JetPack 7.2 공개, Jetson에서 한 줄로 배포하는 NemoClaw
NVIDIA JetPack 7.2가 Jetson에 NemoClaw, agent skills, Yocto, MIG를 묶어 물리 AI 에이전트 배포 기준을 바꿉니다.

- 무슨 일: NVIDIA가
JetPack 7.2를 공개하고 Jetson에서 NemoClaw를 한 줄로 배포하는 경로를 열었습니다.- 발표 범위는 Jetson agent skills, Yocto 공식 지원, Jetson Thor
MIG, Orin 32GB Super Mode까지 포함합니다.
- 발표 범위는 Jetson agent skills, Yocto 공식 지원, Jetson Thor
- 개발자 영향: BSP bring-up, memory optimization, model benchmarking 같은 엣지 장비 작업이 agent-executable workflow로 포장됩니다.
- 운영 쟁점: 물리 장치에서는 모델 점수보다 deterministic latency, OS reproducibility, memory footprint, safety workload isolation이 먼저 부딪힙니다.
- NVIDIA 기술 블로그는 Thor에서 12 SM/1536 CUDA core 파티션과 8 SM/1024 CUDA core 파티션을 나누는
MIG구성을 제시했습니다.
- NVIDIA 기술 블로그는 Thor에서 12 SM/1536 CUDA core 파티션과 8 SM/1024 CUDA core 파티션을 나누는
NVIDIA가 2026년 6월 1일 COMPUTEX와 GTC Taipei 흐름 안에서 JetPack 7.2와 NemoClaw support on Jetson을 공개했습니다. 같은 날 올라온 NVIDIA Technical Blog는 이 발표를 더 실무적인 언어로 풀었습니다. Jetson 장치에서 curl -fsSL nvidia.com/nemoclaw.sh | bash 한 줄로 NemoClaw 기반 workflow를 배포하고, Jetson agent skills로 Linux customization, memory optimization, model benchmarking을 자동화한다는 내용입니다.
이번 발표는 새 LLM 하나가 나왔다는 뉴스가 아닙니다. 최근 NVIDIA는 Nemotron 3 Ultra, OpenShell, NemoClaw, CUDA-X agent skills를 묶어 서버와 워크스테이션용 에이전트 실행 스택을 강조했습니다. JetPack 7.2에서 달라진 지점은 그 실행 스택이 Jetson board로 내려온다는 점입니다. 로봇, 산업 검사 카메라, 스마트 리테일 장비, 교통 신호 시스템, 드론처럼 전력과 메모리, 지연시간 제한이 있는 장비가 대상입니다.
NVIDIA의 공식 표현은 "agentic AI is getting physical"입니다. 한국어로 옮기면 에이전트가 브라우저나 IDE 안의 자동화에서 벗어나 카메라, 센서, 로봇 팔, 이동체가 붙은 시스템 안으로 들어간다는 뜻에 가깝습니다. 물리 장치에서는 실패의 형태가 다릅니다. 코드 리뷰 에이전트가 잘못된 PR을 올리면 사람이 닫을 수 있지만, 공장 결함 검사나 로봇 제어 pipeline에서 지연시간이 흔들리면 생산 라인, 안전 장치, 현장 운영 절차가 함께 영향을 받습니다.
JetPack 7.2가 묶은 다섯 가지 변화
NVIDIA 기술 블로그는 JetPack 7.2의 범위를 다섯 갈래로 설명합니다. NemoClaw one-command deployment, Jetson agent skills, Jetson Thor의 Multi-Instance GPU, Yocto Project 공식 지원, Jetson AGX Orin 32GB Super Mode입니다. 이 항목들은 서로 다른 기능처럼 보이지만, 엣지 장비에서 에이전트를 실제 제품으로 넣을 때 필요한 작업 목록과 거의 겹칩니다.
| JetPack 7.2 항목 | NVIDIA 설명 | 현장 영향 |
|---|---|---|
| NemoClaw 배포 | Jetson에서 한 줄 명령으로 agent workflow 실행 | 로봇과 vision agent prototype의 초기 설치 비용 감소 |
| Jetson agent skills | Linux customization, memory optimization, model benchmarking | BSP와 성능 튜닝을 반복 가능한 workflow로 문서화 |
| Thor MIG | 두 GPU instance로 mixed-criticality workload 분리 | 제어 loop와 생성 AI 추론을 같은 SoC 안에서 격리 |
| Yocto 공식 지원 | validated recipes, reference images, OE4T roadmap 참여 | 제품용 Linux image 재현성과 attack surface 관리 |
| Orin 32GB Super | 200 TOPS에서 241 TOPS, module cost 45% 절감 주장 | 기존 Orin 계열 장비에서 LLM/VLM workload 여지 확대 |
이 표에서 눈여겨볼 부분은 agent skills입니다. NVIDIA는 skill을 추상적인 prompt 모음으로 설명하지 않습니다. 기술 블로그는 "어떤 도구를 호출하고, 어떤 출력을 만들고, 어떻게 검증할지 정의하는 repeatable, agent-executable instructions"라고 설명합니다. 이 표현은 .md 지식 문서와 shell script 사이의 중간 형태입니다. 현장 엔지니어가 매번 BSP 설정, kernel reservation, redundant process 제거, model benchmark를 손으로 반복하는 대신, 에이전트가 같은 절차를 따라가도록 묶는 방식입니다.

세 범주 중 첫 번째는 Jetson Linux customization입니다. NVIDIA 설명에 따르면 custom carrier board용 BSP를 처음부터 만들고, I/O, clock, fan control, power profile 같은 항목을 특정 hardware design에 맞춰 구성하는 작업을 다룹니다. 일반 웹 서비스 개발자에게는 낯선 단계지만, Jetson을 실제 제품에 넣는 팀에는 출시 일정과 직결되는 작업입니다. NVIDIA는 이런 작업이 과거에는 몇 주가 걸렸고, agent skill을 통해 days 단위로 줄일 수 있다고 주장합니다.
두 번째는 memory optimization입니다. 엣지 장비에서 메모리는 단순한 스펙 항목이 아닙니다. 같은 workload가 16GB module에서만 돌아가느냐, 8GB module에서도 돌아가느냐에 따라 BOM cost, 발열, 전력, 공급망 선택지가 바뀝니다. 기술 블로그는 bootloader memory carveouts, kernel memory reservation, redundant user space process 제거 같은 항목을 언급합니다. 이는 LLM prompt engineering보다 embedded Linux와 deployment engineering에 가까운 작업입니다.
세 번째는 model benchmarking입니다. 로봇 또는 산업 카메라에 들어가는 모델 선택은 "가장 큰 모델이 가장 좋다"로 끝나지 않습니다. target device, camera stream, batch size, latency budget, thermal envelope, safety process가 함께 묶입니다. NVIDIA는 Jetson diagnostics와 inference optimization까지 포함해, 특정 Jetson device에서 어떤 model configuration이 가장 효율적인지 찾는 skill을 제시했습니다. 이 부분은 LLMOps보다 MLOps와 embedded QA가 만나는 지점입니다.
NemoClaw는 서버에서 Jetson으로 내려온다
NemoClaw는 최근 NVIDIA 발표에서 계속 등장하는 이름입니다. 앞선 GTC 발표에서는 OpenClaw 기반 에이전트를 더 안전하게 운영하기 위한 reference stack, OpenShell runtime, privacy와 security control이 강조됐습니다. JetPack 7.2에서는 같은 이름이 Jetson 장치의 배포 경로로 들어갑니다. NVIDIA Developer의 JetPack 페이지도 JetPack 7이 NemoClaw와 purpose-built Jetson agent skills로 agentic-ready라고 설명합니다.
서버에서 돌아가는 에이전트와 Jetson에서 돌아가는 에이전트의 차이는 실행 환경입니다. 서버는 scaling과 cost attribution이 먼저 문제로 올라옵니다. Jetson은 physical interaction, sensor timing, memory footprint, offline 또는 제한된 네트워크, 장기 배포 OS image가 먼저 부딪힙니다. 그래서 JetPack 7.2의 핵심은 "NemoClaw가 Jetson에서도 된다"보다 "NemoClaw가 들어갈 수 있도록 OS, GPU partition, BSP, benchmark, Yocto까지 같이 정렬한다"에 가깝습니다.
NVIDIA 공식 블로그는 Solomon, Advantech, Rebotnix, Spingence, SandStar, NoTraffic, Hexagon Robotics, Zipline 같은 사례를 나열했습니다. Solomon은 humanoid robot에서 reasoning, perception, sensor fusion, locomotion, manipulation을 하나의 workflow로 조정한다고 소개됐습니다. Advantech는 NemoClaw, Nemotron 3, Jetson Thor를 이용해 robot fleet management, defect detection, autonomous decision-making을 다루는 factory brain을 구축한다고 설명됐습니다.
이 사례 목록은 검증된 벤치마크라기보다 NVIDIA ecosystem 방향을 보여주는 고객 지도에 가깝습니다. 그래도 개발자에게는 유용한 힌트가 있습니다. Jetson 위 에이전트의 초기 target은 웹 브라우저 조작이나 문서 요약이 아니라, vision pipeline과 물리 장치 판단입니다. Rebotnix smart city camera, Spingence defect agent, SandStar smart retail, NoTraffic traffic management가 모두 camera, sensor, real-time operation을 전제로 합니다.
Thor MIG가 중요한 이유
Jetson Thor에서 추가된 MIG 지원은 이번 발표에서 가장 물리 장치다운 변화입니다. NVIDIA 기술 블로그는 integrated Blackwell GPU를 dedicated compute, cache, memory bandwidth를 가진 두 isolated GPU instance로 나눌 수 있다고 설명합니다. 한 파티션은 inferencing, rendering, visualization, general CUDA workload용 12 SMs, 1536 CUDA cores입니다. 다른 파티션은 robotics, control, perception, safety-critical workload용 8 SMs, 1024 CUDA cores입니다.
이 숫자가 중요한 이유는 에이전트가 항상 고정된 workload가 아니기 때문입니다. vision-language reasoning이나 task planning이 갑자기 긴 추론을 시작하면, 같은 SoC에서 돌던 perception, sensor fusion, motion planning의 latency budget을 침범할 수 있습니다. NVIDIA는 Preemptible RT kernel과 MIG를 함께 언급하며 mixed-criticality system의 deterministic execution을 강조했습니다. 로봇 제어 loop는 "대체로 빠름"이 아니라 worst-case latency 관리가 필요합니다.
클라우드 서버의 MIG는 보통 tenancy와 GPU utilization 언어로 설명됩니다. Jetson Thor의 MIG는 제품 안전과 제어 품질의 언어로 읽힙니다. 한쪽 파티션에서는 생성 AI 추론이나 시각화가 돌아가고, 다른 파티션에서는 perception 또는 safety monitoring이 일정한 자원을 받습니다. container와 service를 CUDA Runtime controls, NVIDIA Container Toolkit으로 특정 MIG partition에 할당할 수 있다는 설명도 이 맥락입니다.
Yocto 지원은 제품화를 겨냥한다
JetPack 7.2의 Yocto Project 공식 지원은 AI 뉴스 제목으로는 덜 화려하지만, 장비를 실제 판매하는 팀에는 큰 변화입니다. NVIDIA는 Jetson developer kit용 validated recipes와 reference images를 제공하고, OE4T layer의 roadmap contribution, CI/CD, SQA, release를 맡는다고 설명했습니다. Yocto는 필요한 driver, service, library만 포함한 custom Linux distribution을 만들 때 쓰이는 embedded Linux 생태계입니다.
NVIDIA 기술 블로그는 Yocto의 이점을 customizability, reproducibility, open ecosystem으로 나눕니다. customizability는 Ubuntu L4T image를 그대로 쓰지 않고 제품에 필요한 구성만 넣어 image size와 memory footprint를 줄이는 문제입니다. reproducibility는 같은 image build가 여러 번 동일하게 나오는 문제입니다. 의료, 산업, 물류 장비처럼 인증과 현장 재현이 필요한 제품에서는 이 항목이 운영 비용으로 바로 연결됩니다.
에이전트가 물리 장치에 들어가면 update 문제도 달라집니다. 브라우저 extension이나 SaaS agent는 서버 쪽에서 빠르게 rollback할 수 있지만, 공장이나 도로에 깔린 Jetson 장비는 fleet update, secure OTA, 장애 복구 절차가 붙습니다. JetPack 페이지가 secure boot, disk encryption, runtime integrity, fTPM, secure OTA를 Jetson Linux security feature로 함께 나열하는 이유도 여기에 있습니다.
Orin 32GB Super와 메모리 계산
JetPack 7.2는 기존 Jetson AGX Orin 32GB에도 Super Mode를 제공합니다. NVIDIA 기술 블로그는 GPU frequency를 930MHz에서 1.3GHz로 올리고 power envelope를 최대 60W로 확장해 AI performance를 200 TOPS에서 241 TOPS로 높인다고 설명했습니다. NVIDIA는 이를 통해 AGX Orin 64GB에 가까운 성능을 더 낮은 module cost로 얻을 수 있다고 주장하며, 45% cost reduction 표현도 사용했습니다.
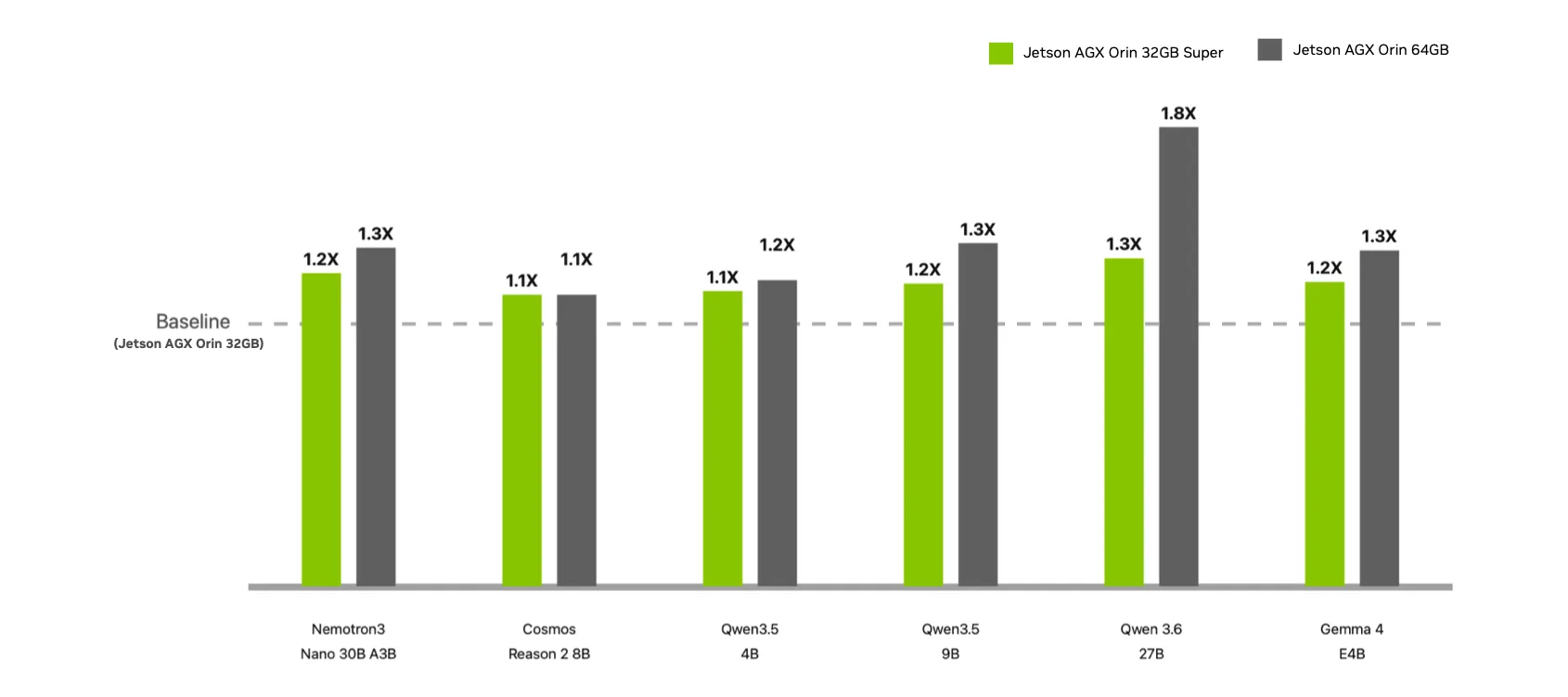
기술 블로그의 모델별 표는 숫자를 더 구체화합니다. Nemotron3 Nano 30B A3B는 Jetson AGX Orin 32GB baseline에서 31 tokens/sec, 32GB Super에서 37 tokens/sec, 64GB에서 40 tokens/sec로 제시됐습니다. Qwen 3.6 27B는 각각 4, 5, 7 tokens/sec입니다. Gemma 4 E4B는 25, 29, 32 tokens/sec입니다. 이 숫자는 서버 LLM benchmark와 비교하면 작아 보이지만, 카메라와 로봇 장치 안에서 local reasoning을 붙이는 비용 계산에는 직접적인 입력값입니다.
SandStar 사례도 같은 방향입니다. NVIDIA 공식 블로그는 SandStar가 Jetson Orin NX와 NemoClaw로 AI vending machine과 smart retail operation을 운영하며, 약 40% memory optimization으로 16GB device에서 8GB device로 옮겼다고 설명했습니다. NoTraffic은 static compilation과 targeted kernel pruning으로 CUDA library overhead를 최적화해 memory usage를 29% 줄였다고 소개됐습니다. 이 수치들은 vendor case study 성격이므로 독립 검증은 필요하지만, NVIDIA가 무엇을 판매하려는지는 명확합니다. 물리 AI 에이전트의 병목은 모델 호출 API가 아니라 memory와 packaging입니다.
개발팀이 실제로 점검할 질문
JetPack 7.2를 바로 채택할 팀은 로봇, 산업 검사, embedded AI 장비를 다루는 팀입니다. 일반 웹/앱 개발팀에는 멀게 느껴질 수 있습니다. 그러나 에이전트 개발 관점에서 보면 이번 발표는 중요한 기준선을 만듭니다. AI agent가 production에서 움직인다는 말이 단순히 GitHub issue를 처리하거나 PR을 올린다는 뜻이 아니라, 하드웨어 resource partition과 OS image reproducibility까지 포함할 수 있다는 사례이기 때문입니다.
첫 번째 질문은 runtime boundary입니다. NemoClaw와 OpenShell이 어느 수준까지 tool, network, filesystem, model routing을 통제하는지 확인해야 합니다. Jetson 장치에서는 offline operation, field debugging, physical actuator 연결 때문에 일반 cloud sandbox보다 권한 모델이 더 복잡합니다. 에이전트가 vision pipeline을 수정하거나 process를 재시작하거나 device configuration을 바꾸는 경우, approval과 audit log의 단위가 명확해야 합니다.
두 번째 질문은 skill 검증입니다. Jetson agent skills가 NVIDIA documentation과 design guide에서 만들어졌다는 점은 장점이지만, 현장 hardware variation은 큽니다. custom carrier board, sensor mix, power budget, thermal design, kernel module, regulatory requirement가 다르면 skill 결과를 그대로 믿을 수 없습니다. skill이 만든 BSP 설정, memory tuning, benchmark 결과를 어떤 fixture와 hardware-in-the-loop test로 검증할지가 제품팀의 책임으로 남습니다.
세 번째 질문은 update 전략입니다. Yocto 공식 지원은 reproducible image를 만들기 위한 좋은 출발점입니다. 하지만 agent runtime이 현장 장비에 들어가면 model update, skill update, policy update, OS image update가 서로 다른 cadence를 가질 수 있습니다. 하나의 OTA로 묶을지, runtime policy만 별도로 갱신할지, 장애 발생 시 이전 image와 이전 policy로 어떻게 되돌릴지 설계해야 합니다.
네 번째 질문은 cost model입니다. NVIDIA는 memory optimization과 Orin 32GB Super를 통해 더 작은 module 또는 기존 hardware에서 더 많은 workload를 돌리는 그림을 제시했습니다. 이 계산은 tokens/sec만으로 결정되지 않습니다. camera count, frame rate, safety margin, thermal throttling, on-device storage, operator intervention cost, fleet management cost가 함께 들어갑니다. 특히 60W Super Mode는 전력과 발열 envelope를 다시 계산하게 만듭니다.
서버 에이전트와 물리 에이전트의 갈림길
2026년 AI agent 뉴스는 대부분 IDE, 브라우저, GitHub, cloud workflow를 중심으로 움직였습니다. JetPack 7.2는 같은 agent라는 단어를 쓰지만 판단 기준이 다릅니다. cloud coding agent는 task success rate, PR merge rate, token cost, repository permission을 봅니다. Jetson physical agent는 latency jitter, memory footprint, deterministic partition, OS reproducibility, hardware bring-up 시간을 봅니다.
이 차이는 모델 공급자 경쟁에도 영향을 줍니다. 서버 에이전트에서는 OpenAI, Anthropic, Google, xAI, Mistral 같은 모델 이름이 앞에 옵니다. 물리 장치에서는 모델 이름보다 board support package, CUDA stack, sensor SDK, vision pipeline, OTA, safety certification이 함께 묶입니다. NVIDIA가 JetPack 7.2에서 NemoClaw와 Jetson agent skills를 한 패키지로 다루는 이유도 여기에 있습니다. 모델만으로는 로봇 장비가 출고되지 않습니다.
취재 시점에 NVIDIA 기술 블로그의 공개 댓글은 Discuss (0)로 보였고, Hacker News에서도 JetPack 7.2 자체에 대한 큰 스레드는 확인하지 못했습니다. 커뮤니티 검증은 아직 부족합니다. 따라서 이번 발표를 "물리 AI agent가 완성됐다"로 읽으면 과장입니다. 더 정확한 읽기는 NVIDIA가 Jetson 생태계의 오래된 작업인 BSP, memory, benchmarking, Yocto, GPU partitioning을 agent 시대의 개발 표면으로 다시 포장했다는 것입니다.
앞으로 볼 지점은 세 가지입니다. 첫째, Jetson agent skills가 실제 custom hardware bring-up에서 얼마나 반복 가능한 결과를 내는지입니다. 둘째, NemoClaw와 OpenShell이 물리 장치의 권한, audit, rollback 요구를 얼마나 흡수하는지입니다. 셋째, Orin 32GB Super와 Thor MIG가 vision-language agent workload에서 열, 전력, latency budget을 실제 제품 수준으로 맞추는지입니다. JetPack 7.2의 뉴스 가치는 새 모델 headline보다 이 검증 항목들이 명확해졌다는 데 있습니다.