Lyft AI Assist 6개월에서 2주, 고객지원 에이전트 셀프서브 실험
Lyft가 LangGraph와 LangSmith로 고객지원 에이전트 개발 기간을 약 6개월에서 2주로 줄인 운영 구조를 공개했습니다.

- 무슨 일: Lyft가
LangGraph와LangSmith기반 고객지원 agent platform 사례를 공개했습니다.- 새 configurable agent 개발 기간은 첫 driver agent 기준 약 6개월에서 약 2주로 줄었다고 설명합니다.
- 구조: meta agent가 rider/driver 요청을 분류하고, specialist subagent로 routing합니다.
- 운영: production agents 100%에 LLM-as-a-judge 평가가 붙고, error rate 5%와 p95 10초가 alert 기준입니다.
- 주의점: 셀프서브의 병목은 UI가 아니라 prompt 품질, eval 신뢰도, trace와 rollout discipline입니다.
LangChain은 2026년 5월 27일 Lyft SCX Data Science and MLE 팀의 guest post를 공개했습니다. 글의 주제는 LangGraph와 LangSmith로 만든 고객지원용 multi-agent platform입니다. Lyft는 이 platform으로 새 configurable agent 개발 기간을 첫 driver agent 기준 약 6개월에서 약 2주로 줄였고, 몇 개 self-serve agent 출시 뒤 AI Resolution Rate가 16% 올랐다고 밝혔습니다. 숫자만 보면 성공 사례처럼 보이지만, 개발팀이 봐야 할 부분은 "비개발자가 agent를 만든다"는 문장 뒤에 붙은 운영 장치입니다.
Lyft AI Assist는 rider와 driver의 account access, damage claims, charge reviews, earnings disputes 같은 고객지원 업무를 다룹니다. 공식 글은 이 시스템이 riders와 drivers의 수백만 interaction을 처리한다고 설명합니다. 2023년에 시작한 기존 방식은 domain expert가 workflow behavior를 정의하고, MLE와 engineering team이 tool configuration과 prompt로 옮기는 구조였습니다. 2026년에는 새 user segment, issue type, autonomous vehicle support 요구가 늘면서 이 loop가 병목이 됐습니다.
Lyft가 던진 질문은 모델 성능이 아니라 권한 배분입니다. 고객 문제를 가장 잘 아는 ops team, VoC lead, product manager가 agent를 직접 만들 수 있는가. 이 질문은 최근 agent platform 경쟁의 중요한 분기점입니다. OpenAI, Google, Anthropic, Microsoft, Salesforce, ServiceNow 모두 agent builder를 말합니다. 다만 enterprise support에서 agent를 production으로 보내려면 prompt editor보다 router, state, safety, trace, eval, rollout 기준이 먼저 필요합니다.
라우터가 먼저 있고, agent가 뒤에 붙습니다
Lyft architecture의 중심은 meta agent입니다. LangChain 글은 이 system이 LangGraph의 router multi-agent architecture를 따른다고 설명합니다. meta agent는 stateful router로 incoming request를 분류하고, Command(goto=...)를 사용해 적절한 specialized subagent로 dispatch합니다. 각 subagent는 자체 StateGraph이고, meta agent에는 subgraph node로 등록됩니다.
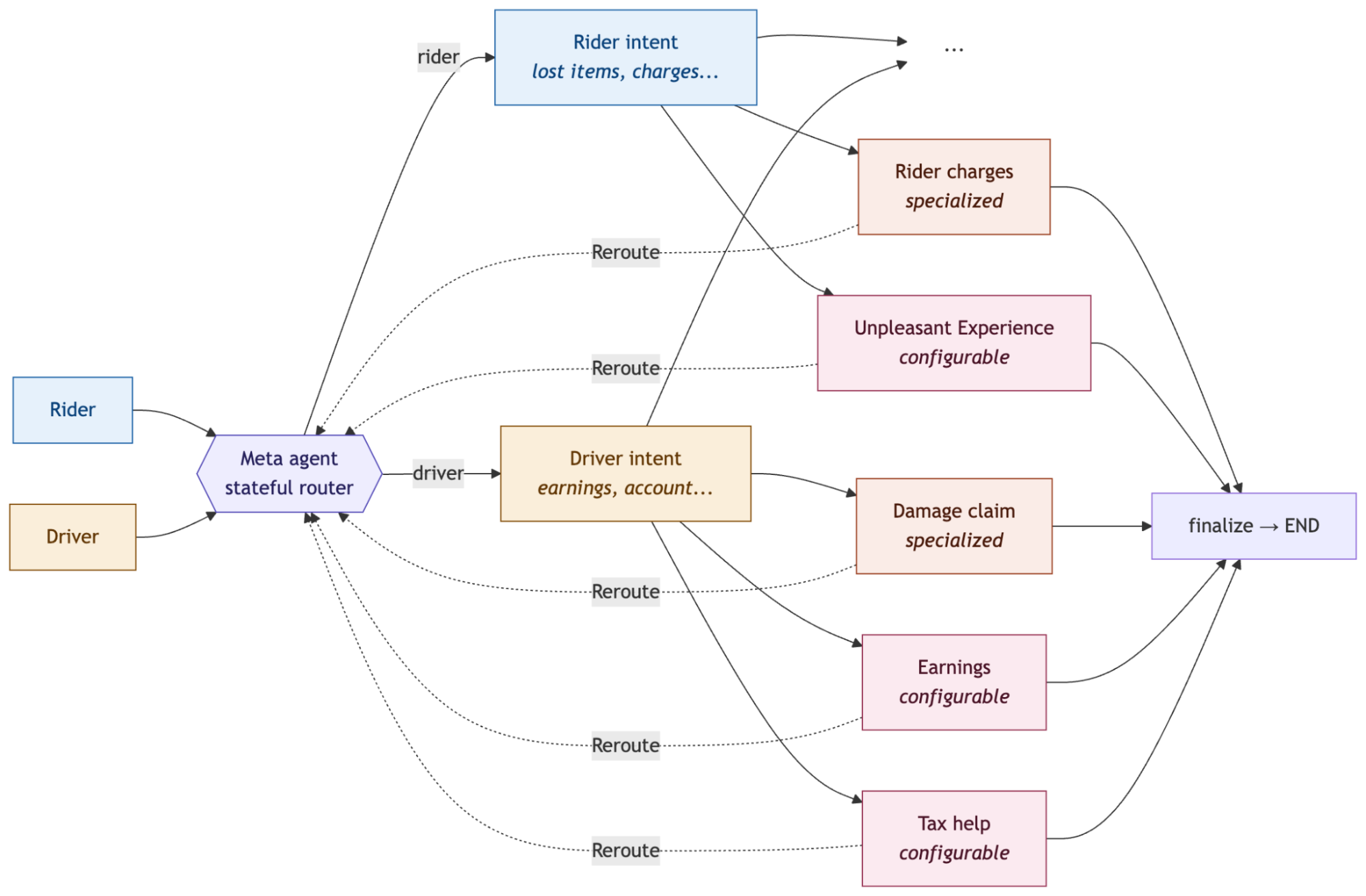
Lyft는 rider와 driver router instance를 따로 운영합니다. rider가 support에 연락하면 meta agent는 먼저 rider_intent subagent로 보내 lost items, charge disputes, trip issues 같은 rider-specific intent를 분류합니다. driver 요청은 driver_intent subagent가 earnings, account access, damage claims 같은 범주로 나눕니다. 대화 도중 더 specialized agent가 필요하면 intent agent는 Command(goto=..., graph=Command.PARENT)로 control을 parent meta agent에 돌려보냅니다. meta agent는 damage claim agent 같은 specialist로 다시 routing합니다.
이 구조가 중요한 이유는 self-serve agent를 "prompt 하나 추가"로 끝내지 않기 때문입니다. 새 agent는 meta graph에 subgraph로 등록되고, routing과 handoff 규칙 아래에서 실행됩니다. support agent가 실제 사용자와 대화할 때는 사용자가 topic을 바꾸거나, 해결 범위를 벗어나거나, high-stakes action으로 이어지는 순간이 자주 생깁니다. router가 없으면 agent는 자기 prompt 안에서 계속 improvisation을 하게 됩니다.
Lyft는 각 subagent가 consistent node pattern을 따르도록 만들었습니다. 공식 글에서 명시한 첫 번째 속성은 safety입니다. malicious intent detection과 safety issue detection이 매 turn마다 LangGraph의 Command(goto=[...]) fan-out으로 병렬 실행되고, 그 다음에 LLM reasoning으로 넘어갑니다. 두 번째 속성은 modularity입니다. 새 agent는 새 subgraph를 정의하고 meta agent에 등록하는 방식으로 추가됩니다.
셀프서브 agent는 JSON과 prompt로 로드됩니다
Lyft는 agent를 두 종류로 나눕니다. specialized agent는 MLE가 직접 만드는 고위험 workflow입니다. damage claim agent처럼 image processing, fraud detection, multi-step classification, automation call이 복잡한 영역은 low-code layer에 맡기지 않습니다. configurable agent는 self-serve layer입니다. JSON configuration은 internal config service에 저장되고, prompt는 LangSmith Prompt Hub에서 불러옵니다.
이 구분은 practical합니다. 모든 agent를 domain expert에게 맡기면 위험하고, 모든 agent를 MLE가 직접 만들면 속도가 나지 않습니다. Lyft의 선택은 agent surface를 위험도에 따라 나누는 것입니다. product manager가 driver tax question agent를 만들 때는 prompt와 JSON config를 작성하고, platform이 graph construction, tool binding, safety gates, state management를 처리합니다. 반대로 image fraud나 payment dispute처럼 tool chain과 policy risk가 큰 agent는 hand-built specialist로 남깁니다.
이 모델에서 prompt는 단순한 설명문이 아닙니다. Lyft는 나중에 "prompt quality가 infrastructure보다 더 큰 병목이었다"고 적었습니다. domain expert는 issue type을 깊게 이해하지만, LLM이 안정적으로 따를 instruction으로 바꾸는 일은 다릅니다. "empathetic하게 응답하라"는 문장은 support policy가 아닙니다. tool unavailable 상태, topic change, out-of-scope request, escalation condition, terminal action을 명시해야 production agent가 같은 방식으로 움직입니다.
state 저장 없이는 고객지원 agent가 아닙니다
Multi-turn support conversation은 stateless chat completion으로 처리하기 어렵습니다. 사용자는 이전 답변을 기준으로 반박하고, 추가 증거를 내고, 같은 conversation 안에서 다른 issue를 꺼냅니다. Lyft는 custom DynamoDBSaver를 만들어 LangGraph의 BaseCheckpointSaver interface를 구현했습니다. 각 checkpoint는 full graph state, execution metadata, parent checkpoint reference를 저장합니다.
이 설계는 debugging과 replay에 직접 연결됩니다. production에서 driver가 "이 답변이 이상했다"고 report하면, 팀은 해당 trace와 checkpoint를 따라 intent classification, tool execution, final LLM response 중 어느 단계가 문제였는지 볼 수 있습니다. LangChain 글은 실제로 confusing response가 보고되면 exact trace를 끌어와 node input/output, tool call, final response를 보고 몇 시간 안에 수정할 수 있었다고 설명합니다.
Agent platform 논의에서 state persistence는 종종 memory라는 단어로 뭉개집니다. Lyft 사례에서는 더 구체적입니다. memory는 사용자의 장기 선호만이 아니라 graph state, execution metadata, parent checkpoint, replay 가능한 conversation path입니다. 고객지원처럼 dispute와 policy가 얽힌 업무에서는 "무슨 말을 기억했는가"보다 "어느 node가 어떤 근거로 다음 node를 불렀는가"가 더 중요합니다.
LangSmith는 trace 저장소가 아니라 rollout gate입니다
Lyft는 development, staging, production 전 환경에서 LANGSMITH_TRACING=true로 agent invocation을 trace합니다. trace는 graph execution, LLM input, tool call, token usage, latency를 포함합니다. user type, agent name, intent, conversation ID 같은 custom metadata도 붙여 filtering과 debugging에 씁니다. 이 정도 instrumentation이 있어야 self-serve가 중앙팀의 blind delegation으로 변하지 않습니다.
평가 pipeline도 production rollout에 묶여 있습니다. Lyft는 agent가 100% traffic으로 가기 전에 5-10% small production rollout을 먼저 둡니다. 그 다음 real conversation trace를 evaluation dataset으로 sample하고, LangSmith Prompt Hub의 shared judge prompt template을 agent-specific metric으로 확장해 LLM-as-a-judge evaluator를 돌립니다. 모든 production agent에는 automated LLM-as-a-judge pipeline이 붙어 있다고 밝혔습니다.
Monitoring dashboard는 run volume, error rate, p50/p95 latency, token usage, tool call success rate, LLM-as-a-judge score를 봅니다. PagerDuty 기준도 숫자로 공개했습니다. error rate가 5%를 넘거나 p95 latency가 10초를 넘는 상태가 15분 지속되면 on-call engineer가 page를 받습니다. 이 수치는 agent 운영에서 유용한 reference point입니다. "agent가 잘 답했는가"만 보지 않고, real-time support product로서 latency와 tool health를 같은 dashboard에 놓습니다.
prompt는 제품 명세가 됩니다
Lyft가 공개한 가장 실무적인 교훈은 prompt discipline입니다. 팀은 처음에 가장 어려운 문제가 platform infrastructure일 것이라고 봤습니다. tool binding, graph edge case, state management가 난제라고 생각했습니다. 실제 병목은 prompt quality였습니다. domain expert가 issue type을 잘 알아도, happy path만 설명하고 topic change나 tool failure를 빠뜨리면 agent는 edge case에서 무너집니다.
Lyft는 structured prompt writing framework를 만들었습니다. required component는 identity, primary objective, scope, phased workflow, content guidelines입니다. 여기서 primary objective는 "help" 같은 추상 동사가 아니라 concrete verb를 요구합니다. scope는 in-scope와 out-of-scope를 모두 쓰고, out-of-scope일 때 routing action을 명시합니다.
phased workflow는 entry condition, branching, terminal action을 요구합니다. content guideline도 추상 원칙이 아니라 do/don't rule과 example phrase로 작성합니다. 공식 글의 checklist는 "does every phase have an exit?"처럼 prompt를 검토 가능한 product spec으로 다룹니다.
이 접근은 prompt를 code comment가 아니라 product spec으로 취급합니다. comment는 개발자가 읽고 지나갑니다. product spec은 input, boundary, failure mode, exit condition, acceptance criteria를 가집니다. Self-serve agent platform에서 prompt author가 PM이나 ops lead라면, prompt는 engineering artifact와 policy artifact 사이에 놓입니다. version control, review, lint, CI가 필요한 이유입니다.

Lyft는 Git-backed prompt linting pipeline도 만들고 있습니다. domain expert가 builder UI에서 prompt 작성을 끝내면 config repository에 pull request가 열립니다. CI는 두 계층으로 돌고, 빠른 static rule은 malformed template variable, duplicate intent slug, spelling error를 잡습니다. LLM-powered rule은 prompt injection vulnerability, contradictory instruction, structural dead-end를 찾습니다. violation은 merge를 막고, author는 UI에서 inline feedback을 받아 MLE 없이 수정합니다.
이 설계는 최근 coding agent workflow와 닮았습니다. Codex나 Copilot cloud agent가 PR을 만들고 CI가 검증하듯, customer support agent prompt도 PR과 CI를 통과합니다. 차이는 artifact가 code가 아니라 prompt/config라는 점입니다. Lyft 사례는 prompt governance가 법무 문서가 아니라 software delivery pipeline 안으로 들어오는 예입니다.
성과 숫자는 좋지만, 해석에는 조건이 붙습니다
Lyft가 공개한 결과는 강합니다. 새 configurable agent 개발 기간은 약 6개월에서 약 2주로 줄었습니다. production agents 100%가 automated LLM-as-a-judge pipeline을 가집니다. hallucination and contradiction rate는 LangSmith evaluation metric 기반 guardrail 설정 뒤 20% 감소했습니다. AI Resolution Rate는 self-serve platform으로 몇 개 agent를 출시한 뒤 16% 상승했습니다.
다만 이 숫자는 "agent builder만 사면 된다"는 결론으로 읽으면 안 됩니다. Lyft는 이미 MLE team, internal config service, DynamoDB checkpointing, PagerDuty 운영, LangSmith dashboard, evaluation dataset, prompt review process를 갖고 있습니다. Self-serve는 infrastructure를 없애는 것이 아니라, 반복 업무의 ownership을 domain expert 쪽으로 옮기고 MLE가 platform과 guardrail을 관리하도록 역할을 바꾸는 일입니다.
또 하나의 조건은 LLM-as-a-judge입니다. Lyft는 production trace를 sample해 evaluator를 돌리고, agent-specific metric을 추가합니다. 그러나 judge model도 model입니다. prompt injection, policy ambiguity, subtle customer harm, regional compliance 같은 문제를 전부 정확히 잡는다고 가정할 수 없습니다. Lyft가 pairwise evaluation과 human reviewer를 다음 단계로 둔 이유도 여기에 있습니다.
경쟁 기준은 모델보다 운영 primitive입니다
이 사례의 경쟁 상대는 단순히 LangGraph와 다른 framework가 아닙니다. Sierra Agent OS, Intercom Fin, Zendesk AI, Salesforce Agentforce처럼 고객지원 agent를 제품으로 파는 회사가 있고, OpenAI Agents SDK, Google ADK, CrewAI, AutoGen처럼 runtime과 framework를 제공하는 선택지도 있습니다. Observability 쪽에서는 LangSmith, Langfuse, Arize Phoenix, Honeycomb Agent Timeline, Datadog LLM Observability가 겹칩니다.
Lyft 사례는 open framework 기반으로 production customer support를 직접 짓는 쪽의 장단점을 보여줍니다. 2026년 5월 27일 공개된 이 architecture의 장점은 routing, checkpointing, prompt lifecycle, rollout metric을 업무에 맞게 설계할 수 있다는 점입니다.
단점은 platform team이 있어야 한다는 점입니다. Self-serve라고 해도 self-running은 아닙니다. Domain expert가 agent를 만들수록 central platform은 더 강한 lint, eval, trace, permission, rollback을 가져야 합니다.
최근 agent platform 경쟁에서 자주 빠지는 질문은 "누가 agent를 수정하는가"입니다. MLE만 수정한다면 안전하지만 느립니다. Ops가 바로 수정한다면 빠르지만 위험합니다. Lyft는 그 사이에 graph runtime, prompt template, config PR, eval CI, monitoring dashboard를 놓았습니다. LangChain 글의 숫자처럼 2주 배포를 목표로 한다면, 이 조합이 없을 때 self-serve는 demo로 끝나기 쉽습니다.
다음 단계는 simulation과 continuous scoring입니다.
Lyft가 밝힌 다음 작업은 prompt linting 완성, mocking and simulation infrastructure, pairwise evaluation입니다. Freenow Europe과 autonomous vehicle support 확장, 모든 production trace의 continuous scoring도 roadmap에 들어갑니다. 이 roadmap은 agent 운영이 어디로 가는지 보여줍니다.
실제 고객에게 5-10% traffic을 열기 전에 synthetic conversation과 mocked tool response로 실패를 재현합니다. prompt revision은 A/B test와 human reviewer로 비교합니다.
Simulation은 customer support agent에 특히 중요합니다. Refund, safety issue, account access, earnings dispute는 낮은 빈도의 edge case가 실제 위험을 만듭니다. Production trace sampling만으로는 rare failure를 충분히 보기 어렵습니다. Mocked tool response와 synthetic conversation을 조합하면 tool timeout, contradictory user input, policy boundary, abuse attempt를 사전에 넣을 수 있습니다.
Continuous scoring은 비용과 신뢰도 문제가 따라옵니다. 모든 production trace를 judge model로 평가하면 token cost가 늘고, judge drift가 생기며, false positive alert도 늘 수 있습니다. 그러나 sampled evaluation만으로는 agent degradation을 늦게 볼 수 있습니다. Lyft가 "automatic prompt degradation alert"를 다음 단계로 언급한 것은 agent가 release 후에도 계속 변하는 product라는 뜻입니다.
개발팀이 가져갈 체크포인트
Lyft 글에서 바로 가져갈 수 있는 첫 번째 체크포인트는 router입니다. 단일 all-purpose support agent보다 meta router와 specialist subagent를 나누면 intent change와 handoff를 명시할 수 있습니다. 두 번째는 checkpoint입니다. Multi-turn support에서는 conversation replay와 state inspection이 없으면 장애 분석이 불가능합니다. 세 번째는 prompt CI입니다. Prompt author가 늘어날수록 instruction 품질을 review checklist와 lint로 잡아야 합니다.
네 번째는 rollout입니다. Agent launch를 feature flag처럼 취급해야 합니다. 5-10% traffic, real trace sampling, evaluation dataset, judge metric, monitoring dashboard, alert threshold가 함께 있어야 합니다. 다섯 번째는 role design입니다. Domain expert가 prompt를 쓰고, platform team이 graph와 guardrail을 관리하고, on-call engineer가 latency와 error rate를 봅니다. 이 역할 구분이 없으면 "비개발자도 agent를 만든다"는 문장은 곧 "누가 책임지는지 모르는 agent"가 됩니다.
Lyft AI Assist 사례는 agent 시장의 과장된 문장보다 더 쓸모 있는 세부사항을 줍니다. Agent 개발 기간을 6개월에서 2주로 줄였다는 숫자는 headline입니다.
실제 lesson은 prompt가 제품 명세가 되고, trace가 운영 기록이 되며, eval이 release gate가 되는 구조입니다. 고객지원 agent를 production에 넣으려는 팀에게 이번 사례의 메시지는 명확합니다. Self-serve agent platform은 builder UI가 아니라 graph, state, safety, eval, CI, alert를 묶은 운영 시스템입니다.