LLM도 잠이 필요하다, 긴 문맥 병목을 우회한 빠른 가중치
Language Models Need Sleep 논문이 제안한 sleep-like fast weight consolidation과 장기 에이전트 메모리의 의미를 짚습니다.
- 무슨 일: CMU와 Maryland 연구진이 arXiv에 Language Models Need Sleep를 공개했습니다.
- 긴 문맥을 계속
KV cache에 두지 않고, eviction 직전 여러 번의 오프라인 pass로fast weight에 통합합니다.
- 긴 문맥을 계속
- 의미: 에이전트 메모리 문제가 prompt 요약이나 RAG만의 문제가 아니라 모델 실행 스케줄의 문제로 이동합니다.
- 숫자: Ouro 1.4B는 GSM-Infinite 6-operation 정확도가
0.419에서0.615로 올랐습니다.- 다만 recurrent sleep loop는 학습 비용을 거의 선형으로 늘리고, 논문 결과는 아직 통제된 benchmark 중심입니다.
2026년 5월 25일 arXiv에 올라온 Language Models Need Sleep는 제목만 보면 쉽게 과장된 AI 의인화처럼 보입니다. 하지만 논문이 실제로 다루는 문제는 훨씬 실무적입니다. 긴 문맥을 가진 LLM이 오래 일할수록 KV cache는 커지고, attention 비용은 문맥 길이에 따라 빠르게 불어납니다. 코딩 에이전트나 리서치 에이전트가 몇 시간씩 작업하는 시대에는 "모든 것을 active context에 계속 넣어둘 것인가"라는 질문이 곧 비용, 지연 시간, 추론 안정성의 질문이 됩니다.
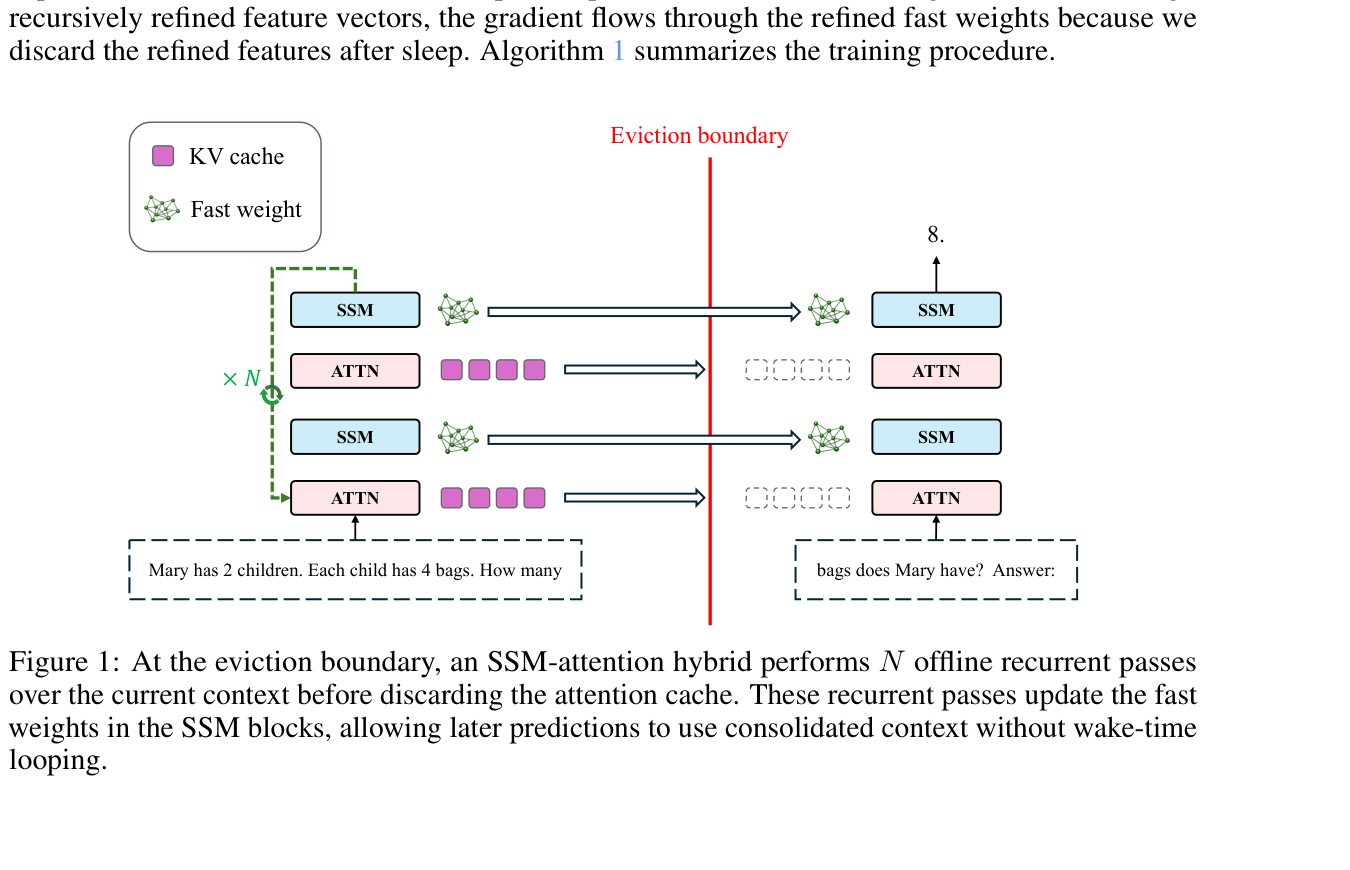
연구진의 제안은 모델이 정말로 잠을 잔다는 이야기가 아닙니다. context window가 가득 차서 과거 토큰을 버려야 하는 순간, 모델이 잠깐 외부 입력을 받지 않는 consolidation 단계를 수행한다는 뜻입니다. 이 단계에서 모델은 최근 문맥을 여러 번 다시 통과하며 SSM 계열 block의 fast weight를 업데이트합니다. 그다음 KV cache를 비우고, 이후 답변 단계에서는 단일 forward pass만 사용합니다. 즉 답변 시점의 latency를 늘리는 대신, 문맥을 버리기 전에 "기억으로 바꾸는 계산"을 미리 쓰자는 설계입니다.
이 논문이 흥미로운 이유는 단순히 long-context benchmark 하나를 더 제시해서가 아닙니다. 최근 에이전트 제품은 대개 context compaction, vector memory, summary memory, RAG를 조합해 장기 작업을 버팁니다. 이 방식은 애플리케이션 계층에서 메모리를 관리합니다. 반면 이 논문은 "문맥을 버리기 전 모델 내부 상태로 어떻게 통합할 것인가"를 architecture와 inference schedule의 문제로 다시 끌고 옵니다. AI 에이전트의 장기 기억이 제품 기능에서 모델 설계의 주제로 내려오는 장면입니다.
무엇을 "sleep"이라고 부르나
기본 Transformer는 과거 토큰의 key와 value를 cache에 저장하고, 새 토큰을 만들 때 attention으로 다시 조회합니다. 이 구조는 강력하지만 비용 구조가 불편합니다. 전체 attention compute는 문맥 길이에 대해 이차적으로 커지고, cache 메모리는 선형으로 증가합니다. 그래서 최근에는 attention block과 SSM 또는 linear recurrent layer를 섞은 hybrid model이 많이 연구됐습니다. attention은 가까운 문맥을 정밀하게 보고, SSM 계열 fast weight memory는 오래된 정보를 압축해 들고 가는 식입니다.
논문은 여기서 한 발 더 들어갑니다. fixed-size fast weight memory가 있다고 해서 깊은 추론까지 자동으로 해결되는 것은 아니라는 문제의식입니다. 과거 토큰을 어딘가에 저장하는 것과, 그 토큰들 사이의 관계를 나중에 한 번의 forward pass로 활용할 수 있게 정리하는 것은 다릅니다. 특히 cache가 비워진 뒤에는 모델이 원문을 다시 볼 수 없습니다. 그렇다면 eviction 전에 충분한 계산을 써서 과거 문맥을 유용한 내부 상태로 바꿔야 합니다.
이 과정을 논문은 sleep-like consolidation이라고 부릅니다. window 크기 L이 있고, 모델이 L개의 토큰을 처리한 뒤 cache를 버려야 한다고 해보겠습니다. 일반적인 hybrid model은 그 시점까지 SSM state를 업데이트한 뒤 바로 다음 window로 넘어갑니다. 논문의 방법은 cache를 버리기 전에 동일한 context chunk를 N번 반복해서 통과합니다. 반복 pass는 SSM block의 fast weight를 계속 다듬고, 이후 attention cache는 삭제됩니다. 답변을 생성하는 prediction phase에서는 별도의 loop나 chain-of-thought token을 허용하지 않습니다.
여기서 중요한 제약은 "깨어 있을 때는 빠르게 답해야 한다"는 점입니다. 많은 test-time compute 기법은 답변 시점에 더 오래 생각하게 만듭니다. 이 논문은 반대로 prediction time에 계산을 늘리지 않고, consolidation time에 계산을 옮깁니다. 장기 실행 에이전트 관점에서는 꽤 자연스럽습니다. 사용자가 질문을 던지는 순간마다 느려지는 대신, 작업 중간중간 문맥이 꽉 찼을 때 내부 기억을 정리하는 방식이기 때문입니다.
| 방식 | 기억을 두는 곳 | 비용이 드는 시점 | 실무적 의미 |
|---|---|---|---|
| 긴 KV cache | active attention context | 매 예측과 cache 유지 | 정확하지만 메모리와 latency가 커집니다. |
| 요약/RAG | 앱 계층의 summary 또는 외부 store | 검색, 재삽입, 요약 갱신 | 구현은 쉽지만 모델 내부 추론과 분리됩니다. |
| Sleep consolidation | SSM block의 fast weight | eviction 직전 offline loop | 답변 latency를 유지하며 과거 문맥을 내부 상태로 압축합니다. |
숫자가 보여준 것은 저장보다 정리의 문제
논문은 먼저 Rule 110 cellular automaton으로 문제를 단순화합니다. 모델은 여러 개의 이진 문자열을 읽고, 각 문자열을 t번 전개한 뒤 첫 비트를 예측해야 합니다. window가 24 token 단위로 hard eviction되기 때문에, prediction phase에서는 원래 문자열을 attention으로 다시 볼 수 없습니다. SSM-attention hybrid라면 정보 일부를 fast weight에 저장할 수 있지만, t가 커질수록 필요한 계산 깊이가 커집니다.
결과는 직관적입니다. vanilla GDN-attention hybrid model은 rollout step이 늘어날수록 빠르게 무너집니다. 반면 eviction 전에 2회, 3회, 4회 loop를 넣으면 t = 32 같은 어려운 설정에서 정확도가 올라갑니다. 논문은 no-loop 모델이 약 50억 training token 뒤에도 10% 근처에 머문 반면, 3회와 4회 loop는 30%를 넘었다고 보고합니다. 이 수치가 절대적으로 높다는 뜻은 아닙니다. 중요한 점은 context 길이와 prediction-time 계산을 고정한 상태에서 consolidation-time 계산만 늘려 차이가 났다는 점입니다.
Depo multi-hop retrieval에서도 비슷한 패턴이 나옵니다. Depo는 섞인 directed cycle을 읽고, 어떤 node에서 k hop 뒤에 도달하는 node를 답해야 하는 과제입니다. cycle 정보는 여러 window에 쪼개져 들어오고, query-answer phase에서는 이미 cache에서 사라져 있습니다. 1-hop 같은 쉬운 문제에서는 loop 차이가 작지만, 4-hop 이상에서는 offline loop가 learning speed를 끌어올립니다. 16-hop에서는 4-loop 모델만 의미 있는 개선을 시작합니다.
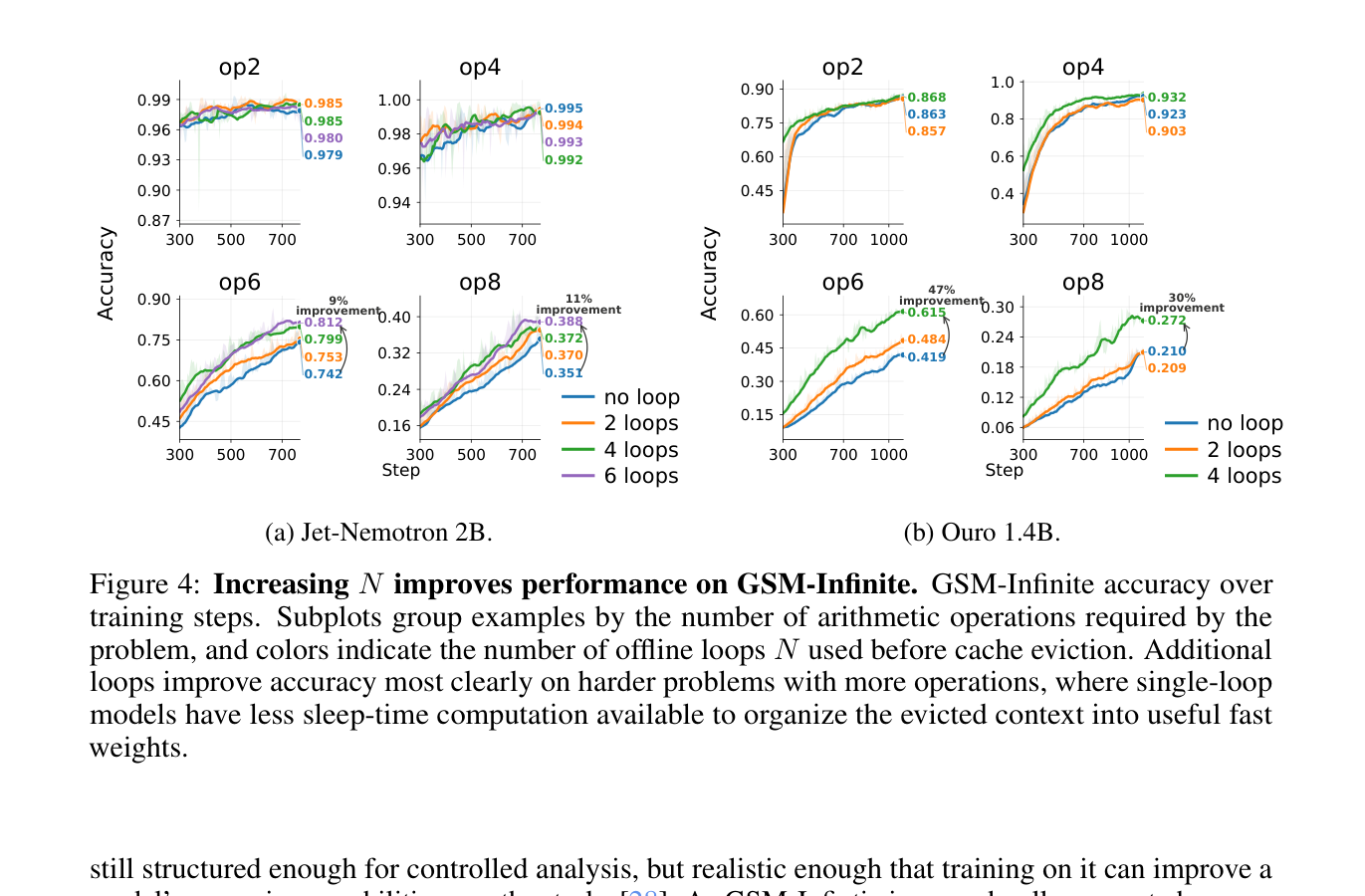
가장 눈에 띄는 부분은 GSM-Infinite 실험입니다. GSM-Infinite는 GSM8K류 수학 문제를 길게 늘리고 distractor token을 섞어, 긴 문맥 처리와 다단계 추론을 함께 요구합니다. 논문은 Jet-Nemotron 2B와 Ouro 1.4B를 사용했습니다. Jet-Nemotron 2B에서는 6-operation 문제 정확도가 0.742에서 0.812로, 8-operation 문제 정확도가 0.351에서 0.388로 올랐습니다. Ouro 1.4B에서는 차이가 더 컸습니다. 6-operation은 0.419에서 0.615, 8-operation은 0.210에서 0.272로 올라갔습니다.
이 결과는 "더 긴 context window를 주면 된다"는 단순한 답을 흔듭니다. 긴 context가 있어도 모델이 그 안에서 어떤 정보를 어떤 내부 상태로 바꿔야 하는지는 별개의 문제입니다. 특히 에이전트가 긴 로그, 도구 호출 결과, 파일 diff, 테스트 출력, 사용자 피드백을 계속 축적하는 상황에서는 오래된 정보가 그대로 남아 있는 것보다 어떤 형태로 재구성되는지가 더 중요해집니다. sleep-like loop는 그 재구성에 별도의 계산 예산을 배정합니다.
에이전트 메모리에 주는 신호
현재 코딩 에이전트의 장기 작업은 대부분 외부 메모리 전략에 의존합니다. 일정 길이를 넘으면 transcript를 요약하고, 파일 상태를 다시 읽고, vector store에서 관련 문서를 가져오고, 중요한 결정은 별도 memory file에 남깁니다. 이 방식은 당장 유용하지만, 모델 입장에서는 매번 외부에서 다시 주입되는 텍스트입니다. 요약이 잘못되면 모델은 잘못된 상태를 믿고, 검색이 빗나가면 필요한 근거가 active context에 들어오지 않습니다.
논문이 던지는 질문은 다릅니다. "문맥을 버리기 전에 모델 내부에서 정리할 수 있다면 무엇이 달라지는가"입니다. 예를 들어 장시간 실행되는 코드 에이전트가 수백 개 파일과 테스트 로그를 훑었다고 가정해보겠습니다. 오늘의 시스템은 중요한 정보를 요약문이나 scratchpad로 남깁니다. sleep-style 모델은 eviction boundary마다 그 경험을 fast weight state로 통합하고, 이후 prediction phase에서는 원본 로그를 다시 보지 않고도 관련 구조를 활용할 수 있습니다.
물론 이것은 아직 제품 기능이 아닙니다. 논문은 controlled synthetic task와 modest-scale pretrained model 중심입니다. 실제 대규모 frontier model에서 동일한 이득이 비용 대비 충분한지, safety policy와 personalization boundary를 어떻게 다룰지, 사용자별 fast weight state가 어떤 보안 모델을 가져야 하는지는 별개의 문제입니다. 특히 fast weight가 세션별로 계속 바뀐다면, jailbreak나 데이터 오염이 단순 prompt injection보다 더 오래 남을 가능성도 검토해야 합니다.
그래도 방향성은 중요합니다. 지금까지 long-context 경쟁은 대체로 "얼마나 많은 token을 한 번에 넣을 수 있는가"로 홍보됐습니다. 이 논문은 "얼마나 많은 token을 넣느냐"보다 "버릴 token을 어떤 계산으로 남길 것인가"를 묻습니다. 에이전트가 실제 일을 오래 할수록, 이 질문은 더 중요해집니다.
비용표는 아직 무겁다
sleep-like consolidation은 공짜가 아닙니다. 논문도 이 점을 명확히 인정합니다. recurrent depth N을 늘리면 학습 비용은 대략 선형으로 증가합니다. 또한 window j + 1을 처리하려면 window j의 sleep pass가 끝나고 fast weight가 업데이트되어야 하므로, sequence axis를 완전히 병렬화하기 어렵습니다. 긴 sequence를 병렬로 밀어 넣는 Transformer 학습의 장점 일부를 내려놓는 셈입니다.
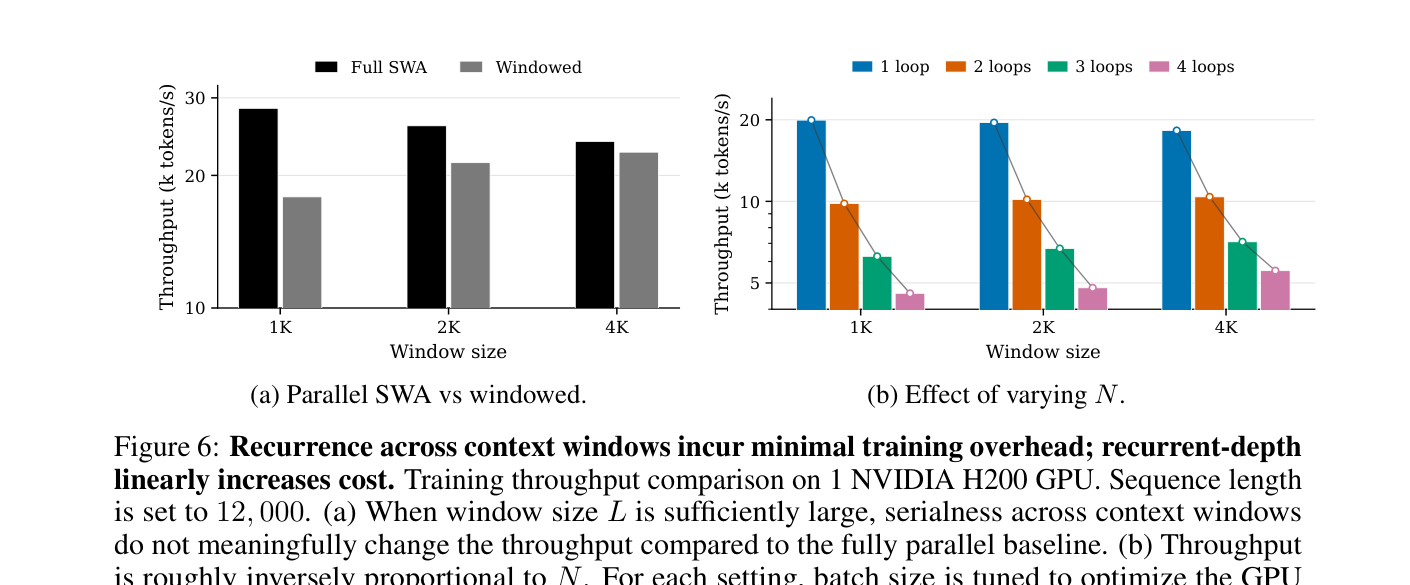
논문 Figure 6은 이 trade-off를 보여줍니다. window size가 충분히 크면 window 단위 sequential dependency 자체는 GPU 활용을 크게 해치지 않을 수 있지만, loop 수가 늘어나는 비용은 뚜렷합니다. 따라서 이 접근은 모든 요청에 무조건 적용할 기능이라기보다, 긴 문맥을 오래 유지해야 하고 eviction 이후의 추론이 중요한 workload에 맞는 선택지로 보는 편이 정확합니다.
이 지점에서 AI 인프라 관점의 질문이 생깁니다. 에이전트 runtime은 앞으로 "생성 token당 비용"뿐 아니라 "기억을 정리하는 background compute"까지 가격표에 넣어야 할 수 있습니다. 사용자가 기다리는 foreground latency는 낮추고, agent가 쉬는 사이에 memory consolidation을 수행하는 구조입니다. 이미 제품 계층에서는 background agent, scheduled compaction, memory indexing이 늘고 있습니다. 모델 계층에서도 비슷한 분리가 생길 수 있습니다.
커뮤니티의 비판, sleep이라는 이름의 위험
Hacker News 반응은 뜨거웠지만 일방적으로 긍정적이지 않았습니다. 많은 댓글은 이 연구를 long-context 비용 문제와 연결해 흥미롭게 봤습니다. 반대로 "sleep"이라는 이름이 너무 많은 생물학적 함의를 끌고 온다는 비판도 강했습니다. 실제로 논문이 하는 일은 동물이 잠을 자는 현상을 재현하는 것이 아닙니다. 외부 입력이 없는 구간에서 최근 context를 반복 처리하고, fast weight memory를 업데이트하는 engineering mechanism입니다.
이 비판은 중요합니다. AI 뉴스에서 "모델이 잠을 잔다"는 표현은 클릭을 만들기 쉽지만, 논점을 흐리기도 쉽습니다. 더 정확한 표현은 offline recurrent memory consolidation입니다. 다만 논문이 sleep 비유를 택한 이유도 이해할 수 있습니다. 짧은 기억을 더 안정적인 장기 표현으로 옮기고, 그동안 외부 입력을 받지 않으며, 이후 행동에서 그 이득을 쓰는 구조이기 때문입니다. 비유는 설명에는 도움이 되지만, 기능의 범위를 과장해서는 안 됩니다.
개발자에게 중요한 것은 용어보다 경계입니다. 이 방식은 모델이 새로운 사실을 마법처럼 학습한다는 뜻이 아닙니다. 세션 문맥을 fast weight state로 통합하는 메커니즘이며, 그 state가 어떤 범위에서 유지되고 언제 폐기되는지 명확해야 합니다. multi-tenant inference, 개인화, 보안 로그, 기업 코드베이스에 적용하려면 이 경계가 제품 정책과 인프라 정책으로 함께 내려와야 합니다.
다음 병목은 기억의 형식
이 논문은 아직 초기 연구입니다. benchmark는 통제된 과제가 많고, 실제 agent workload 전체를 대체해 검증한 것은 아닙니다. 결과가 대형 상용 LLM의 production inference에 곧장 들어간다고 보기도 어렵습니다. 하지만 흐름은 선명합니다. 장기 작업을 하는 AI 시스템에서 memory는 단순히 더 큰 context window가 아닙니다. 무엇을 원문으로 남기고, 무엇을 요약하고, 무엇을 내부 상태로 통합할지 결정하는 설계 문제입니다.
앞으로 코딩 에이전트나 연구 에이전트가 더 긴 세션을 맡게 되면, 지금의 context compaction은 더 자주 한계에 부딪힐 가능성이 큽니다. 요약은 손실이 있고, RAG는 검색 실패가 있으며, 긴 cache는 비쌉니다. sleep-like consolidation은 이 세 갈래 사이에 네 번째 선택지를 놓습니다. 버릴 문맥을 그냥 버리지 않고, 답변 시점에 부담을 주지 않는 형태로 미리 계산해 두는 것입니다.
그래서 이 논문의 진짜 뉴스 가치는 "LLM도 잠을 잔다"가 아닙니다. AI 에이전트의 다음 병목이 context 길이 자체가 아니라 기억의 형식일 수 있다는 신호입니다. 더 많은 token을 넣는 경쟁은 계속되겠지만, 오래 일하는 모델에는 언젠가 정리하는 시간이 필요합니다. 그 시간이 사람에게 보이지 않는 background compute가 될지, 모델 architecture에 들어간 sleep phase가 될지는 아직 열려 있습니다.