Google SRE AI Operator 공개, 장애 조치까지 맡는 운영 에이전트
Google SRE가 AI Operator, Actus, Detectr로 생산 장애 대응을 에이전트화하는 AI-Ops 설계를 공개했습니다.

- 무슨 일: Google SRE가
AI Operator,Actus, Detectr를 포함한 생산 운영 에이전트 설계를 공개했습니다.- 문서는 AI 코딩으로 변경 속도가 빨라진 뒤 SRE가 장애 대응, 배포 검증, 권한 통제를 어떻게 다시 설계하는지 설명합니다.
- 수치: Incident Hypothesis는 MTTM 10% 감소, Investigation Dashboard는 지원 incident에서 약 44% MTTM 감소를 냈다고 Google이 적었습니다.
- 실무 영향: 운영 에이전트의 쟁점은 모델 성능보다
dry_run, agent identity, circuit breaker, red button 같은 실행 통제입니다.- Google은 AI가 직접 low-level script를 실행하지 않고 Actuation Agent가 계획, 위험 평가, 승인 단계, 사후 guardian을 분리한다고 설명합니다.
Google SRE가 새 글 AI in SRE: How Google is Engineering the Future of Reliable Operations를 공개했습니다. 주제는 생산 운영용 AI 에이전트 설계입니다. 제목만 보면 AI-Ops 일반론처럼 보이지만, 본문은 훨씬 구체적입니다. Google은 AI Operator, Actus라고도 부르는 Actuation Agent, Gemini 기반 Detectr, AI Alert, Investigation Dashboard, Antigravity CLI, Production Agent MCP 서버, A2A를 하나의 운영 체계로 묶었습니다. AI가 코드를 더 빨리 쓰는 시대에 SRE가 어디서 승인을 잡고, 어디서 기계에 실행권을 넘기며, 어디서 모든 실행을 멈출 수 있어야 하는지를 문서화한 글입니다.
Google 문서의 출발점은 개발 생산성입니다. 초록은 AI 코딩 어시스턴트가 코드 생성과 배포 속도를 크게 높이고 있으며, 일부 조직이 최대 4배 생산성 향상을 목표로 한다고 적습니다. 같은 속도로 사람이 코드 리뷰와 장애 대응을 늘릴 수 없다는 판단이 이어집니다. Google은 수동 리뷰가 machine-generated code volume과 선형으로 확장되지 않고, 복잡해진 시스템에서 표준 운영 대응도 뒤처진다고 봅니다. 이 문장은 코딩 에이전트 시장의 다음 비용을 운영 조직이 치르게 된다는 뜻으로 읽힙니다.
여기서 Google이 제시한 답은 단순한 챗봇이 아닙니다. 문서가 말하는 AI Operator는 production alert의 first responder 역할을 맡습니다. alert signal을 받으면 여러 investigation module을 병렬로 돌리고, 과거 유사 incident에서 사람이 수행한 조사 예시를 바탕으로 root cause analysis를 시도합니다. RCA 이후에는 deterministic signal booster, mitigation skill, text proto에 담긴 few-shot investigation strategy를 동적으로 골라 씁니다. 현재 구조는 critical operation에는 L2 autonomy로 사람 승인을 요구하고, minor incident에는 L3 autonomy로 bounded autonomous mitigation을 수행할 수 있다고 설명합니다.
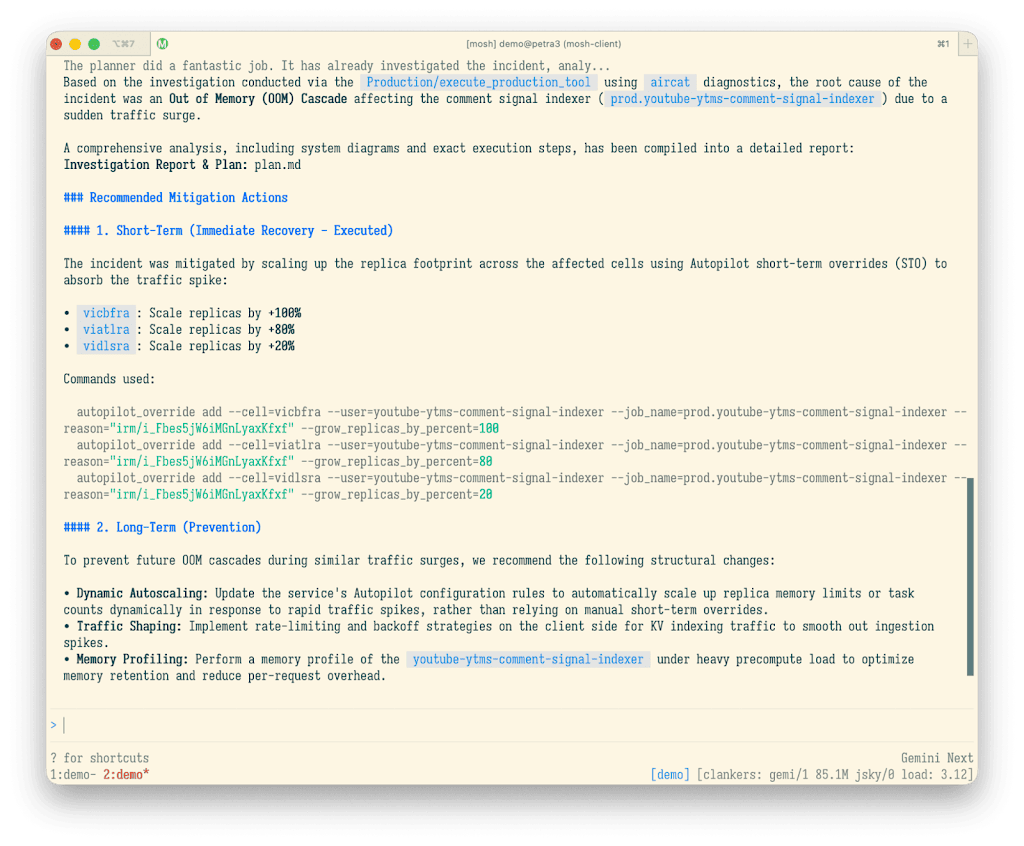
본문 이미지에서 눈에 띄는 부분은 agent가 "조치했다"는 결과보다 실행 경로입니다. Google의 예시는 YouTube comment signal indexer 관련 incident를 분석하고, traffic spike를 흡수하기 위해 replica footprint를 cell별로 늘리는 단기 조치와 장기 예방 조치를 제안합니다. 명령어에는 grow_replicas_by_percent 같은 구체 parameter가 붙고, agent는 investigation report와 plan을 남깁니다. SRE 글의 관심은 모델이 그럴듯한 문장을 만들었는지가 아니라, 운영자가 나중에 재현하고 감사할 수 있는 실행 trace가 남는지에 있습니다.
Google은 이 구조를 Safety Trifecta라는 세 가지 원칙으로 묶었습니다. 첫째, transparency입니다. AI agent는 어떤 signal을 봤고, 어떤 hypothesis를 검토했고, 왜 특정 action을 선택했으며, confidence가 어느 정도였는지를 남겨야 합니다. 둘째, real-time risk evaluation입니다. 같은 cell drain 조치라도 평상시에는 낮은 위험이지만 regional peak, active incident, error budget 상태에 따라 높은 위험이 될 수 있습니다. 셋째, progressive authorization입니다. agent는 첫날부터 전체 production access를 받지 않고, human approved 단계에서 시작해 SRE autonomy level에 따라 권한을 늘립니다.
실행 통제는 더 직접적입니다. Google은 agentic system이 개발자의 standing credential로 움직이면 안 된다고 적습니다. agent identity는 human user와 분리되고, 강하게 인증되며, 필요한 순간에 필요한 권한만 받아야 합니다. agent-specific rate limit와 circuit breaker도 필요합니다. agent가 runaway loop에 빠지거나 자원을 과도하게 쓰면 자동으로 끊을 수 있어야 하기 때문입니다. production state를 바꾸는 API에는 dry_run=true 같은 선언적 dry-run mode가 있어야 하며, agent와 safety framework와 human reviewer가 blast radius를 미리 계산할 수 있어야 합니다.
이 기준 때문에 AI Operator는 저수준 script를 직접 실행하지 않습니다. Google은 reasoning engine과 execution engine을 분리합니다. AI Operator가 mitigation strategy를 만들면 Actuation Agent가 EvaluateAction 요청을 받아 parameter를 채우고, LLM intent를 검증 가능한 실행 계획으로 바꿉니다. 실행 전에는 mandatory dry-run, justification verification, concurrent action check가 들어갑니다. agent가 L3 실행을 요청해도 risk score가 높거나 production state가 이상하면 Actuation Agent가 자동으로 L2로 낮춰 human approval을 요구합니다. 이 downgrade 규칙은 운영 에이전트의 실제 제품 요구사항에 가깝습니다.
Actuation Agent에는 사후 guardian도 들어갑니다. long-running operation 상태를 추적하고 mitigation이 성공했는지 polling하며, 사람에게 "red button" endpoint를 제공합니다. red button은 진행 중인 agentic action을 멈추고, 새 action을 막고, 전체 fleet의 L3 권한을 회수하는 긴급 제동 장치입니다. 모델이 좋아지더라도 production mutation 권한은 deterministic, human-controlled safety boundary 안에 남긴다는 설계입니다. 운영 자동화 논의에서 자주 빠지는 부분이 바로 이 제동 장치입니다.
Google의 autonomy model은 monitoring, investigation, approval, actuation, self-directed operation을 나눕니다. L0는 사람이 모두 수행합니다. L1은 monitoring과 investigation을 자동화하지만 승인과 실행은 사람이 합니다. L2는 system이 조치를 stage하거나 실행할 수 있으나 human approval이 필요합니다. L3는 정해진 scenario에서 monitoring, investigation, approval, actuation을 자동화하고, novel multi-step resolution은 사람이 맡습니다. L4는 진단, 완화, 해결까지 sequence를 직접 만들고 결과를 보며 전략을 바꿉니다.
| 레벨 | 승인 | 실행 | Google 문서의 경계 |
|---|---|---|---|
| L1 Assisted | 사람 | 사람 | AI는 alert 조사와 hypothesis 제시에 머뭅니다. |
| L2 Partial | 사람 | 시스템 가능 | plan과 dry-run 이후 명시적 승인을 받습니다. |
| L3 High | 시스템 | 시스템 | well-defined scenario와 안전 검증을 통과한 minor incident에 한정됩니다. |
| L4 Full | 시스템 | 시스템 | multi-step incident lifecycle을 끝까지 관리하는 목표 상태입니다. |
평가 데이터도 별도 축입니다. Google은 incident 당시 사람 responder가 남긴 chat, note, command line entry를 구조화해 human trajectory로 재구성한다고 설명합니다. IRM-Analyzer는 key event, action, tool, hypothesis를 시간순으로 정리하고, 이 trajectory가 agent 학습과 reinforcement loop의 재료가 됩니다. 데이터 품질은 Bronze, Silver, Gold로 나뉩니다. Bronze는 heuristic autolabeler가 만들고, Silver는 Gold 데이터로 calibration된 programmatic data이며, Gold는 human expert가 검증합니다.
Nightly Eval은 이 데이터를 계속 돌립니다. Google은 Everest evaluation platform에 자동 nightly evaluation을 연결하고, 최근 real-world Google incident의 rolling dataset으로 agent response를 시험한다고 적습니다. 평가 방식은 LLM-as-a-Judge와 deterministic scoring의 혼합입니다. LLM rater는 중간 reasoning, investigation trajectory, tool call의 질을 보지만, 최종 mitigation output은 rigid precision과 recall로 봅니다. 예를 들어 "rollback" 같은 모호한 제안은 정답이 아닙니다. 정확한 binary와 version parameter가 golden data와 맞아야 합니다.
Detectr는 운영 에이전트가 metric, log, trace 밖의 signal을 어떻게 쓰는지 보여줍니다. Google은 기존 telemetry가 known failure mode에는 강하지만, user intent나 실제 고객 경험을 놓칠 수 있다고 설명합니다. Detectr는 social media, customer support, product forum 같은 비정형 사용자 feedback을 모아 filtering, clustering, de-noising, report generation 단계를 거쳐 outage notification을 만듭니다. Google은 Detectr가 Cloud, Ads, YouTube, Search 팀에서 채택됐고, 조기 탐지로 고객 영향 시간을 누적 수백 시간 줄였다고 적었습니다.
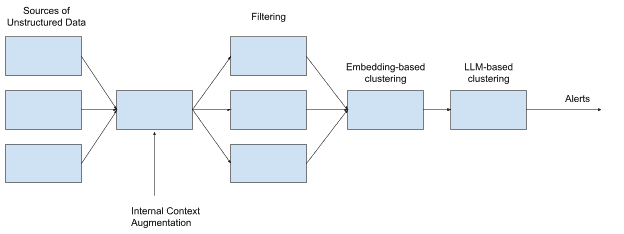
AI Alert는 더 짧은 시간 예산을 둡니다. Google은 alert가 human에게 도달하기 전 약 2분 안에 monitoring, logging, production change log, dependency graph를 대량 병렬 조회한다고 설명합니다. 이후 관련 anomaly, 최근 rollout, configuration change, similar past incident, potential root cause를 묶어 incident management tool에 붙입니다. 여기서 AI Alert는 read-only mode입니다. Google은 speculative conclusion보다 source data link가 붙은 verifiable fact와 evidence-based insight에 초점을 둔다고 적었습니다.
Incident Hypothesis는 L1 자동화의 성과 수치가 제시된 부분입니다. Google은 declared incident에서 real-time monitoring anomaly, service playbook, application log, incident management data를 RAG와 LLM으로 종합합니다. 여기에 similar past incident pattern을 더해 credible lead와 verification step을 oncaller에게 제공합니다. Google은 자체 A/B test로 이 informational assistance만으로도 MTTM을 10% 줄였다고 설명합니다. 수치가 크지 않아 보일 수 있지만, read-only와 human-driven mitigation 단계에서 얻은 감소라는 점이 운영 조직에는 더 중요합니다.
Investigation Dashboard는 더 큰 수치를 냅니다. Google은 static dashboard를 뒤지는 작업을 줄이기 위해 incident-specific single pane of glass를 자동 생성한다고 설명합니다. 분석 능력은 anomaly detection, alert signal과 change correlation, investigation worthiness, root cause identification으로 계층화됩니다. 문서에 따르면 ML-based anomaly detection만으로 overall findings가 195% 늘었고, 지원 incident에서 MTTM은 약 44% 감소했습니다. 이 수치는 AI가 조치를 직접 실행하기 전에도 데이터 수집과 상관관계 분석을 기계화하는 편익이 크다는 점을 보여줍니다.
Antigravity CLI 부분은 개발자 도구 독자가 바로 볼 지점입니다. Google SRE는 운영 UI가 있어도 production 관리는 주로 CLI에서 이뤄진다고 적고, Antigravity CLI가 Production Agent라는 표준 agent interface와 연결된다고 설명합니다. Gemini는 Production Agent MCP 서버를 통해 issue tracker에 action item을 bug로 만들고, owner를 지정하고, postmortem을 Google Docs로 내보낼 수 있습니다. 같은 interface는 real-time monitoring query, log analysis, incident detail fetch, dependency inspection, policy-compliant traffic drain initiation도 노출합니다.
MCP와 A2A가 여기서 등장하는 방식은 흥미롭습니다. 문서는 MCP를 AI-friendly tool interface로 설명하고, production environment에 대한 observability, incident management, traffic control, infrastructure tool을 자연어 interface로 노출한다고 말합니다. 하지만 production state를 바꿀 수 있는 tool은 Mitigation Safety Verification Agent와 통합돼 policy compliance를 확인합니다. A2A는 monitoring, rollout, capacity 같은 domain agent가 composite AI-Ops system을 만들도록 하는 inter-agent communication protocol로 언급됩니다.
이 설계가 일반 기업에 주는 교훈은 "운영 에이전트를 도입하라"가 아닙니다. Google의 전제는 엄청난 incident history, service topology, SLO, error budget, production tool catalog, internal RAG platform, fine-tuned model, nightly evaluation, Spanner trace store입니다. 이 기반 없이 L3 autonomy 문장만 가져오면 위험합니다. 작은 팀은 먼저 read-only alert enrichment, dry-run 가능한 runbook, human-approved plan, agent identity 분리, rate limit, 모든 tool call log 같은 좁은 요구사항부터 가져오는 편이 현실적입니다.
코딩 에이전트와의 연결은 문서 후반에 더 분명해집니다. Google은 4배에서 10배 코드 볼륨이 되면 line-by-line code review가 reviewer fatigue와 rubber-stamping으로 이어진다고 적습니다. 사람은 design, intent, policy를 검토하는 쪽으로 올라가야 하고, 코드 생성 agent와 test case 또는 review agent는 independent harness로 분리해야 한다고 설명합니다. 같은 agent가 코드를 만들고 테스트도 정의하면 bias가 전달돼 요구사항 누락을 놓칠 수 있다는 판단입니다.
배포 전략도 바뀝니다. 변경이 빠르게 누적되면 전통적 rollback은 간단하지 않습니다. Google은 이를 Intervening Pull Request Problem으로 부릅니다. 마지막으로 좋았던 version으로 되돌리면 그 사이 들어간 bug fix나 security patch까지 빼버릴 수 있습니다. 그래서 dynamic configuration, feature flag, continuous production validation, AI-assisted fix-forward가 더 중요해집니다. AI가 코드를 빠르게 만들었다면, 장애 해결도 더 작은 patch를 빠르게 만들어 적용하는 구조가 필요하다는 논리입니다.
GeekNews는 6월 2일 이 글을 SRE에서의 AI: Google은 어떻게 신뢰성 있는 운영의 미래를 설계하는가로 소개하며, AI 코딩 어시스턴트가 코드 생성과 배포 속도를 높인 뒤 사람이 일일이 검토하는 SRE 관행은 확장 불가능하다는 점을 요약했습니다. 같은 시각 Hacker News 첫 화면에는 AI agent guideline, OpenAI on AWS, NVIDIA RTX Spark, Alphabet AI 인프라 투자 같은 항목이 함께 보였습니다. 운영 에이전트 논의는 아직 모델 발표보다 덜 시끄럽지만, 실제 비용은 incident review, rollout guardrail, agent permission model에서 먼저 나타납니다.
Google SRE 글의 가장 실무적인 문장은 "AI Operator가 생산 장애를 고친다"보다 "AI Operator는 직접 raw script를 실행하지 않는다"에 가깝습니다. 운영 자동화의 품질은 모델 이름보다 agent principal, dry_run, evidence link, deterministic score, Actuation Agent, autonomy downgrade, red button으로 결정됩니다. 코딩 에이전트가 pull request를 더 많이 만들수록, SRE와 platform 팀은 이 실행 통제를 제품 요구사항으로 써야 합니다. Google 문서는 그 요구사항을 Google 규모의 사례로 먼저 적어둔 셈입니다.