Mellum2 공개, JetBrains가 낮춘 코딩 에이전트 호출 비용
JetBrains Mellum2는 12B MoE지만 토큰마다 2.5B만 활성화합니다. IDE 회사가 연 사설 코딩 모델 선택지를 봅니다.

- 무슨 일: JetBrains가 Mellum2를 Apache 2.0 open-weight 모델로 공개했습니다.
- 2026년 6월 1일 발표 기준
12Btotal parameters,2.5Bactive parameters per token의 MoE 구조입니다.
- 2026년 6월 1일 발표 기준
- 모델 위치: 단일 챗봇보다 routing, RAG 요약, validation, sub-agent 같은 반복 호출 단계가 표적입니다.
- arXiv report는
10.6Ttokens pre-training,128Kcontext extension, SFT와 RLVR post-training을 적었습니다.
- arXiv report는
- 개발자 영향: 사내 코드와 IDE context를 외부 API로 보내기 어려운 팀에 self-hosted coding model 후보가 늘었습니다.
- 주의점: 벤치마크는 JetBrains self-reported 값입니다. 실제 채택은 serving 비용, tool-call 정확도, 로컬 지원으로 다시 재야 합니다.
JetBrains가 2026년 6월 1일 Mellum2를 공개했습니다. Hugging Face에도 같은 날 공식 소개 글이 올라왔고, technical report는 2026년 5월 29일 arXiv v1으로 제출됐습니다. 공개된 숫자는 12B total parameters, 2.5B active parameters per token, Apache 2.0 license입니다. JetBrains는 이 모델을 거대 범용 챗봇으로 포장하지 않고, 소프트웨어 엔지니어링 시스템 안에서 routing, summarization, validation, sub-agent처럼 자주 반복되는 단계에 쓰는 모델로 설명합니다.
이 발표가 코딩 에이전트 뉴스인 이유는 JetBrains의 위치 때문입니다. IntelliJ IDEA, PyCharm, WebStorm, Android Studio 계열은 개발자가 코드를 열고, 검색하고, refactor하고, 테스트 실패를 확인하는 장소입니다. 최근 코딩 에이전트 경쟁은 IDE 밖의 원격 실행 환경과 GitHub issue 기반 agent workflow로 확장됐지만, JetBrains는 모델 자체를 공개하면서 IDE 안쪽의 latency와 데이터 경계를 다시 꺼냈습니다. 사내 코드가 외부 API로 나가기 어려운 팀이라면 Mellum2는 "더 똑똑한 frontier model"보다 "반복 호출을 내부에서 처리할 수 있는 작은 활성 계산량"으로 먼저 읽힙니다.
Mellum2의 첫 번째 수치는 MoE 구조입니다. 모델 전체는 12B이지만 토큰마다 활성화되는 parameter는 2.5B입니다. Hugging Face 소개 글은 이를 high-throughput, low-latency inference를 위한 구조로 설명하고, JetBrains AI Blog는 similar-sized models와 경쟁하면서 inference time을 절반 이하로 줄인다고 적었습니다. 이 문장은 독립 측정이 아니라 JetBrains의 주장입니다. 그래도 AI 제품 팀이 실제로 확인할 질문은 분명합니다. every-turn routing, retrieval post-processing, code diff validation에 frontier API를 계속 부를 것인지, 아니면 일부 단계를 self-hosted focal model로 빼낼 것인지입니다.
Technical report의 abstract는 아키텍처를 더 촘촘히 적습니다. Mellum2는 64 experts 중 8 experts를 활성화하고, Grouped-Query Attention에서 KV heads 4개를 사용하며, 4개 layer 중 3개에 Sliding Window Attention을 넣습니다. 단일 Multi-Token Prediction head는 auxiliary pre-training objective이면서 speculative decoding용 draft model 역할도 합니다. JetBrains는 이런 선택을 commodity GPU inference efficiency 제약 아래 ablation으로 검증했다고 설명합니다. 개발자가 이 문장을 실무 언어로 바꾸면, 모델 품질보다 serving 속도와 비용을 먼저 설계 변수에 넣었다는 뜻입니다.
학습 규모도 공개됐습니다. arXiv abstract는 약 10.6T tokens pre-training을 언급하고, three-phase curriculum이 diverse web data에서 curated code와 mathematical content 쪽으로 이동한다고 설명합니다. Optimizer는 Muon, precision은 FP8 hybrid precision, schedule은 Warmup-Hold-Decay와 linear decay to zero입니다. Base model은 layer-selective YaRN으로 128K context window까지 확장된 뒤, supervised fine-tuning과 reinforcement learning with verifiable rewards를 거칩니다. 공개 변형은 직접 답하는 Instruct와 reasoning trace를 내는 Thinking입니다.
| 항목 | Mellum2 공개 수치 | 개발팀 검증 질문 |
|---|---|---|
| 계산량 | 12B total, 2.5B active per token | router, validator, summarizer 호출 비용을 줄이는가 |
| 문맥 길이 | 131,072 token context | repository slice와 retrieval 결과를 함께 넣어도 안정적인가 |
| 실행 경로 | vLLM, SGLang, Docker Model Runner 예시 | 현재 GPU, quantization, OpenAI-compatible gateway에 맞는가 |
| 라이선스 | Apache 2.0 | 상업 배포, 사내 fine-tune, artifact 관리가 가능한가 |
Hugging Face model card는 Thinking checkpoint의 세부 수치를 따로 제공합니다. Number of layers는 28, hidden size는 2304, intermediate size는 7168, MoE intermediate size는 896입니다. Vocabulary size는 98,304이고 tensor type은 BF16입니다. 모델 카드는 vLLM 실행 예시에서 --reasoning-parser qwen3를 붙이고, tool calling을 켤 때 --enable-auto-tool-choice와 --tool-call-parser hermes를 사용합니다. SGLang 예시와 Docker Model Runner 예시도 같이 있습니다. 이것은 "모델 파일이 있다"에서 한 걸음 더 나아가, coding agent runtime에 붙일 수 있는 운영 힌트를 제공한다는 의미입니다.
다만 모델 카드 하단에는 기사 작성 시점 기준 "This model isn't deployed by any Inference Provider"라고 표시됩니다. 곧바로 managed endpoint에서 클릭해 쓰는 방식이 아니라, weights를 내려받아 serving stack을 준비해야 하는 모델입니다. 이 제약은 Mellum2의 성격과도 맞습니다. JetBrains가 말하는 private deployment와 self-hosted software engineering workflow는 API key 하나로 끝나는 제품이 아닙니다. GPU capacity, model cache, request routing, logging, eval harness, fallback model을 함께 설계해야 합니다.
Mellum2가 겨냥하는 작업은 code generation만이 아닙니다. Hugging Face 소개 글은 routing and orchestration, RAG pipelines, sub-agents, private deployment를 key use cases로 나눕니다. Routing에서는 prompt classification, tool selection, intermediate control-flow step을 예로 들고, RAG에서는 context compression, summarization, retrieval post-processing을 듭니다. Sub-agent에서는 planning, validation, transformation, context preparation을 언급합니다. 코딩 에이전트가 하나의 거대 모델 호출로 끝나지 않고 여러 작은 판단을 이어 붙이는 제품으로 바뀌면서, 이런 중간 모델의 비용이 눈에 보이기 시작했습니다.
이 점에서 Mellum2는 "작은 모델도 충분히 똑똑하다"는 일반론보다 더 좁은 주장을 합니다. 발표문은 multimodal을 버리고 text와 code에 집중했다고 적습니다. 비전, 음성, 이미지 생성이 빠진 대신 software engineering 환경의 자연어와 코드 데이터에 맞췄다는 설명입니다. JetBrains에게 이 선택은 낯설지 않습니다. IDE는 파일 트리, symbol, type, call hierarchy, diff, test output처럼 이미 구조화된 context를 갖고 있습니다. 모델이 모든 것을 세상 지식으로 해결하기보다, IDE가 가진 context를 읽고 작은 결정을 빠르게 내리는 쪽이 제품 경험에 맞습니다.
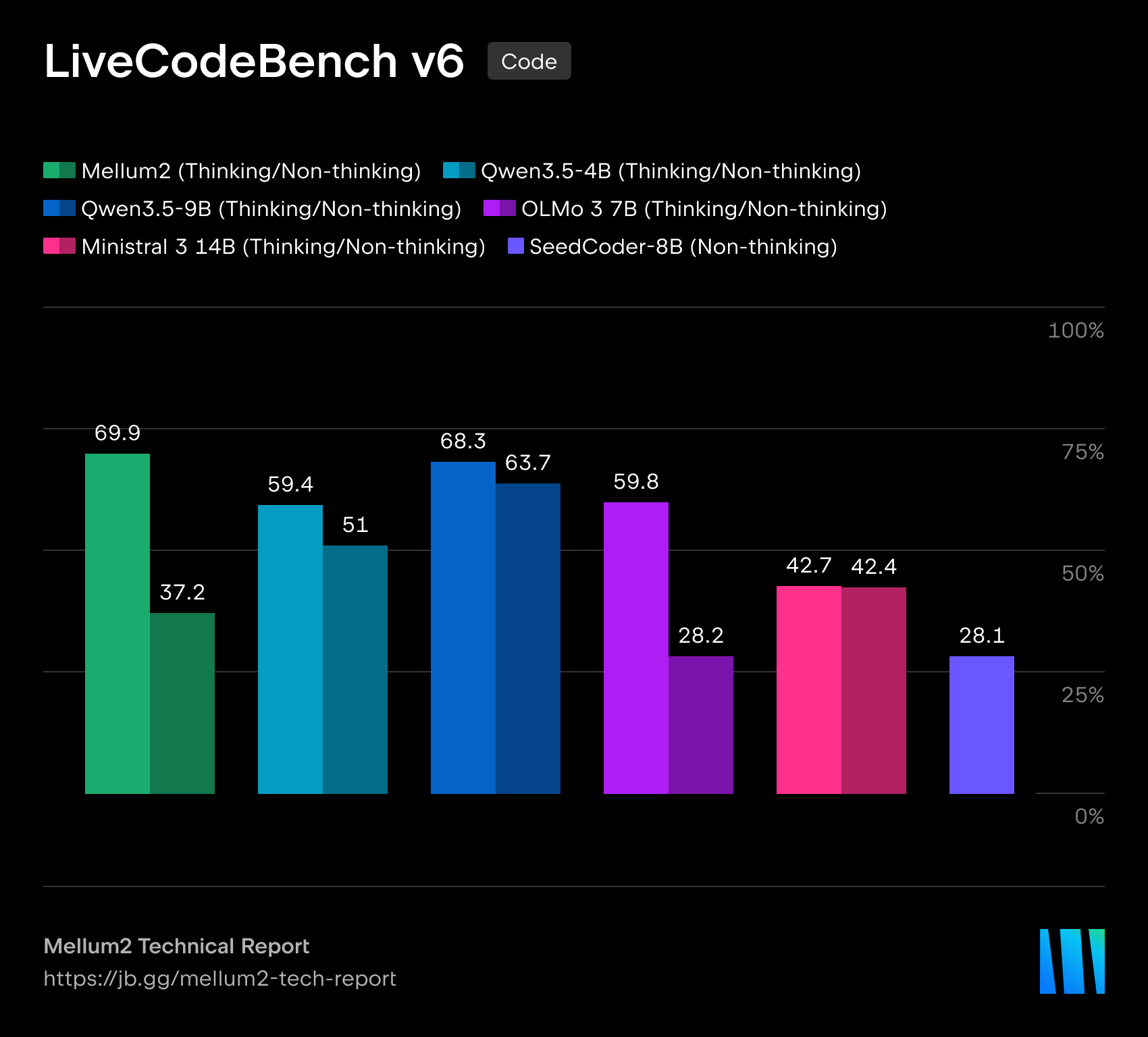
성능 수치는 조심해서 읽어야 합니다. Hugging Face model card의 evaluation section은 "All values self-reported by JetBrains"라고 못박습니다. Thinking RL variant는 LiveCodeBench v6에서 69.9를 받았고, Thinking SFT는 75.1을 받았습니다. BFCL v4는 Thinking RL 45.6, BFCL v3는 69.4입니다. AIME는 58.4, GSM-Plus는 87.0, MMLU-Redux는 86.2로 표시됩니다. 같은 표에서 Qwen3.5 9B는 AIME 73.4, GPQA Diamond 81.3, IFEval 89.8로 더 높은 항목도 있습니다. Mellum2를 모든 지표의 승자로 읽기보다, coding과 tool-use 주변의 효율 모델 후보로 읽어야 합니다.
Reddit r/LocalLLaMA 반응도 이 유보를 보여줍니다. 한 글은 "Coding focused small MoE"라고 요약하며 Qwen 계열과 비교했고, 댓글에서는 llama.cpp 지원 여부가 바로 나왔습니다. 다른 글에서는 128K context, 12B-A2.5B 크기를 두고 16GB급 laptop에서 돌릴 수 있을지 묻는 반응이 있었습니다. JetBrains IDE telemetry가 차별화된 code-aware data가 될 수 있다는 기대도 있었지만, Qwen3.5나 Gemma 계열과 비교해야 한다는 의견도 같이 올라왔습니다. 초기 커뮤니티 반응은 "쓸 만한 사내 보조 모델 후보"와 "벤치마크만으로는 부족하다" 사이에 놓여 있습니다.
JetBrains가 모델을 여는 방식은 OpenAI, Anthropic, Google의 coding agent 전략과 다릅니다. Codex, Claude Code, Gemini 계열은 강한 managed model과 agent surface를 앞세웁니다. 사용자는 제품 안에서 issue, branch, terminal, browser, PR을 맡기고, provider는 모델 업데이트와 compute를 가져갑니다. Mellum2는 그 반대쪽 질문을 던집니다. model weights와 Apache 2.0 license, vLLM/SGLang 예시가 있다면, 기업이 자기 네트워크 안에서 일부 agent step을 직접 운영할 수 있는가입니다. 이 질문은 보안팀과 플랫폼팀이 함께 답해야 합니다.
사내 코드 보안에서는 이 선택지가 작지 않습니다. 코딩 에이전트가 repository context, secret-adjacent config, incident log, proprietary API schema를 읽는 순간 데이터 경로가 procurement 문서에 들어갑니다. API-only 모델은 data retention policy와 enterprise agreement로 통제합니다. Open-weight self-hosting은 외부 전송을 줄일 수 있지만, model artifact와 inference server를 내부 책임으로 가져옵니다. Mellum2의 Apache 2.0 표기는 상업 활용 장벽을 낮추지만, 실제 배포에서는 weights provenance, acceptable use, export control, access logging, prompt storage policy를 따로 검토해야 합니다.
개발자 경험에서 바뀌는 지점은 버튼이나 UI보다 호출 구조입니다. 예를 들어 agent가 큰 작업을 받으면, 먼저 작은 모델이 요청을 분류하고, repository에서 필요한 파일 후보를 고르고, retrieval 결과를 압축하고, frontier model 호출 전 plan을 정리할 수 있습니다. 실행 뒤에는 diff가 task 범위를 벗어났는지, test failure log가 어느 파일과 관련되는지, PR description이 실제 변경과 맞는지 다시 확인할 수 있습니다. 이런 단계는 정답 하나를 창의적으로 쓰는 작업보다 latency와 cost가 더 민감합니다. Mellum2의 2.5B active parameter 설계는 이 구간을 노립니다.
그렇다고 Mellum2가 바로 Claude Code나 Codex를 대체한다고 쓰면 과장입니다. JetBrains 발표문도 "single frontier model"을 대체한다고 말하지 않습니다. Hugging Face 글은 larger AI systems 안의 fast, well-scoped model이라는 표현을 씁니다. 실제 agent product에서는 Mellum2가 router 또는 validator로 들어가고, 어려운 reasoning이나 code synthesis는 더 큰 model이 맡는 구조가 자연스럽습니다. 이 구성이 성공하려면 model router가 틀렸을 때 fallback이 있어야 하고, validator가 false positive를 너무 많이 내지 않아야 하며, cost saving이 orchestration complexity를 넘어서야 합니다.
팀이 Mellum2를 검토한다면 첫 실험은 benchmark 재현보다 trace replay가 낫습니다. 지난 한 달의 coding agent session에서 prompt classification, tool selection, retrieval compression, diff review, test failure summary 같은 작은 단계만 뽑아 Mellum2와 기존 모델에 동시에 보냅니다. 그 뒤 latency, token throughput, schema error, hallucinated file path, missed test failure, false rejection을 나눠 기록합니다. 모델 카드의 LiveCodeBench 점수는 출발점이고, 사내 agent에서는 "파일을 잘못 읽었는가"와 "PR diff 설명이 틀렸는가"가 더 직접적인 비용입니다.
Serving 실험도 별도입니다. vLLM과 SGLang 예시가 있어도, 128K context를 실제로 열면 memory pressure와 throughput이 달라집니다. Sliding window 1,024와 full attention layer 조합이 긴 repository context에서 어떤 지연을 만드는지 확인해야 합니다. Thinking model은 <think> block을 낼 수 있으므로, 제품 로그와 UI에서 reasoning trace를 저장할지, 숨길지, final answer만 쓸지도 정해야 합니다. tool calling parser와 OpenAI-compatible API gateway를 붙이면 function argument 안정성도 별도 지표가 됩니다.
Mellum2 발표는 JetBrains가 AI 코딩 시장을 IDE plugin 기능으로만 보지 않는다는 신호입니다. 모델을 열고, technical report를 붙이고, Hugging Face collection에 여러 checkpoint를 올렸습니다. 이 조합은 JetBrains AI Assistant를 위한 내부 모델 공개를 넘어, third-party AI workflow 안에서 JetBrains 모델을 작은 실행 부품으로 쓰게 하려는 시도입니다. 코딩 에이전트 시장에서 모델 이름보다 권한, 실행 위치, trace 검증, 비용 단위가 더 자주 논의되는 상황과 맞물립니다.
한국 개발팀이 볼 지점은 두 가지입니다. 첫째, Mellum2는 한국어 특화 모델로 발표되지 않았습니다. Model card는 English tag를 달고 있고, 공개 evaluation도 code, math, reasoning, tool use 중심입니다. 한국어 요구사항 문서, 고객 문의, 사내 위키를 붙일 팀은 자체 eval set을 만들어야 합니다. 둘째, JetBrains IDE 생태계를 쓰는 팀이라면 model quality보다 IDE context 연결이 더 큰 변수가 됩니다. symbol graph, inspection result, test runner, debugger output이 모델 호출에 어떻게 들어가는지에 따라 2.5B active model의 체감 품질이 달라질 수 있습니다.
이번 공개의 실무 결론은 좁습니다. Mellum2는 frontier coding agent 경쟁을 끝내는 모델이 아닙니다. 대신 코딩 에이전트가 여러 모델 호출과 도구 호출로 쪼개질 때, 반복 단계의 비용과 데이터 경계를 낮출 수 있는 open-weight 후보입니다. Apache 2.0, 12B-A2.5B, 128K context, vLLM/SGLang 예시는 이 후보를 실험 가능한 상태로 만듭니다. 다음 판단은 JetBrains 그래프보다 각 팀의 trace replay, GPU 사용률, tool-call 오류율, 보안 심사 결과에서 나와야 합니다.