접적인 질문은 "우리 에이전트가 어디서 기다리나"입니다. 모델 호출이 2초이고 test suite가 45초라면 GPU upgrade보다 CPU sandbox 병렬성이 중요합니다. retrieval query와 document parsing이 병목이면 storage, database, memory bandwidth가 체감 latency를 좌우합니다. tool execution 결과를 받아 다시 reasoning하는 multi-step agent에서는 CPU step이 매번 GPU step 사이에 끼어듭니다. NVIDIA가 "CPU execution becomes part of the AI loop"라고 그린 이유도 이 구조 때문입니다.
이 구조는 reinforcement learning에도 연결됩니다. RL post-training에서 모델은 code generation, math tool, simulator, browser, game environment, validator를 반복 호출할 수 있습니다. GPU가 policy를 생성해도 environment step, judge, test execution은 CPU 쪽에서 돌아갑니다. NVIDIA는 Vera가 더 많은 completed evaluation과 더 많은 training window data를 만들 수 있다고 설명합니다. agent가 더 오래 생각하고 더 많이 검증할수록 CPU가 accelerator utilization을 붙잡는 시간이 늘어납니다.
Vera BlueField-4 STX 발표도 같은 방향입니다. NVIDIA는 별도 newsroom에서 Vera BlueField-4 STX가 agent, context memory, file-based data access를 silicon level security로 보호하고, storage acceleration과 networking을 통합한다고 설명했습니다. 에이전트가 파일과 tool을 계속 만지는 구조에서는 compute만이 아니라 권한, storage, network policy도 runtime path가 됩니다. Vera CPU 발표문이 BlueField-4 STX를 함께 언급한 것은 agentic workload가 CPU, DPU, storage, security를 한 묶음으로 요구한다는 신호입니다.
NYSE 사례는 AI lab과 다른 해석을 줍니다. NVIDIA 발표문에서 NYSE Group president Lynn Martin은 NYSE가 하루 1조 1000억 개 이상 message를 처리하며, Redpanda와 HPE, Vera CPU를 통해 capacity를 scaling하고 latency를 더 최적화하겠다고 말했습니다. 이 발언은 "AI agent"라는 단어만으로는 설명되지 않습니다. Vera가 겨냥하는 범위가 model-serving 주변 CPU 작업뿐 아니라 streaming data, database, analytics, latency-sensitive infrastructure까지 넓다는 뜻입니다.
Anthropic과 Oracle의 발언은 agent workload 쪽에 더 가깝습니다. Anthropic head of compute James Bradbury는 agentic workload를 풀기 위한 ecosystem의 유망한 부분으로 Vera를 평가한다고 밝혔습니다. OCI executive Mahesh Thiagarajan은 training, inference, agentic AI 수요를 맞추기 위해 infrastructure를 scaling하고 있다고 말했습니다. 그는 Vera CPU가 high-throughput reasoning과 data processing workload를 지원한다고 설명했습니다. 이 발언들은 모델 성능 경쟁보다 infrastructure scheduling과 cost curve에 가까운 주제입니다.
OpenAI와 SpaceXAI에 대해서는 공개 quote보다 delivery story가 먼저 나왔습니다. NVIDIA는 2026년 5월 18일 Ian Buck이 Anthropic, OpenAI Mission Bay, SpaceXAI Palo Alto, Oracle Cloud Infrastructure에 첫 Vera CPU system을 직접 전달했다고 블로그에 썼습니다. 같은 글은 OpenAI에서 server lid를 열어 내부를 보여줬고, SpaceXAI에서는 core, memory layout, cooling에 관한 질문이 오갔다고 설명합니다. 이 내용은 상징성이 강하지만, production 규모나 workload 성격을 증명하지는 않습니다.
그래서 이번 발표를 "NVIDIA가 Intel과 AMD를 이겼다"로만 읽으면 일부를 놓칩니다. 경쟁 대상은 EPYC와 Xeon이 맞지만, NVIDIA가 판매하려는 기준은 기존 cloud CPU의 cores per dollar가 아니라 AI factory의 tokens per dollar, output per watt, task completion time입니다. 이 기준에서는 CPU가 GPU의 부속품이 아니라 GPU가 다음 token을 생성하기 전후에 필요한 실행 환경입니다. 에이전트가 도구를 더 많이 호출할수록 이 기준은 더 눈에 띕니다.
소프트웨어 팀은 이 발표를 hardware roadmap보다 observability checklist로 읽을 수 있습니다. agent latency를 모델 호출 시간, tool execution time, retrieval time, sandbox startup time, test runner time, policy approval time으로 나눠 기록해야 합니다. 각 step의 CPU utilization, memory bandwidth, storage wait, network wait도 분리해야 합니다. Vera 같은 CPU가 실제 비용을 줄이는지는 "에이전트 한 요청당 GPU token time"이 아니라 "작업 완료까지 CPU step이 몇 번, 몇 초, 몇 watt를 썼나"로 드러납니다.
클라우드 구매자에게는 lock-in 질문도 생깁니다. NVIDIA는 Vera가 standalone CPU server로도 제공되고, Vera Rubin platform host CPU로도 들어가며, BlueField-4 STX storage processor에도 통합된다고 설명합니다. full-stack AI factory를 NVIDIA로 맞추면 CPU-GPU coherent bandwidth, storage security, networking, rack power를 한 설계로 받을 수 있습니다. 반대로 특정 workload가 일반 x86 fleet에서 충분히 잘 돌거나, cloud provider의 custom Arm CPU가 더 싸다면 Vera의 1.8배 agentic sandbox 성능이 전체 bill에 얼마나 반영되는지 따져야 합니다.
가을 availability도 확인 지점입니다. 공식 발표는 partner system과 cloud partner를 통한 시작 시점을 2026년 가을로 적었습니다. 지금 시점에서 구매 가능한 대량 cloud instance 목록, price, SLA, region, software stack은 아직 별도 발표가 필요합니다. production chassis에서의 thermals, frequency, memory configuration도 benchmark 해석에 들어가야 합니다. agent workload는 synthetic benchmark보다 noisy하고, 실제 enterprise environment에서는 policy engine, logging, secret broker, network proxy가 함께 latency를 만듭니다.
그럼에도 Vera 발표가 뉴스인 이유는 AI infrastructure의 비교 단위가 바뀌고 있기 때문입니다. 2023년 이후 LLM 경쟁은 model parameter, context window, token price, GPU availability를 중심으로 설명됐습니다. 2025년 이후 coding agent와 research agent가 늘면서 "모델이 무엇을 생성했나"보다 "생성한 다음 무엇을 실행했나"가 비용과 reliability를 좌우하기 시작했습니다. NVIDIA는 이 실행 단계를 CPU 사업의 새 수요로 포장했고, 2026년 5월 31일 발표는 그 포장을 공급망과 고객 명단으로 확장했습니다.
개발자가 당장 할 수 있는 검증은 단순합니다. 에이전트 trace에서 model step과 CPU step을 분리하고, tool call이 많은 요청을 따로 모읍니다. code agent라면 compile, test, static analysis, package install, file search 시간을 별도 metric으로 기록합니다. data agent라면 parsing, SQL, embedding lookup, reranking, format conversion을 나눕니다. 그다음 hardware나 cloud SKU를 비교할 때 GPU throughput만 보지 말고 completed task per dollar, completed evaluation per hour, failed sandbox restart rate를 같이 봐야 합니다.
Vera CPU는 아직 모든 팀이 살 수 있는 범용 답안이 아닙니다. NVIDIA가 공개한 성능 수치도 agentic workload에 맞춘 주장이고, 생산 시스템에서의 가격과 availability는 가을 이후 확인해야 합니다. 그러나 이번 발표가 던진 질문은 제품보다 빨리 적용할 수 있습니다. AI 에이전트가 답변 생성기를 넘어 실행기로 바뀌면 병목은 GPU kernel 밖으로 나옵니다. 파일을 열고, 코드를 돌리고, database를 조회하고, validator를 통과하는 그 시간까지 포함해야 에이전트의 실제 속도와 비용이 보입니다.